Alerting Significant Multivariate Drift and guaranteeing Knowledge High quality
Mannequin monitoring is turning into a scorching pattern in machine studying. With the crescent hype within the actions regarding the MLOps, we register the rise of instruments and analysis in regards to the matter.
Some of the fascinating is for certain the Confidence-based Efficiency Estimation (CBPE) algorithm developed by NannyML. They carried out a novel process to estimate future fashions’ efficiency degradation in absence of floor fact. It might yield nice benefits in detecting efficiency drops since, in actual functions, the labels might be costly to gather and out there in delay.
The CBPE algorithm is on the market within the NannyML package deal along with some fascinating shift detection methods. From the usual univariate drift detection strategies to the extra superior multivariate characteristic drift approaches, we’ve got at our disposal a terrific arsenal to mechanically detect silent mannequin failures.
On this put up, we deal with the multivariate shit detection methods. We wish to examine tips on how to detect a multivariate characteristic shift. We make a comparability with the univariate case to reveal why the latter, in some circumstances, couldn’t be sufficient to alert information drift. In the long run, we make a step additional, introducing a hybrid method to supply explainable multivariate drift detection.
Univariate drift takes place when a variable registers a major distinction in distribution. Virtually, we monitor every characteristic independently and examine whether or not its distribution change over time. It might be carried out straightforwardly by evaluating statistics between the brand new observations and previous ones. For these causes, univariate detection is simple to speak and totally comprehensible.

Multivariate drift happens when the relationships between enter information change. Detecting multivariate modifications might be extra sophisticated to interpret, however usually it’s required to override the pitfalls of univariate detection.

The causes behind univariate and multivariate drift might range in accordance with use circumstances. Regardless of the software, the outcomes of univariate characteristic drift could also be deceptive. Let’s examine why.
Supposing we’ve got at our disposal 4 sequence of information (obtained via a simulation): two correlated sinusoids and two random noise options. We additionally contemplate two subsets (intervals) of information to hold out our experiment. With the “reference” interval we’re referring to the historic information at our disposal. With the “evaluation” interval we’re referring to the brand new samples we wish to analyze.

In our “reference” interval, the info observe the identical patterns sustaining unchanged their relationship. Within the “evaluation” interval we observe a variation within the verse of the connection between the blue and the purple sinusoids. Extra exactly, the 2 options are positively correlated within the “reference” interval whereas they grow to be negatively correlated by the tip of the “evaluation” interval.


The connection is modified however the univariate distributions stay unchanged. Can our univariate drift detection be efficient?


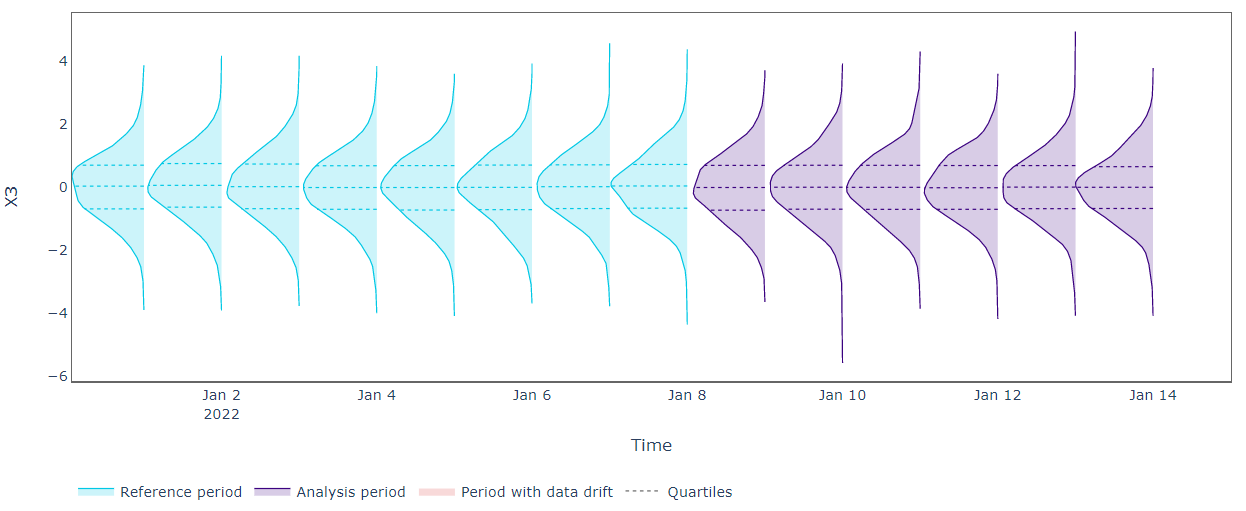

As anticipated, the univariate information drift detection algorithms don’t reveal any drift for all of the options below evaluation. From the plots above, we are able to see that univariate distributions don’t change over time so the Kolmogorov–Smirnov check can’t alert shift. We want a more practical method.
Everybody, who attended a fundamental machine studying course, has already encountered the Principal Part Evaluation (PCA). It’s a way to hold out dimensionality discount of tabular datasets preserving essentially the most salient interactions. On the identical time, we are able to use the PCA to reverse the compressed information to their unique form. This reconstruction process can protect solely the significant patterns within the information whereas discharging the noise.

