
After the work described in the previous blog post, Stack Overflow for Teams now runs on its own domain: stackoverflowteams.com. All Teams have been migrated and customers have been informed of configuration changes they would need to make on their end to keep everything working.
As a reminder, here’s the phases we planned to move our Teams instances:
- Phase I: Move Stack Overflow for Teams from stackoverflow.com to stackoverflowteams.com
- Phase II: Decouple Teams and stackoverflow.com infrastructure within the data center
- Phase III: Build a cloud environment in Azure as a read-only replica while the datacenter remains as primary
- Phase IV: Switch the Azure environment to be the primary environment customers use
- Phase V: Remove the link to the on-premises datacenter
With Phase I completed, we now had a cosmetic separation. The next step is making sure there is nothing behind the scenes that depends on the stackoverflow.com DMZ. This meant we needed to remove the dependency on the Sites database and contain all Teams infrastructure and data within the TFZ which is all part of Phase II.
Breaking up is hard to do
The largest factor we nonetheless shared with the DMZ was the Websites database. This database is the muse of our multi-tenancy. However that’s not all. The DMZ nonetheless obtained incoming requests and forwarded these to the TFZ for all Groups-related enterprise. And our deployment processes have been shared with stackoverflow.com and primarily based on our older TeamCity course of.
We first labored on getting a model new remoted Groups surroundings deployed to a dev surroundings. We created some additional servers for this within the TFZ and constructed a deployment course of in Octopus Deploy. This gave us a brand new, self-contained clear surroundings that we might check and helped us with shifting away from TeamCity.
As soon as we had our dev surroundings working and examined, we knew the brand new Groups surroundings would have the ability to perform. Now we needed to give you a plan to separate the DMZ and the TFZ in manufacturing.
We got here up with a script that we might comply with to carry out 27 steps ranging touching every little thing from IIS settings to software deployments , all required to totally cut up the infrastructure and begin operating Groups from the TFZ. This meant database steps equivalent to getting a duplicate of the Websites database over to the TFZ, software steps equivalent to turning off all Groups associated code within the previous DMZ, deploying the total app to the TFZ, and cargo balancer adjustments to verify requests not have been dealt with by the DMZ.
Practice makes perfect
As soon as we had a primary model of the script, we began training this on our dev surroundings. Optimistic as I used to be, I believed this may take us an hour. After 4 hours we determined to surrender, lick our wounds, and determine what went fallacious.
The difficulty we noticed was that in our ‘new’ surroundings, newly requested questions have been solely proven within the overview web page after 5 minutes. In our previous surroundings, this was virtually instantaneous. We knew this needed to be a configuration subject from the migration as a result of a model new deployed surroundings did present the questions instantly.
Lengthy story brief, we made a configuration mistake the place we used an incorrect Redis key prefix to sign from the online app to TagEngine {that a} new query was out there and needs to be added to the overview web page. As soon as we figured this out, we ran a brand new follow spherical and issues went a lot smoother.
We then scheduled the actual factor for March eleventh, 2023. Due to our follow rounds, the actual change over went off with none points.
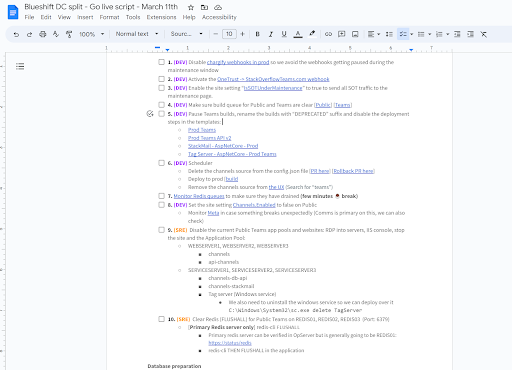
Part of the script for March eleventh with in whole 27 steps to separate Groups and Stack Overflow
This accomplished Section II. Section III was to take this fully-isolated surroundings from the datacenter and migrate it into Azure. We determined to do a carry and shift as a result of we didn’t wish to threat altering each the infrastructure and the appliance whereas migrating to the cloud. As an alternative, we determined to maintain issues as related as attainable and begin modernizing as soon as we’re in Azure.
What do we have to move?
We have now a few key parts operating Groups in our datacenter that we needed to carry and shift to Azure:
- Home windows Server digital machines operating the online software and all supporting companies
- Redis for caching
- ElasticSearch for our search performance
- Fastly and HAProxy for load balancing
- SQL Server for our databases
We began with excited about how we might map all these parts to Azure whereas altering as little as attainable but additionally making adjustments the place it made sense. The next sections undergo all these parts and discusses how we construct them in Azure.
