SQL for heavy lifting, Pandas for deep diving
Firms want to have the ability to measure consumer engagement and retention to quantify a wide range of data akin to (i) the way it evolves over time, (ii) how delicate it’s to exterior occasions and seasonality, and (iii) how totally different consumer teams interact with their product. The product might typically be an app that customers work together with, to obtain some companies. Consequently, engagement might merely be outlined because the consumer’s exercise with the app.
On this submit, I’ll present you an instance of how consumer engagement could be investigated with “Cohort Evaluation”.
“A cohort is a gaggle of people that share a typical attribute over a sure time frame.”
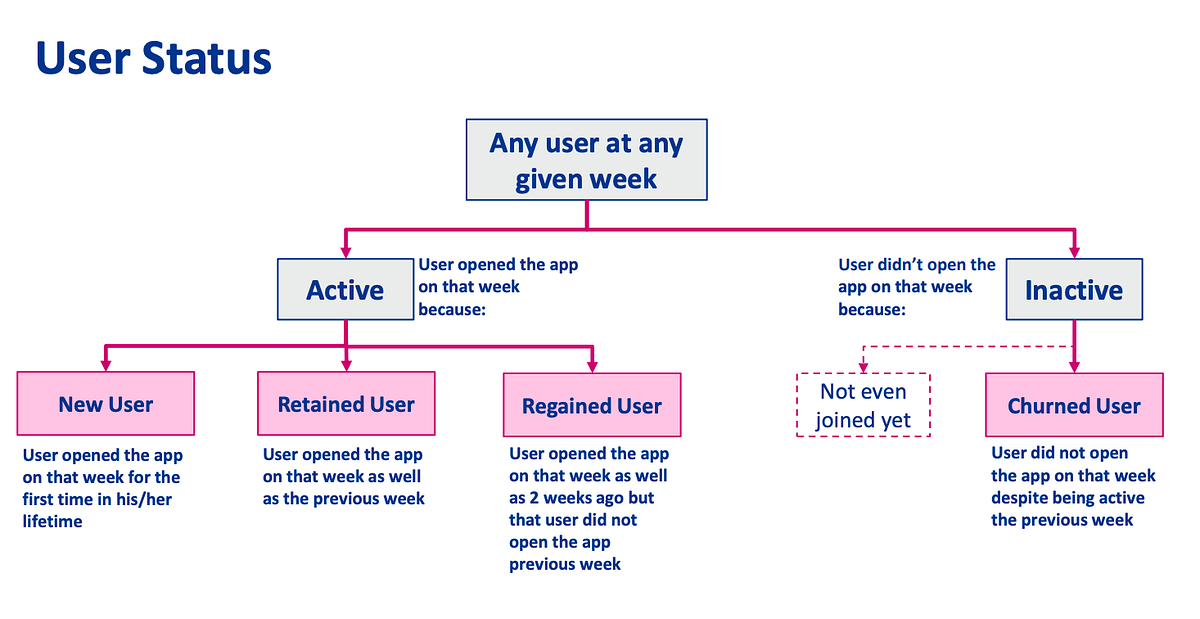
To make issues less complicated, let’s assume this frequent attribute to be the week a consumer opens the corporate’s app for the primary time. This units that consumer’s standing as an energetic consumer. If that consumer doesn’t open the app the subsequent week, then its standing might be inactive. By build up on this, one can give you the next standing definitions for the energetic and inactive customers, which can assist us to trace totally different cohorts over time.

