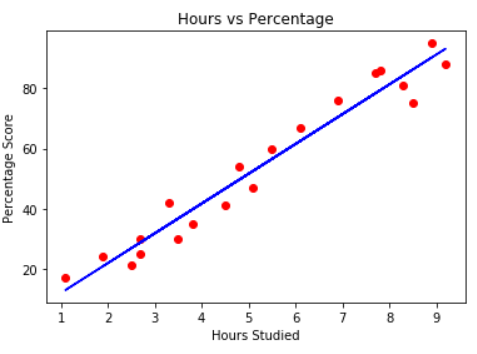
Sign in Welcome! Log into your account your username your password Forgot your password? Get help Password recovery Recover your password your email A password will be e-mailed to you. HomeProgrammingLinear Regression in Python with Scikit-Study Programming Linear Regression in Python with Scikit-Study By Admin June 21, 2022 0 1 Share FacebookTwitterPinterestWhatsApp Should you had studied longer, would your general scores get any higher? A method of answering this query is by having information on how lengthy you studied for and what scores you bought. We are able to then attempt to see if there’s a sample in that information, and if in that sample, whenever you add to the hours, it additionally finally ends up including to the scores share. As an illustration, say you’ve gotten an hour-score dataset, which incorporates entries akin to 1.5h and 87.5% rating. It may additionally include 1.61h, 2.32h and 78%, 97% scores. The type of information kind that may have any intermediate worth (or any degree of ‘granularity’) is named steady information. One other state of affairs is that you’ve an hour-score dataset which incorporates letter-based grades as an alternative of number-based grades, akin to A, B or C. Grades are clear values that may be remoted, since you may’t have an A.23, A+++++++++++ (and to infinity) or A * e^12. The type of information kind that can’t be partitioned or outlined extra granularly is named discrete information. Based mostly on the modality (kind) of your information – to determine what rating you’d get primarily based in your research time – you will carry out regression or classification. Regression is carried out on steady information, whereas classification is carried out on discrete information. Regression could be something from predicting somebody’s age, the home of a worth, or worth of any variable. Classification contains predicting what class one thing belongs to (akin to whether or not a tumor is benign or malignant). Notice: Predicting home costs and whether or not a most cancers is current isn’t any small process, and each sometimes embody non-linear relationships. Linear relationships are pretty easy to mannequin, as you will see in a second. If you wish to study via real-world, example-led, sensible tasks, try our “Fingers-On Home Worth Prediction – Machine Studying in Python” and our research-grade “Breast Most cancers Classification with Deep Studying – Keras and Tensorflow”! For each regression and classification – we’ll use information to foretell labels (umbrella-term for the goal variables). Labels could be something from “B” (class) for classification duties to 123 (quantity) for regression duties. As a result of we’re additionally supplying the labels – these are supervised studying algorithms. On this beginner-oriented information – we’ll be performing linear regression in Python, using the Scikit-Study library. We’ll undergo an end-to-end machine studying pipeline. We’ll first load the info we’ll be studying from and visualizing it, on the identical time performing Exploratory Knowledge Evaluation. Then, we’ll pre-process the info and construct fashions to suit it (like a glove). This mannequin is then evaluated, and if favorable, used to foretell new values primarily based on new enter. Exploratory Knowledge Evaluation Notice: You possibly can obtain the hour-score dataset right here. Let’s begin with exploratory information evaluation. You wish to get to know your information first – this contains loading it in, visualizing options, exploring their relationships and making hypotheses primarily based in your observations. The dataset is a CSV (comma-separated values) file, which incorporates the hours studied and the scores obtained primarily based on these hours. We’ll load the info right into a DataFrame utilizing Pandas: import pandas as pd Should you’re new to Pandas and DataFrames, learn our “Information to Python with Pandas: DataFrame Tutorial with Examples”! Let’s learn the CSV file and package deal it right into a DataFrame: path_to_file = 'house/tasks/datasets/student_scores.csv' df = pd.read_csv(path_to_file) As soon as the info is loaded in, let’s take a fast peek on the first 5 values utilizing the head() technique: df.head() This ends in: Hours Scores 0 2.5 21 1 5.1 47 2 3.2 27 3 8.5 75 4 3.5 30 We are able to additionally test the form of our dataset through the form property: df.form Realizing the form of your information is mostly fairly essential to having the ability to each analyze it and construct fashions round it: (25, 2) We have now 25 rows and a pair of columns – that is 25 entries containing a pair of an hour and a rating. Our preliminary query was whether or not we would rating a better rating if we would studied longer. In essence, we’re asking for the connection between Hours and Scores. So, what is the relationship between these variables? An effective way to discover relationships between variables is thru Scatterplots. We’ll plot the hours on the X-axis and scores on the Y-axis, and for every pair, a marker shall be positioned primarily based on their values: df.plot.scatter(x='Hours', y='Scores', title='Scatterplot of hours and scores percentages'); Should you’re new to Scatter Plots – learn our “Matplotlib Scatter Plot – Tutorial and Examples”! This ends in: Because the hours improve, so do the scores. There is a pretty excessive optimistic correlation right here! Because the form of the road the factors are making seems to be straight – we are saying that there is a optimistic linear correlation between the Hours and Scores variables. How correlated are they? The corr() technique calculates and shows the correlations between numerical variables in a DataFrame: print(df.corr()) Hours Scores