Having constructed machine studying merchandise at two completely different corporations with very completely different engineering cultures, I’ve made all the following unsuitable assumptions
- All different knowledge orgs do issues like my firm, so we’re doing tremendous.
- My org is method behind different orgs.
- My org is uniquely superior, so we are able to relaxation on our laurels.
In an effort to escape the small bubble of my existence, I posted a survey in Could 2019 to a non-public slack group and on Twitter. The survey was designed to study in regards to the manufacturing lifecycle of machine studying fashions at different corporations. If you want to see the survey questions for your self (and fill it out!), it’s reside right here.
Maybe it’s because of the small pattern measurement of the survey (40 respondents as of this writing), however I’m completely satisfied to report that knowledge orgs are all over. The strongest conclusion that I can draw is that there’s all the time room for enchancment within the manufacturing ML course of.
Regardless of the small pattern measurement, I’ll delve into among the findings, notably those who I discovered shocking. If you want to have a look at the uncooked knowledge, the outcomes can be found at this Google Sheet.
Knowledge Cleaning
Survey knowledge is usually a ache to munge in pandas, and this situation isn’t any completely different. Apologies for the lengthy, pretty boring code beneath. I’ll make a fast shoutout to:
- bidict: This library means that you can create one-to-one dictionaries in Python. Because of this each worth solely belongs to 1 key which lets you translate lengthy strings to slugs and vice versa.
- pandas Categorical: This was useful for mapping binned ranges in survey responses (1-4, 5-10, 10-20, and many others…) to ordered classes which permits for straightforward sorting in a while.
%config InlineBackend.figure_format = 'retina'
from altair import datum
from bidict import bidict
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
import numpy as np
import pandas as pd
from pandas.api.sorts import CategoricalDtype
import seaborn as sns
plt.ion()
plt.rcParams['axes.labelsize'] = 16
plt.rcParams['axes.titlesize'] = 18
plt.rcParams['font.size'] = 16
plt.rcParams['lines.linewidth'] = 2.0
plt.rcParams['lines.markersize'] = 6
plt.rcParams['legend.fontsize'] = 14
df = pd.read_csv("responses_anon.csv")
renames = bidict({
"Does your organization practice and use machine studying fashions?": "train_models",
"What kinds of machine studying issues are labored on at your organization?": "problem_types",
"How do nearly all of fashions get retrained?": "retrain_method",
"How typically do nearly all of fashions get retrained?": "retrain_frequency",
"How do the outputs of the fashions get served? (examine all that apply)": "output_methods",
"Roughly what number of completely different fashions are serving outputs?": "num_models",
"Which classes of efficiency do you monitor?": "perf_tracking_cats",
"How is the mannequin efficiency tracked? (examine all that apply)": "perf_tracking_methods",
"How typically do you examine mannequin efficiency?": "perf_checking_frequency",
"How huge is your organization?": "company_size",
"How many individuals are coaching and/or deploying ML fashions at your organization?": "num_ml_employees",
"Can I attain out to you for follow-up questions?": "can_i_followup",
"Are you curious about the outcomes of this survey?": "interested_in_results",
"If sure to both of the above, what's your e mail tackle?": "e mail"
})
df = df.rename(columns=renames)
def split_and_rename(splittable_string, rename_func, delim=";"):
return [
rename_func(split) for split
in str(splittable_string).split(delim)
]
def clean_problem_types(df):
df["problem_types"] = (
df["problem_types"]
.apply(
lambda x: [
