Introduction
This information is the third and last a part of three guides about Help Vector Machines (SVMs). On this information, we are going to preserve working with the solid financial institution notes use case, have a fast recap concerning the common concept behind SVMs, perceive what’s the kernel trick, and implement various kinds of non-linear kernels with Scikit-Be taught.
Within the full sequence of SVM guides, in addition to studying about different kinds of SVMs, additionally, you will find out about easy SVM, SVM pre-defined parameters, C and Gamma hyperparameters and the way they are often tuned with grid search and cross validation.
In the event you want to learn the earlier guides, you possibly can check out the primary two guides or see which subjects curiosity you essentially the most. Under is the desk of subjects lined in every information:
- Use case: neglect financial institution notes
- Background of SVMs
- Easy (Linear) SVM Mannequin
- In regards to the Dataset
- Importing the Dataset
- Exploring the Dataset
- Implementing SVM with Scikit-Be taught
- Dividing Information into Practice/Take a look at Units
- Coaching the Mannequin
- Making Predictions
- Evaluating the Mannequin
- Deciphering Outcomes
- The C Hyperparameter
- The Gamma Hyperparameter
3. Implementing different SVM flavors with Python’s Scikit-Be taught
- The Basic Thought of SVMs (a recap)
- Kernel (Trick) SVM
- Implementing Non-Linear Kernel SVM with Scikit-Be taught
- Importing Libraries
- Importing the Dataset
- Dividing Information Into Options (X) and Goal (y)
- Dividing Information Into Practice/Take a look at Units
- Coaching the Algorithm
- Polynomial kernel
- Making Predictions
- Evaluating the Algorithm
- Gaussian kernel
- Prediction and Analysis
- Sigmoid Kernel
- Prediction and Analysis
- Comparability of Non-Linear Kernel Performances
Let’s bear in mind what SVM is all about earlier than seeing some attention-grabbing SVM kernel variations.
The Basic Thought of SVMs
In case of linearly separable information in two dimensions (as proven in Fig. 1) the standard machine studying algorithm method could be to attempt to discover a boundary that divides the info in such a manner that the misclassification error is minimized. In the event you look carefully at determine 1, discover there might be a number of boundaries (infinite) that divide the info factors accurately. The 2 dashed strains in addition to the strong line are all legitimate classifications of the info.
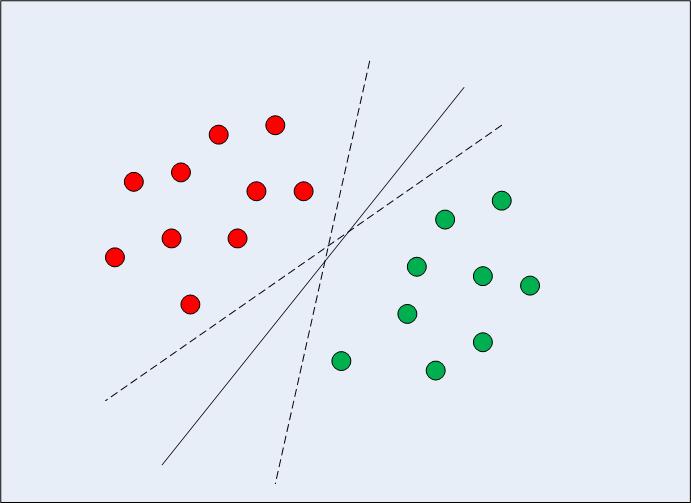
Fig 1: A number of Resolution Boundaries
When SVM chooses the resolution boundary, it chooses a boundary that maximizes the space between itself and the closest information factors of the courses. We already know that the closest information factors are the assist vectors and that the space might be parametrized each by C and gamma hyperparameters.
In calculating that call boundary, the algorithm chooses what number of factors to contemplate and the way far the margin can go – this configures a margin maximization downside. In fixing that margin maximization downside, SVM makes use of the assist vectors (as seen in Fig. 2) and tries to determine what are optimum values that preserve the margin distance larger, whereas classifying extra factors accurately in accordance with the perform that’s getting used to separate the info.