Hours 1.000000 0.976191 Scores 0.976191 1.000000 On this desk, Hours and Hours have a 1.0 (100%) correlation, simply as Scores have a 100% correlation to Scores, naturally. Any variable could have a 1:1 mapping with itself! Nonetheless, the correlation between Scores and Hours is 0.97. Something above 0.8 is taken into account to be a powerful optimistic correlation. If you would like to learn extra about correlation between linear variables intimately, in addition to totally different correlation coefficients, learn our “Calculating Pearson Correlation Coefficient in Python with Numpy”! Having a excessive linear correlation implies that we’ll typically have the ability to inform the worth of 1 characteristic, primarily based on the opposite. Even with out calculation, you may inform that if somebody research for five hours, they will get round 50% as their rating. Since this relationship is de facto robust – we’ll have the ability to construct a easy but correct linear regression algorithm to foretell the rating primarily based on the research time, on this dataset. When we have now a linear relationship between two variables, we shall be taking a look at a line. When there’s a linear relationship between three, 4, 5 (or extra) variables, we shall be taking a look at an intersecction of planes. In each case, this type of high quality is outlined in algebra as linearity. Pandas additionally ships with an awesome helper technique for statistical summaries, and we are able to describe() the dataset to get an thought of the imply, most, minimal, and so forth. values of our columns: print(df.describe()) Hours Scores depend 25.000000 25.000000 imply 5.012000 51.480000 std 2.525094 25.286887 min 1.100000 17.000000 25% 2.700000 30.000000 50% 4.800000 47.000000 75% 7.400000 75.000000 max 9.200000 95.000000 Linear Regression Concept Our variables categorical a linear relationship. We are able to intuitively guesstimate the rating share primarily based on the variety of hours studied. Nonetheless, can we outline a extra formal approach to do that? We may hint a line in between our factors and browse the worth of “Rating” if we hint a vertical line from a given worth of “Hours”: The equation that describes any straight line is:$$y = a*x+b$$On this equation, y represents the rating share, x symbolize the hours studied. b is the place the road begins on the Y-axis, additionally referred to as the Y-axis intercept and a defines if the road goes to be extra in the direction of the higher or decrease a part of the graph (the angle of the road), so it’s referred to as the slope of the road. By adjusting the slope and intercept of the road, we are able to transfer it in any course. Thus – by determining the slope and intercept values, we are able to alter a line to suit our information! That is it! That is the center of linear regression and an algorithm actually solely figures out the values of the slope and intercept. It makes use of the values of x and y that we have already got and varies the values of a and b. By doing that, it matches a number of traces to the info factors and returns the road that’s nearer to all the info factors, or the greatest becoming line. By modelling that linear relationship, our regression algorithm can also be referred to as a mannequin. On this course of, after we attempt to decide, or predict the share primarily based on the hours, it implies that our y variable depends upon the values of our x variable. Notice: In Statistics, it’s customary to name y the dependent variable, and x the unbiased variable. In Pc Science, y is often referred to as goal, label, and x characteristic, or attribute. You will note that the names interchange, take into account that there’s often a variable that we wish to predict and one other used to search out it is worth. It is also a conference to make use of capitalized X as an alternative of decrease case, in each Statistics and CS. Linear Regression with Python’s Scikit-learn With the idea underneath our belts – let’s get to implementing a Linear Regression algorithm with Python and the Scikit-Study library! We’ll begin with an easier linear regression after which develop onto a number of linear regression with a brand new dataset. Knowledge Preprocessing Within the the earlier part, we have now already imported Pandas, loaded our file right into a DataFrame and plotted a graph to see if there was a sign of a linear relationship. Now, we are able to divide our information two arrays – one for the dependent characteristic and one for the unbiased, or goal characteristic. Since we wish to predict the rating share relying on the hours studied, our y would be the “Rating” column and our X will the “Hours” column. To separate the goal and options, we are able to attribute the dataframe column values to our y and X variables: y = df['Scores'].values.reshape(-1, 1) X = df['Hours'].values.reshape(-1, 1) Notice: df['Column_Name'] returns a pandas Collection. Some libraries can work on a Collection simply as they’d on a NumPy array, however not all libraries have this consciousness. In some instances, you will wish to extract the underlying NumPy array that describes your information. That is simply carried out through the values area of the Collection. Scikit-Study’s linear regression mannequin expects a 2D enter, and we’re actually providing a 1D array if we simply extract the values: print(df['Hours'].values) print(df['Hours'].values.form) It is count on a 2D enter as a result of the LinearRegression() class (extra on it later) expects entries that will include greater than a single worth (however can be a single worth). In both case – it needs to be a 2D array, the place every component (hour) is definitely a 1-element array: print(X.form) print(X) Take a look at