Making a real-time value recommender system utilizing trendy data-related instruments
Just lately, GitHub introduced the anticipated (and controversial) Copilot, an AI able to producing and suggesting code snippets with significantly good efficiency.
Nevertheless, Copilot shouldn’t be solely spectacular for its suggestion capacities — one thing already achieved in scientific papers — however primarily for the truth that it’s an glorious product (and I additionally say this from the angle of a person), able to offering predictions in actual time to thousands and thousands of builders concurrently by way of easy textual content editors’ extensions.
As machine studying applied sciences mature, it turns into more and more essential to know not solely how AI fashions work and the right way to improve their efficiency, but in addition the technical a part of the right way to put them into manufacturing and combine them with different techniques.
To train this a part of “AI infrastructure”, on this submit we are going to simulate an actual state of affairs (or virtually), the place it will likely be essential to combine a Machine Studying mannequin with a “manufacturing” database to make real-time predictions as new information are added.
Possibly the submit will get a bit lengthy, so roll up your sleeves and be a part of me on this undertaking.
Suppose we’ve a promoting automobile platform, the place the customers can register and announce their autos. As new automobiles are registered (within the database), the app ought to counsel (utilizing our machine studying mannequin) a value for the automobile. After all, this software must run in real-time, so the person can rapidly obtain acceptable suggestions.
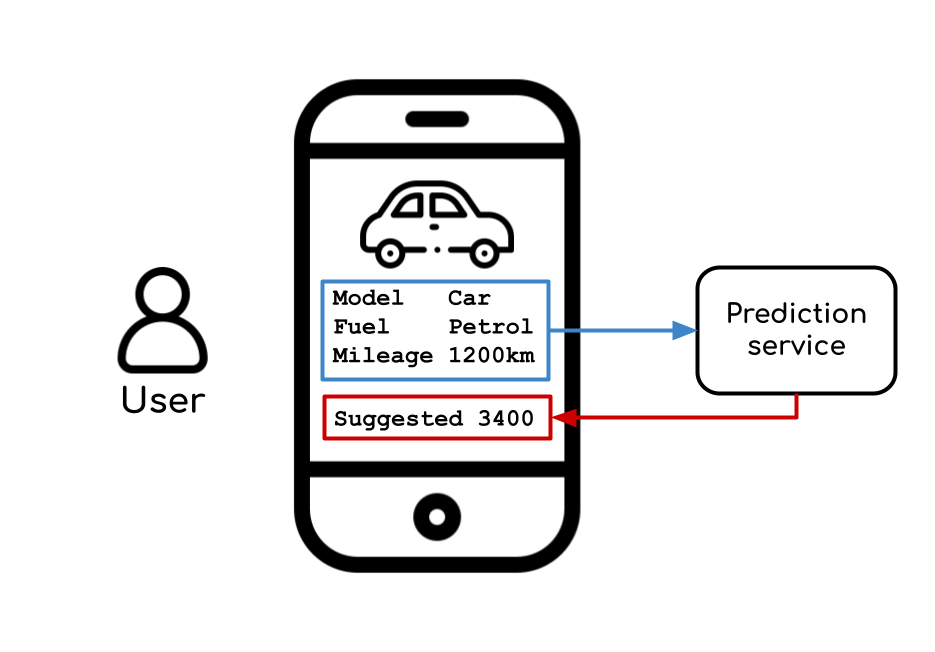
To simulate the information, we’re going to make use of the Ford Used Automobile Itemizing dataset from Kaggle, a dataset containing the promoting value of over 15k automobiles and their respective attributes (Gas kind, mileage, mannequin, and so on).
I beforehand made some experiments on the dataset and located a adequate mannequin, (the total code can be accessible on GitHub) so let’s skip the information evaluation/knowledge science half to deal with our most important purpose — making the appliance work.
To unravel our downside, we’re going to want the next issues: A strategy to detect when new entries are added to the database (Change Knowledge Seize), an software to learn these entries and predict the value with the machine studying mannequin, and a strategy to write these entries again within the unique database (with the value), all in real-time.
Fortunately, we don’t should reinvent the wheel. The instruments offered within the following sections will assist us quite a bit, with little (or no) code in any respect.
CDC with Debezium & Kafka
Change Knowledge Seize, or simply CDC, is the act of monitoring and monitoring the adjustments in a database. You possibly can consider CDC as knowledge gossip, each time one thing occurs contained in the database, the CDC software listens and shares the message with its “mates”.
For instance, if the entry (João, 21) is added to the desk neighbors, the software will whisper one thing like: {‘added’:{‘identify’: ‘João’, ‘age’:21, ‘id’:214}}.
And that is very helpful for a lot of purposes because the adjustments captured can be utilized for a lot of duties, like database synchronization, knowledge processing, and Machine Studying, which is our case.
