
Bettering analytics efficiency is necessary. All of us perceive that, however what’s one of the simplest ways to make sure that our customers are getting the speeds they want with out placing a load of additional work on our plate?
As information engineers, we confronted this problem, and so did our pals and colleagues. Our try to discover a resolution would lead us to begin the open challenge StarRocks, an analytics engine that might assist us meet quickly rising analytics efficiency calls for whereas additionally being straightforward to work with and preserve.
Because the challenge and neighborhood have grown these previous few years, we’ve discovered so much about what works and what doesn’t in relation to analytics efficiency. At the moment, we wish to share some insights round one of many key applied sciences for constructing a excessive efficiency analytics engine: vectorization.
Why vectorization improves database efficiency
Earlier than we dig into how we strategy vectorization with StarRocks, it’s necessary to make clear that once we discuss vectorization, we’re speaking in regards to the vectorization of databases with a contemporary CPU structure. With that understanding, we will start to reply the query: Why can vectorization enhance database efficiency?
To deal with this query, we first must reply the next:
- How do you measure CPU efficiency?
- What components have an effect on CPU efficiency?
The reply to the primary query may be represented by this method:
CPU time = (instruction numbers) * CPI * (clock cycle time)
The place
- Instruction numbers = the variety of directions generated by the CPU
- CPI (cycles per instruction) = the CPU cycles wanted to execute an instruction
- Clock cycle time = the time elapsed for a CPU clock cycle
This method offers us some phrases we will use to debate the levers that transfer efficiency. Since there may be nothing we will do in regards to the clock cycle time, we have to deal with instruction numbers and CPI to enhance software program efficiency.
One other necessary piece of data we additionally know is that the execution of a CPU instruction may be divided into 5 steps:
- Fetching
- Decoding
- Execution
- Reminiscence entry
- Outcome write again (into registers)
Steps 1 and a pair of are carried out by the CPU entrance finish, whereas steps 3 to five are dealt with by the CPU again finish. Intel has revealed the High-down Microarchitecture Evaluation Technique, as illustrated within the following picture.