With this logic, we will see that at any given week,
- The overall of retained, regained, and churned customers is the same as the cumulative sum of all new customers from the earlier weeks till that week.
- Retention Fee is (sum of retained customers) / (sum of retained customers + sum of churned customers)
Steps
Let’s generate a dummy consumer exercise database and begin crunching it.
2.a) Dummy Information Base
Usually, corporations have their very own databases the place they gather consumer exercise information. Nevertheless, for illustrative functions, we’ll generate our personal consumer exercise desk (with pandas and NumPy) and push it to a SQL database in order that we will use SQL queries for the heavy lifting. Our exercise desk can have 3 fundamental columns: (i) user_id, (ii) activity_day, and (iii) app_opens for that consumer on that day.
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import string
import seaborn as snspd.set_option('show.max_rows', 400)
pd.set_option('show.max_columns', 200)
pd.set_option('show.max_colwidth', 150)# ['A', 'B', ..., 'AA', 'AB', ..., 'ZY', 'ZZ']
ALPHABETICAL_LIST = (listing(string.ascii_uppercase) +
[letter1+letter2 for letter1 in string.ascii_uppercase
for letter2 in string.ascii_uppercase])%matplotlib inline
plt.rcParams["figure.figsize"] = (40,20)
The dummy consumer exercise desk might be
userid_list = [letter+'{:02d}'.format(i) for letter in ALPHABETICAL_LISTfor i in range(1,21)][:14000]
np.random.seed(0)app_opens = np.concatenate((
np.random.alternative(vary(10,13), dimension=len(userid_list)),
np.random.alternative(vary(8,11), dimension=len(userid_list)),
))user_ids = np.concatenate((
userid_list,
userid_list,
))app_activations = np.datetime64('2020-01-06') + np.random.alternative(np.arange(0, 180), len(userid_list))activity_days = np.concatenate((
app_activations,
app_activations + 7,
))random_user_ids = [x for x in userid_list]for days_passed in vary(14,106, 7):user_id_sample = int(np.ground(len(random_user_ids) * 0.98))
if user_id_sample!=0:random_user_ids = [random_user_ids[x] for x in
np.random.alternative(vary(len(random_user_ids)),
dimension=user_id_sample,substitute=False)]user_ids = np.concatenate((user_ids, random_user_ids))app_opens = np.concatenate((app_opens,
np.random.alternative(vary(3,7),
dimension=user_id_sample,
p=[0.2, 0.3, 0.3, 0.2]
),
))activity_days = np.concatenate((activity_days,
[app_activations[userid_list.index(x)]+days_passed for x in random_user_ids]
))
df_user_activity = pd.DataFrame(zip(user_ids, activity_days, app_opens),
columns=['user_id', 'activity_day', 'app_opens'])df_user_activity = df_user_activity.groupby(['user_id'],
group_keys=False
).apply(lambda df: df.pattern(len(df)-2)
).sort_index().reset_index(drop=True)df_user_activity['count'] = df_user_activity.groupby(['user_id'])['activity_day'].remodel(len)df_user_activity.loc[df_user_activity['count']==1, 'app_opens'] = np.minimal(5, df_user_activity['app_opens'])df_user_activity = df_user_activity.drop(['count'], axis=1)df_user_activity

Let’s write this desk to a SQL database.
from sqlalchemy import create_engine
import osSQL_ENGINE = create_engine('sqlite:///'+ 'medium_project.db',
connect_args={'check_same_thread': False}).join()df_user_activity.to_sql(title='user_activity',
index=False,
con=SQL_ENGINE,
if_exists='substitute')
2.b) SQL Question
The next question helped me obtain the view I wished to conduct my cohort evaluation. For the above-mentioned interval (42 weeks), I created a desk which reveals user_id, week, and weekly_flags (akin to new, retained, regained, and churned). This desk has 13,720 distinctive user_ids * 42 weeks = 576,240 rows.
On the question,
I created a weekly interval desk to hitch with user_activity_daily information to deliver lacking weeks for each consumer. My objective is to realize a desk view by which, for each consumer id, we now have 42-week rows and their whole weekly app opens. I begin with turning each exercise day right into a 12 months-Week view to use a gaggle by (sum of app opens) for customers. Later, I be a part of this to the interval desk, I convert app_opens to 0 for unrelated weeks and lastly, I calculate lifetime (cumsum), earlier week (lagged) and former lifetime (lagged cumsum) weekly_app_opens to assign new, retained, energetic, churned, regained flags. Observe: row_number() columns are to repeat the identical daily_activity row 42 occasions.
After I save this desk as a CSV, I returned Pandas for the remainder of my evaluation.
Though it’s not on this submit’s scope, if wanted, this desk may very well be additional joined with different SQL tables to deliver consumer segment-related data into the view.