Debezium is an open-source software specialised in CDC. It really works by studying the database (on this case referred to as supply) logs and reworking the detected adjustments into standardized structured messages, formatted in AVRO or JSON, so one other software can devour it with out worrying about who’s the supply.
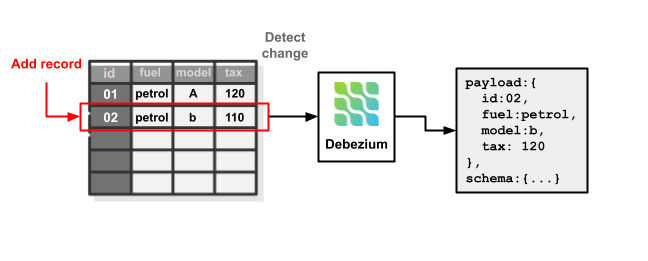
It can also do it the opposite approach, by receiving standardized messages describing a change and reflecting it into the database (on this case referred to as sink).
Debezium is constructed on prime of Apache Kafka, a well-known open-source Distributed Occasion Streaming Device utilized by many massive corporations, like Uber and Netflix, to every day transfer gigabytes of information. Due to this large scalability when involves knowledge motion, Kafka has an immense potential to assist machine studying fashions in manufacturing.
We don’t have to know quite a bit about Kafka for this undertaking, simply its primary ideas. In Kafka, we’ve a construction of subjects, containing messages (actually only a string of bytes) written by a producer and browse by a shopper. The latter two will be any software that’s capable of join with Kafka.
It has confirmed to be a superb software for large-scale purposes, which is certainly not our case with this easy undertaking, however its simplicity in use pays out any overhead added (on this undertaking).
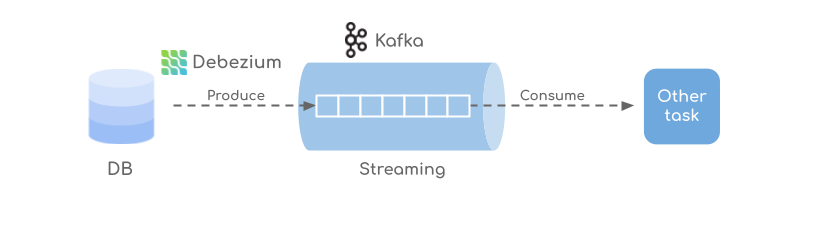
And that’s how our knowledge strikes: When Debezium is configured to look at some desk in our database it transforms the detected adjustments into standardized messages, serializes them into bytes, and sends them to a Kafka subject.
Then, one other software can connect with that Subject and devour the information for its wants.
BentoML
BentoML is an open-source framework for serving ML fashions. It permits us to make versioning and deploying of our machine studying mannequin with a easy python library.
It is a superb software, particularly in case you are from the information science world and by no means took off a mannequin from the Jupyter Pocket book’s “comfortable fields” into the “manufacturing” world.
The well-known python libraries for machine studying both don’t have a strategy to serve fashions, as a result of they think about it out of scope or once they have it, it’s not really easy to make use of. Due to this, many tasks depend on delivering their fashions through APIs constructed with FastAPI or Flask, which is ok, however not optimum.
For my part, BentoML narrows this hole between mannequin coaching and deploying very properly.
We’ll study extra about it within the following sections.
Becoming a member of every little thing collectively
Now that we all know, a minimum of superficially, the instruments used, you in all probability already found out how we going to unravel the issue.
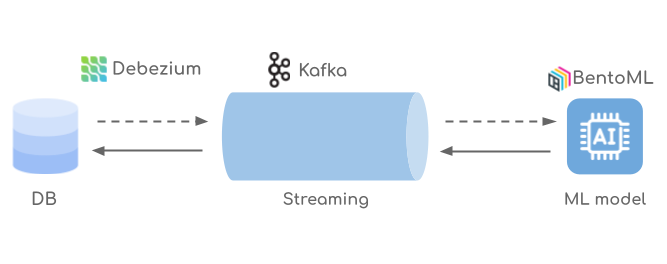
We’ll have a Debezium occasion watching our database, streaming each change detected to a Kafka subject. On the opposite facet, a python app consumes the messages and redirects them to the BentoML service, which returns a predicted value. Then, the python app joins the information with their predicted costs and writes them again to a different Kafka subject. Lastly, the Debezium occasion, which can also be watching this subject, reads the messages and saves them again into the database.
Okay, that’s a number of steps, however don’t be scared, I promise that the code for doing all that is quite simple.
To ease the understanding, let’s make an X-ray on the above picture and see some inside organs (elements) of our creature (structure).
