
Introduction
On this publish, we’ll study net scraping Google with Node JS utilizing a number of the in-demand net scraping and net parsing libraries current in Node JS.
This text might be useful to learners who wish to make their profession in net scraping, knowledge extraction, or mining in Javascript. Internet Scraping can open many alternatives to builders around the globe. As we are saying, “Information is the brand new oil.”
So, right here we finish the introduction and get began with our lengthy tutorial on scraping Google with Node JS.

Desk Of Contents
1 What are HTTP Headers?
1.1 HTTP Request Header
1.2 HTTP Response Header
1.3 HTTP Illustration Header
1.4 HTTP Payload Header
2 Person Agent
3 Unirest
3.1 Benefits of Unirest
4 Axios
4.1 Benefits of Axios
5 Cheerio
5.1 Benefits of Cheerio
6 Headless Browsers
7 Puppeteer
7.1 Benefits of Puppeteer
8 Playwright
8.1 Playwright v/s Puppeteer
8.2 Benefits of Playwright
9 Recap
10 Nightmare
11 Node Fetch
12 Osmosis
12.1 Benefits of Osmosis
13 Conclusion
14 Extra Sources
15 FAQ
16 Donation Enchantment
Earlier than we begin with the tutorial, let me clarify the headers and their significance in scraping.
What are HTTP Headers?
Headers are an necessary a part of an HTTP request or response that gives some extra meta-information concerning the request or response.
Headers are case-insensitive, and the header identify and its worth are often separated by a single colon in a textual content string format.
Headers play necessary in net scraping. Often, when web site homeowners’ has data that their web site knowledge extraction can happen in many various methods, they implement many instruments and methods to avoid wasting their web site from being scraped by the bots.
Scrapers with nonoptimized headers get didn’t scrape some of these web sites. However once you cross right headers, your bot not solely mimics an actual consumer however can be efficiently in a position to scrape the standard knowledge from the web site. Thus, scrapers with optimized headers can save your IPs from being blocked by these web sites. Internet

Headers may be categorised into 4 totally different classes:
- Request Headers
- Response Headers
- Illustration Headers
- Payload Headers
HTTP Request Header
These are the headers despatched by the shopper whereas fetching some knowledge from the server. It consists identical key-value pair headers in a textual content string format as different headers. Identification of the request sender may be accomplished with the assistance of the knowledge in request headers.
The under instance reveals a number of the request headers:
HTTP Request header incorporates numerous data like:
- The browser model of the request sender.
- Requested web page URL
- Platform from which the request is distributed.
HTTP Response Header
The headers despatched again by the server after efficiently receiving the request headers from the consumer are generally known as Response Headers. It incorporates data just like the date and time and the kind of file despatched again by the server. It additionally consists of details about the server that generated the response.
The under instance reveals a number of the response headers:
- content-length: 27098
- content-type: textual content/html
- date: Fri, 16 Sep 2022 19:49:16 GMT
- server: server: nginx
- cache-control: cache-control: max-age=21584
Content material-Encoding record all of the encodes which are utilized to the illustration. Content material-Size is the scale of the acquired by the consumer in bytes. The Content material-Kind header signifies the media sort of the useful resource.
HTTP Illustration Header
The illustration header describes the kind of useful resource despatched in an HTTP message physique. The info transferred may be in any format, reminiscent of JSON, XML, HTML, and so forth. These headers inform the shopper concerning the knowledge format they acquired.
The under instance reveals a number of the illustration headers:
- content-encoding: gzip
- content-length: 27098
- content-type: textual content/html
HTTP Payload Headers
Understanding the payload headers is kind of troublesome, so first you must know concerning the which means of payload, then we’ll come to a proof.
What’s Payload?
When the info is transferred from a server to a recipient, the message content material or the info anticipated by the server that the recipient will obtain is called payload.
The Payload Header is the HTTP header that consists of the payload details about the unique useful resource illustration. They consists of details about the content material size and vary of the message, any encoding current within the switch of the message, and so forth.
The under instance reveals a number of the payload headers:
content-length: 27098
content-range: bytes 200-1000/67589
trailer: Expires
transfer-encoding: chunked
The content material–vary header signifies the place in a full physique therapeutic massage a partial message belongs. The transfer-encoding header is used to specify the kind of encoding to switch securely the payload physique to the consumer.
Person Agent
Person-Agent is used to determine the appliance, working system, vendor, and model of the requesting consumer agent. It will probably assist us in mimicking as an actual consumer. Thus, saving our IP from being blocked by Google. It is without doubt one of the most important headers we use whereas scraping Google Search Outcomes.
It appears like this:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36
Unirest
On this part, we’ll study concerning the Node JS library Unirest which can assist us scrape Google Search Outcomes. We’ll focus on the necessity for this library and the disadvantages related to it.
Unirest is a light-weight HTTP library out there in lots of languages, together with Java, Python, PHP, .Internet, and so forth. Kong at present manages the Unirest JS. Additionally, it comes within the record of probably the most in style net scraping Javascript libraries. It helps us to make all forms of HTTP requests to scrape the dear knowledge on the requested web page.
Allow us to take an instance of how we are able to scrape Google utilizing this library:
npm i unirest
Then we’ll make a request on our goal URL:
const unirest = require(“unirest”)
perform getData()
{
const url = "https://www.google.com/search?q=javascript&gl=us&hl=en"
let header = {
"Person-Agent": "Mozilla/5.0 (Home windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 Viewer/96.9.4688.89"
}
return unirest
.get(url)
.headers(header)
.then((response) => {
console.log(response.physique);
})
}
getData();
Step-by-step rationalization after header declaration:
-
get()is used to make a get request at our goal URL. -
headers()are used to cross HTTP request headers together with the request.
This block of code will return an HTML file and can seem like this:

Unreadable, proper? Don’t fear. We might be discussing an online parsing library in a bit.
As we all know, Google can block our request if we request with the identical Person Agent every time. So, if you wish to rotate Person-Brokers on every request, allow us to outline a perform that can return random Person-Agent strings from the Person-Agent array.
const selectRandom = () => {
const userAgents = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
]
var randomNumber = Math.flooring(Math.random() * userAgents.size);
return userAgents[randomNumber];
}
let user_agent = selectRandom();
let header = {
"Person-Agent": `${user_agent}`
}
This logic will guarantee we don’t have to make use of the identical Person-Brokers every time.
Benefits of Unirest:
- It has proxy assist.
- It helps all HTTP request strategies(GET,POST,DELETE,and so forth).
- It helps kind downloads.
- It helps TLS/SSL protocol.
- It helps HTTP authentication.
Axios
Axios is a promise-based HTTP shopper for Node JS and browsers and probably the most in style and highly effective javascript libraries. It will probably make XMLHttpRequests and HTTP from the browser Node JS respectively. It additionally has client-side assist for shielding towards the CSRF.
Allow us to take an instance of how we are able to use Axios for net scraping:
npm i axios
The under block of code will return the identical HTML file we noticed within the Unirest part.
const axios = require('axios');
let headers = {
"Person-Agent": "Mozilla/5.0 (Home windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 Viewer/96.9.4688.89"
}
axios.get('https://www.google.com/search?q=javascript&gl=us&hl=en' , headers)
.then((response) {
console.log(response.physique);
})
.catch((e) {
console.log(e);
});
Benefits of Axios:
- It will probably assist outdated browsers additionally, indicating wider browser assist.
- It helps response timeout.
- It will probably assist a number of requests on the identical time.
- It will probably intercept HTTP requests.
- Most necessary for builders, it has sensible group assist.
Cheerio
Cheerio is an online parsing library that may parse any HTML and XML doc. It implements a subset of jQuery, which is why its syntax is kind of just like jQuery.
Manipulating and rendering the markup may be accomplished very quick with the assistance of Cheerio. It doesn’t produce a visible rendering, apply CSS, load exterior assets, or execute Javascript.

Allow us to take a small instance of how we are able to use Cheerio to parse the Google adverts search outcomes.
You possibly can set up Cheerio by working the under command in your terminal.
npm i cheerio
Now, we’ll put together our parser by discovering the CSS selectors utilizing the SelectorGadget extension. Watch the tutorial on the selector gadget web site if you wish to discover ways to use it.
Allow us to first scrape the HTML with the assistance of unirest and make a cheerio occasion for parsing the HTML.
const cheerio = require("cheerio");
const unirest = require("unirest");
const getData = async() => {
strive
{
const url = "https://www.google.com/search?q=life+insurance coverage";
const response = await unirest
.get(url)
.headers({
"Person-Agent":
"Mozilla/5.0 (Home windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
})
const $ = cheerio.load(response.physique)

Within the final line, we simply created a continuing and loaded the scraped HTML in it. In the event you see the best backside of the web page, the outcomes of the adverts are underneath the tag .uEierd.
We’ll scrape the advert’s title, snippet, hyperlink, displayed hyperlink, and web site hyperlinks.

