Learn to correctly load your worksheets into Pandas DataFrames
In most information analytics tasks, one of the widespread and common information file codecs that you’ll often encounter is CSV. Nonetheless, individuals from the monetary sector usually take care of one other format — Excel spreadsheets.
Whereas quite a lot of articles on Pandas DataFrame concentrate on loading utilizing CSV recordsdata, on this article I’ll focus my dialogue on Excel. I’ll present you easy methods to load worksheets from Excel into your dataframes, in addition to some suggestions and tips for loading a part of the worksheet onto a dataframe.
For this text, I’ll use two pattern Excel spreadsheets.
Notice: All photographs and screenshots on this article have been created by writer
Associated Readings
Ideas and Tips for Loading Massive CSV Information into Pandas DataFrames — Half 2 (https://towardsdatascience.com/tips-and-tricks-for-loading-large-csv-files-into-pandas-dataframes-part-2-5fc02fc4e3ab)
Ideas and Tips for Loading Massive CSV Information into Pandas DataFrames — Half 1 (https://towardsdatascience.com/tips-and-tricks-for-loading-large-csv-files-into-pandas-dataframes-part-1-fac6e351fe79)
My first pattern Excel spreadsheet (mydata.xls; self-created) accommodates two worksheets:
The information from the 2 worksheets have been obtained from the Flights Delay dataset — https://www.kaggle.com/datasets/usdot/flight-delays. Licensing: CC0: Public Area
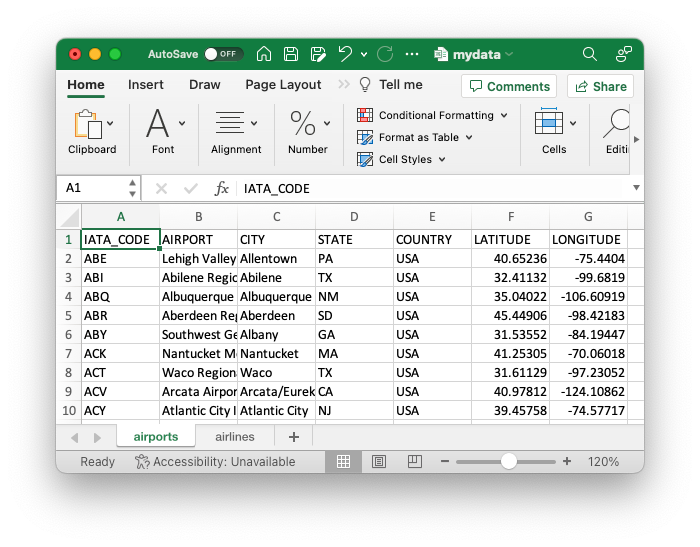
Here’s what the airports worksheet seems to be like:

Here’s what the airways worksheet seems to be like:

Observe that the airways worksheet doesn’t comprise a header.
To load the older .xls format Excel file, it is advisable set up the xlrd bundle:
xlrd is a library for studying information and formatting info from Excel recordsdata within the historic .xls format.
pip set up xlrd
Let’s attempt to load the information within the Excel spreadsheet utilizing the read_excel() operate in Pandas:
import pandas as pddf = pd.read_excel('mydata.xls')
df
Right here is the content material of the dataframe:

Discover that solely the primary worksheet is loaded, despite the fact that our Excel spreadsheet has two worksheets.
To load all of the worksheets within the Excel spreadsheet, set the sheet_name parameter to None:
df = pd.read_excel('mydata.xls',
sheet_name=None)
print(df)
The outcome will not be a Pandas DataFrame anymore; somewhat it’s a dictionary of dataframes:
{'airports': IATA_CODE AIRPORT
0 ABE Lehigh Valley Worldwide Airport
1 ABI Abilene Regional Airport
2 ABQ Albuquerque Worldwide Sunport
3 ABR Aberdeen Regional Airport
4 ABY Southwest Georgia Regional Airport
.. ... ...
317 WRG Wrangell Airport
318 WYS Westerly State Airport
319 XNA Northwest Arkansas Regional Airport
320 YAK Yakutat Airport
321 YUM Yuma Worldwide Airport CITY STATE COUNTRY LATITUDE LONGITUDE
0 Allentown PA USA 40.65236 -75.44040
1 Abilene TX USA 32.41132 -99.68190
2 Albuquerque NM USA 35.04022 -106.60919
3 Aberdeen SD USA 45.44906 -98.42183
4 Albany GA USA 31.53552 -84.19447
.. ... ... ... ... ...
317 Wrangell AK USA 56.48433 -132.36982
318 West Yellowstone MT USA 44.68840 -111.11764
319 Fayetteville/Springdale/Rogers AR USA 36.28187 -94.30681
320 Yakutat AK USA 59.50336 -139.66023
321 Yuma AZ USA 32.65658 -114.60597
[322 rows x 7 columns], 'airways': UA United Air Strains Inc.
0 AA American Airways Inc.
1 US US Airways Inc.
2 F9 Frontier Airways Inc.
3 B6 JetBlue Airways
4 OO Skywest Airways Inc.
5 AS Alaska Airways Inc.
6 NK Spirit Air Strains
7 WN Southwest Airways Co.
8 DL Delta Air Strains Inc.
9 EV Atlantic Southeast Airways
10 HA Hawaiian Airways Inc.
11 MQ American Eagle Airways Inc.
12 VX Virgin America}
The keys within the outcome are the names of the worksheets. The next assertion shows the dataframe loaded for the airports worksheet:
show(df['airports'])