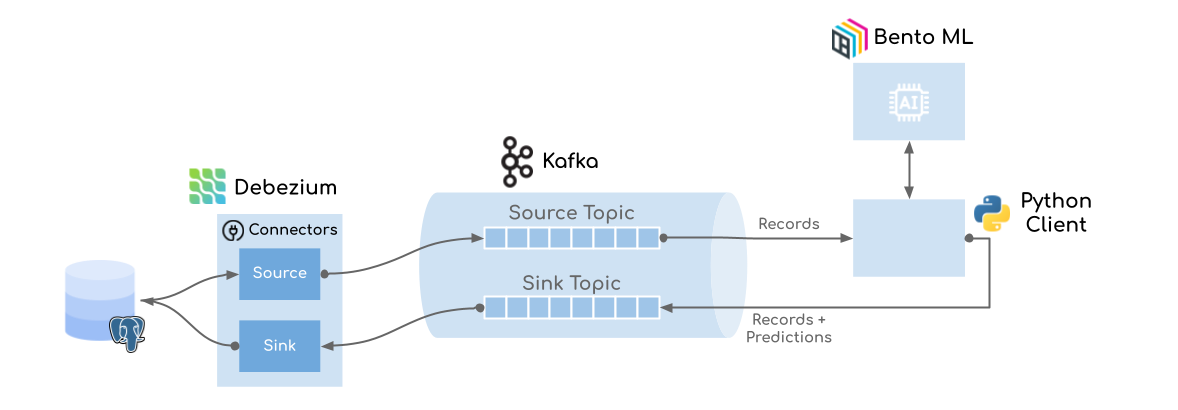
All we have to do is to create the database, configure the Debezium connectors (supply and sink) and deploy our machine studying mannequin with Python.
I’ll attempt to be temporary, the total detailed code can be on GitHub.
The setting
The very first thing to do is configure the setting, all you want is:
- A Python setting with the next packages:
numpy
pandas
scikit-learn==1.1.2
xgboost==1.6.1
bentoml
pydantic
used to coach and deploy the machine studying mannequin.
2. Docker and docker-compose.
All of the infrastructure is constructed utilizing containers. Additionally, we can be utilizing Postgres as our database.
And that’s all 
Configuring Postgres
The Postgres configuration could be very easy, we solely have to create a desk to retailer the automobile knowledge and set the configuration wal_level=logical.
So, the Postgres Dockerfile is simply this:
The wal_level=logical is a configuration wanted to Postgres work appropriately with Debezium.
Configuring Debezium and Kafka connectors
Getting began with Kafka and Debezium (with Docker) is easy, is only a matter of configuring the pictures and connectors appropriately. The docker-compose and Dockerfile used on this undertaking have been primarily based on one in all Debezium’s examples within the official repository.
Observe: I’ve hidden some strains to make this code block shorter, examine the total code on GitHub.
The Debezium Dockerfile is configured with the drivers for Kafka Join and Postgres.
With this docker-compose file, we’re able to configure Debezium. To begin the containers, kind within the terminal:
docker-compose up --build
After some preliminary configurations (and a number of logs), the containers ought to begin appropriately. Now you may open your browser on localhost:8083.
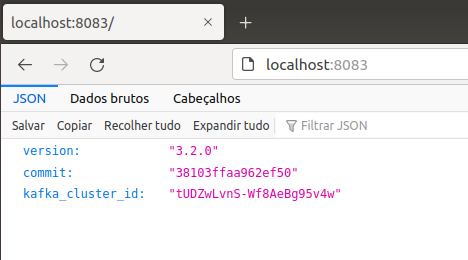
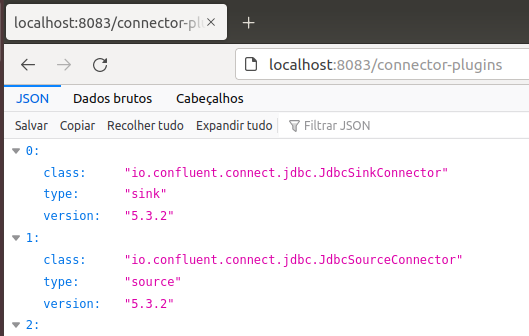
That is the bottom endpoint of Debezium’s API, which is the place all of the configurations happen. For instance, if we transfer to localhost:8083/connector-plugins/, it is potential to see all of the plugins accessible to create a connector.
To create a brand new database connector, we have to ship a POST request with the connector’s configurations to the endpoint /connectors. As mentioned earlier than, there are two kinds of connectors, the supply connectors that retrieve the adjustments from the database and stream them to Kafka, and the sink connectors that learn messages from Kafka and replicate them to the database.
Let’s create the supply connector for our Postgres database and see how this works.
We simply have to move the database deal with and credentials, the connector class (one of many accessible on the endpoint /connector-plugins/), and the desk that we wish to seize.
You possibly can study extra about these connectors and configurations on this submit.