Have a look at the underside of the picture for the tag of the title.
Equally, for the snippet:
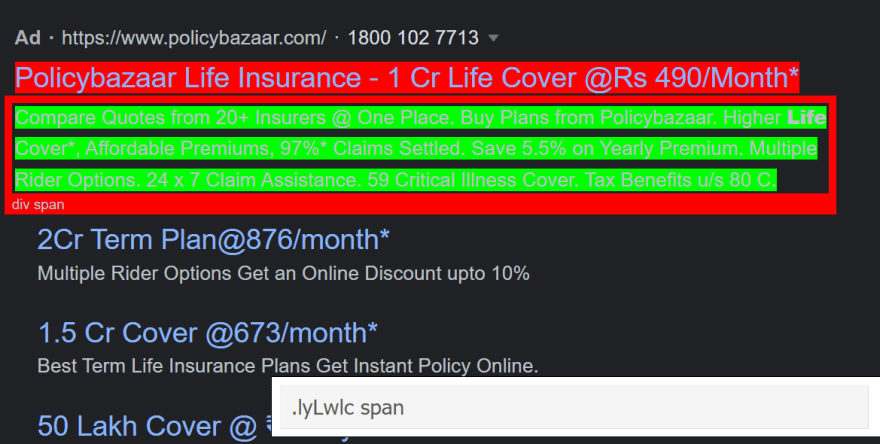
Allow us to discover the tag for the displayed hyperlink:

And in the event you examine the title, you can see the tag for the hyperlink to be a.sVXRqc.
After looking out all of the tags, our code will seem like this:
let adverts = [];
$("#tads .uEierd").every((i,el) => {
adverts[i] = {
title: $(el).discover(".v0nnCb span").textual content(),
snippet: $(el).discover(".lyLwlc").textual content(),
displayed_link: $(el).discover(".qzEoUe").textual content(),
hyperlink: $(el).discover("a.sVXRqc").attr("href"),
}
})
Now, allow us to discover tags for web site hyperlinks.

Now, equally, if we comply with the above course of to seek out the tags for sitelinks titles, snippets, and hyperlinks, our code will seem like this:
let sitelinks = [];
if($(el).discover(".UBEOKe").size)
{
$(el).discover(".MhgNwc").every((i,el) => {
sitelinks.push({
title: $(el).discover("h3").textual content(),
hyperlink: $(el).discover("a").attr("href"),
snippet: $(el).discover(".lyLwlc").textual content()
})
})
adverts[i].sitelinks = sitelinks
}
And our outcomes:

Full Code:
const cheerio = require("cheerio");
const unirest = require("unirest");
const getData = async() => {
strive
{
const url = "https://www.google.com/search?q=life+insurance coverage";
const response = await unirest
.get(url)
.headers({
"Person-Agent":
"Mozilla/5.0 (Home windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
})
const $ = cheerio.load(response.physique)
let adverts=[];
$("#tads .uEierd").every((i,el) => {
let sitelinks = [];
adverts[i] = {
title: $(el).discover(".v0nnCb span").textual content(),
snippet: $(el).discover(".lyLwlc").textual content(),
displayed_link: $(el).discover(".qzEoUe").textual content(),
hyperlink: $(el).discover("a.sVXRqc").attr("href"),
}
if($(el).discover(".UBEOKe").size)
{
$(el).discover(".MhgNwc").every((i,el) => {
sitelinks.push({
title: $(el).discover("h3").textual content(),
hyperlink: $(el).discover("a").attr("href"),
snippet: $(el).discover(".lyLwlc").textual content()
})
})
adverts[i].sitelinks = sitelinks
}
})
console.log(adverts)
}
catch(e)
{
console.log(e);
}
}
getData();
You possibly can see how straightforward it’s to make use of Cheerio JS for parsing HTML. Equally, we are able to use Cheerio with different net scraping libraries like Axios, Puppeteer, Playwright, and so forth.
If you wish to study extra about scraping web sites with Cheerio, you may think about my blogs the place I’ve used Cheerio as an online parser:
Benefits of Cheerio:
- Cheerio implements a subset of jQuery. It reveals its attractive API by eradicating all of the DOM inconsistencies from jQuery.
- Cheerio JS is extremely quick because it doesn’t produce visible rendering, apply CSS, load exterior assets, or execute Javascript, which is widespread in single-page purposes.
- It will probably parse practically any HTML and XML doc.
Headless Browsers
Gone are the times when web sites used to construct with solely HTML and CSS. These days, interplay on trendy web sites may be dealt with by javascript utterly, particularly the SPAs(single web page purposes), constructed on frameworks like React, Subsequent, and Angular are closely relied on Javascript for rendering the dynamic content material.
However when doing net scraping, the content material we require is typically rendered by Javascript, which isn’t accessible from the HTML response we get from the server.
And that’s the place the headless browser comes into play. Let’s focus on a number of the Javascript libraries which use headless browsers for net automation and scraping.
Puppeteer
Puppeteer is a Google-designed Node JS library that gives a high-quality API that lets you management Chrome or Chromium browsers.
Listed here are some options related to Puppeteer JS:
- It may be used to crawl single-page purposes and may generate pre-rendered content material, i.e., server-side rendering.
- It really works within the background and carry out actions as directed by the API.
- It will probably generate screenshots and pdf of net pages.
- It may be used for automate kind submission and UI testing.
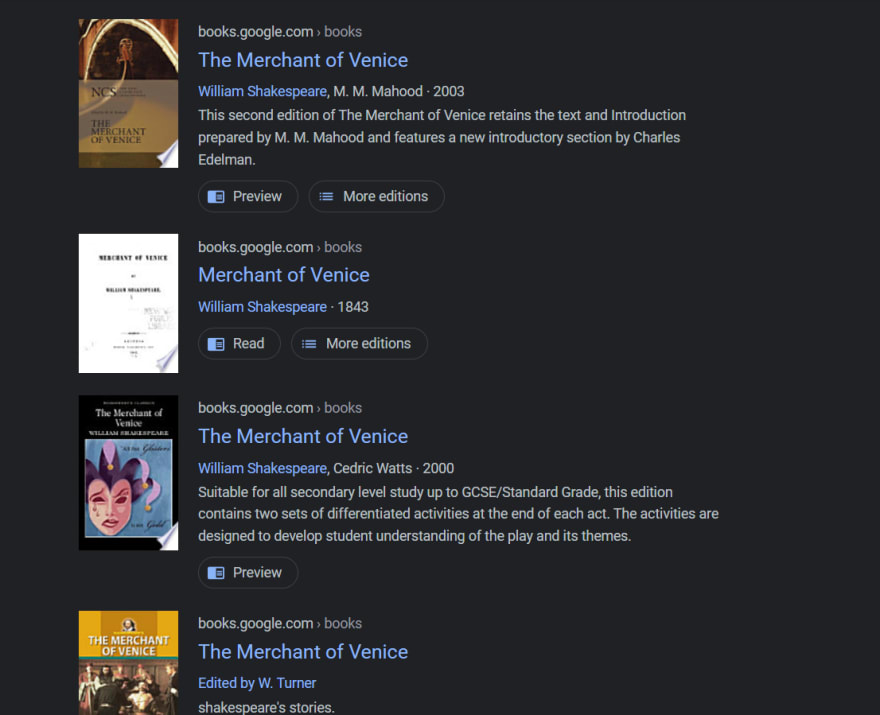
Allow us to take an instance of how we are able to scrape Google Books Outcomes utilizing Puppeteer JS. We’ll scrape the guide title, picture, description, and author.
First, set up puppeteer by working the under command in your venture terminal:
npm i puppeteer
Now, allow us to create an online crawler by launching the puppeteer in a non-headless mode.
const url = "https://www.google.com/search?q=service provider+of+venice&gl=us&tbm=bks";
browser = await puppeteer.launch({
headless: false,
args: ["--disabled-setuid-sandbox", "--no-sandbox"],
});
const web page = await browser.newPage();
await web page.setExtraHTTPHeaders({
"Person-Agent":
"Mozilla/5.0 (Home windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 Company/97.8.6287.88",
});
await web page.goto(url, { waitUntil: "domcontentloaded" });
What every line of code says:
-
puppeteer.launch()– This can launch chrome browser with non-headless mode. -
browser.newPage()– This can open a brand new tab within the browser. -
web page.setExtraHTTPHeaders()– This can enable us to set headers on our goal URL. -
web page.goto()– This can navigate us to our goal URL web page.
Now, allow us to discover the CSS selector for the guide title.