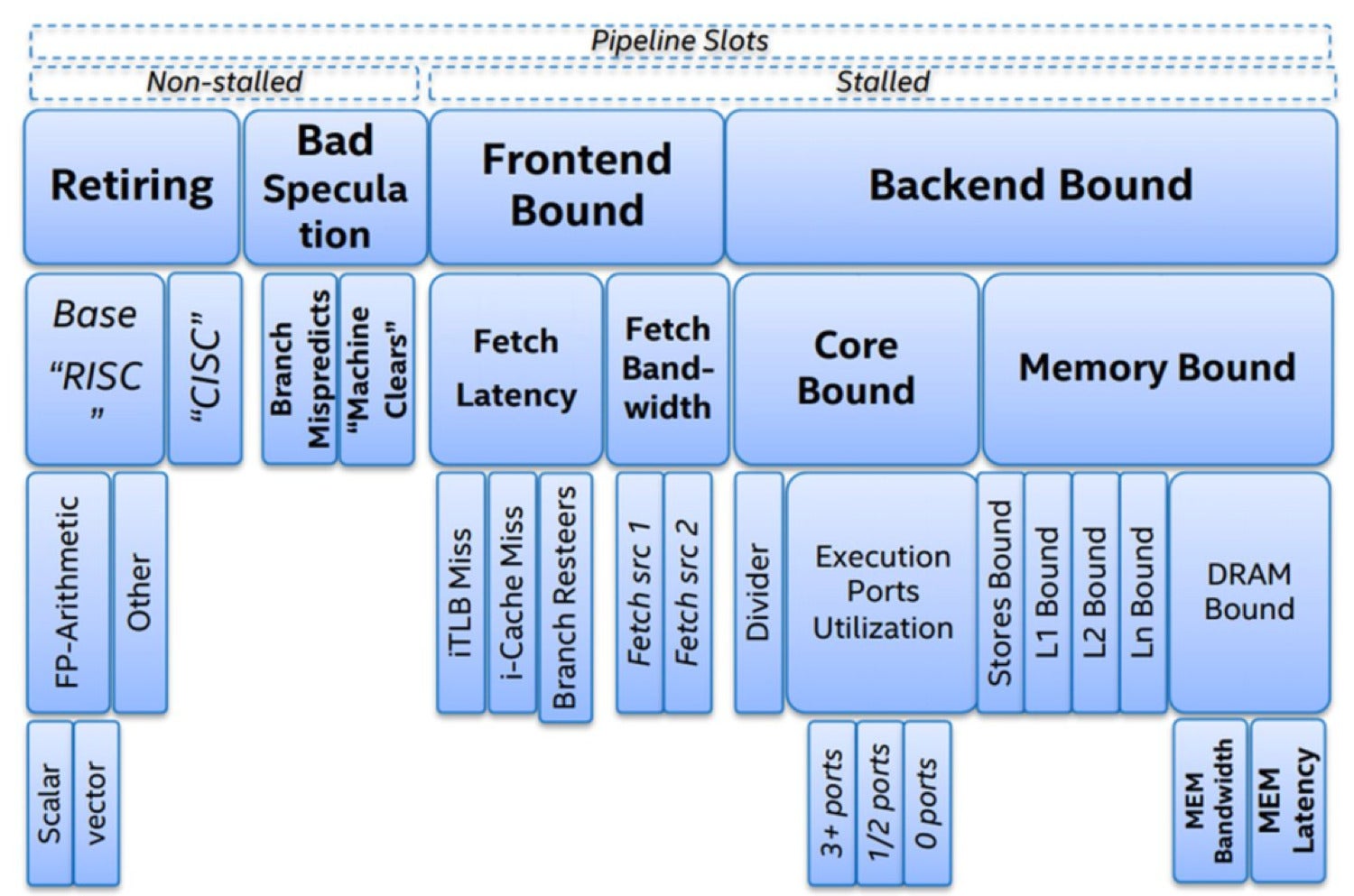 Intel
IntelHigh-down Microarchitecture Evaluation Technique (Intel)
Right here’s a extra simplified model of the strategy above.
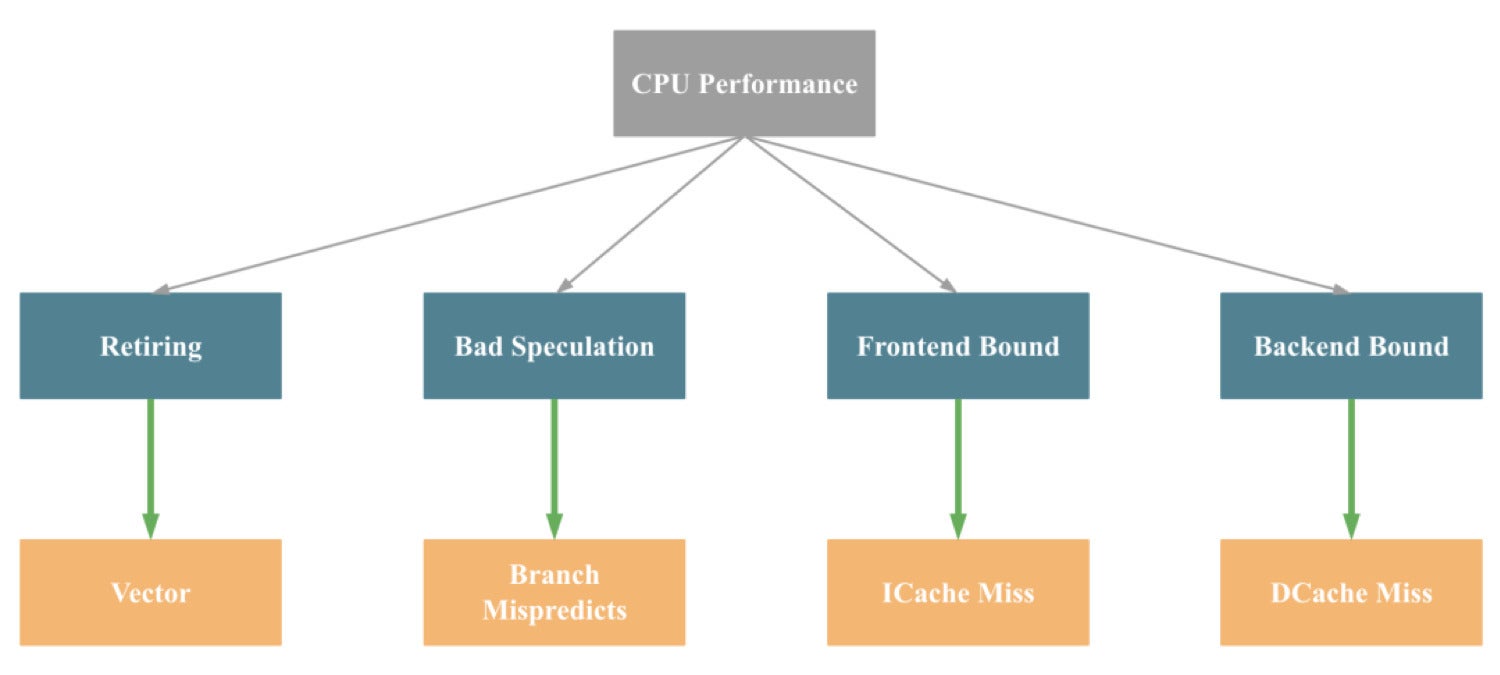 CelerData
CelerDataAs you may see, the primary contributing components to CPU efficiency points are Retiring, Dangerous Hypothesis, Frontend Certain, and Backend Certain.
The primary drivers behind these points, respectively, are an absence of SIMD instruction optimization, department prediction errors, instruction cache misses, and information cache misses.
So, if we map the above causes to the CPU efficiency method launched earlier, we come to the next conclusion:
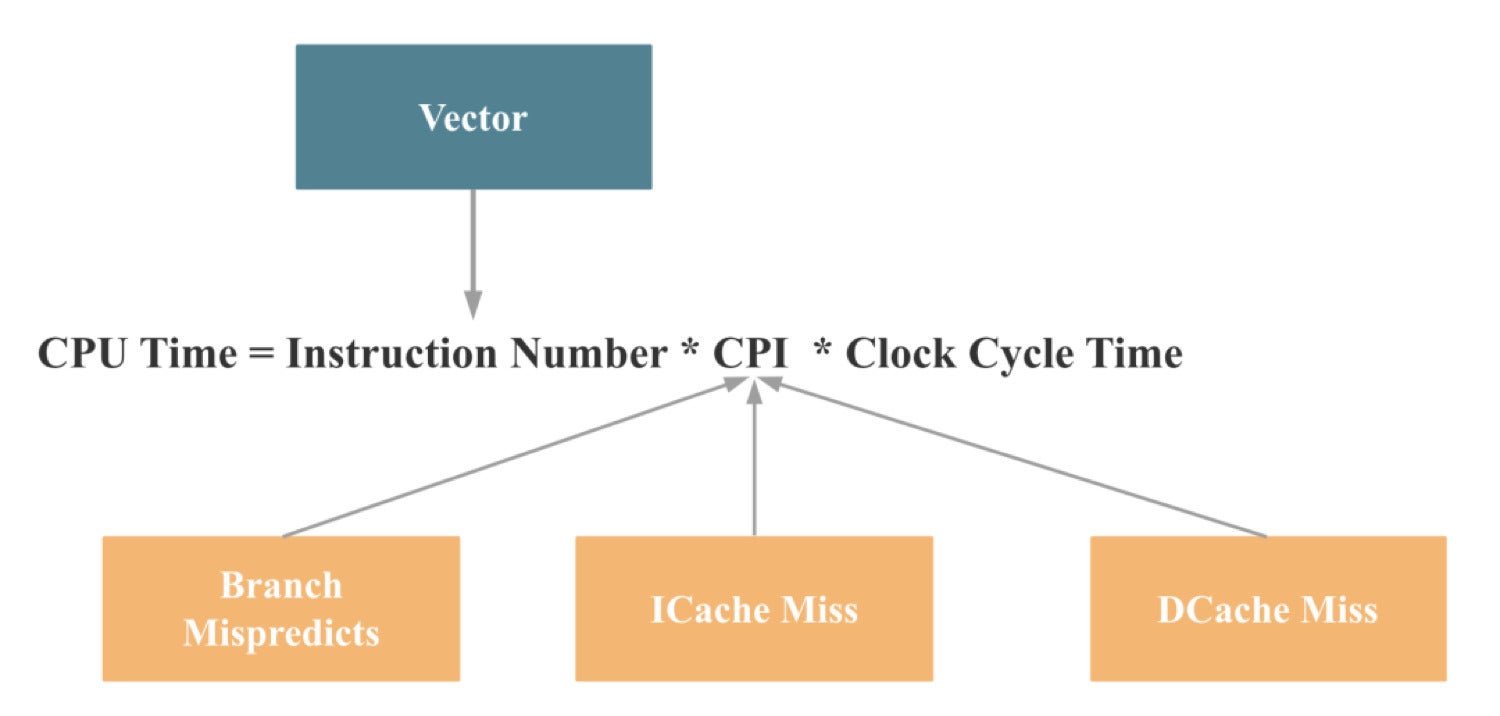 CelerData
CelerDataAnd what was designed to enhance CPU efficiency in these 4 areas?
That’s proper, vectorization.
We have now now established why vectorization can enhance database efficiency. In the remainder of this text, we’ll check out how vectorization does it.
The basics of vectorization
In the event you’ve bought an excellent understanding of vectorization, you may skip this part and transfer on to the one about database vectorization, however in the event you’re unfamiliar with the basics of vectorization, or you would use a refresher, we’ll briefly define what you must know.