The web tier
Digital machines are annoying. They require patching for OS updates and sometimes have the tendency to begin diverging the second you deploy them. On-premises, now we have an in-house device referred to as Patcher that we use along side Ansible to repeatedly patch our servers. We use Puppet for server configuration. We wished to enhance upon this and do away with the manually deployed and configured servers.
So we determined to spend money on constructing VM base pictures with Packer that we might simply replace and deploy.
Packer is a device from HashiCorp. Packer standardizes and automates the method of constructing system and container pictures. The ensuing pictures included all newest OS patches, IIS configuration, .NET runtime and certificates that we would want for each net VM. This helped us deprecate Patcher, Ansible, and Puppet. As an alternative of updating an present machine, we construct a brand new picture and changed the machine with the brand new model,
Deployment occurs to a Digital Machine Scale Set. VMSS is a simple strategy to provision a number of VMs primarily based on the picture we created with Packer. It helps rolling deployments and monitoring of the VMs permitting us to securely substitute VMs when a brand new picture turns into out there.
We run 4 Standard_D32ds_v5 VMs in manufacturing. These have 32 cores and 128GB of reminiscence. We’d like this quantity of reminiscence due to all of the caching we do and since TagServer requires a variety of reminiscence.
On every of those VMs, we run six functions:
- Internet app
- API v2 and v3
- Scheduler (inner device used to execute scheduled duties)
- TeamsDbApi (inner API that manages the databases for all Groups)
- StackMail (inner device to handle all electronic mail we ship)
- TagServer (a novel customized, high-performance index of Groups questions)
The bottom picture is immutable, so every time we wish to apply OS updates or different adjustments we create new VMs primarily based on this new picture after which delete the previous VMs as soon as every little thing is dwell. The functions are deployed on high of those not-so-immutable pictures.
The rationale we don’t bake the app into the picture is pace. Constructing and deploying a brand new picture can simply take a few hours. Doing an app deploy on a operating VM takes minutes.
If we do a rolling replace of all VMs to interchange their base picture, we have to ensure that the functions are absolutely deployed and functioning earlier than shifting on. The following diagram exhibits the method we use for this. The VMSS creates a brand new VM primarily based on the VM picture which accommodates the Octopus agent. As soon as that agent comes on-line, it routinely triggers a deployment of all functions. The VMSS then checks the well being endpoint, which is dealt with by the principle net software. This endpoint checks if all different functions are achieved deploying and solely then alerts that the total VM is wholesome.
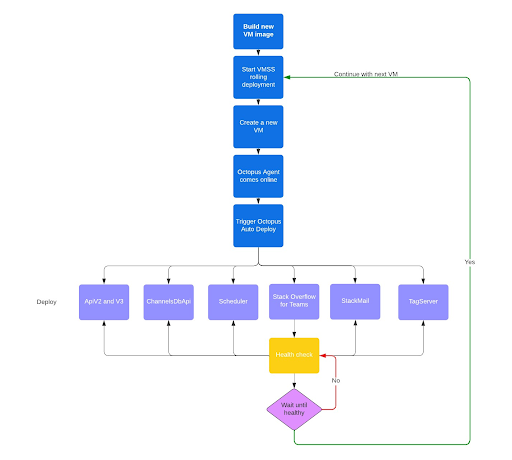
Now think about that one of many functions fails to begin. The VMSS will cease the rolling deployments, leaving one VM unhealthy and all different VMs wholesome. The unhealthy VM received’t obtain site visitors from Azure Software Gateway and clients received’t discover this.
If we do an everyday software deployment, we begin with a VM that has all functions already deployed. Our Octopus pipeline does a rolling deployment over all VMs. For every VM, the pipeline first runs a script that marks the precise app for that particular VM as unhealthy within the Software Gateway. As soon as that’s achieved, the appliance is deployed and we wait till the appliance begins displaying wholesome within the Software Gateway. Solely then we transfer on to the following VM. This fashion, we could be certain we by no means take all VMs offline with a failing deployment.
We all know this course of is complicated and may simply fail. For the carry and shift, nevertheless, this was ok and we plan on bettering this additional sooner or later, perhaps by shifting to containers.
Application Gateway and Fastly
On-premises we use Fastly and HAProxy for load balancing. We determined to maintain Fastly but additionally begin leveraging Azure Software Gateway to handle exterior and inner site visitors. App Gateway is a layer 7 load balancer that enables us to handle site visitors to all of the apps put in on the assorted VMs within the VMSS. Azure Software Gateway is a cloud native providing we don’t should handle ourselves making our lives somewhat simpler.
We determined to deploy two Azure Software Gateways: one for inner and one for exterior communication. The App Gateway for exterior site visitors is linked to Fastly. The 2 App Gateways are deployed to 2 completely different subnets so we absolutely management entry to who can attain which software and communication between apps.