As you may see on the backside of the web page, the CSS selector of our title.
We’ll paste this in our code:
let books_results = [];
books_results = await web page.consider(() => {
return Array.from(doc.querySelectorAll(".Yr5TG")).map((el) => {
return {
title: el.querySelector(".DKV0Md")?.textContent
}
})
});
Right here I’ve used the web page.consider() perform to guage the web page’s context and returns the consequence.
Then I chosen the guardian handler of the title, which can be a guardian handler of different issues we wish to scrape(picture, author, description, and so forth as acknowledged above) utilizing the doc.querySelectorAll() technique.
And at last, we chosen the title from the weather current within the guardian handler container with the assistance of querySelector(). The textContent will enable us to seize the textual content inside the chosen component.
We’ll choose the opposite components simply in the identical means as we chosen the title. Now, allow us to discover the tag for the author.

books_results = await web page.consider(() => {
return Array.from(doc.querySelectorAll(".Yr5TG")).map((el) => {
return {
title: el.querySelector(".DKV0Md")?.textContent,
writers: el.querySelector(".N96wpd")?.textContent,
}
})
});
Allow us to discover the tag for our description as nicely.

let books_results = [];
books_results = await web page.consider(() => {
return Array.from(doc.querySelectorAll(".Yr5TG")).map((el) => {
return {
title: el.querySelector(".DKV0Md")?.textContent,
writers: el.querySelector(".N96wpd")?.textContent,
description: el.querySelector(".cmlJmd")?.textContent,
}
})
});
And at last for the picture:
let books_results = [];
books_results = await web page.consider(() => {
return Array.from(doc.querySelectorAll(".Yr5TG")).map((el) => {
return {
title: el.querySelector(".DKV0Md")?.textContent,
writers: el.querySelector(".N96wpd")?.textContent,
description: el.querySelector(".cmlJmd")?.textContent,
thumbnail: el.querySelector("img").getAttribute("src"),
}
})
});
console.log(books_results);
await browser.shut();
We don’t want to seek out the tag for the picture as it’s the solely picture within the container. So we simply used the “img” component for reference. Don’t neglect to shut the browser.
Now, allow us to run our program to examine the outcomes.

The lengthy URL you see as a thumbnail worth is nothing however a base64 picture URL. So, we acquired the outcomes we needed.
Full Code:
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const getBooksData = async () => {
const url = "https://www.google.com/search?q=service provider+of+venice&gl=us&tbm=bks";
browser = await puppeteer.launch({
headless: true,
args: ["--disabled-setuid-sandbox", "--no-sandbox"],
});
const web page = await browser.newPage();
await web page.setExtraHTTPHeaders({
"Person-Agent":
"Mozilla/5.0 (Home windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 Company/97.8.6287.88",
});
await web page.goto(url, { waitUntil: "domcontentloaded" });
let books_results = [];
books_results = await web page.consider(() => {
return Array.from(doc.querySelectorAll(".Yr5TG")).map((el) => {
return {
title: el.querySelector(".DKV0Md")?.textContent,
writers: el.querySelector(".N96wpd")?.textContent,
description: el.querySelector(".cmlJmd")?.textContent,
thumbnail: el.querySelector("img").getAttribute("src"),
}
})
});
console.log(books_results)
await browser.shut();
};
getBooksData();
So, we now have now understood a fundamental understanding of Puppeteer JS. Now, let’s focus on its some benefits.
Benefits of Puppeteer:
- We are able to scroll the web page in puppeteer js.
- We are able to click on on components like buttons and hyperlinks.
- We are able to take screenshots and also can make pdf of the online web page.
- We are able to navigate between the online pages.
- We are able to parse Javascript additionally with the assistance of Puppeteer JS.
Playwright JS
Playwright JS is a check automation framework utilized by builders around the globe to automate net browsers. The identical workforce that labored on Puppeteer JS beforehand has developed the Playwright JS. You will see that the syntax of Playwright JS to be just like Puppeteer JS, the API technique in each instances are additionally an identical, however each languages have some variations. Let’s focus on them:
Playwright v/s Puppeteer JS:
- Playwright helps a number of languages like C#, .NET, Javascript, and so forth. Whereas the latter solely helps Javascript.
- The Playwright JS remains to be a brand new library with restricted group assist, not like Puppeteer JS, which has good group assist.
- Playwright helps browsers like Chromium, Firefox, and Webkit, whereas Puppeteer most important focus is Chrome and Chromium, with restricted assist for Firefox.