our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and truly study it! We may already feed our X and y information on to our linear regression mannequin, but when we use all of our information without delay, how can we all know if our outcomes are any good? Identical to in studying, what we’ll do, is use part of the info to practice our mannequin and one other a part of it, to check it. If you would like to learn extra concerning the guidelines of thumb, significance of splitting units, validation units and the train_test_split() helper technique, learn our detailed information on “Scikit-Study’s train_test_split() – Coaching, Testing and Validation Units”! That is simply achieved via the helper train_test_split() technique, which accepts our X and y arrays (additionally works on DataFrames and splits a single DataFrame into coaching and testing units), and a test_size. The test_size is the share of the general information we’ll be utilizing for testing: from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2) The strategy randomly takes samples respecting the share we have outlined, however respects the X-y pairs, lest the sampling would completely combine up the connection. Some widespread train-test splits are 80/20 and 70/30. Because the sampling course of is inherently random, we’ll all the time have totally different outcomes when working the tactic. To have the ability to have the identical outcomes, or reproducible outcomes, we are able to outline a relentless referred to as SEED that has the worth of the that means of life (42): SEED = 42 Notice: The seed could be any integer, and is used because the seed for the random sampler. The seed is often random, netting totally different outcomes. Nonetheless, for those who set it manually, the sampler will return the identical outcomes. It is conference to make use of 42 because the seed as a reference to the favored novel sequence “The Hitchhiker’s Information to the Galaxy”. We are able to then go that SEEDto the random_state parameter of our train_test_split technique: X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = SEED) Now, for those who print your X_train array – you will discover the research hours, and y_train incorporates the rating percentages: print(X_train) print(y_train) Coaching a Linear Regression Mannequin We have now our practice and check units prepared. Scikit-Study has a plethora of mannequin varieties we are able to simply import and practice, LinearRegression being one among them: from sklearn.linear_model import LinearRegression regressor = LinearRegression() Now, we have to match the road to our information, we’ll do this through the use of the .match() technique together with our X_train and y_train information: regressor.match(X_train, y_train) If no errors are thrown – the regressor discovered the most effective becoming line! The road is outlined by our options and the intercept/slope. In truth, we are able to examine the intercept and slope by printing the regressor.intecept_ and regressor.coef_ attributes, respectively: print(regressor.intercept_) 2.82689235 For retrieving the slope (which can also be the coefficient of x): print(regressor.coef_) The outcome must be: [9.68207815] This may fairly actually be plugged in into our system from earlier than: $$rating = 9.68207815*hours+2.82689235$$ Let’s test actual fast whether or not this aligns with our guesstimation: h o u r s = 5 s c o r e = 9.68207815 ∗ h o u r s + 2.82689235 s c o r e = 51.2672831 With 5 hours of research, you may count on round 51% as a rating! One other option to interpret the intercept worth is – if a scholar research one hour greater than they beforehand studied for an examination, they will count on to have a rise of 9.68% contemplating the rating share that they’d beforehand achieved. In different phrases, the slope worth reveals what occurs to the dependent variable each time there’s an improve (or lower) of one unit of the unbiased variable. Making Predictions To keep away from working calculations ourselves, we may write our personal system that calculates the worth: def calc(slope, intercept, hours): return slope*hours+intercept rating = calc(regressor.coef_, regressor.intercept_, 9.5) print(rating) Nonetheless – a a lot handier option to predict new values utilizing our mannequin is to name on the predict() operate: rating = regressor.predict([[9.5]]) print(rating) Our result’s 94.80663482, or roughly 95%. Now we have now a rating share estimate for each hours we are able to consider. However can we belief these estimates? Within the reply to that query is the explanation why we break up the info into practice and check within the first place. Now we are able to predict utilizing our check information and examine the expected with our precise outcomes – the floor reality outcomes. To make predictions on the check information, we go the X_test values to the predict() technique. We are able to assign the outcomes to the variable y_pred: y_pred = regressor.predict(X_test) The y_pred variable now incorporates all the expected values for the enter values within the X_test. We are able to now examine the precise output values for X_test with the expected values, by arranging them aspect by aspect in a dataframe construction: df_preds = pd.DataFrame({'Precise': y_test.squeeze(), 'Predicted': y_pred.squeeze()}) print(df_preds The output appears to be like like this: Precise Predicted 0 81 83.188141 1 30 27.032088 2 21 27.032088 3 76 69.633232 4 62 59.951153 Although our mannequin appears to not be very exact, the expected percentages are near the precise ones. Let’s quantify the distinction between the precise and predicted values to realize an goal view of the way it’s truly performing. Evaluating the Mannequin After trying on the information, seeing a linear