Please remember the fact that on this part we’ll restrict our dialogue of vectorization to SIMD. SIMD vectorization is completely different from normal database vectorization, which we’ll talk about subsequent.
An introduction to SIMD
SIMD stands for single instruction, a number of information. Because the title suggests, with SIMD structure one instruction can function on a number of information factors concurrently. This isn’t the case with a SISD (single instruction, single information) structure the place one instruction operates on a single information level solely.
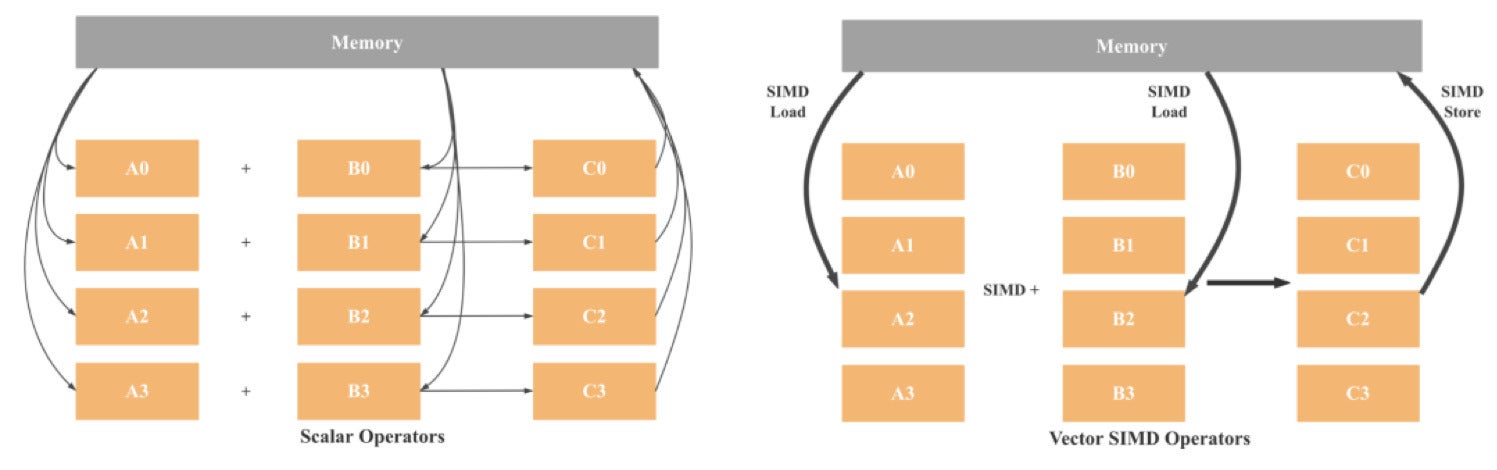 CelerData
CelerDataAs illustrated above, in SISD structure, operations are scalar, that means just one set of knowledge is being processed. Therefore, the 4 additions will contain eight load operations (one for every variable), 4 addition operations, and 4 retailer operations. If we use 128-bit SIMD, we’ll want solely two hundreds, one addition, and one storing. In principle, we now have a 4x efficiency enchancment in comparison with SISD. Contemplating fashionable CPUs have already got 512-bit registers, we will anticipate as much as a 16x efficiency acquire.
