Use Levenshtein distance to find comparable or duplicated values, clear your information, and extra!
Utilizing the Levenshtein distance technique
This technique can be utilized amongst others (Soundex, LIKE assertion, Regexp) to carry out string similarity or string matching with a view to establish two parts (textual content, strings, inputs) which can be comparable however not similar.
This technique can be utilized for a wide range of purposes, together with figuring out duplicates, dealing with misspelled consumer enter information, cleansing buyer information, and so forth.
The thought of the Levenshtein technique is to compute the minimal edit distance between two strings.
However what’s an “edit” distance? It’s composed of three actions: insertions, substitutions, and deletions. These three actions are given equal weight by the algorithm, mainly a 1.
To assist perceive the mechanisms, listed here are just a few examples:
- Bigquer → Bigquery: The letter
yis added on the finish, so the space will likely be 1 (we made 1 addition). - music → mujic: The letter
jis an alternative to the lettersfrom music, the space can also be 1 (we made 1 substitution). - french fries → frij: The letters
frenchand area had been added, the letterjis a substitute foreand the letterswas deleted. (We made 7 additions, 1 substitution, and 1 deletion)
This technique is especially efficient when evaluating a full string to a different full string (and performs much less nicely when evaluating key phrases inside a sentence or evaluating a sentence in opposition to one other sentence).
You’ll find additional info on the algorithm on Wikipedia.
And now that we’ve realized the idea and purposes, let’s take a look at how we’d apply it in SQL.
Making a persistent operate
You may outline a UDFs as both persistent or non permanent. The primary distinction is that persistent features could be reused and accessed by a number of queries (it’s like making a dataset in your undertaking) whereas non permanent features solely work for the question you’re at present operating in your editor.
Personally, I get pleasure from working with a dataset that I name utility because it permits me to retailer tables and features that I can reuse throughout different datasets and queries.
Right here is the Javascript UDF operate we’ll in BigQuery:
When executing this question, it might then seem in your undertaking construction as observe:
Notice that this operate, as a substitute of returning the precise distinction as plenty of editions (returning 1 if we had been making 1 addition), will return a worth on a 0 to 1 scale. The place 1 means fully comparable and 0 means not comparable in any respect.
In our first theoric instance, Bigquer → Bigquery: The letter y was added, which means a distance of 1. Our operate will first compute the variety of editions divided by the longest inputted string, on this case, Bigquery with 8 characters (1 addition / 8 size) which is the space.
For getting the similarity, we merely reverse it, utilizing 1-(1/8) = 0,875
However first, let’s take a look at an actual SQL question!
Utilizing the operate in a SQL question
Now that the operate has been saved as a persistent UDF, you possibly can merely name it by writing its location. In our instance, will probably be referred to as utilizing the next:
`datastic.utility.levenshtein`(supply,goal)
We ready a number of circumstances to check the similarity rating produced by our technique.
The question will output the next outcomes:
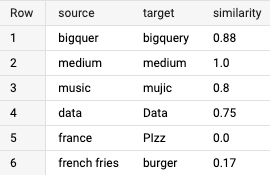
Within the first case, there’s an addition of 1 letter, which ends up in a similarity between the 2 phrases of 0.88!
The 2 extremes are additionally demonstrated: with the similar mixture of phrases medium | medium, the result’s a similarity of 1, and with the alternative mixture of phrases france | PIzz, the result’s a similarity of 0.
An actual-world instance with publicly accessible information
The use case we wish to clear up is correcting consumer nation information from our CRM. We seen that there was plenty of misspelled information, and we’ll use BigQuery public information to assist us.
This desk comprises the information offered by BigQuery,
and comprises all nation names within the following format:

Now, our CRM information desk comprises the next info, an e mail and a rustic (apparently with plenty of misspelled phrases)

Let’s attempt to clear up our real-world use case. For that, we’ll carry out the next question, which is able to consist of 4 steps:
- Loading nation information from BigQuery
- Loading our CRM information
- Making use of a
CROSS JOINassertion and computing our Levenshtein operate - Rating the outcomes to search out probably the most comparable nation
And, tadam 🎉, the outcomes are as follows:
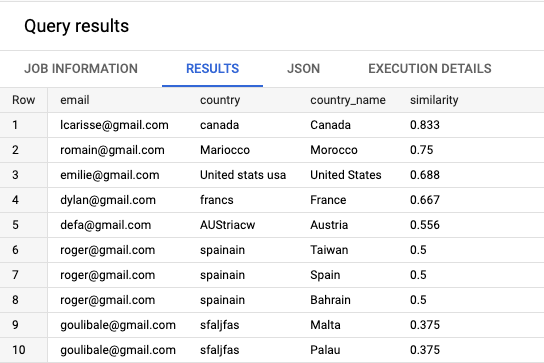
As you possibly can see, this technique has some caveats as we have now typically multiple row returned as a result of two units of strings are very comparable (that is the case for spainiain which is equally near Spain, Bahrain, and Taiwan)
We determined to make use of a CROSS JOINassertion to affix our two information tables. It means that we’ll evaluate every row of our CRM desk with all of the doable international locations current within the nation desk. In our instance, our CRM information has 7 rows and our nation information set has 250, which is able to create the results of 7×250=1750 rows.
This result’s diminished through the use of the QUALIFY clause to rank the nation that’s most comparable, However relying in your use case, the CROSS JOINanswer would require plenty of computing.
Going additional with larger datasets
For our instance, we used a small CRM dataset (7 rows). As compared, I reused the identical nation desk (250 rows) on a dataset of 8 million prospects, and it took round 33 seconds with BigQuery, which continues to be fairly quick. When you had been to make use of even larger datasets (perhaps in billion rows), then I might suggest utilizing ARRAYS than utilizing JOINS, which in BigQuery would lead to fewer sources wanted.
The second problem to unravel is selecting the right similarity when our Levenshtein distance operate returns multiple consequence. My advice can be to mix the Levenshtein technique with extra ones, like Common Expressions or Soundex, which might give extra weight to the similarity rating and doubtless permit a greater choice.