relationship, coaching and testing our mannequin, we are able to perceive how properly it predicts through the use of some metrics. For regression fashions, three analysis metrics are primarily used: Imply Absolute Error (MAE): Once we subtract the expected values from the precise values, acquiring the errors, sum absolutely the values of these errors and get their imply. This metric provides a notion of the general error for every prediction of the mannequin, the smaller (nearer to 0) the higher. $$mae = (frac{1}{n})sum_{i=1}^{n}left | Precise – Predicted proper |$$ Notice: You might also encounter the y and ŷ notation within the equations. The y refers back to the precise values and the ŷ to the expected values. Imply Squared Error (MSE): It’s much like the MAE metric, but it surely squares absolutely the values of the errors. Additionally, as with MAE, the smaller, or nearer to 0, the higher. The MSE worth is squared in order to make giant errors even bigger. One factor to pay shut consideration to, it that it’s often a tough metric to interpret as a result of measurement of its values and of the truth that they don’t seem to be in the identical scale of the info. $$mse = sum_{i=1}^{D}(Precise – Predicted)^2$$ Root Imply Squared Error (RMSE): Tries to unravel the interpretation drawback raised with the MSE by getting the sq. root of its last worth, in order to scale it again to the identical items of the info. It’s simpler to interpret and good when we have to show or present the precise worth of the info with the error. It reveals how a lot the info could fluctuate, so, if we have now an RMSE of 4.35, our mannequin could make an error both as a result of it added 4.35 to the precise worth, or wanted 4.35 to get to the precise worth. The nearer to 0, the higher as properly. $$rmse = sqrt{ sum_{i=1}^{D}(Precise – Predicted)^2}$$ We are able to use any of these three metrics to examine fashions (if we have to select one). We are able to additionally examine the identical regression mannequin with totally different argument values or with totally different information after which contemplate the analysis metrics. This is named hyperparameter tuning – tuning the hyperparameters that affect a studying algorithm and observing the outcomes. When selecting between fashions, those with the smallest errors, often carry out higher. When monitoring fashions, if the metrics obtained worse, then a earlier model of the mannequin was higher, or there was some vital alteration within the information for the mannequin to carry out worse than it was performing. Fortunately, we do not have to do any of the metrics calculations manually. The Scikit-Study package deal already comes with capabilities that can be utilized to search out out the values of those metrics for us. Let’s discover the values for these metrics utilizing our check information. First, we’ll import the mandatory modules for calculating the MAE and MSE errors. Respectively, the mean_absolute_error and mean_squared_error: from sklearn.metrics import mean_absolute_error, mean_squared_error Now, we are able to calculate the MAE and MSE by passing the y_test (precise) and y_pred (predicted) to the strategies. The RMSE could be calculated by taking the sq. root of the MSE, to to that, we’ll use NumPy’s sqrt() technique: import numpy as np For the metrics calculations: mae = mean_absolute_error(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) We will even print the metrics outcomes utilizing the f string and the two digit precision after the comma with :.2f: print(f'Imply absolute error: {mae:.2f}') print(f'Imply squared error: {mse:.2f}') print(f'Root imply squared error: {rmse:.2f}') The outcomes of the metrics will appear like this: Imply absolute error: 3.92 Imply squared error: 18.94 Root imply squared error: 4.35 All of our errors are low – and we’re lacking the precise worth by 4.35 at most (decrease or larger), which is a fairly small vary contemplating the info we have now. A number of Linear Regression Till this level, we have now predicted a price with linear regression utilizing just one variable. There’s a totally different state of affairs that we are able to contemplate, the place we are able to predict utilizing many variables as an alternative of 1, and that is additionally a way more widespread state of affairs in actual life, the place many issues can have an effect on some outcome. As an illustration, if we wish to predict the gasoline consumption in US states, it will be limiting to make use of just one variable, as an example, gasoline taxes, to do it, since extra than simply gasoline taxes impacts consumption. There are extra issues concerned within the gasoline consumption than solely gasoline taxes, such because the per capita revenue of the individuals in a sure space, the extension of paved highways, the proportion of the inhabitants that has a driver’s license, and lots of different elements. Some elements have an effect on the consumption greater than others – and here is the place correlation coefficients actually assist! In a case like this, when it is sensible to make use of a number of variables, linear regression turns into a a number of linear regression. Notice: One other nomenclature for the linear regression with one unbiased variable is univariate linear regression. And for the a number of linear regression, with many unbiased variables, is multivariate linear regression. Normally, actual world information, by having far more variables with larger values vary, or extra variability, and in addition complicated relationships between variables – will contain a number of linear regression as an alternative of a easy linear regression. That’s to say, on a day-to-day foundation, if there’s linearity in your information, you’ll most