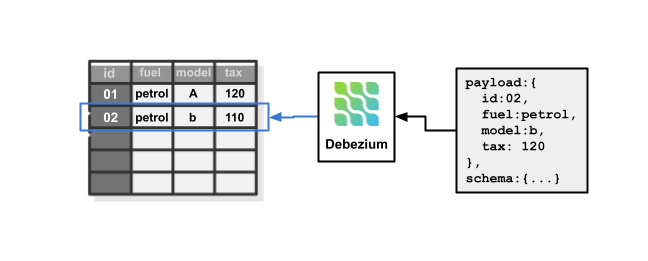
Now, Debezium will create a Kafka subject named car_database.public.car_data and begin streaming the adjustments to it.
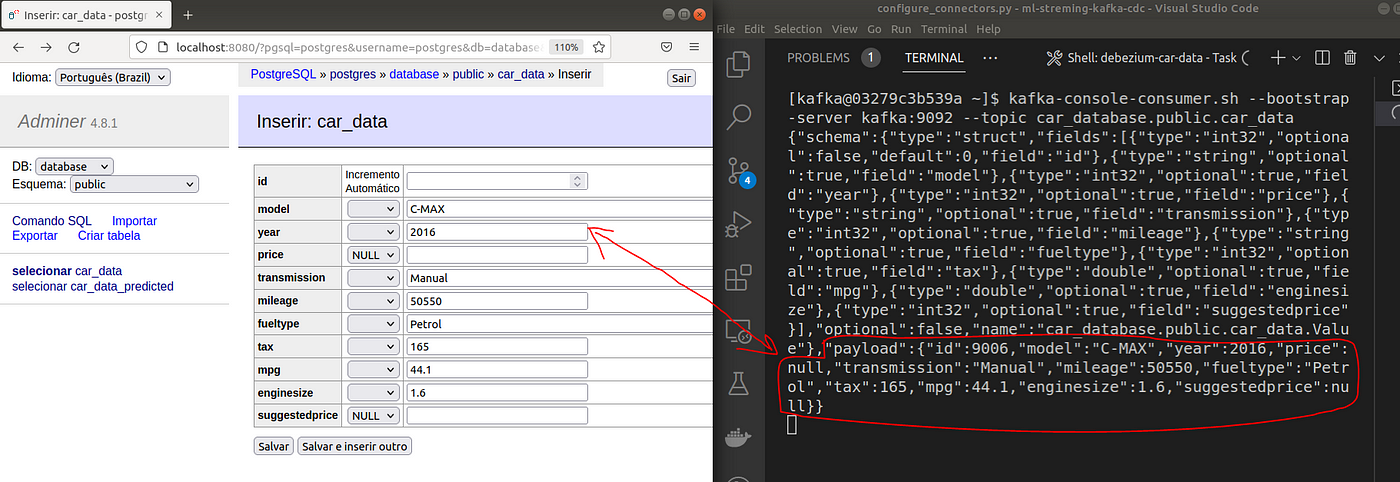
Within the picture above, on the left, we are able to see an entry that I added to the database and, on the proper, the message created on Kafka. The message is written in AVRO, which will be understood as a JSON divided into “payload” and “schema”.
The sink connector’s configuration follows the identical logic, however on this case, we additionally want to provide a reputation for our subject. Debezium will mechanically create the sink desk (if it doesn’t exist) utilizing the subject’s title, inferring the columns primarily based on the primary message despatched.
Because of this we don’t have to create a second desk in Postgres: it will likely be mechanically generated by Debezium.
Deploying our mannequin with BentoML
The subsequent factor to do is to deploy our machine studying mannequin with BentoML. That is achieved with three steps: Saving our mannequin, constructing a Bento, and reworking it right into a Docker container.
Saving a mannequin shouldn’t be so totally different from saving any file, you simply give it a reputation and persist it on disk with the save_model perform.
BentoML supplies many functionalities to monitor and model the saved fashions which can be price checking.
With the mannequin saved, we are able to construct a service to deploy it.
The educated mannequin is loaded as a runner, a particular kind of object utilized by BentoML to signify fashions. The runner is used to create a service object and, with it, we outline the /predict endpoint, answerable for receiving a document and returning its predicted value.
The very last thing to do earlier than deploying our mannequin is to outline a bentofile, a particular configuration file utilized by BentoML to explain the deployment setting.
Then, by working the instructions beneath, we create a Docker picture with our service named ford_price_predictor:1.0.0.
bentoml construct --version 1.0.0
bentoml containerize ford_price_predictor:1.0.0
Lastly, we are able to begin a container occasion of our service.
docker run -p 3000:3000 ford_price_predictor:1.0.0
And work together with it by accessing localhost:3000.
