The layer-2 forwarding and flooding in an MLAG cluster are intricate however nonetheless fairly simple to know. Layer-3 will get extra fascinating; its quirks rely closely on layer-2 implementation. Whereas most MLAG implementations exhibit related bridging conduct, count on fascinating variations in routing conduct.
We’ll need to broaden by-now acquainted community topology to cowl layer-3 edge instances. We’ll nonetheless work with two switches in an MLAG cluster, however we’ll have an exterior router connected to each of them. The hosts linked to the switches belong to 2 subnets (purple and blue).
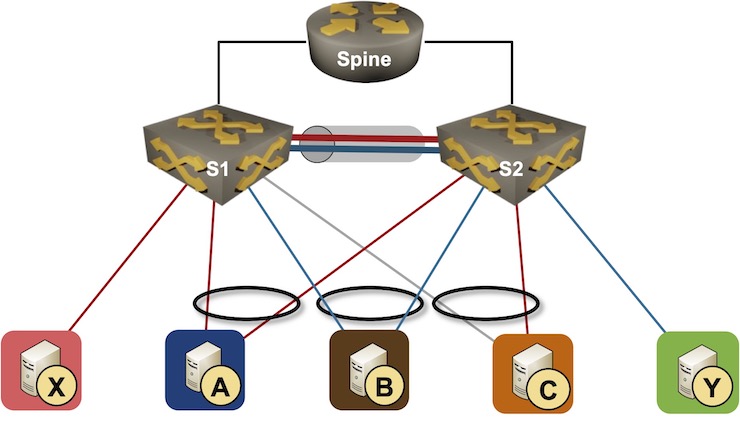
Layer-3 MLAG topology
Forwarding Necessities
Earlier than going into the main points, let’s work out what we must always count on in a well-designed MLAG cluster offering layer-3 forwarding:
- One of many main causes to take care of MLAG complexity is redundancy – the visitors ought to hold flowing even when one of many MLAG cluster members crashes. That’s simple to do inside a layer-2 section; to maintain inter-subnet visitors flowing, the MLAG cluster members need to share the IP and MAC deal with of the first-hop gateway.
- We wish energetic/energetic layer-3 forwarding throughout the MLAG cluster. For instance, when A sends an IP packet to B, it would use the A-S1 or the A-S2 hyperlink. It could make no sense to ship that packet over the S1-S2 peer hyperlink simply to be routed by the opposite swap. The primary-hop IP and MAC deal with should due to this fact be energetic on all MLAG cluster members.
- MLAG cluster members should take care of misdirected visitors. In most designs, S1 and S2 promote complete subnets (purple and blue) to the exterior router. Whereas it doesn’t matter whether or not the exterior router sends visitors for A or B to S1 or S2, S1 and S2 need to take care of visitors for X or Y arriving on the flawed swap.
First-Hop IP and MAC Tackle
I’m constructive the “shared first-hop IP- and MAC deal with” requirement instantly triggered the “first-hop redundancy protocols (FHRP)” knee-jerk response, however that doesn’t need to be the case. Arista’s Digital ARP (VARP) or Cumulus Linux Digital Router Redundancy (VRR) – statically configured shared IP- and MAC deal with – are greater than ok, and are fairly resilient towards configuration errors.
Many different distributors insist on working HSRP or VRRP between MLAG cluster members, and Arista and Cumulus supply each choices – what may very well be higher than two methods of configuring the identical factor.
Energetic/Energetic Forwarding
Many distributors took historic FHRP implementations that supported a single energetic forwarder and made them a part of their MLAG options. It took years earlier than they realized it’s completely fantastic to have all switches take heed to the identical MAC deal with. In spite of everything, if the MAC desk on the ingress swap forwards a layer-2 packet with the FHRP vacation spot MAC deal with to the layer-3 forwarding desk, that very same packet is just not flooded to every other host (or the peer hyperlink), and there’s no hazard of visitors duplication.
Quick ahead to 2022. Energetic/energetic forwarding is now a table-stakes MLAG characteristic, and there’s a great cause for that. Keep in mind the “use outbound ACL to restrict layer-2 flooding” trick? Right here’s what occurs whenever you attempt to use single forwarder with it:
- Let’s assume S1 is our devoted forwarder, and S2 is only a layer-2 swap.
- Assume A needs to ship a packet to B (which is in a special subnet) and occurs to ship the packet to the VRRP MAC deal with (owned by S1) over the A-S2 hyperlink.
- S2 forwards the packet (based mostly on vacation spot MAC deal with) to S1.
- S1 routes the packet, and tries to ship it to B.
- The outbound ACL on the S1-B hyperlink drops the packet as a result of S1 obtained it over the peer hyperlink.