likely be making use of a a number of linear regression to your information. Exploratory Knowledge Evaluation To get a sensible sense of a number of linear regression, let’s hold working with our gasoline consumption instance, and use a dataset that has gasoline consumption information on 48 US States. Notice: You possibly can obtain the gasoline consumption dataset on Kaggle. You possibly can study extra concerning the particulars on the dataset right here. Following what we did with the linear regression, we will even wish to know our information earlier than making use of a number of linear regression. First, we are able to import the info with pandas read_csv() technique: path_to_file = 'house/tasks/datasets/petrol_consumption.csv' df = pd.read_csv(path_to_file) We are able to now check out the primary 5 rows with df.head(): df.head() This ends in: Petrol_tax Average_income Paved_Highways Population_Driver_licence(%) Petrol_Consumption 0 9.0 3571 1976 0.525 541 1 9.0 4092 1250 0.572 524 2 9.0 3865 1586 0.580 561 3 7.5 4870 2351 0.529 414 4 8.0 4399 431 0.544 410 We are able to see the what number of rows and columns our information has with form: df.form Which shows: (48, 5) On this dataset, we have now 48 rows and 5 columns. When classifying the scale of a dataset, there are additionally variations between Statistics and Pc Science. In Statistics, a dataset with greater than 30 or with greater than 100 rows (or observations) is already thought of massive, whereas in Pc Science, a dataset often has to have at the least 1,000-3,000 rows to be thought of “massive”. “Huge” can also be very subjective – some contemplate 3,000 massive, whereas some contemplate 3,000,000 massive. There isn’t any consensus on the scale of our dataset. Let’s hold exploring it and check out the descriptive statistics of this new information. This time, we’ll facilitate the comparability of the statistics by rounding up the values to 2 decimals with the spherical() technique, and transposing the desk with the T property: print(df.describe().spherical(2).T) Our desk is now column-wide as an alternative of being row-wide: depend imply std min 25% 50% 75% max Petrol_tax 48.0 7.67 0.95 5.00 7.00 7.50 8.12 10.00 Average_income 48.0 4241.83 573.62 3063.00 3739.00 4298.00 4578.75 5342.00 Paved_Highways 48.0 5565.42 3491.51 431.00 3110.25 4735.50 7156.00 17782.00 Population_Driver_licence(%) 48.0 0.57 0.06 0.45 0.53 0.56 0.60 0.72 Petrol_Consumption 48.0 576.77 111.89 344.00 509.50 568.50 632.75 968.00 Notice: The transposed desk is healthier if we wish to examine between statistics, and the unique desk is healthier if we wish to examine between variables. By trying on the min and max columns of the describe desk, we see that the minimal worth in our information is 0.45, and the utmost worth is 17,782. Because of this our information vary is 17,781.55 (17,782 – 0.45 = 17,781.55), very broad – which suggests our information variability can also be excessive. Additionally, by evaluating the values of the imply and std columns, akin to 7.67 and 0.95, 4241.83 and 573.62, and so forth., we are able to see that the means are actually removed from the usual deviations. That means our information is much from the imply, decentralized – which additionally provides to the variability. We have already got two indications that our information is unfold out, which isn’t in our favor, because it makes it tougher to have a line that may match from 0.45 to 17,782 – in statistical phrases, to clarify that variability. Both approach, it’s all the time essential that we plot the info. Knowledge with totally different shapes (relationships) can have the identical descriptive statistics. So, let’s hold going and have a look at our factors in a graph. Notice: The issue of getting information with totally different shapes which have the identical descriptive statistics is outlined as Anscombe’s Quartet. You possibly can see examples of it right here. One other instance of a coefficient being the identical between differing relationships is Pearson Correlation (which checks for linear correlation): This information clearly has a sample! Although, it is non-linear, and the info does not have linear correlation, thus, Pearson’s Coefficient is 0 for many of them. It could be 0 for random noise as properly. Once more, for those who’re focused on studying extra about Pearson’s Coefficient, learn out in-depth “Calculating Pearson Correlation Coefficient in Python with Numpy”! In our easy regression state of affairs, we have used a scatterplot of the dependent and unbiased variables to see if the form of the factors was near a line. In out present state of affairs, we have now 4 unbiased variables and one dependent variable. To do a scatterplot with all of the variables would require one dimension per variable, leading to a 5D plot. We may create a 5D plot with all of the variables, which might take some time and be somewhat onerous to learn – or we may plot one scatterplot for every of our unbiased variables and dependent variable to see if there is a linear relationship between them. Following Ockham’s razor (also referred to as Occam’s razor) and Python’s PEP20 – “easy is healthier than complicated” – we’ll create a for loop with a plot for every variable. Notice: Ockham’s/Occam’s razor is a philosophical and scientific precept that states that the best concept or clarification is to be most popular in regard to complicated theories or explanations. This time, we’ll use Seaborn, an extension of Matplotlib which Pandas makes use of underneath the hood when plotting: import seaborn as sns variables = ['Petrol_tax', 'Average_income', 'Paved_Highways','Population_Driver_licence(%)'] for var in variables: plt.determine() sns.regplot(x=var, y='Petrol_Consumption', information=df).set(title=f'Regression