y.replace("Recommendation systems", "Recommendation Systems")
for y in x.split(";")
]
)
)
return df
def clean_output_methods(df):
def renamer(val):
if val.startswith("Outputs are written"):
return "written_to_db"
elif val.startswith("An API computes outputs"):
return "realtime_api"
elif val.startswith("An API serves"):
return "precomputed_api"
else:
return val
df["output_methods"] = df["output_methods"].apply(split_and_rename, args=(renamer,))
return df
def clean_num_models(df):
model_types = CategoricalDtype(
classes=["1", "2-5", "5-10", "10-20", "20-50", "50+"],
ordered=True
)
df["num_models"] = df["num_models"].astype(model_types)
return df
def clean_perf_tracking_cats(df):
def renamer(val):
if val.startswith("Coaching"):
return "training_data"
if val.startswith("Offline"):
return "offline_test"
if val.startswith("On-line"):
return "on-line"
if val.startswith("nan"):
return "none"
if val.startswith("Put up"):
return "post-hoc"
else:
elevate ValueError(f"Unknown val: {val}")
df["perf_tracking_cats"] = df["perf_tracking_cats"].apply(split_and_rename, args=(renamer,))
return df
def clean_perf_tracking_methods(df):
def renamer(val):
if val.startswith("Guide"):
return "handbook"
if val.startswith("Automated"):
return "automated_sql_or_script"
if val.startswith("Customized"):
return "custom_system"
if val.startswith("Third"):
return "third_party"
if val.startswith("Software"):
return "logs"
if val.startswith("Buying and selling"):
return "aux_metric"
else:
elevate ValueError(f"Unknown val: {val}")
df["perf_tracking_methods"] = (
df["perf_tracking_methods"]
.apply(lambda x: [renamer(val) for val in str(x).split(";")])
)
return df
def clean_perf_checking_frequency(df):
df["perf_checking_frequency"] = df["perf_checking_frequency"].apply(
lambda x: str(x).break up(";")
)
return df
def clean_company_size(df):
company_size_types = CategoricalDtype(
classes=["1-10", "11-50", "51-150", "151-500", "500+"],
ordered=True
)
df["company_size"] = df["company_size"].astype(company_size_types)
return df
def clean_num_ml_employees(df):
ml_types = CategoricalDtype(
classes=["1-4", "5-10", "11-24", "25-49", "50-100", "100+"],
ordered=True
)
df["num_ml_employees"] = df["num_ml_employees"].astype(ml_types)
return df
def clear(df):
df = clean_problem_types(df)
df = clean_output_methods(df)
df = clean_num_models(df)
df = clean_perf_tracking_cats(df)
df = clean_perf_tracking_methods(df)
df = clean_perf_checking_frequency(df)
df = clean_company_size(df)
df = clean_num_ml_employees(df)
return df
Respondent Context
Earlier than trying on the machine learning-specific questions within the survey, let’s take a look at some demographics of the survey respondents. We are able to see that almost all of the respondents come from bigger corporations.
(Writer’s word: You possibly can inform that I’ve solely labored at startups by the low bins of firm sizes that I supplied within the survey. Yay for survey bias.)
ax = (
df
.groupby("company_size")
.measurement()
.sort_index(ascending=False)
.plot
.barh()
);
ax.set_xlabel("Variety of Respondents");
ax.set_ylabel("");
ax.set_title(f"Q: {renames.inverse['company_size']}");

Alternatively, there are usually fewer knowledge individuals deploying ML fashions at these corporations.
ax = (
df
.groupby("num_ml_employees")
.measurement()
.sort_index(ascending=False)
.plot
.barh()
);
ax.set_xlabel("Variety of Respondents");
ax.set_ylabel("");
title = renames.inverse['num_ml_employees']
title = "and/orn ".be part of(title.break up("and/or"))
ax.set_title(f"Q: {title}");
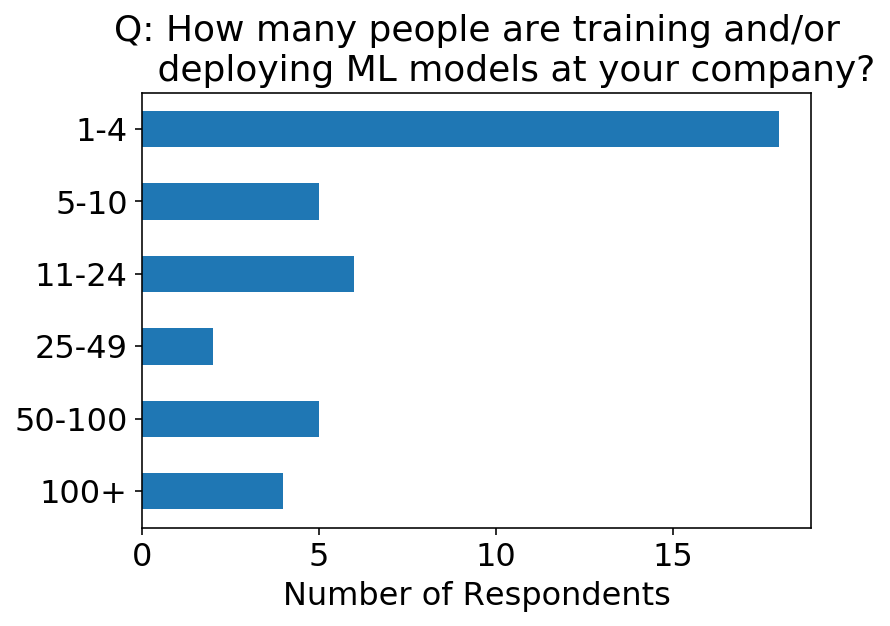
We are able to take a look at a warmth map of the above two questions. As a sanity examine, it’s good to see that we don’t actually have respondents saying there are extra ML staff than firm staff. I used to be additionally impressed to see that there are 4 locations with 100+ staff deploying ML fashions!