You can clear up that problem with a extra particular ACL (drop the packet if it got here from the peer hyperlink and if the supply MAC is just not the router MAC), or you can do the suitable factor and implement energetic/energetic forwarding.
Lastly, since VXLAN and EVPN grew to become all the fad, many switches help anycast gateway that extends the shared IP- and MAC addresses throughout the entire VLAN. Isn’t it ironic that it took so lengthy for everybody to ultimately converge towards essentially the most simple answer that has been recognized for ages?
ARP Dealing with
I already talked about misdirected visitors: an exterior supply may ship an IP packet to a swap that isn’t but able to ahead it to a directly-connected host attributable to a lacking ARP entry.
Many MLAG implementations use a control-plane protocol that synchronizes the ARP tables between MLAG cluster members to take care of that problem; I nonetheless can’t work out why they must do it. In spite of everything, the worst that may occur is one other ARP request and a dropped packet (or few).
One may assume (based mostly on the active-active forwarding dialogue) that you need to synchronize ARP entries attributable to misdirected ARP replies – S1 sends an ARP request to A, however A replies over the A-S2 hyperlink – however that doesn’t make sense.
ARP reply is a unicast layer-2 body, and is forwarded to the management airplane ASIC port as soon as it reaches the goal swap, so it’s not hitting the LAG member outbound ACL. Moreover, ought to that be a problem, we might have a 50% likelihood of getting ARP to work within the first place, and possibly a number of sad unfortunate clients.
It appears like most distributors determined that it doesn’t price a lot to have ARP synchronization in the event that they already carried out MAC synchronization, and simply went with the circulate.
Gateway Supply MAC Tackle
MLAG implementations should take care of one other glitch. Some units (most notably storage units, supposedly additionally some load balancers) construct forwarding cache entries from the supply IP- and MAC addresses of the incoming IP packets – a transparent layering violation, in all probability additionally an RFC violation.
Let’s assume B is such a tool. When A sends a packet to B over the A-S1 hyperlink, S1 routes the packet and forwards it to B with the S1 supply MAC deal with. A sane IP host would ignore the supply MAC deal with and ship the return packet to the default gateway MAC deal with (in spite of everything, A is in a special subnet). B – an aggressively over-optimizing gadget – would construct a forwarding entry from that packet saying “to ship packets to A, use S1 MAC deal with”.
Now think about that:
- B occurs to ship the packet to A with the vacation spot MAC deal with of S1 over the B-S2 hyperlink
- S2 would ahead (bridge) the packet to the S2-S1 peer hyperlink
- S1 would obtain and route the packet and ahead it towards A over the direct hyperlink.
- Primarily based on the MLAG implementation, the packet is perhaps dropped because of the outbound ACL on the S1-A LAG member hyperlink (see energetic/energetic forwarding part).
There are two methods to unravel this conundrum:
- The academically appropriate means: use switch-specific MAC addresses for native visitors, and ship all forwarded visitors with the shared supply MAC deal with. Regardless of the loopy hosts determine to do can not break active-active forwarding.
- The standard kludge: make each switches course of visitors despatched to the shared MAC deal with and the native MAC addresses of each switches. This strategy ensures no control-plane protocol (together with ARP) will ever work out of the field, and requires tons of different kludges to make easy issues like ARP work; the proof is left as an train for the reader.
Why would anybody implement such a loopy kludge? Wouldn’t or not it’s simpler to ship forwarded packets and locally-originated packets with completely different supply MAC addresses? In spite of everything, some community working techniques (like Cisco IOS) ceaselessly used completely different forwarding paths for native and forwarded visitors.
It appears like most knowledge heart swap distributors discovered it simpler to push the locally-originated visitors to the switching ASIC and let it take care of the entire forwarding course of (together with outbound ACL). When utilizing such an strategy, the swap ASIC makes use of the identical forwarding path for native visitors and visitors obtained on exterior ports, leading to the identical supply MAC deal with after the layer-3 forwarding course of rewrites the MAC header.
Thank You
There have been many issues that made little sense after I wrote the primary draft of the weblog put up. A protracted chat with Dinesh Dutt cleared the MLAG fog, and impulsively the whole lot made (some bizarre) sense. Dinesh, thanks 1,000,000 to your time and the persistence to assist me determine all of it out.
It goes with out saying that every one the errors left within the weblog put up are mine 
What’s Subsequent?
We coated the fundamentals of layer-2 and layer-3 forwarding in an MLAG cluster. Time for extra fascinating matters, beginning with “how will we combine MLAG with VXLAN?” – the subject of the following weblog put up within the MLAG Deep Dive collection.

{kind=link}