
Retailer information in tables and achieve insights from graphs

Although there was sufficient meals for 10 billion folks, 10% of the world inhabitants nonetheless recurrently goes to mattress hungry. Local weather change, COVID-19, and the struggle in Ukraine have exacerbated the meals disaster. Whereas feeding the world inhabitants (8 billion in 2022) has already been arduous sufficient, producing and distributing sufficient meals for the longer term inhabitants (9.8 billion in 2050) might be much more difficult, particularly when the losses of topsoil, agricultural data, and soil biodiversity maintain appearing towards us.
Within the face of a large-scale meals disaster and local weather change, we have to reform our present unsustainable agriculture. Among the many a number of alternate options, the great outdated companion planting is admittedly value our consideration. It’s the farming apply of rising various vegetation in proximity that assist one another both by nutrient provision, useful insect attraction, or pest suppression. Compared with monocultures, companion planting may be extra productive and extra eco-friendly. One well-known instance is the Three Sisters: winter squash, corn, and beans (title determine). Beans repair nitrogen with their symbiotic micro organism. Squash protects the soil from the weather with its broad leaves and repels pests with its hairs. And corn is a pure trellis for the beans to climb. Collectively, they will defend the soil from erosion and enhance productiveness.
People have practiced companion planting over millennia and collected in depth data in regards to the topic. This information is codified into tables, resembling this one on Wikipedia. Tables are simple to switch and keep with instruments resembling Google Sheets. However for relation-rich information such because the companion plant information, a desk shouldn’t be my first selection for visible evaluation. In distinction, a community graph (Determine 1) can show the intricate interconnections of vegetation simply. We will additionally carry out graph queries and graph-based algorithms to achieve new insights into the info.

However information enhancing in a graph database like Neo4j shouldn’t be so simple as in a desk. Though the graph app Neo4j Commander brings information enhancing into the Neo4j platform, its person expertise continues to be a far cry from what we are able to get from Google Sheets. Can we have now each simple information enhancing and straightforward graphing with only one single supply of reality?
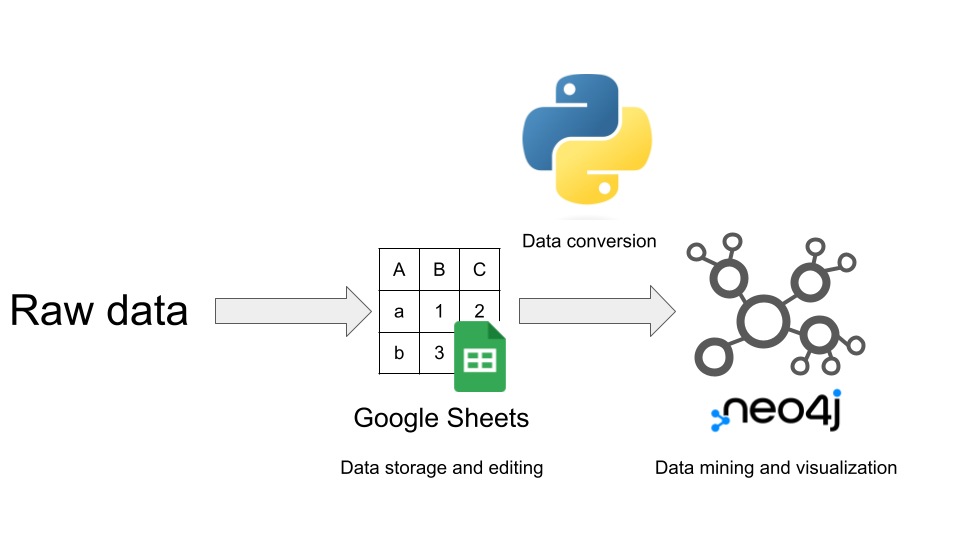
On this article, I need to present you my resolution. I retailer the companion plant information from Wikipedia in Google Sheets. It’s my solely supply of reality. I then use Neo4j Desktop to create a neighborhood data graph. A Python Jupyter pocket book serves as a bridge. The pocket book downloads and codecs the info from Google Sheets. Then it drops the outdated information and imports the brand new one in Neo4j (Determine 1). After which we’re going to do some information mining on the data graph in each Cypher and Python. For instance, I’m going to make use of the Diploma Centrality algorithm in Neo4j’s Graph Knowledge Science (GDS) library to calculate the most important set of mutually supportive vegetation that we are able to develop across the potatoes.
The code for this text is hosted on my GitHub repository right here.
The information on this challenge comes from Wikipedia and is beneath the Inventive Commons Attribution Share-Alike license.