Allow us to take an instance of how we are able to use Playwright JS to scrape High Tales from Google Search Outcomes. First, set up playwright by working the under command in your terminal:
npm i playwright
Now, let’s create our scraper by launching the chromium browser at our goal URL.
const browser = await playwright['chromium'].launch({ headless: false, args: ['--no-sandbox'] });
const context = await browser.newContext();
const web page = await context.newPage();
await web page.goto("https://www.google.com/search?q=india&gl=us&hl=en");
Step-by-step rationalization:
- Step one will launch the chromium browser in non-headless mode.
- The second step creates a brand new browser context. It will not share cookies/cache with different browser contexts.
- The third step opens a brand new tab within the browser.
- Within the fourth step, we navigate to our goal URL.
Now, allow us to seek for the tags for these single tales.
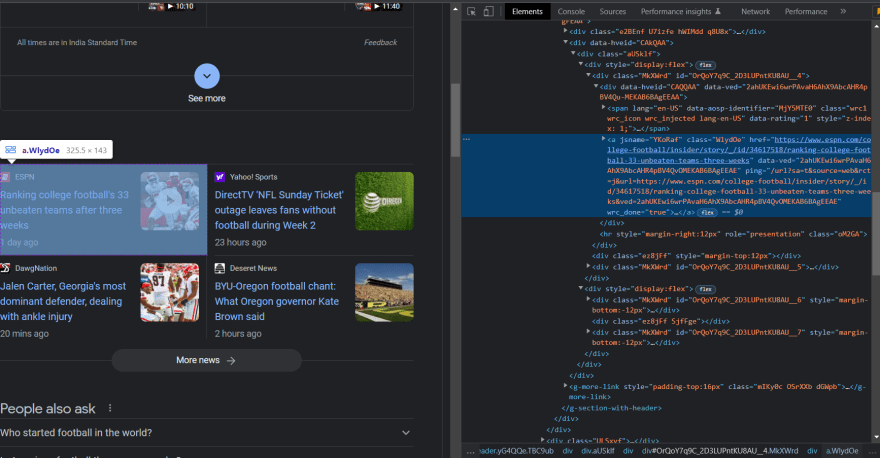
As you may see each single story comes underneath the .WlydOe tag. This technique web page.$$ will discover all components matching the required selector inside the web page and can return the array containing all these components.
Search for tags of the title, date, and thumbnail, with the identical strategy as we now have accomplished within the Puppeteer part. After discovering the tags push the info in our top_stories array and shut the browser.
let top_stories = [];
for(let single_story of single_stories)
{
top_stories.push({
title: await single_story.$eval(".mCBkyc", el => el.textContent.change('n','')),
hyperlink: await single_story.getAttribute("href"),
date: await single_story.$eval(".eGGgIf", el => el.textContent),
thumbnail: await single_story.$eval("img", el => el.getAttribute("src"))
})
}
console.log(top_stories)
await browser.shut();
The $eval will discover the required component contained in the guardian component we declared above in single_stories array. The textContent will return the textual content inside the required component and getAttribute will return the worth of the required component’s attribute.
Our consequence will ought to seem like this:
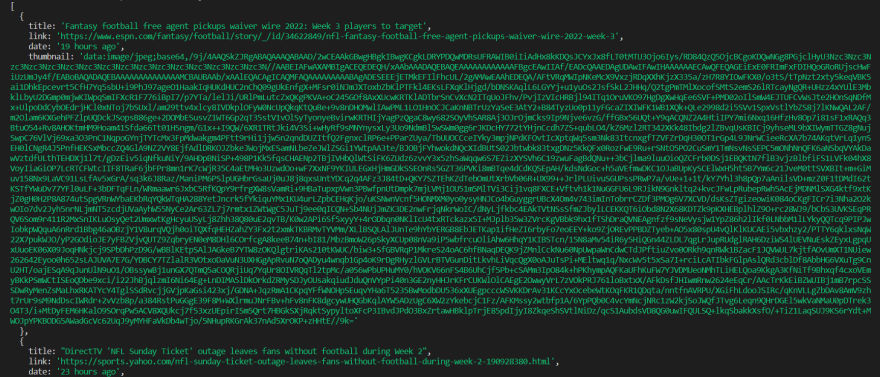
Right here is the full code:
const playwright = require("playwright");
const getTopStories = async () => {
strive {
const browser = await playwright['chromium'].launch({ headless: false, args: ['--no-sandbox'] });
const context = await browser.newContext();
const web page = await context.newPage();
await web page.goto("https://www.google.com/search?q=soccer&gl=us&hl=en");
const single_stories = await web page.$$(".WlydOe");
let top_stories = [];
for(let single_story of single_stories)
{
top_stories.push({
title: await single_story.$eval(".mCBkyc", el => el.textContent.change('n','')),
hyperlink: await single_story.getAttribute("href"),
date: await single_story.$eval(".eGGgIf", el => el.textContent),
thumbnail: await single_story.$eval("img", el => el.getAttribute("src"))
})
}
console.log(top_stories)
await browser.shut();
} catch (e) {
console.log(e);
}
};
getTopStories();
Benefits of Playwright:
- It allows auto-wait for components earlier than performing any duties.
- It permits you to check your net purposes in cellular browsers.
- It comes within the record of one of many quickest processing libraries in terms of net scraping.
- It covers all trendy net browsers like Chrome, Edge, Safari, and Firefox.
Recap
The above sections taught us to scrape and parse Google Search Outcomes with numerous Javascript libraries. We additionally noticed how we are able to use a mix of Unirest and Cheerio and Axios and Cheerio to extract the info from Google. It’s apparent, if you wish to scrape thousands and thousands of pages of Google, that received’t work with out proxies and captchas.
However, wait! You possibly can nonetheless use Serpdog’s | Google Search API that solves all of your issues of dealing with proxies and captchas enabling you to scrape thousands and thousands of Google Search Outcomes with none hindrance.
Additionally, you require a big pool of consumer brokers to make thousands and thousands of requests on Google. However in the event you use the identical consumer agent every time you request, your proxies will get blocked. Serpdog additionally solves this drawback as our Google Search API makes use of a big pool of Person Brokers to scrape Google Search Outcomes efficiently.
Furthermore, Serpdog gives its customers 100 free credit on the primary sign-up.
Listed here are some articles if you wish to know extra about find out how to scrape Google:
- Scrape Google Procuring Outcomes
- Internet Scraping Google Information Outcomes
- Scrape Google Procuring Product Outcomes
Different Libraries
On this part, we’ll focus on a number of the alternate options to the above-discussed libraries.
Nightmare JS
Nightmare JS is an online automation library designed for web sites that don’t personal APIs and wish to automate searching duties.
Nightmare JS is usually utilized by builders for UI testing and crawling. It will probably additionally assist mimic consumer actions(like goto, sort, and click on) with an API that feels synchronous for every block of scripting.
Allow us to take an instance of how we are able to use Nightmare JS to scrape the Google Search Twitter Outcomes.