sns.heatmap(
df
.groupby(["company_size", "num_ml_employees"])
.measurement()
.unstack(degree=1),
annot=True
);
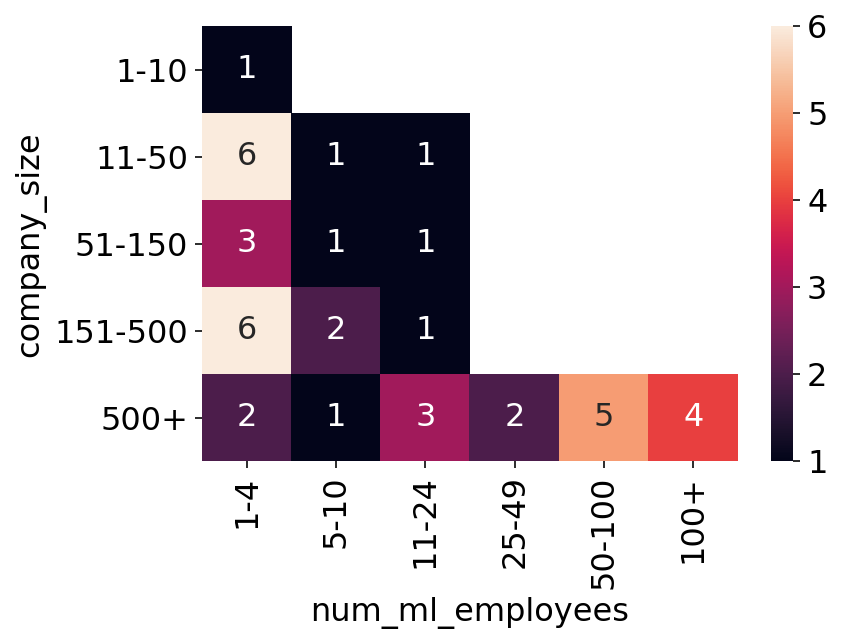
The survey additionally requested “Roughly what number of completely different fashions are serving outputs?”. Under we see the heatmap of this query on the y-axis versus the variety of ML staff on the x-axis. This provides us some type of an understanding of how many individuals per fashions there are on the firm.
sns.heatmap(
df
.groupby(["num_models", "num_ml_employees"])
.measurement()
.unstack(degree=1),
annot=True
);

Mannequin Coaching
Once I began at my final job, I inherited an ML system that required coaching a mannequin domestically, scp-ing the pickled mannequin as much as an EC2 occasion, and restarting the API on that occasion to have it choose up the brand new mannequin. On the one hand, this was fairly terrifying to do on a manufacturing service, and I undoubtedly fucked the method up greater than as soon as. Alternatively, we have been working an experiment to see if the mannequin was even value it, so perhaps this may very well be thought of us adhering to not prematurely optimizing. Nonetheless, the mannequin received the experiment, and we finally setup automated batch retraining of the mannequin.