plot of {var} and Petrol Consumption'); Discover within the above code, that we’re importing Seaborn, creating an inventory of the variables we wish to plot, and looping via that checklist to plot every unbiased variable with our dependent variable. The Seaborn plot we’re utilizing is regplot, which is brief from regression plot. It’s a scatterplot that already plots the scattered information together with the regression line. Should you’d quite have a look at a scatterplot with out the regression line, use sns.scatteplot as an alternative. These are our 4 plots: When trying on the regplots, it appears the Petrol_tax and Average_income have a weak destructive linear relationship with Petrol_Consumption. It additionally appears that the Population_Driver_license(%) has a powerful optimistic linear relationship with Petrol_Consumption, and that the Paved_Highways variable has no relationship with Petrol_Consumption. We are able to additionally calculate the correlation of the brand new variables, this time utilizing Seaborn’s heatmap() to assist us spot the strongest and weaker correlations primarily based on hotter (reds) and cooler (blues) tones: correlations = df.corr() sns.heatmap(correlations, annot=True).set(title='Heatmap of Consumption Knowledge - Pearson Correlations'); Plainly the heatmap corroborates our earlier evaluation! Petrol_tax and Average_income have a weak destructive linear relationship of, respectively, -0.45 and -0.24 with Petrol_Consumption. Population_Driver_license(%) has a powerful optimistic linear relationship of 0.7 with Petrol_Consumption, and Paved_Highways correlation is of 0.019 – which signifies no relationship with Petrol_Consumption. The correlation does not suggest causation, however we’d discover causation if we are able to efficiently clarify the phenomena with our regression mannequin. One other essential factor to note within the regplots is that there are some factors actually far off from the place most factors focus, we had been already anticipating one thing like that after the large distinction between the imply and std columns – these factors is likely to be information outliers and excessive values. Notice: Outliers and excessive values have totally different definitions. Whereas outliers do not comply with the pure course of the info, and drift away from the form it makes – excessive values are in the identical course as different factors however are both too excessive or too low in that course, far off to the extremes within the graph. A linear regression mannequin, both uni or multivariate, will take these outlier and excessive values under consideration when figuring out the slope and coefficients of the regression line. Contemplating what the already know of the linear regression system: $$rating = 9.68207815*hours+2.82689235$$ If we have now an outlier level of 200 hours, that may have been a typing error – it’s going to nonetheless be used to calculate the ultimate rating: $$rating = 9.68207815*200+2.82689235 rating = 1939.24252235$$ Only one outlier could make our slope worth 200 instances larger. The identical holds for a number of linear regression. The a number of linear regression system is mainly an extension of the linear regression system with extra slope values: $$y = b_0 + b_1 * x_1 + b_2 * x_2 + b_3 * x_3 + ldots + b_n * x_n$$ The primary distinction between this system from our earlier one, is thtat it describes as aircraft, as an alternative of describing a line. We all know have bn * xn coefficients as an alternative of only a * x. Notice: There’s an error added to the top of the a number of linear regression system, which is an error between predicted and precise values – or residual error. This error often is so small, it’s ommitted from most formulation: $$y = b_0 + b_1 * x_1 + b_2 * x_2 + b_3 * x_3 + ldots + b_n * x_n + epsilon$$ In the identical approach, if we have now an excessive worth of 17,000, it’s going to find yourself making our slope 17,000 larger: $$y = b_0 + 17,000 * x_1 + b_2 * x_2 + b_3 * x_3 + ldots + b_n * x_n$$ In different phrases, univariate and multivariate linear fashions are delicate to outliers and excessive information values. Notice: It’s past the scope of this information, however you may go additional within the information evaluation and information preparation for the mannequin by taking a look at boxplots, treating outliers and excessive values. If you would like to study extra about Violin Plots and Field Plots – learn our Field Plot and Violin Plot guides! We have now discovered so much about linear fashions and exploratory information evaluation, now it is time to use the Average_income, Paved_Highways, Population_Driver_license(%) and Petrol_tax as unbiased variables of our mannequin and see what occurs. Making ready the Knowledge Following what has been carried out with the easy linear regression, after loading and exploring the info, we are able to divide it into options and targets. The primary distinction is that now our options have 4 columns as an alternative of 1. We are able to use double brackets [[ ]] to pick them from the dataframe: y = df['Petrol_Consumption'] X = df[['Average_income', 'Paved_Highways', 'Population_Driver_licence(%)', 'Petrol_tax']] After setting our X and y units, we are able to divide our information into practice and check units. We shall be utilizing the identical seed and 20% of our information for coaching: X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=SEED) Coaching the Multivariate Mannequin After splitting the info, we are able to practice our a number of regression mannequin. Discover that now there isn’t a have to reshape our X information, as soon as it already has multiple dimension: X.form To coach our mannequin we are able to execute