First, create a Neo4j challenge in your Neo4j Desktop referred to as “companion vegetation”. Open its import folder (“…”  “Open folder” “Import”). Copy the seemingly random database string (dbms-xxxxxx) and set it as the worth of
“Open folder” “Import”). Copy the seemingly random database string (dbms-xxxxxx) and set it as the worth of neo4j_project_id in config.yaml. Additionally, fill out the opposite particulars in config.yaml.
As well as, it’s worthwhile to allow the GDS library within the Plugins tab.
My desk relies on the Checklist of companion vegetation on Wikipedia. The information had been break up into 5 tables: greens, fruit, herbs, flowers, and others. I then used the IMPORTHTML operate to fetch the info into 5 Google Sheets and merged them right into a grasp desk.
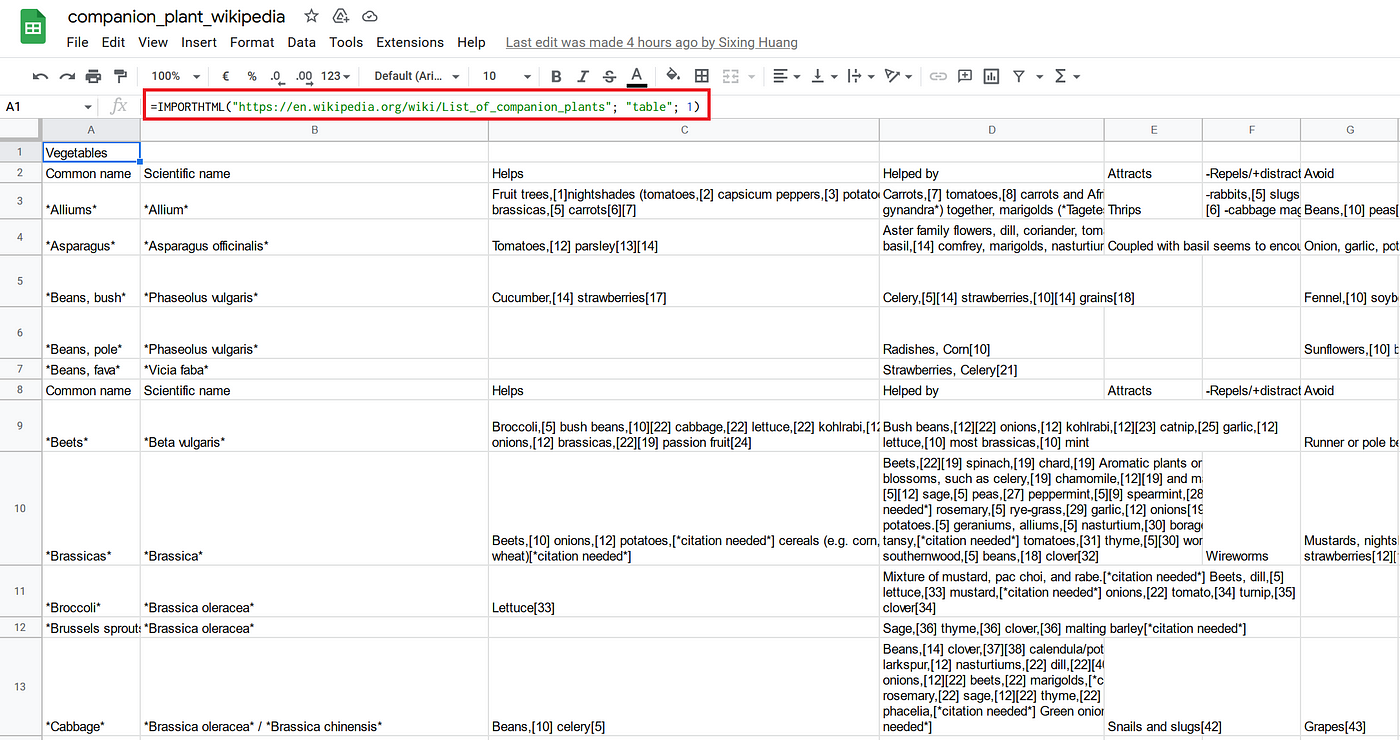
Afterward, I manually curated the info. I first corrected a number of typos, cleared some ambiguous phrases like “nearly all the pieces”, added many information entries, and normalized the synonyms (Determine 3 left). Lastly, I constructed a sheet for the taxonomy (Determine 3 proper).