How do you vectorize a program?
Within the above part, we noticed how SIMD vectorization can tremendously enhance a program’s efficiency. So how will you begin utilizing this to your personal work?
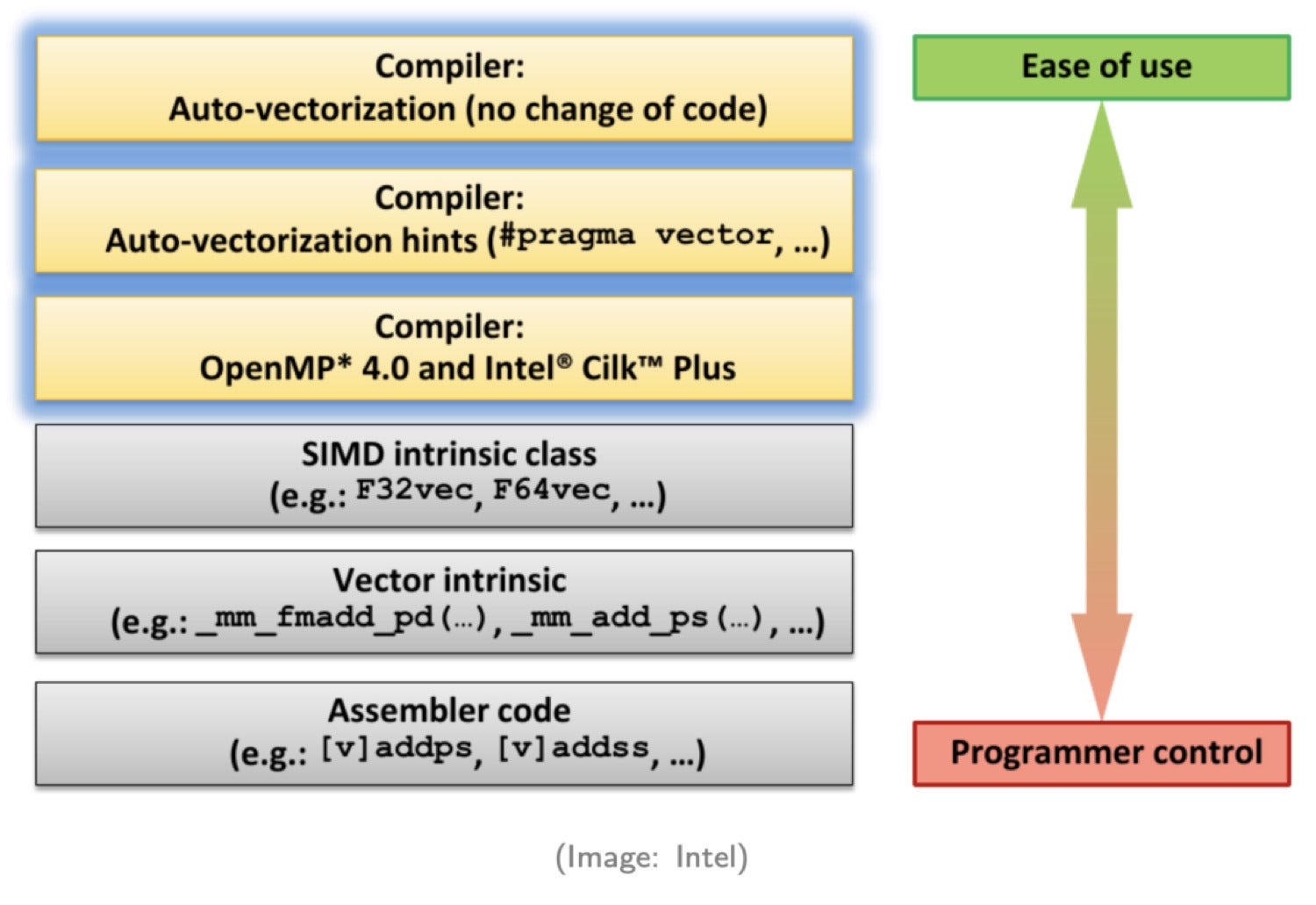 Intel
IntelAlternative ways to invoke SIMD (Intel)
As illustrated on this diagram from Intel, there are six methods SIMD is invoked. Transferring from high to backside, every methodology calls for extra experience from the programmers and requires extra coding effort.