The general public App Gateway is fronted by Fastly. Fastly is aware of about our self-importance domains (stackoverflowteams.com and api.stackoverflowteams.com), whereas the appliance gateways solely know concerning the inner URLs for Groups cases. This permits us to simply spin up environments which might be absolutely self contained with out having to the touch Fastly. Fastly provides us management over routing/redirection, in addition to issues like request/header manipulation, certificates administration, failover between areas, and request logging and observability. As well as, we use mutual TLS (mTLS) between Fastly and the Azure Software Gateway to make sure site visitors coming into the App Gateways is coming solely from Fastly.
Our on-premises Fastly configuration was comparatively “monolithic”—now we have a single config pushed to a number of companies, which makes use of guidelines to find out which a part of the configuration applies to which service. For our new cloud config for Section III, we cut up out every workload into its personal service in Fastly (principal software, API, and many others) to permit us larger flexibility in making use of guidelines focusing on solely a single service with out impacting others. This fashion, we are able to hold the Software Gateway as flat as attainable and deploy a number of cases of our surroundings subsequent to one another with none conflicts or overlap.
The Software Gateway displays the well being of all its backends. The next screenshot exhibits considered one of our developer environments that has all the interior functions deployed to a VMSS with two VMs.
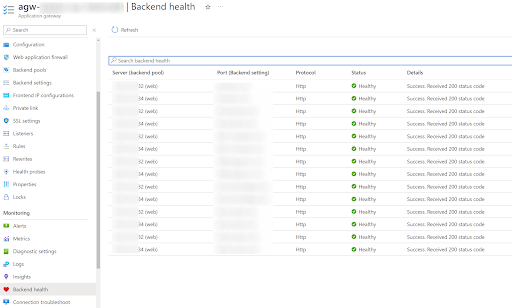
You possibly can see how the Software Gateway checks every backend’s well being so it is aware of the place it may well route site visitors.
Elastic and Redis
Our functions make heavy use of caching. On-premises, we set up and handle Redis ourselves on a bunch of Linux servers. In Azure, we opted to make use of Azure Cache for Redis. It is a fully-managed service that we don’t should improve or preserve. We did ensure that each Redis occasion has a Personal Hyperlink community endpoint so we are able to take away all public entry and ensure we by no means unintentionally expose our cache to the general public web. However past that, our days of fidgeting with Redis settings have been over.
Elastic was a bit extra sophisticated. Simply as we did for Redis, we wished to make use of a completely managed service: ElasticCloud. Now this labored rather well for all our check environments. Nevertheless, after we began loading extra information, we bumped into points the place ElasticCloud would turn out to be unresponsive and grasp nodes randomly failed and didn’t come again up.
We determined to maneuver away from ElasticCloud and as a substitute deploy an Azure Kubernetes Service with our personal Elastic deployment utilizing Elastic Operator. This deployment mannequin gave us extra perception and visibility into what was occurring, which helped us detect the efficiency root trigger—a problem with a single Elastic API endpoint—and repair it. The difficulty we had originated from the way in which we use aliases. We create a filtered alias per Staff and every question to Elastic is pressured to specify the alias. This fashion, no buyer might ever question information from one other buyer. Nevertheless, the large variety of aliases was the trigger for our efficiency points. As soon as we figured this out, a fast configuration change to permit extra aliases mounted our points.
SQL Server
On-premises, we ran SQL Server put in on a VM in an availability group that spanned our two on-premises information facilities. Every information heart had two nodes, with a major in a single information heart, and three whole secondaries. Our software runs in read-write mode in the identical area as the first reproduction, sending read-only queries to the secondary node inside the identical area, with all different queries going to the first node. The opposite area is used solely for catastrophe restoration.
We have now the principle Websites database, after which dozens of databases that every include ~1,000 Groups. To get this information into Azure, we needed to lengthen our availability group to incorporate SQL Servers deployed in Azure. This prevented us from operating one thing like Azure SQL Database or Managed Situations. As an alternative we had to make use of manually configured SQL Server VMs.
As soon as the information began flowing, we might deploy our manufacturing surroundings in Azure as read-only. The SQL Servers in Azure have been each read-only and the appliance turns off all routes that may edit information.
Now, testing a read-only surroundings will not be very thrilling, however having the ability to view a Staff and an inventory of questions already exhibits that a variety of our parts are deployed and configured efficiently!
Along with the manually put in and configured SQL Servers in Azure, we additionally wished further environments to check new infrastructure or software adjustments and to run automated checks. To assist this, we’ve prolonged our infrastructure deployment to assist Azure SQL Database. The benefit of Azure SQL Database is that we are able to deploy and configure all of the required databases in a completely automated manner.