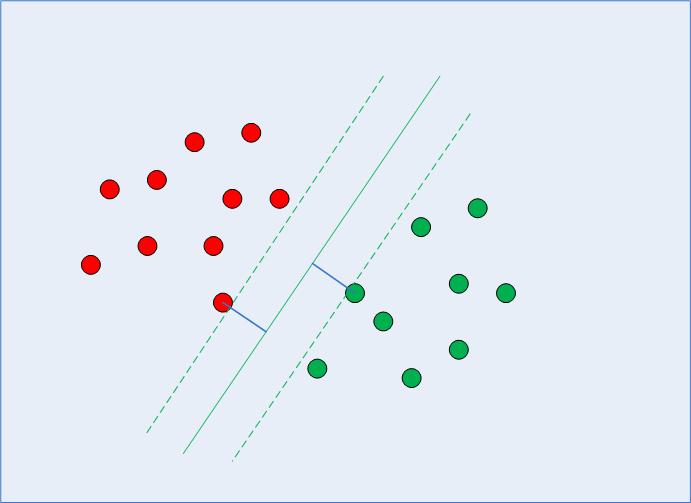
Fig 2: Resolution Boundary with Help Vectors
For this reason SVM differs from different classification algorithms, as soon as it does not merely discover a resolution boundary, however it finally ends up discovering the optimum resolution boundary.
There’s complicated arithmetic derived from statistics and computational strategies concerned behind discovering the assist vectors, calculating the margin between the choice boundary and the assist vectors, and maximizing that margin. This time, we won’t go into the small print of how the arithmetic play out.
It’s all the time vital to dive deeper and ensure machine studying algorithms usually are not some sort of mysterious spell, though not understanding each mathematical element at the moment did not and will not cease you from with the ability to execute the algorithm and acquire outcomes.
Recommendation: now that we’ve made a recap of the algorithmic course of, it’s clear that the space between information factors will have an effect on the choice boundary SVM chooses, due to that, scaling the info is often obligatory when utilizing an SVM classifier. Attempt utilizing Scikit-learn’s Commonplace Scaler methodology to organize information, after which operating the codes once more to see if there’s a distinction in outcomes.
Kernel (Trick) SVM
Within the earlier part, we’ve remembered and arranged the overall concept of SVM – seeing how it may be used to seek out the optimum resolution boundary for linearly separable information. Nevertheless, within the case of non-linearly separable information, such because the one proven in Fig. 3, we already know {that a} straight line can’t be used as a call boundary.
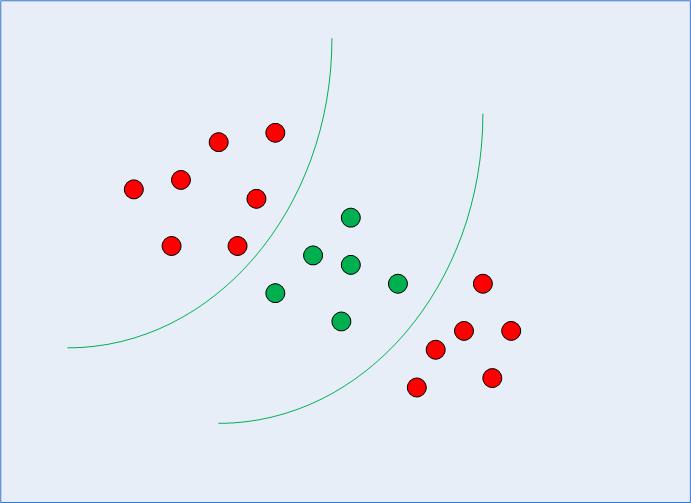
Fig 3: Non-linearly Separable Information
Quite, we are able to use the modified model of SVM we had mentioned at first, known as Kernel SVM.
Mainly, what the kernel SVM will do is to venture the non-linearly separable information of decrease dimensions to its corresponding kind in larger dimensions. It is a trick, as a result of when projecting non-linearly separable information in larger dimensions, the info form adjustments in such a manner that it turns into separable. As an illustration, when fascinated about 3 dimensions, the info factors from every class may find yourself being allotted in a special dimension, making it separable. A method of accelerating the info dimensions might be by means of exponentiating it. Once more, there may be complicated arithmetic concerned on this, however you wouldn’t have to fret about it to be able to use SVM. Quite, we are able to use Python’s Scikit-Be taught library to implement and use the non-linear kernels in the identical manner we’ve used the linear.