I suppose I simply assumed that as a result of I had finally set this up, different individuals had, too. By the query responses beneath, that doesn’t seem like the case. There may very well be a number of explanations, although. It’s a hell of a number of work to get to the purpose the place any different system or particular person is consuming the outputs of your mannequin. It’s much more work to automate the manufacturing workflow. Some respondents’ orgs could also be younger. Alternatively, some fashions not often must be retrained (e.g. word2vec from scratch).
ax = df.retrain_method.value_counts(normalize=True).plot.barh();
ax.set_title(renames.inverse["retrain_method"]);
ax.set_ylabel("Retrain Methodology");
ax.set_xlabel("P.c of Respondents");
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format))

The following query considerations how typically the fashions get retrained. We see right here that the most well-liked response is Randomly, adopted by Month-to-month which might be not shocking provided that many fashions are retrained manually. One factor I ought to level out is that various kinds of fashions require completely different coaching frequencies. Recommender methods’ efficiency vastly improves with any knowledge on a person (the so-called “chilly begin” downside). As such, one ought to retrain them as often as doable on the most recent knowledge. A couple of-featured logistic regression might not profit a lot from retraining because of the mannequin’s complexity already being saturated on smaller knowledge.
At my final firm, we strove for each day mannequin retraining just because we might (the info was small), and we might choose up errors within the knowledge faster this manner.
ax = df.retrain_frequency.value_counts(normalize=True).plot.barh();
ax.set_title(renames.inverse["retrain_frequency"]);
ax.set_ylabel("Retrain Frequency");
ax.set_xlabel("P.c of Respondents");
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format))

We are able to break up the above two questions and take a look at the retraining frequency for fashions which might be retrained routinely versus manually. As anticipated, nearly all of manually retrained fashions are retrained with random frequency, whereas routinely retrained fashions have a set frequency.
fig, axs = plt.subplots(2, 1, figsize=(6, 8));
axs = axs.flatten();
df.question("retrain_method == 'Routinely (e.g. a batch job)'").groupby("retrain_frequency").measurement().plot.barh(ax=axs[0]);