Connecting Stream and Mannequin
Proper now, we’ve the 2 most important elements of our pipeline constructed, all that rests is to attach them, and this can be achieved utilizing a python script.
On one facet, Debezium streams knowledge to the Kafka subject car_database.public.car_data and waits for messages in car_data_predicted. On the opposite, the BentoML service is deployed and ready for predictions on the endpoint /predictions.
To connect with Kafka, we gonna use the confluent_kafka package deal, and to connect with the deployed mannequin, the requests package deal.
Subsequent, we outline the Kafka subjects and the bento service URL.
The URLs will not be localhost as a result of this script will run inside one other container.
Then, a Kafka shopper is created for the supply subject and a producer for the sink subject.
The patron retrieves one message at a time from the supply subject. Then, simply the required fields to make a prediction are extracted from every message.
The message is distributed to the machine studying mannequin through a POST request, that returns the anticipated value.
Lastly, the anticipated value is added to the unique message so the producer can ship it to the sink subject.
Debezium will learn this new message and create the respective document within the database.
And we are able to name it a day!
Seeing it working
It’s lastly time to see our undertaking working 
Sadly, I don’t have a elaborate app to check our pipeline, so we’re going to do it by interacting instantly with the database.
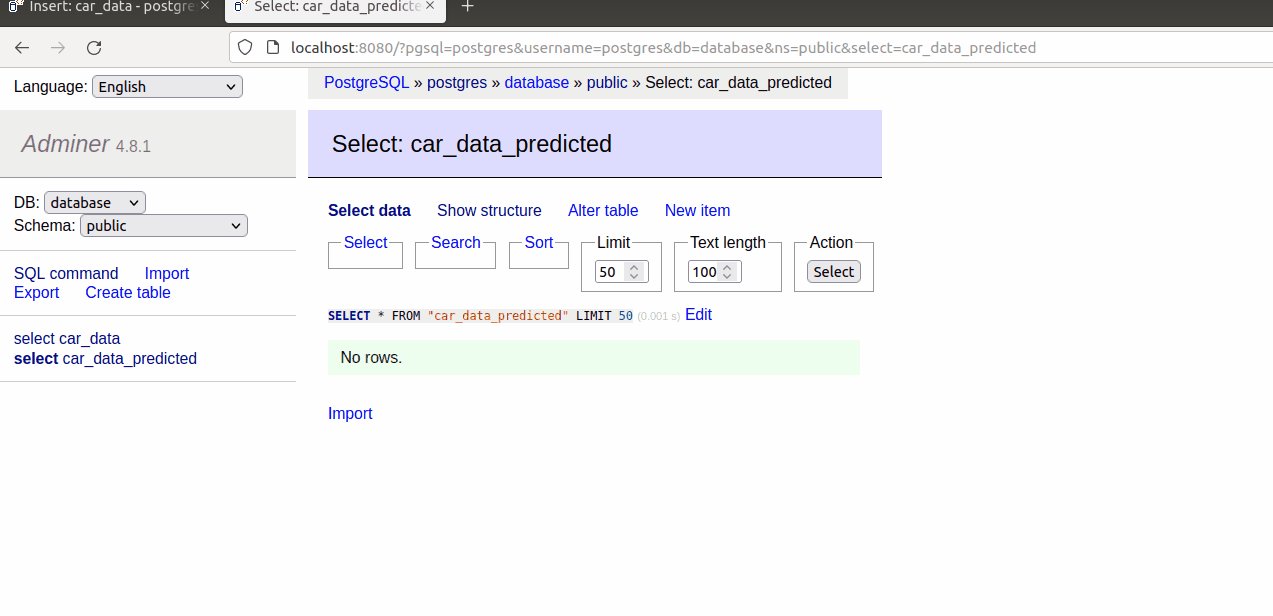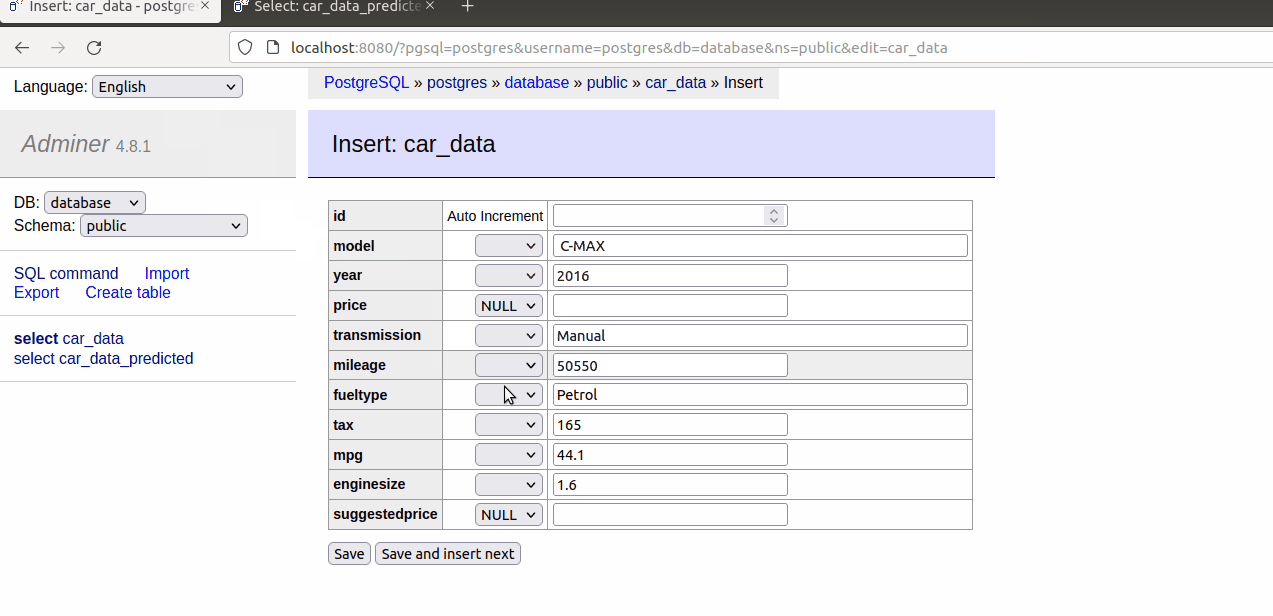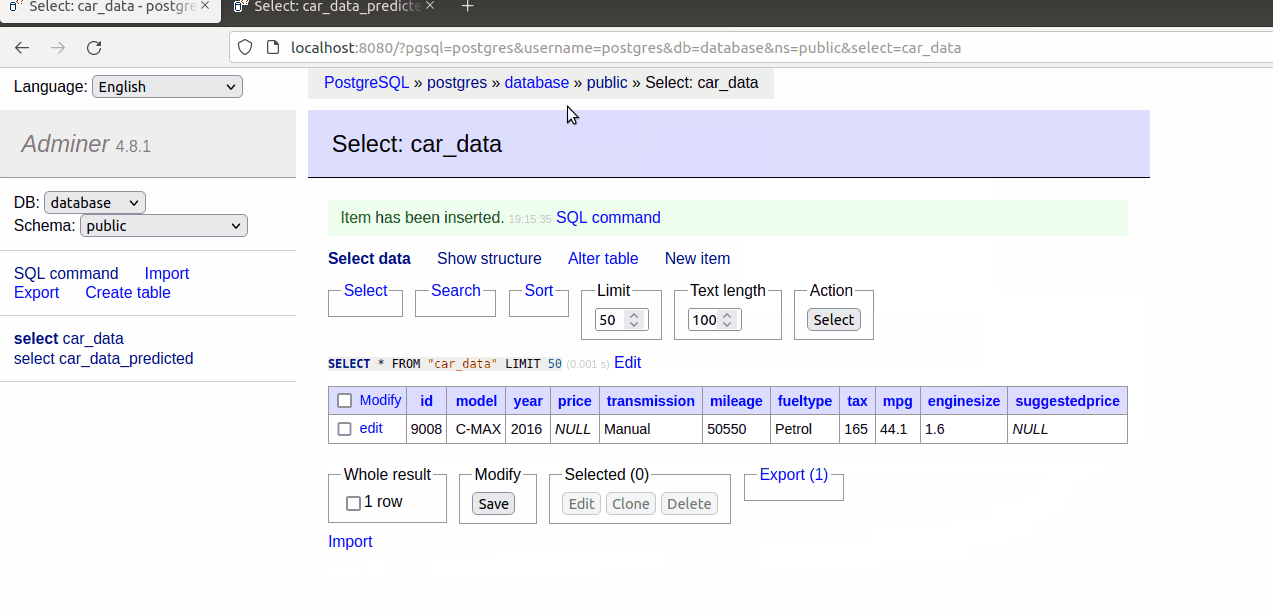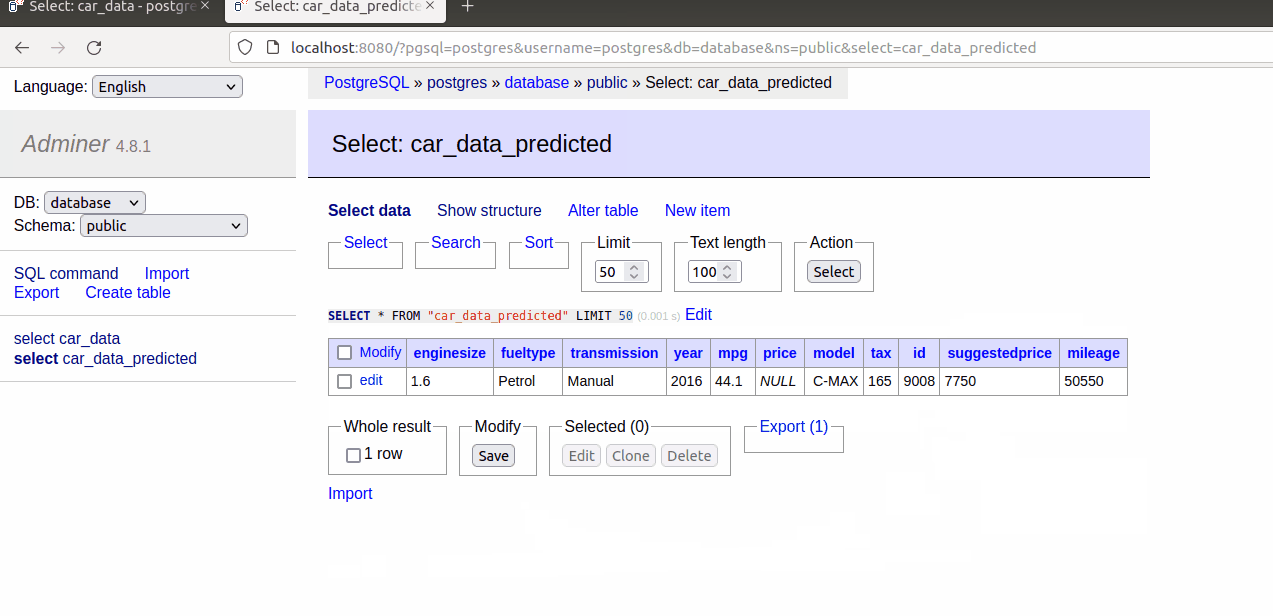
As we are able to see within the gif, when a brand new document is added within the car_data, one other is mechanically created within the car_data_predicetd desk with the recommended value.
If we hold including increasingly information within the car_data desk.
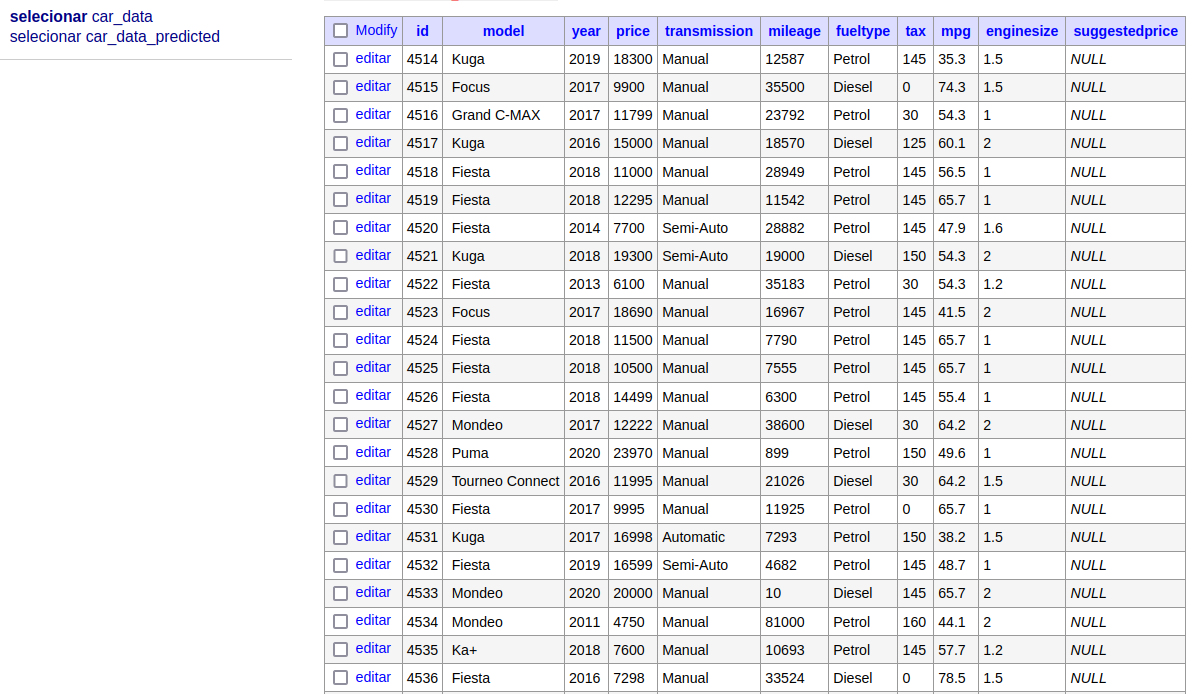
They are going to be duplicated within the car_data_predicted desk with the recommended value.