2.c) Returning to Pandas
The desk under reveals us the weekly total new, retained, energetic, regained, churned customers.
df_overall_summary = df_weekly_activity.groupby(
['year_week']
)['new_flag',
'retained_flag',
'active_flag',
'churned_flag',
'regained_flag'].sum().reset_index()df_overall_summary

As an example, if we have a look at the primary 3 rows of the above information body, we will see that on the primary week of 2020, 435 customers opened the app for the primary time ever. The following week, out of those 435, 72 churned (for that week) and 363 have been nonetheless energetic along with the 523 new joiners.
Now that we now have our weekly exercise view on a consumer foundation, let’s analyse additional and visualize cohorts.
2.d) Desk Transformation
I’ll have a look at all customers’ exercise journeys by grouping same-week subscribers collectively. My objective is to determine whether or not there’s a drop in exercise for everybody after the Nth week. The energetic consumer common of those that have a brand new flag on Week X might be investigated all through Week X (100% exercise), Week X+1, Week X+2, Week X+3, Week X+4, … and many others.
df_weekly_activity['new_flag_cumsum'] = df_weekly_activity.groupby(['user_id'])['new_flag'].cumsum()# Filterin out the rows the place the consumer did not began its journey
# (they weren't even a brand new consumer but).df_cohort_prep = df_weekly_activity[df_weekly_activity['new_flag_cumsum']>0].reset_index(drop=True)
df_cohort_prep = df_cohort_prep.merge(df_cohort_prep[df_cohort_prep['new_flag']==1][['user_id', 'year_week']].rename(columns={'year_week': 'joined_on'}),
how='left', on=['user_id']
)
df_cohort['Nth_Week'] = (df_cohort['year_week'].str[:4].astype(int) * 52 +
df_cohort['joined_on'].str[:4].astype(int) * 52 * -1 +
df_cohort['year_week'].str[-2:].astype(int) +
df_cohort['joined_on'].str[-2:].astype(int) * -1
+ 1
)
2.e) Time Cohorts
Week No 1 is all the time 100% as a result of that’s when a consumer is a brand new consumer for the corporate.
df_heatmap = pd.pivot_table(
df_cohort[df_cohort['Nth_Week']<20],
index=['joined_on'],
columns=['Nth_Week'],
values=['active_flag'],
aggfunc=lambda x: np.sum(x) / len(x)
)df_heatmap.loc[''] = np.nandf_heatmap = df_heatmap.sort_index(axis=0)df_heatmap.loc[' '] = np.nanfig2 = plt.determine(figsize=(24,16))ax1=sns.heatmap(df_heatmap.values,
xticklabels=[b for a,b in df_heatmap.columns],
yticklabels=df_heatmap.index.tolist(),
vmin=df_heatmap.min(axis=1).min(),
vmax=df_heatmap.max(axis=1).max(),
annot=True,
fmt=".2%",
cmap='YlGnBu',
linewidths=.005,
linecolor='#029386',
cbar=False,
)ax1.set_title('Lively Customers %')plt.subplots_adjust(hspace=0.35, wspace=0.2)ax1.set_yticklabels(ax1.get_yticklabels(), rotation=0)ax1.set_xlabel('Nth Week at [Company X]')ax1.set_ylabel('Joined On Week')fig2.savefig("Weekly Lively Customers % Medium.png", bbox_inches = 'tight')