df.question("retrain_method == 'Manually'").groupby("retrain_frequency").measurement().plot.barh(ax=axs[1]);
axs[0].set_title("Computerized Retraining");
axs[1].set_title("Guide Retraining");
axs[1].set_xlabel("Variety of Respondents");
# Set identical x-scale for each axes
xlims = listing(zip(*[ax.get_xlim() for ax in axs]))
xlim = min(xlims[0]), max(xlims[1])
axs[0].set_xlim(xlim);
axs[1].set_xlim(xlim);
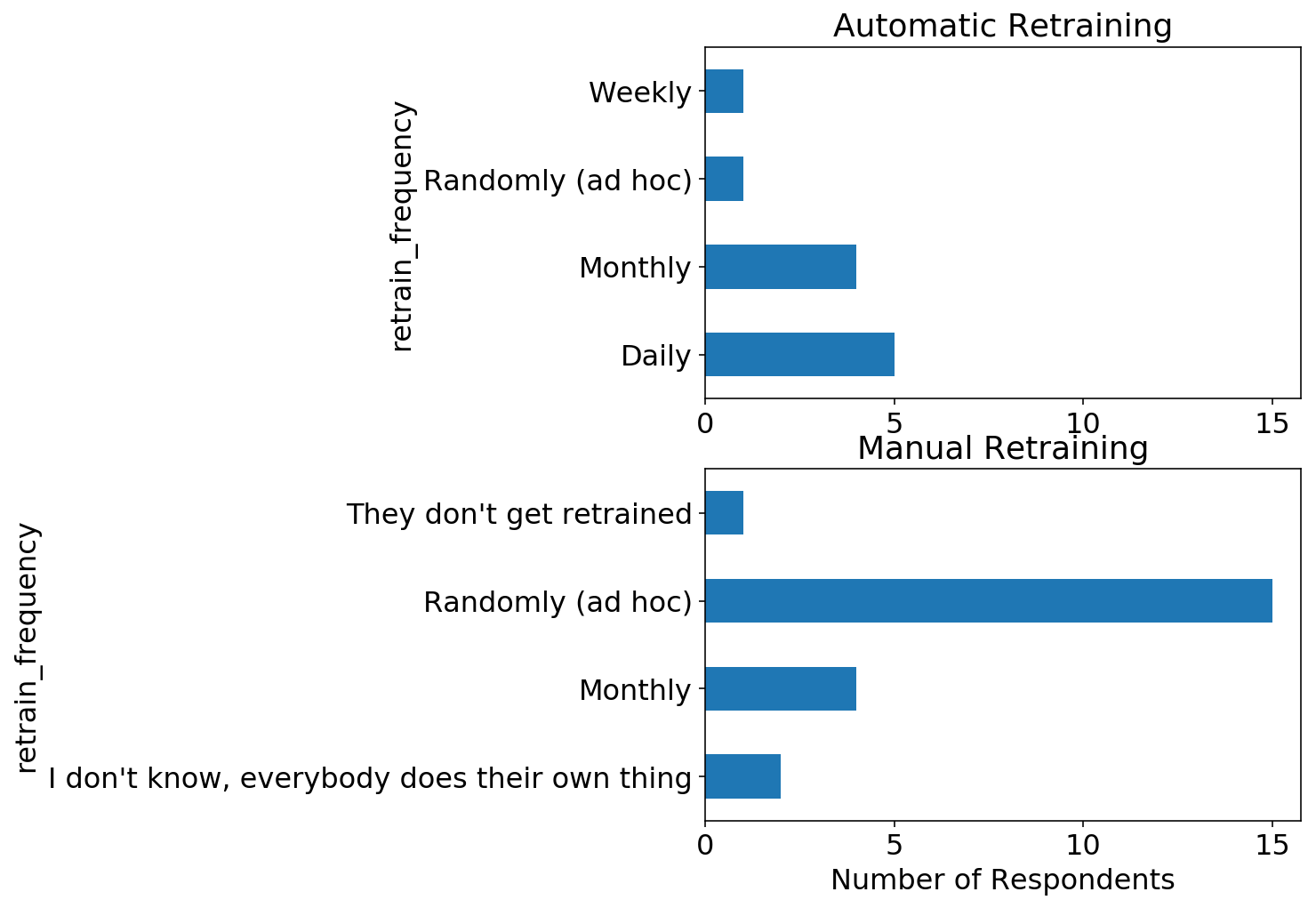
Mannequin Serving and Monitoring
Lest I used to be sounding snobby within the earlier part speaking about peoples’ random, handbook retraining, I used to be completely impressed with the sophistication of respondents’ mannequin serving and monitoring setups. The primary query I requested about mannequin serving was
How do the outputs of the fashions get served? (examine all that apply)
with the next choices:
- Outputs are written to a database and another system makes use of them
- An API serves pre-computed outputs
- An API computes outputs in realtime
Wanting on the chart beneath, it’s spectacular to see that 60% of respondents’ corporations have fashions deployed as realtime APIs. That is fairly tough in that the mannequin possible wants to fulfill typical engineering SLAs like low latency and uptime.
total_respondents = len(df)
ax = (
df
.explode("output_methods")
.question("output_methods in ['precomputed_api', 'realtime_api', 'written_to_db']")
["output_methods"]
.value_counts() / total_respondents
).plot.barh();
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format));
ax.set_title("fashionsn ".be part of(renames.inverse["output_methods"].break up("fashions")));
ax.set_xlabel("Share of Respondents");

I additionally requested in regards to the metrics which might be monitored, together with how they’re monitored:
Q: What classes of efficiency do you monitor?
A:
- Coaching knowledge metrics (e.g. a classifier’s AUC on the coaching knowledge)
- Offline take a look at knowledge metrics (e.g. a classifier’s AUC on held out take a look at knowledge)
- On-line metrics (e.g. evaluating predictions on the time of mannequin serving to outcomes)
Q: How is the mannequin efficiency tracked? (examine all that apply)
A:
- Guide SQL queries / scripts
- Automated SQL queries / scripts
- Customized-built monitoring system
- Third-party system
Once more, I’m impressed by the extent of sophistication. On-line metrics are important to trace as soon as a mannequin is in manufacturing, however they’re additionally probably the most tough metrics to trace. Nonetheless, >60% of respondents monitor this knowledge.