Set up the Nightmare JS by working this command:
npm i nightmare
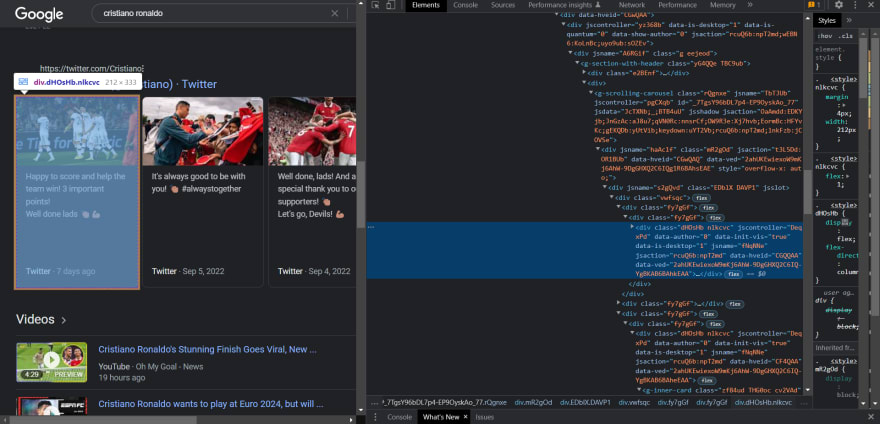
As you may see within the above picture, every Twitter result’s underneath the tag .dHOsHb. So, this makes our code seem like this:
const Nightmare = require("nightmare")
const nightmare = Nightmare()
nightmare.goto("https://www.google.com/search?q=cristiano+ronaldo&gl=us")
.wait(".dHOsHb")
.consider(() => {
let twitter_results = [];
const outcomes = doc.querySelectorAll(".dHOsHb")
outcomes.forEach((consequence) => {
let row = {
"tweet": consequence.innerText,
}
twitter_results.push(row)
})
return twitter_results;
})
.finish()
.then((consequence) => {
consequence.forEach((r) => {
console.log(r.tweet);
})
})
.catch((error) => {
console.log(error)
})
Step-by-step rationalization:
- After importing the library, we created an occasion of Nightmare JS with the identify nightmare.
- Then we use
goto()to navigate to our goal URL. - Within the subsequent step, we used
wait()to attend for the chosen tag of the twitter consequence. You may as well cross a time worth as a parameter to attend for a selected interval. - Then we used
consider(), which invokes features on the web page, in our case, it’squerySelectorAll(). - Within the subsequent step, we used the
forEach()perform to iterate over the outcomes array and fill every component with the textual content content material. - Eventually we known as the
finish()to cease the crawler and returned our scraped worth.
Listed here are our outcomes:

Node Fetch
Node Fetch is a light-weight module that brings Fetch API to Node JS, or you may say it allows to make use of of the fetch() performance in Node JS.
Options:
Use native promise and async features.
It’s according to window.fetch API.
It makes use of native Node streams for the physique, on each request and response.
To make use of Node Fetch run this command in your venture terminal:
npm i node-fetch@2
Allow us to take a easy instance to request our goal URL:
const fetch = require("node-fetch");
const getData = async() => {
const response = await fetch("https://google.com/search?q=net+scraping&gl=us" , {
headers: {
“Person-Agent”:
"Mozilla/5.0 (Home windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 Company/97.8.6287.88"
}
});
const physique = await response.textual content();
console.log(physique);
}
getData();
Osmosis
Osmosis is an HTML/XML parser for Node JS.
Options:
- It helps CSS 3.0 and XPath 1.0 selector hybrids.
- It’s a very quick parser with a small reminiscence footprint.
- No giant dependencies like jQuery, cheerio JS.
Benefits of Osmosis:
- It helps quick looking out.
- Helps single or a number of proxies and handles their failures.
- Assist kind submission and session cookies.
- Retries and redirect limits.
Conclusion
On this tutorial, we mentioned eight Javascript libraries that can be utilized for net scraping Google Search Outcomes. We additionally discovered some examples to scrape search outcomes. Every of those libraries has distinctive options and benefits, some are simply new, and a few have been up to date and adopted based on developer wants. Thus, you recognize which library to decide on based on the circumstances.
You probably have any questions concerning the tutorial, please be happy to ask me.
In the event you assume I’ve not coated some subjects within the tutorial, please be happy to message me.
Extra Sources
- Scrape Google Autocomplete Outcomes
- Scrape Google Photographs Outcomes
- Scrape Google Scholar Outcomes
Often Requested Questions
1. Which Javascript library is greatest for net scraping?
When choosing the right library for net scraping, think about that library that’s simpler to make use of, a library that has good group assist and may stand up to giant quantities of information.
2. From the place ought to I begin studying scraping Google?
This tutorial is designed for learners to develop a fundamental understanding to scrape Google. And if anybody desires to study extra, I’ve already made numerous blogs on scraping Google, which you’ll see on the Serpdog’s Weblog net web page, which gives you an intermediate to superior understanding of scraping Google.
3. Is net scraping Google laborious?
Internet scraping Google is just about straightforward! Even a developer with respectable information can kickstart his profession in net scraping if given the best device.
4. Is net scraping authorized?
Sure. All the info publicly out there on the web is authorized to scrape.
Donation Enchantment
Hey, are you able to purchase me a espresso. It will assist me to maintain writing some of these blogs.



{kind=link}