Implementing Non-Linear Kernel SVM with Scikit-Be taught
On this part, we are going to use the identical dataset to foretell whether or not a financial institution word is actual or cast in accordance with the 4 options we already know.
You will notice that the remainder of the steps are typical machine studying steps and want little or no rationalization till we attain the half the place we practice our Non-linear Kernel SVMs.
Importing Libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
Importing the Dataset
data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ["variance", "skewness", "curtosis", "entropy", "class"]
bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()mes)
Dividing Information Into Options (X) and Goal (y)
X = bankdata.drop('class', axis=1)
y = bankdata['class']
Dividing Information into Practice/Take a look at Units
SEED = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
Coaching the Algorithm
To coach the kernel SVM, we are going to use the identical SVC class of the Scikit-Be taught’s svm library. The distinction lies within the worth for the kernel parameter of the SVC class.
Within the case of the straightforward SVM we’ve used “linear” as the worth for the kernel parameter. Nevertheless, as we’ve talked about earlier, for kernel SVM, we are able to use Gaussian, polynomial, sigmoid, or computable kernels. We’ll implement polynomial, Gaussian, and sigmoid kernels and have a look at its last metrics to see which one appears to suit our courses with the next metric.
1. Polynomial kernel
In algebra, a polynomial is an expression of the shape:
$$
2a*b^3 + 4a – 9
$$
This has variables, comparable to a and b, constants, in our instance, 9 and coefficients (constants accompanied by variables), comparable to 2 and 4. The 3 is taken into account to be the diploma of the polynomial.
There are kinds of information that may greatest be described when utilizing a polynomial perform, right here, what the kernel will do is to map our information to a polynomial to which we are going to select the diploma. The upper the diploma, the extra the perform will attempt to get nearer to the info, so the choice boundary is extra versatile (and extra vulnerable to overfit) – the decrease the diploma, the least versatile.
Try our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and truly be taught it!
So, for implementing the polynomial kernel, in addition to selecting the poly kernel, we may even go a price for the diploma parameter of the SVC class. Under is the code:
from sklearn.svm import SVC
svc_poly = SVC(kernel='poly', diploma=8)
svc_poly.match(X_train, y_train)
Making Predictions
Now, as soon as we’ve educated the algorithm, the following step is to make predictions on the check information.
As we’ve completed earlier than, we are able to execute the next script to take action:
y_pred_poly = svclassifier.predict(X_test)
Evaluating the Algorithm
As traditional, the ultimate step is to make evaluations on the polynomial kernel. Since we’ve repeated the code for the classification report and the confusion matrix just a few occasions, let’s remodel it right into a perform that display_results after receiving the respectives y_test, y_pred and title to the Seaborn’s confusion matrix with cm_title:
def display_results(y_test, y_pred, cm_title):
cm = confusion_matrix(y_test,y_pred)
sns.heatmap(cm, annot=True, fmt='d').set_title(cm_title)
print(classification_report(y_test,y_pred))
Now, we are able to name the perform and have a look at the outcomes obtained with the polynomial kernel:
cm_title_poly = "Confusion matrix with polynomial kernel"
display_results(y_test, y_pred_poly, cm_title_poly)
The output appears to be like like this:
precision recall f1-score assist
0 0.69 1.00 0.81 148
1 1.00 0.46 0.63 127
accuracy 0.75 275
macro avg 0.84 0.73 0.72 275
weighted avg 0.83 0.75 0.73 275

Now we are able to repeat the identical steps for Gaussian and sigmoid kernels.
2. Gaussian kernel
To make use of the gaussian kernel, we solely have to specify ‘rbf’ as worth for the kernel parameter of the SVC class:
svc_gaussian = SVC(kernel='rbf', diploma=8)
svc_gaussian.match(X_train, y_train)
When additional exploring this kernel, it’s also possible to use grid search to mix it with totally different C and gamma values.