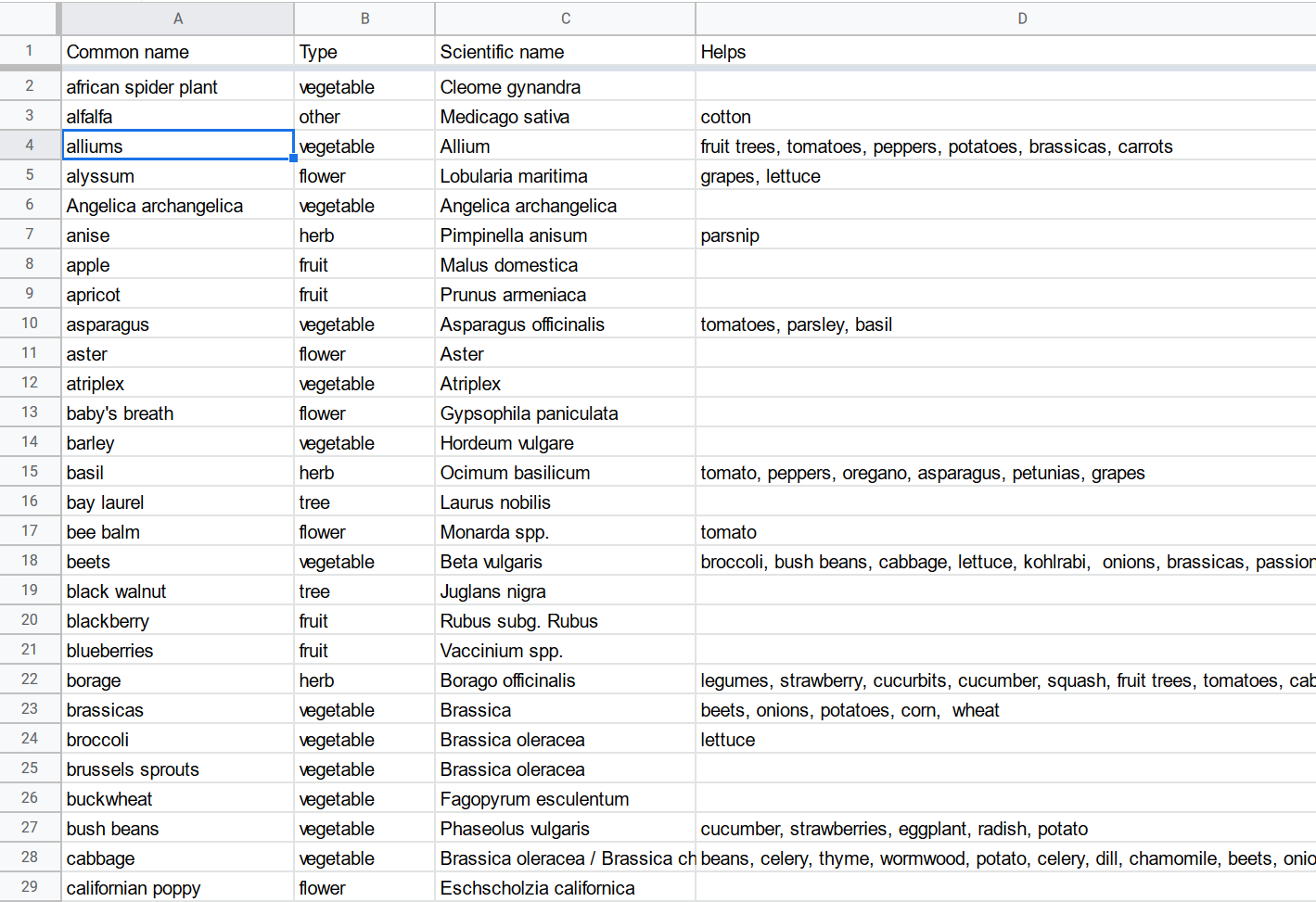

For simplicity’s sake, I made the Google Sheets typically accessible in order that the pandas library may load the info simply later in my script. And since the info are within the public area, it’s OK for this challenge. But when your challenge information are confidential, you’d higher set a extra restrictive entry coverage in Google Sheets and use the gsheets library in your Python script.
The middleware consists of three information: a Jupyter pocket book, a config.yaml, and a textual content file containing all of the Neo4j instructions. Config.yaml accommodates the native Neo4j credentials and different person information. The Python Jupyter pocket book connects Google Sheets with my Neo4j database.
Knowledge from Google Sheets may be learn immediately with the read_csv operate in pandas (Itemizing 1).