total_respondents = len(df)
ax = (
df
.explode("perf_tracking_cats")
.question("perf_tracking_cats in ['training_data', 'offline_test', 'online']")
["perf_tracking_cats"]
.value_counts() / total_respondents
).plot.barh();
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format));
ax.set_title(renames.inverse["perf_tracking_cats"]);
ax.set_xlabel("Share of Respondents");

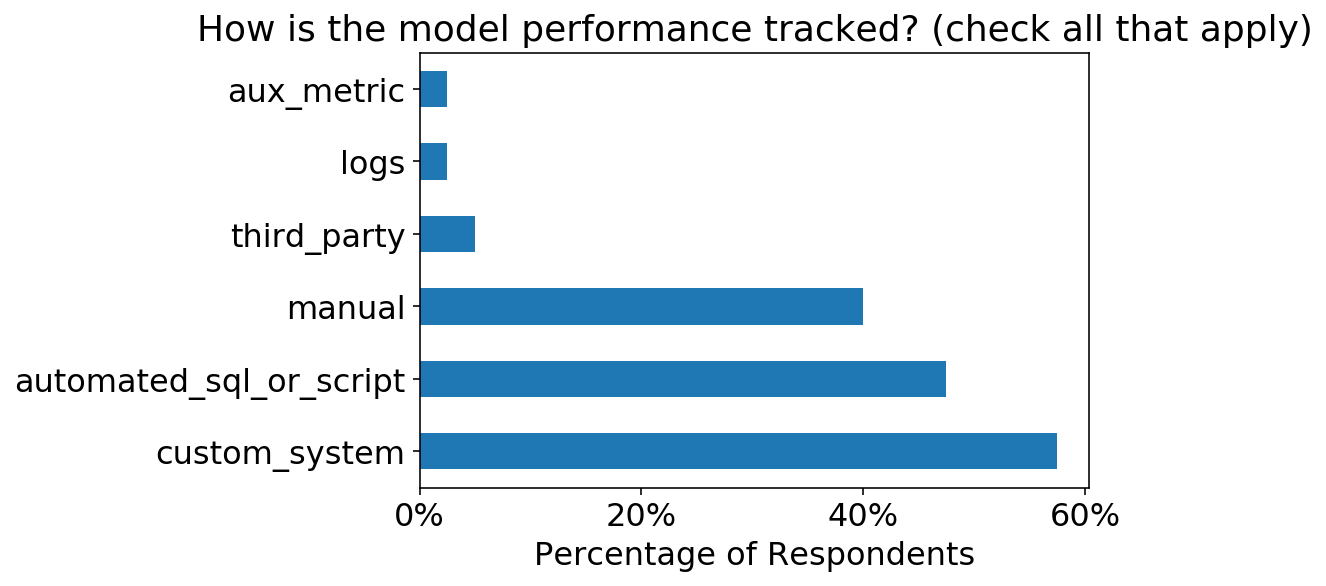
As effectively, it’s cool to see that >50% of respondents have setup both automated scripts or customized monitoring methods.
total_respondents = len(df)
ax = (
df["perf_tracking_methods"]
.explode()
.value_counts() / total_respondents
).plot.barh();
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format));
ax.set_title(renames.inverse["perf_tracking_methods"]);
ax.set_xlabel("Share of Respondents");
I additionally requested how typically the mannequin efficiency is tracked. We are able to see that the most well-liked frequency is Weekly, which is the everyday cadence that I’ve setup automated monitoring for this stuff prior to now. Whether or not or not I might truly look on the metrics every week is a special story…
total_respondents = len(df)
opts = [
"Daily",
"Weekly",
"Monthly",
"Rarely",
"I don't check the performance"
]
ax = (
df
.explode("perf_checking_frequency")
.question("perf_checking_frequency in @opts")
["perf_checking_frequency"]
.value_counts() / total_respondents
).loc[opts].plot.barh();
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format));
ax.set_title(renames.inverse["perf_checking_frequency"]);
ax.set_xlabel("Share of Respondents");


{kind=link}