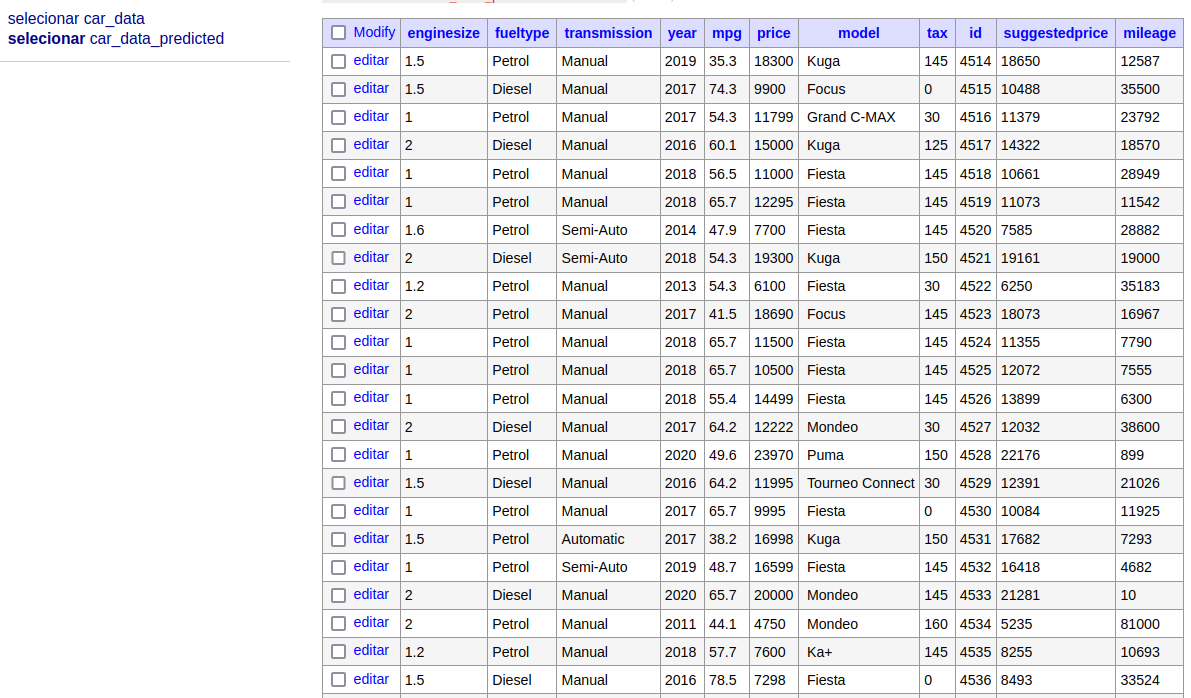
In abstract, it’s working!
Placing a Machine Studying undertaking to life shouldn’t be a easy process and, identical to some other software program product, it requires many alternative varieties of data: infrastructure, enterprise, knowledge science, and so on.
I need to confess that, for a very long time, I simply uncared for the infrastructure half, making my tasks relaxation in peace inside Jupiter notebooks. However as quickly as I began studying it, I noticed that could be a very fascinating subject.
Machine studying remains to be a rising discipline and, as compared with different IT-related areas like Net growth, the group nonetheless has quite a bit to study. Fortunately, within the final years we’ve seen a number of new applied sciences come up to assist us construct an ML software, like Mlflow, Apache Spark’s Mlib, and BentoML, explored on this submit.
On this submit, a machine studying structure is explored with a few of these applied sciences to construct a real-time value recommender system. To carry this idea to life, we would have liked not solely ML-related instruments (BentoML & Scikit-learn) but in addition different software program items (Postgres, Debezium, Kafka).
After all, this can be a easy undertaking that doesn’t also have a person interface, however the ideas explored on this submit could possibly be simply prolonged to many instances and actual situations.
I hope this submit helped you one way or the other, I’m not an professional in any of the themes mentioned, and I strongly suggest additional studying (see some references beneath).
Thanks for studying! 
All of the code is obtainable in this GitHub repository.
[1] Debezium official docs
[2] Jiri Pechanec (2017), Streaming knowledge to a downstream database — Debezium Weblog
[3] Bentoml API I/O descriptors — BentoML Docs
[4] BentoML ideas — BentoML Docs
[5] Kai Waehner (2020), Streaming Machine Studying with Kafka-native Mannequin Deployment — Kai Waehner
[6] Tim Liu, Why Do Individuals Say It’s So Exhausting To Deploy A ML Mannequin To Manufacturing? — BentoML weblog
[7] Debezium examples — Debezium official repository on Github
[8] Ben Dickson (2022), GitHub Copilot is among the many first actual merchandise primarily based on massive language fashions — Tech Talks
[9] Ford Used Automobile Itemizing, CC0: Public Area — Kaggle