Then the script iterates the cells within the desk and break up the comma-delimited contents. They’re largely plant and animal names. The script singularizes the plural types, resolves the synonyms, and concretizes the umbrella taxa (“legume” into “bush bean”, “alfalfa” and so forth)(Itemizing 2). It additionally shops the nodes and relations in variables resembling nodes_plant and plant_plant_help.
Afterward, the script writes these variables into TSV information. For instance, the code beneath creates the file for the plant nodes.
The script then connects to the native Neo4j occasion and clears all constraints and outdated contents.
Then it copies all of the newly generated TSV information into my challenge’s import folder.
Lastly, the script carries out the import instructions within the neo4j_command.txt file. These instructions import the TSV information into the data graph and create the corresponding constraints.
And the data graph has the next easy schema. It represents the supportive and antagonistic relations amongst numerous vegetation and animals.

As soon as the info are loaded, we are able to begin exploring the data graph. There are 162 plant nodes, 71 animal nodes, and a couple of,182 relations within the graph. Among the many relations, we observe 1,455 HELPS and 404 AVOIDS relations.
3.1 Which vegetation are good companions for tomatoes?
If we need to develop tomatoes, let’s discover out which vegetation are good companions.
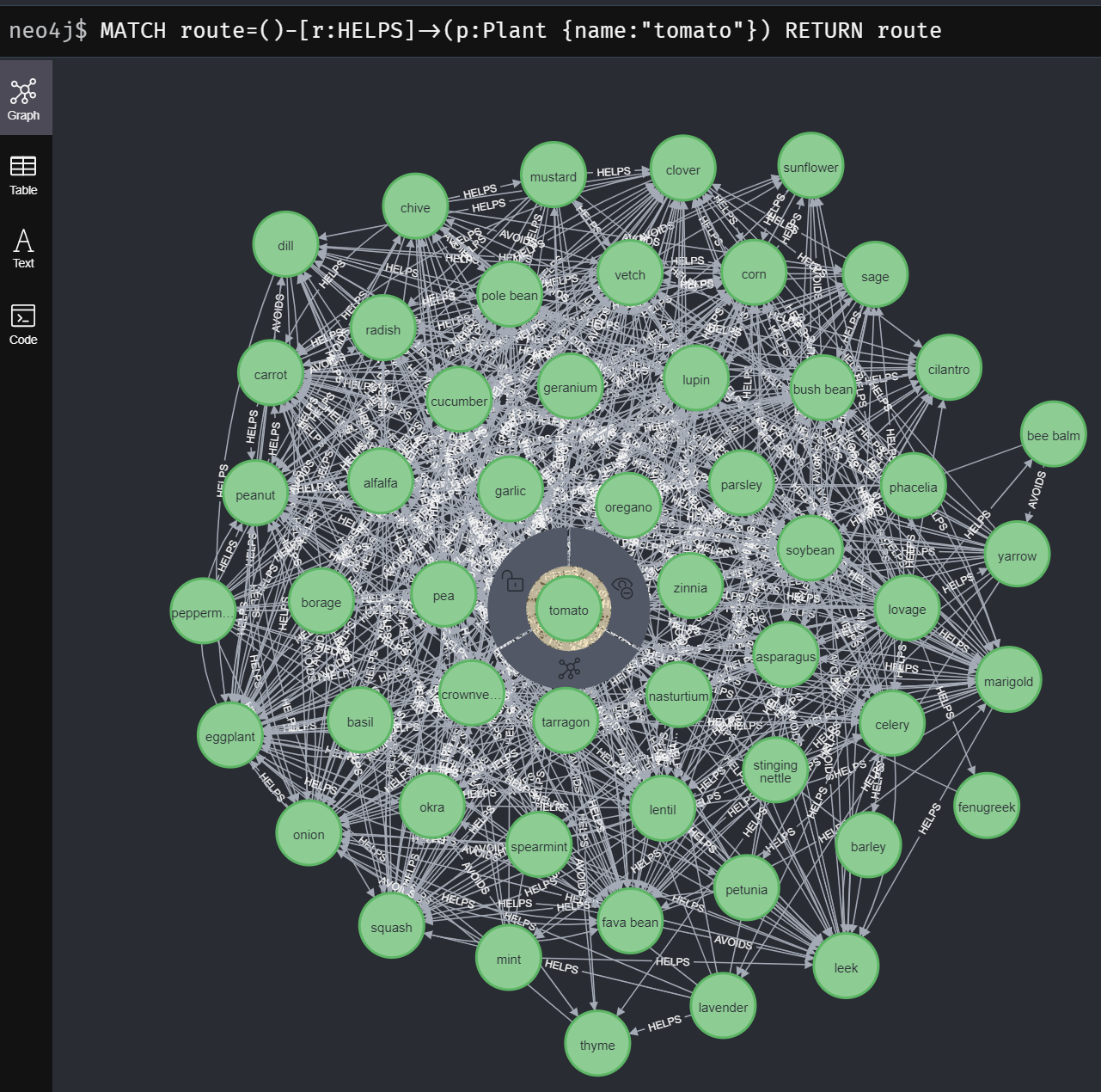
It seems that many vegetation will help us to develop tomatoes. For instance, basil, borage, garlic, and marigold can all repel pests, whereas chive, mint, and parsley could make tomatoes more healthy. However we should always keep away from cabbage, fennel, and walnut tree.