Likewise, the next assertion shows dataframe loaded for the airways worksheet:
show(df['airlines'])

Don’t fear in regards to the headers; I’ll repair it shortly.
If you wish to load particular worksheets, retailer the names of the worksheets you need to load as an inventory and go it to the sheet_name property:
df = pd.read_excel('mydata.xls',
sheet_name=['airports','airlines'])
print(df)
The above assertion hundreds the airports and airways worksheets and the result’s a dictionary of dataframes.
You may look at the information kind for every of the columns loaded within the airports dataframe utilizing the dtypes attribute:
df['airports'].dtypes
Observe that Pandas will load them in response to the forms of values for every column within the worksheet:
IATA_CODE object
AIRPORT object
CITY object
STATE object
COUNTRY object
LATITUDE float64
LONGITUDE float64
dtype: object
Particularly, for the airports dataframe, the STATE and COUNTRY columns ought to ideally be represented because the class kind, somewhat than the object kind. That is to cut back the reminiscence footprint of the dataframe. You may carry out the sort conversion throughout loading time utilizing the dtype parameter:
import numpy as npdf = pd.read_excel('mydata.xls',
sheet_name='airports',
dtype= {
'STATE': 'class',
'COUNTRY':'class'
})
df.dtypes
Within the above assertion, I load the airports worksheet and point out that each the STATE and COUNTRY columns be loaded utilizing the class information kind. You may confirm this after the dataframe has been loaded:
IATA_CODE object
AIRPORT object
CITY object
STATE class
COUNTRY class
LATITUDE float64
LONGITUDE float64
dtype: object
Moreover loading columns to be of a selected kind, you may also carry out values conversion throughout loading time utilizing the converters parameter. For instance, suppose I need to convert all of the latitude and longitude values to the levels, minutes, and seconds format.
I first outline the operate to do the conversion:
# convert from decimal levels to levels, minutes, seconds
def deg_to_dms(deg):
deg = float(deg)
m, s = divmod(abs(deg)*3600, 60)
d, m = divmod(m, 60)
return int(-d if deg < 0 else d), int(m), s
Then, specify the column(s) you need to convert utilizing the converters parameter:
df = pd.read_excel('mydata.xls',
sheet_name='airports',
dtype= {
'STATE': 'class',
'COUNTRY':'class'
},
converters={
'LATITUDE': deg_to_dms,
'LONGITUDE': deg_to_dms,
})
df
Right here it the results of the conversion:

Inspecting the information forms of the columns:
df.dtypes
You will note that each the LATITUDE and LONGITUDE columns are of object kind:
IATA_CODE object
AIRPORT object
CITY object
STATE class
COUNTRY class
LATITUDE object
LONGITUDE object
dtype: object
If you happen to attempt to extract the latitude worth of the primary row:
lat_first_row = df.iloc[0,5]
kind(lat_first_row)
You will note that the worth is of kind tuple:
tuple
Earlier I discussed that the airways worksheet doesn’t have a header. And so if you happen to load it right into a dataframe:
df = pd.read_excel('mydata.xls',
sheet_name='airways')
df
The result’s that the content material of the primary row can be used because the headers:

Clearly this isn’t acceptable. To repair it, use the header parameter and set it to None:
df = pd.read_excel('mydata.xls',
sheet_name='airways',
header=None)
df
The default headers of 0 and 1 will now be used:

You may change the headers by utilizing the names parameter:
df = pd.read_excel('mydata.xls',
sheet_name='airways',
header=None,
names=['IATA_CODE','AIRLINE'])
df
The column names are actually set:

If you happen to solely need to load particular columns within the worksheet, you need to use the usecols parameter:
df = pd.read_excel('mydata.xls',
sheet_name='airports',
usecols=['IATA_CODE','AIRPORT','CITY','STATE','COUNTRY'])
df
Within the above assertion, I solely need to load the ‘IATA_CODE’, ’AIRPORT’, ’CITY’, ’STATE’, and ’COUNTRY’ columns:

Basically, you might be omitting the LATITUDE and LONGITUDE columns. On this case, it could be simpler to specify what to omit, utilizing a lambda operate:
df = pd.read_excel('mydata.xls',
sheet_name='airports',
usecols=lambda column: column not in ['LATITUDE','LONGITUDE'])
df
One other method is to specify the column names to load within the Excel spreadsheet. Hey, keep in mind we’re working with an Excel spreadsheet? The next assertion reveals easy methods to load columns F (LATITUDE) by way of G (LONGITUDE) utilizing the Excel-way:
df = pd.read_excel('mydata.xls',
sheet_name='airports',
usecols='F:G')
df
Right here is the outcome:

If you happen to additionally need the IATA_CODE and AIRPORT columns, you are able to do it simply, like this!
df = pd.read_excel('mydata.xls',
sheet_name='airports',
usecols='A,B,F:G')
df
The outcome now accommodates 4 columns:

To date the primary Excel spreahsheet is fairly easy (I’d say it’s too sanitized for the actual world). The second dataset that I’ll use is extra sensible and it may be downloaded from https://information.world/davelaff/restaurant-inventory-log.
This can be a restaurant stock workbook. The information is actual however is much from present. Costs listed should not precise costs. LICENSE: Public Area
This Excel spreadsheet accommodates two worksheets:
- Stock Worksheets
- Subcategory Stock Worth
Here’s what the Stock Worksheets seems to be like:

And right here is the Subcategory Stock Worth worksheet:

To load the newer .xlsx Excel file format, it is advisable set up the openpyxl bundle:
pip set up openpyxl
openpyxl is a Python library to learn/write Excel 2010 xlsx/xlsm recordsdata.
Let’s load the primary worksheet:
df = pd.read_excel('RESTAURANT INVENTORY LOG.xlsx',
sheet_name='Stock Worksheets')df
Right here’s the output:

Discover the Unnamed:0 column? Additionally, discover the underside few rows containing NaNs?
If you happen to look at the Excel spreadsheet, you’ll discover that the precise information begins with column B, and that there are some empty cells on the backside of the worksheet:

To get Pandas to load the dataframe accurately, it is advisable specify the columns that you simply need to load in addition to the variety of rows to load. Right here, I’ll use the usecols and nrows parameters to try this:
df = pd.read_excel('RESTAURANT INVENTORY LOG.xlsx',
sheet_name='Stock Worksheets',
usecols="B:Q",
nrows=797)
df
The outcome now seems to be a lot better:

For the second worksheet, assume that the precise information that I need to load is in the course of the worksheet (I’ve highlighted in pink). That can assist you visualize the rows to load, I’ve indicated the rows that it is advisable skip loading if you wish to load the information highlighted in pink:

To load all of the rows beneath the FOOD part, first create an inventory to retailer the rows to skip:
rows_to_skip = listing(vary(0,5))
rows_to_skip.append(6)
The above will generate an inventory of values — [0,1,2,3,4,6]. Then , use the skiprows, usecols, and nrows parameters to load the information from the precise places within the worksheet:
df = pd.read_excel('RESTAURANT INVENTORY LOG.xlsx',
sheet_name='Subcategory Stock Worth',
skiprows=rows_to_skip,
usecols="B:AA",
nrows=8)
df
The next reveals the dataframe containing the rows and columns beneath the FOOD part:

Loading Pandas DataFrames from Excel recordsdata is sort of much like loading from CSV recordsdata. The important thing variations are:
- An Excel file might comprise a number of worksheets, and it is advisable point out which worksheet you need to load.
- Loading from Excel offers the flexibleness to specify columns through Excel column names. This makes it straightforward so that you can establish the columns to load the information from.
- As the information in an Excel worksheet is probably not populated in strictly tabular format, fairly often it is advisable specify the variety of rows to load, in addition to the variety of rows to skip when loading.
Normally, when loading from Excel recordsdata, it is advisable pay additional care to the format of the information within the worksheet. Have enjoyable!

{kind=link}