the identical code as earlier than, and use the match() technique of the LinearRegression class: regressor = LinearRegression() regressor.match(X_train, y_train) After becoming the mannequin and discovering our optimum answer, we are able to additionally have a look at the intercept: regressor.intercept_ 361.45087906668397 And on the coefficients of the options regressor.coef_ [-5.65355145e-02, -4.38217137e-03, 1.34686930e+03, -3.69937459e+01] These 4 values are the coefficients for every of our options in the identical order as we have now them in our X information. To see an inventory with their names, we are able to use the dataframe columns attribute: feature_names = X.columns That code will output: ['Average_income', 'Paved_Highways', 'Population_Driver_licence(%)', 'Petrol_tax'] Contemplating it’s a little onerous to see each options and coefficients collectively like this, we are able to higher manage them in a desk format. To do this, we are able to assign our column names to a feature_names variable, and our coefficients to a model_coefficients variable. After that, we are able to create a dataframe with our options as an index and our coefficients as column values referred to as coefficients_df: feature_names = X.columns model_coefficients = regressor.coef_ coefficients_df = pd.DataFrame(information = model_coefficients, index = feature_names, columns = ['Coefficient value']) print(coefficients_df) The ultimate DataFrame ought to appear like this: Coefficient worth Average_income -0.056536 Paved_Highways -0.004382 Population_Driver_licence(%) 1346.869298 Petrol_tax -36.993746 If within the linear regression mannequin, we had 1 variable and 1 coefficient, now within the a number of linear regression mannequin, we have now 4 variables and 4 coefficients. What can these coefficients imply? Following the identical interpretation of the coefficients of the linear regression, which means that for a unit improve within the common revenue, there’s a lower of 0.06 {dollars} in gasoline consumption. Equally, for a unit improve in paved highways, there’s a 0.004 descrease in miles of gasoline consumption; and for a unit improve within the proportion of inhabitants with a drivers license, there is a rise of 1,346 billion gallons of gasoline consumption. And, lastly, for a unit improve in petrol tax, there’s a lower of 36,993 million gallons in gasoline consumption. By trying on the coefficients dataframe, we are able to additionally see that, in accordance with our mannequin, the Average_income and Paved_Highways options are those which might be nearer to 0, which suggests they’ve have the least impression on the gasoline consumption. Whereas the Population_Driver_license(%) and Petrol_tax, with the coefficients of 1,346.86 and -36.99, respectively, have the largest impression on our goal prediction. In different phrases, the gasoline consumption is generally defined by the share of the inhabitants with driver’s license and the petrol tax quantity, surprisingly (or unsurprisingly) sufficient. We are able to see how this outcome has a connection to what we had seen within the correlation heatmap. The motive force’s license percentual had the strongest correlation, so it was anticipated that it may assist clarify the gasoline consumption, and the petrol tax had a weak destructive correlation – however, when in comparison with the typical revenue that additionally had a weak destructive correlation – it was the destructive correlation which was closest to -1 and ended up explaining the mannequin. When all of the values had been added to the a number of regression system, the paved highways and common revenue slopes ended up becaming nearer to 0, whereas the driving force’s license percentual and the tax revenue obtained additional away from 0. So these variables had been taken extra into consideration when discovering the most effective fitted line. Notice: In information science we deal principally with hypotesis and uncertainties. The isn’t any 100% certainty and there is all the time an error. You probably have 0 errors or 100% scores, get suspicious. We have now skilled just one mannequin with a pattern of information, it’s too quickly to imagine that we have now a last outcome. To go additional, you may carry out residual analysys, practice the mannequin with totally different samples utilizing a cross validation method. You would additionally get extra information and extra variables to discover and plug within the mannequin to check outcomes. It appears our evaluation is making sense to date. Now it’s time to decide if our present mannequin is susceptible to errors. Making Predictions with the Multivariate Regression Mannequin To grasp if and the way our mannequin is making errors, we are able to predict the gasoline consumption utilizing our check information after which have a look at our metrics to have the ability to inform how properly our mannequin is behaving. In the identical approach we had carried out for the easy regression mannequin, let’s predict with the check information: y_pred = regressor.predict(X_test) Now, that we have now our check predictions, we are able to higher examine them with the precise output values for X_test by organizing them in a DataFrameformat: outcomes = pd.DataFrame({'Precise': y_test, 'Predicted': y_pred}) print(outcomes) The output ought to appear like this: Precise Predicted 27 631 606.692665 40 587 673.779442 26 577 584.991490 43 591 563.536910 24 460 519.058672 37 704 643.461003 12 525 572.897614 19 640 687.077036 4 410 547.609366 25 566 530.037630 Right here, we have now the index of the row of every check information, a column for its precise worth and one other for its predicted values. Once we have a look at the distinction between the precise and predicted values, akin