NannyML leverages the reconstruction capability of the PCA to develop a easy and efficient technique for multivariate drift detection.
A set of information is firstly compressed right into a decrease dimensionality area and, secondly, decompressed to return to the unique characteristic dimensionality. This transformation course of is the important thing to reconstructing our information preserving solely the related interactions. At this level, it’s doable to compute the sequence of reconstruction errors (as easy Euclidean distance) between the unique information and the reworked counterpart. Any significant spike from the sequence of the reconstruction errors could be considered as a change within the information relationship, aka multivariate drift.
Let’s see this system in motion on our information.
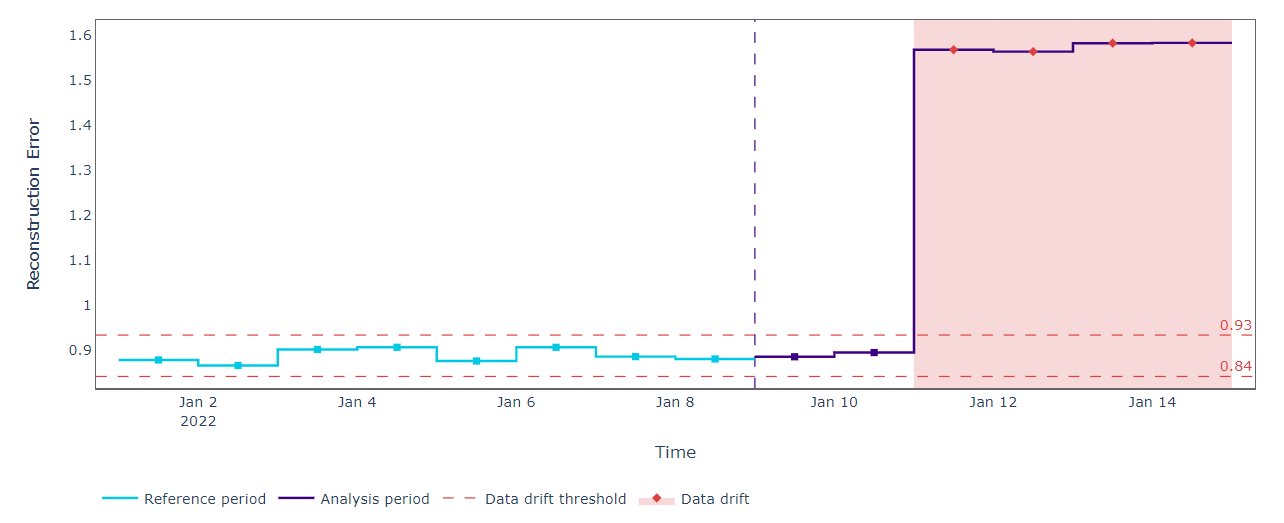
We match the PCA on our “reference” dataset and compute the reconstruction errors. That is helpful to determine the higher and decrease bounds used to detect modifications sooner or later “evaluation” information. When new information turns into out there, we solely should compress and reconstruct them utilizing the fitted PCA. If the reconstruction errors fall outdoors the anticipated thresholds we should always register a change in characteristic relationships. That’s precisely what occurred with our information.
The PCA methodology offers helpful insights for multivariate drift detection. With a single KPI, we might management the complete system standing. On the identical time, disjointing the contribution of every characteristic could also be added worth.
With the PCA we intention to study patterns in a single studying step. That’s nice and divulges to be efficient typically and in a number of functions. If our purpose is to find the unknown relationships between options, we might do the identical in a simple method.
We might think about the connection discovery as a supervised activity. In different phrases, given a set of options, we might use them to foretell one another and use the generated residuals as a measure of drift. If the residuals range with the passing of time, we notify a shift.

Coming again to our simulated situation, we match one mannequin for every characteristic at our disposal on the “reference” information. Every mannequin is fitted to foretell the specified characteristic utilizing all the opposite options as predictors. Then we generated the residuals each on “reference” and “evaluation” information. Having at disposal sequence of residuals we might detect drift utilizing univariate approaches.




Detecting drift with univariate methodologies is now more practical. We register excessive errors on the finish of the “evaluation” interval for each X1 and X2. Extra exactly, we’ve got no proof of a univariate distribution drift for X1 and X2 in the identical interval. For that reason, the excessive errors might point out a change within the relationship between X1 and the remainder of the enter information (the identical for X2). In different phrases, the shift in univariate reconstruction error distributions might reveal that the concerned options have modified their interactions.
On this put up, we launched some current strategies out there for efficient information drift monitoring. We additionally understood how and why solely a univariate method might undergo. We found the significance of multivariate characteristic shift and tried to supply an explainable technique to determine the sources of doable multivariate drift.