Prediction and Analysis
y_pred_gaussian = svc_gaussian.predict(X_test)
cm_title_gaussian = "Confusion matrix with Gaussian kernel"
display_results(y_test, y_pred_gaussian, cm_title_gaussian)
The output of the Gaussian kernel SVM appears to be like like this:
precision recall f1-score assist
0 1.00 1.00 1.00 148
1 1.00 1.00 1.00 127
accuracy 1.00 275
macro avg 1.00 1.00 1.00 275
weighted avg 1.00 1.00 1.00 275

3. Sigmoid Kernel
Lastly, let’s use a sigmoid kernel for implementing Kernel SVM. Check out the next script:
svc_sigmoid = SVC(kernel='sigmoid')
svc_sigmoid.match(X_train, y_train)
To make use of the sigmoid kernel, you need to specify ‘sigmoid’ as worth for the kernel parameter of the SVC class.
Prediction and Analysis
y_pred_sigmoid = svc_sigmoid.predict(X_test)
cm_title_sigmoid = "Confusion matrix with Sigmoid kernel"
display_results(y_test, y_pred_sigmoid, cm_title_sigmoid)
The output of the Kernel SVM with Sigmoid kernel appears to be like like this:
precision recall f1-score assist
0 0.67 0.71 0.69 148
1 0.64 0.59 0.61 127
accuracy 0.65 275
macro avg 0.65 0.65 0.65 275
weighted avg 0.65 0.65 0.65 275

Comparability of Non-Linear Kernel Performances
If we briefly examine the efficiency of the various kinds of non-linear kernels, it may appear that the sigmoid kernel has the bottom metrics, so the worst efficiency.
Amongst the Gaussian and polynomial kernels, we are able to see that the Gaussian kernel achieved an ideal 100% prediction fee – which is often suspicious and should point out an overfit, whereas the polynomial kernel misclassified 68 situations of sophistication 1.
Subsequently, there isn’t any exhausting and quick rule as to which kernel performs greatest in each state of affairs or in our present state of affairs with out additional trying to find hyperparameters, understanding about every perform form, exploring the info, and evaluating practice and check outcomes to see if the algorithm is generalizing.
It’s all about testing all of the kernels and choosing the one with the mix of parameters and information preparation that give the anticipated outcomes in accordance with the context of your venture.
Going Additional – Hand-held end-to-end venture
Your inquisitive nature makes you wish to go additional? We advocate trying out our Guided Mission: “Fingers-On Home Value Prediction – Machine Studying in Python”.

On this guided venture – you will learn to construct highly effective conventional machine studying fashions in addition to deep studying fashions, make the most of Ensemble Studying and coaching meta-learners to foretell home costs from a bag of Scikit-Be taught and Keras fashions.
Utilizing Keras, the deep studying API constructed on high of Tensorflow, we’ll experiment with architectures, construct an ensemble of stacked fashions and practice a meta-learner neural community (level-1 mannequin) to determine the pricing of a home.
Deep studying is wonderful – however earlier than resorting to it, it is suggested to additionally try fixing the issue with easier strategies, comparable to with shallow studying algorithms. Our baseline efficiency will probably be based mostly on a Random Forest Regression algorithm. Moreover – we’ll discover creating ensembles of fashions by means of Scikit-Be taught through strategies comparable to bagging and voting.
That is an end-to-end venture, and like all Machine Studying tasks, we’ll begin out with – with Exploratory Information Evaluation, adopted by Information Preprocessing and at last Constructing Shallow and Deep Studying Fashions to suit the info we have explored and cleaned beforehand.
Conclusion
On this article we made a fast recap on SVMs, studied concerning the kernel trick and applied totally different flavors of non-linear SVMs.
I counsel you implement every kernel and preserve going additional. You may discover the arithmetic used to create every of the totally different kernels, why they have been created and the variations relating to their hyperparameters. In that manner, you’ll be taught concerning the strategies and what kind of kernel is greatest to use relying on the context and the info out there.
Having a transparent understanding of how every kernel works and when to make use of them will certainly aid you in your journey. Tell us how the progress goes and completely satisfied coding!

{kind=link}