It’s seen that the consumer exercise decreases to 80–85% within the 2nd week, and continues to go down and, for lots of the cohorts, exercise drops to 0% within the sixteenth week.
df_heatmap = pd.pivot_table(
df_cohort[df_cohort['Nth_Week']<20],
index=['joined_on'],
columns=['Nth_Week'],
values=['weekly_app_opens'],
aggfunc=lambda x: np.imply(x)
)df_heatmap.loc[''] = np.nandf_heatmap = df_heatmap.sort_index(axis=0)df_heatmap.loc[' '] = np.nanfig2 = plt.determine(figsize=(24,16))ax1=sns.heatmap(df_heatmap.values,
xticklabels=[b for a,b in df_heatmap.columns],
yticklabels=df_heatmap.index.tolist(),
vmin=df_heatmap.min(axis=1).min(),
vmax=df_heatmap.max(axis=1).max(),
annot=True,
#fmt=".2%",
cmap='YlGnBu',
linewidths=.005,
linecolor='#029386',
cbar=False,
)ax1.set_title('App Opens Avg.')plt.subplots_adjust(hspace=0.35, wspace=0.2)ax1.set_yticklabels(ax1.get_yticklabels(), rotation=0)ax1.set_xlabel('Nth Week at [Company X]')ax1.set_ylabel('Joined On Week')fig2.savefig("Weekly App Opens Avg Medium.png", bbox_inches = 'tight')
In common, customers open the app 10–11 occasions on their first week, after which 6–7 occasions on their 2nd week. Earlier than churning fully, they open the app 2–2.5 occasions per week.

2.f) Behaviour Cohorts
Discovering the row indexes the place a consumer churned for good and wasn’t regained once more, ever.
df_churned_forever_index = df_cohort[df_cohort['active_flag'].eq(1)[::-1].astype(int).groupby(df_cohort['user_id']).cumsum().eq(0).sort_index(axis=0)
].groupby('user_id', kind=False
)['Nth_Week'].idxmin().reset_index().rename(columns={'Nth_Week': 'index_value'})
Maintaining solely the rows between a consumer was new and churned for the remainder of our time window.
df_cohort = df_cohort.merge(df_churned_forever_index,
how='left', on=['user_id']
)
df_cohort_churned_forever = df_cohort[df_cohort.index<=df_cohort['index_value']].reset_index(drop=True)
For all churned customers, what number of churned solely after 2 weeks, 3 weeks, … N weeks and what are their weekly_app_opens averages?
df_users_churning_week = df_cohort_churned_forever.groupby(
['user_id']
)['Nth_Week'].max().reset_index()list_to_append_leaving_users = []for Nth_WEEK in vary(2,15):list_of_users_leaving_n_week = df_users_churning_week[
(df_users_churning_week['Nth_Week']==Nth_WEEK)]['user_id'].tolist()list_to_append_leaving_users.append(df_cohort_churned_forever[
df_cohort_churned_forever['user_id'].isin(list_of_users_leaving_n_week)
].groupby(['Nth_Week'])['weekly_app_opens'].imply().reset_index().rename(
columns={'weekly_app_opens': '{} Customers Leaving in Week {}'.format(
len(list_of_users_leaving_n_week), Nth_WEEK)}).set_index(['Nth_Week']))df_churned_users_weekly_app_opens = pd.concat(list_to_append_leaving_users, kind=False, axis=1)
df_churned_users_weekly_app_opens.reset_index()

As the image above presents, the customers that churn of their 2nd week and by no means get regained are those who open the app 4.7 occasions on common of their first week.

Firms want to preserve their customers’ exercise if not enhance it. Moreover, if there are any purple flags that may very well be raised for a possible decline in consumer engagement, they’d wish to know this by inspecting tendencies. On this submit, I shared some Python and SQL code, to reveal how one can analyse the retention from a consumer exercise desk.
A number of cohorts have been created for example:
1- Time cohorts (Part 2.e, grouping customers by their exercise over time)
2- Behaviour cohorts (Part 2.f, discovering customers who have been churned and by no means regained once more)

{kind=link}