This permits us to have what we name ephemeral environments. These environments are created for a selected function and, if we not want them, we are able to simply destroy them.
One such function is our High quality Engineering surroundings the place we run nightly automated Mabl checks in opposition to all Groups options. On-premises, this may have value us a variety of work to configure the servers and set up the appliance. In Azure, all it took was a PR so as to add a brand new surroundings and an Octopus deploy to roll out the infra and app!
What we ended up with
Combining the brand new net VMs, Azure Software Gateway, Fastly, Redis, Elastic, and SQL Server accomplished our Section III: Construct a cloud surroundings in Azure as a read-only reproduction whereas the information heart stays as major.
The next diagram exhibits what our closing Azure surroundings appears to be like like.
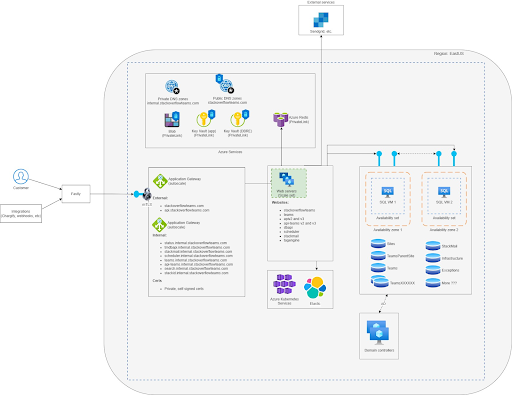
Failing over and cutting the cord
Now that now we have a fully-functional Azure surroundings operating Stack Overflow for Groups in read-only mode, it was time to maneuver to Section IV and make this new surroundings our major learn/write surroundings and really begin serving clients from Azure.
There are two principal steps on this failover:
- Fastly rebuild
- Database failover
We had a earlier model of the Groups service in Fastly, which leveraged a monolithic config shared with different functions. For this effort, we elected to construct the code anew to benefit from classes we have realized through the years from managing functions within the Fastly CDN, in addition to including in greatest follow configurations going ahead (mTLS, automated LetsEncrypt certificates, and many others).
We additionally needed to fail over the database availability group. The on-premises servers have been switched to read-only and the Azure servers grew to become learn/write. That is the place we hit an enormous drawback: the failover repeatedly timed out attributable to community latency. After a number of tries, we determined to pressure the Azure nodes to turn out to be major and make the on-premises nodes unavailable. This allowed us to carry the app up in learn/write mode in Azure, however in fact this isn’t what we envisioned. As soon as Azure was major, we restored the databases to a single node within the information heart and re-joined that node to the supply group. This allow us to resume syncing all information to the information heart in case one thing went fallacious with our Azure surroundings and we wished to fail again.
Now that Azure ran as major with on-premises as secondary (finishing Section IV), it was time to carry a further Azure area (West US) on-line and make that the secondary surroundings. Due to our infrastructure-as-code deployment processes and all of the automation now we have in place, it was very simple to carry the additional Azure surroundings on-line. As soon as the database servers have been configured and the information was synced, we might entry Stack Overflow for Groups as read-only operating in West US.
Lastly, the second got here to chop the wire between Azure and on-premises. We blocked all communication by means of firewall guidelines, eliminated the remaining on-premises node from the AG, and decommissioned all on-premises net servers and SQL Server cases operating Groups, finishing Section V.
After which we have been achieved 🥳
What’s next?
All in all, shifting Groups to Azure took virtually two years however, lastly, we’re achieved! Stack Overflow for Groups runs in Azure with none dependencies on the on-premises datacenter. Now, in fact, this isn’t the place we cease.
As you’ve realized all through these weblog posts, we did a carry and shift and intentionally determined to not undertake cloud native parts but (besides Azure Redis, which simply labored).
One subject we’re seeing is the community efficiency between East US and West US for our SQL Server availability group. After a lot analysis and discussions with Microsoft, we’ve discovered the issue to happen after we area be a part of the SQL Server VMs. We wish to transfer away from digital machines, so we’re now investigating choices to maneuver to Azure SQL Database.
Azure SQL Database would take away all of the handbook upkeep of the SQL Server VMs and permits us to a lot simpler configure excessive availability throughout a number of Azure areas. We do want to determine find out how to get our information into Azure SQL Database and optimize for efficiency and value.
We additionally wish to transfer away from VMs for our net servers; we wish to transfer to containers. We have already got the AKS cluster for Elastic and we’re seeking to transfer apps to containers one after the other till we are able to take away the VMs.
And who is aware of what’s subsequent after that.
In case you have feedback or questions please attain out!

{kind=link}