3.2 Probably the most prevented vegetation
As the instance above reveals, there are antagonistic mixtures that we’d higher keep away from rising collectively. For instance, walnut synthesizes an allelopathic compound referred to as juglone that may inhibit the expansion of tomatoes. Right here, let’s see which vegetation are essentially the most prevented within the dataset.
In response to Wikipedia, the primary ought to have been flax. Nevertheless, that information entry has been flagged as “quotation wanted” and I couldn’t confirm that data wherever else. Quite the opposite, flax can promote tomatoes and potatoes as a result of it will possibly repel Colorado potato beetles. To be on the protected aspect, I cleared its AVOIDS relations. After which fennel turns into the primary. The basis of fennel secrets and techniques substances that inhibit and even kill many backyard vegetation. In truth, dill is the one factor that may develop subsequent to fennel. Apart from that, plant it by itself [1].
3.3 Calculate the most important AVOIDS-free, supportive plant community for the potatoes
Let’s assume that we need to plant potatoes in a big subject. And we need to plant essentially the most biodiverse set of vegetation there. There’s one restriction although, no “AVOIDS” relation is allowed locally. In different phrases, there shouldn’t be any antagonistic plant pair within the set. Discover that there may be a number of such optimum lists.
I googled it however couldn’t discover any resolution. So I developed two algorithms myself in Python. Each algorithms start with the record of vegetation that may promote potato development.
This preliminary record accommodates alfalfa, brassica, garlic, lovage, and so forth.
For every plant, I rely what number of AVOIDS relations it has towards the others (Line 12–19 in Itemizing 11).
Within the first spherical, garlic doesn’t develop properly with the opposite 13 vegetation on this record. Additionally it is the plant with essentially the most AVOIDS relation. So I take away garlic from the supportive plant record (Line 24–29 in Itemizing 11). The algorithm then repeats this course of (Line 8–29 in Itemizing 11) till no extra AVOIDS relation may be discovered. If there are multiple vegetation with the identical quantity of AVOIDS, the code removes one in every of them randomly (Line 25–27 in Itemizing 11).
In one in every of my runs, this algorithm successively removes garlic, leek, chive, onion, and so forth. The ultimate record accommodates the next 22 vegetation: alfalfa, basil, cabbage, carrot, clover, corn, crownvetch, useless nettle, flax, horseradish, lentil, lovage, lupin, marigold, mint, pea, peanut, pole bean, soybean, tarragon, vetch, and yarrow.
The second algorithm makes use of Diploma Centrality from GDS to determine which plant to take away in every iteration. The Diploma Centrality algorithm is used to search out common nodes inside a graph. In our case, I take advantage of it to search out essentially the most prevented vegetation. The algorithm measures the variety of incoming or outgoing (or each) relationships from every node and shops the metric within the “rating” column in a pandas dataframe. Its implementation differs from the primary one within the “whereas” loop.
Throughout every iteration, this algorithm first initiatives the supportive vegetation and their AVOIDS relations right into a graph object (Line 14–17 in Itemizing 12). Then it calculates the diploma centrality rating for every plant (Line 19 in Itemizing 12), fetches essentially the most “common” one (Line 20–26 in Itemizing 12), and removes it from the supportive plant record. When there are a number of vegetation with the identical diploma centrality rating, the code removes one in every of them randomly. The algorithm repeats itself till all diploma centrality scores are 0 (Line 34–35 in Itemizing 12).
This algorithm finds a brand new set of twenty-two vegetation every time you run it. However a number of the vegetation, resembling yarrow and useless nettle, will at all times be within the set as a result of they don’t have any AVOIDS relation within the subgraph. Each algorithms are legitimate. You’ll be able to confirm the outcomes by exhibiting that there isn’t a AVOIDS relation between any two vegetation.
However the Diploma Centrality methodology ran in 0.4 seconds whereas my first algorithm completed in 2.6 seconds.

{kind=link}