to between 631 and 607, which is 24, or between 587 and 674, that’s -87 it appears there is a long way between each values, however is that distance an excessive amount of? Evaluating the Multivariate Mannequin After exploring, coaching and taking a look at our mannequin predictions – our last step is to judge the efficiency of our a number of linear regression. We wish to perceive if our predicted values are too removed from our precise values. We’ll do that in the identical approach we had beforehand carried out, by calculating the MAE, MSE and RMSE metrics. So, let’s execute the next code: mae = mean_absolute_error(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) print(f'Imply absolute error: {mae:.2f}') print(f'Imply squared error: {mse:.2f}') print(f'Root imply squared error: {rmse:.2f}') The output of our metrics must be: Imply absolute error: 53.47 Imply squared error: 4083.26 Root imply squared error: 63.90 We are able to see that the worth of the RMSE is 63.90, which implies that our mannequin may get its prediction incorrect by including or subtracting 63.90 from the precise worth. It could be higher to have this error nearer to 0, and 63.90 is a giant quantity – this means that our mannequin won’t be predicting very properly. Our MAE can also be distant from 0. We are able to see a major distinction in magnitude when evaluating to our earlier easy regression the place we had a greater outcome. To dig additional into what is occurring to our mannequin, we are able to have a look at a metric that measures the mannequin differently, it does not contemplate our particular person information values akin to MSE, RMSE and MAE, however takes a extra basic strategy to the error, the R2: $$R^2 = 1 – frac{sum(Precise – Predicted)^2}{sum(Precise – Precise Imply)^2}$$ The R2 does not inform us about how far or shut every predicted worth is from the actual information – it tells us how a lot of our goal is being captured by our mannequin. In different phrases, R2 quantifies how a lot of the variance of the dependent variable is being defined by the mannequin. The R2 metric varies from 0% to 100%. The nearer to 100%, the higher. If the R2 worth is destructive, it means it does not clarify the goal in any respect. We are able to calculate R2 in Python to get a greater understanding of the way it works: actual_minus_predicted = sum((y_test - y_pred)**2) actual_minus_actual_mean = sum((y_test - y_test.imply())**2) r2 = 1 - actual_minus_predicted/actual_minus_actual_mean print('R²:', r2) R²: 0.39136640014305457 R2 additionally comes carried out by default into the rating technique of Scikit-Study’s linear regressor class. We are able to calculate it like this: regressor.rating(X_test, y_test) This ends in: 0.39136640014305457 To date, evidently our present mannequin explains solely 39% of our check information which isn’t a superb outcome, it means it leaves 61% of the check information unexplained. Let’s additionally perceive how a lot our mannequin explains of our practice information: regressor.rating(X_train, y_train) Which outputs: 0.7068781342155135 We have now discovered a problem with our mannequin. It explains 70% of the practice information, however solely 39% of our check information, which is extra essential to get proper than our practice information. It’s becoming the practice information very well, and never having the ability to match the check information – which suggests, we have now an overfitted a number of linear regression mannequin. There are numerous elements that will have contributed to this, a number of of them may very well be: Want for extra information: we have now just one 12 months value of information (and solely 48 rows), which is not that a lot, whereas having a number of years of information may have helped enhance the prediction outcomes fairly a bit. Overcome overfitting: we are able to use a cross validation that may match our mannequin to totally different shuffled samples of our dataset to attempt to finish overfitting. Assumptions that do not maintain: we have now made the idea that the info had a linear relationship, however that may not be the case. Visualizing the info utilizing boxplots, understanding the info distribution, treating the outliers, and normalizing it might assist with that. Poor options: we’d want different or extra options which have strongest relationships with values we are attempting to foretell. Conclusion On this article we have now studied one of the vital basic machine studying algorithms i.e. linear regression. We carried out each easy linear regression and a number of linear regression with the assistance of the Scikit-learn machine studying library. Share FacebookTwitterPinterestWhatsApp Previous articleAndroid Linked To WiFi However No Web (2022)Next articleGoogle Pixel 7: Every little thing we all know to this point Adminhttps://www.handla.it RELATED ARTICLES Programming How you can Turn into a Software program Developer Quick? June 21, 2022 Programming An Engineer’s Subject Information to Nice Technical Writing (Ep. 455) June 21, 2022 Programming What Apple’s WWDC 2022 means for builders June 20, 2022 LEAVE A REPLY Cancel reply Comment: Please enter your comment! Name:* Please enter your name here Email:* You have entered an incorrect email address! Please enter your email address here Website: Save my name, email, and website in this browser for the next time I comment. - Advertisment - Most Popular Google Pixel 7: Every little thing we all know to this point June 21, 2022 Android Linked To WiFi However No Web (2022) June 21, 2022 plugins – What snippet do I must kind to indicate my ACF discipline present up on my theme? June 21, 2022 Steam Deck Mod Permits for Longer M.2 SSD Upgrades June 21, 2022 Load more Recent Comments





{kind=link}