Technique 1. Auto-vectorization by compiler
Programmers don’t should make any adjustments to their code. The compiler will robotically convert scalar code to vector code. Just some easy circumstances may be auto-converted to vector code.
Technique 2. Trace to compiler
On this methodology, we offer some hints to the compiler. With the additional info supplied, the compiler can generate extra SIMD code.
Technique 3. Parallel programming API
With the assistance of parallel programming APIs akin to OpenMP or Intel TBB, builders can add Pragma to generate vector code.
Technique 4. Use SIMD class libraries
These libraries wrap lessons that allow SIMD directions.
Technique 5. Use SIMD intrinsics
Intrinsics is a set of assembly-coded features that allow you to use C++ operate calls and variables rather than meeting directions.
Technique 6. Write meeting code immediately
Good luck with this one.
Contemplating our choices above, we wish to invoke the compiler’s auto-generated vectorization as a lot as we will. In different phrases, we wish to deal with strategies 1 and a pair of. For performance-critical operations that may’t be robotically transformed to vector code, we’ll use SIMD intrinsics.
Verifying this system has really generated SIMD code
Right here’s an necessary query we get so much once we’re speaking about vectorization: When a program has a posh code construction, how can we ensure that code execution is vectorized?
There are two methods to examine and ensure that the code has been vectorized.
Technique 1. Add choices to the compiler
With these choices, the compiler will generate output concerning if the code is vectorized, and if not, what’s the explanation. For instance, we will add -fopt-info-vec-all, -fopt-info-vec-optimized, -fopt-info-vec-missed, and -fopt-info-vec-note choices to the gcc compiler, as illustrated within the following picture.
 CelerData
CelerDataTechnique 2. Evaluation the meeting code that will get executed
We are able to use web sites like https://gcc.godbolt.org/ or instruments akin to Perf and Vtun to examine the meeting code. If the registers within the meeting code are xmm, ymm, zmm, and so forth., or the directions begin with v, then we all know this code has been vectorized.
Now that we’re all caught in control on the basics of vectorization, it’s time to debate the performance-boosting energy of vectorized databases.
The vectorization of databases
Whereas the StarRocks challenge has grown right into a mature, secure, and industry-leading MPP database (and even spawned an enterprise-ready model from CelerData), the neighborhood has needed to overcome many challenges to get right here. One in all our largest breakthroughs, database vectorization, was additionally considered one of our largest challenges.
Challenges of database vectorization
In our expertise, vectorizing a database is way more difficult than merely enabling SIMD directions within the CPU. It’s a giant, systematic engineering effort. Specifically, we confronted six technical challenges:
- Finish-to-end columnar information. Information must be saved, transferred, and processed in columnar format throughout the storage, community, and reminiscence layers to remove “impedance mismatch.” The storage engine and the question engine have to be redesigned to assist columnar information.
- All operators, expressions, and features have to be vectorized. It is a daunting job and takes a number of person-years to finish.
- Operators and expressions ought to invoke SIMD directions if doable. This requires detailed line-by-line optimization.
- Reminiscence administration. To completely leverage the parallel processing energy of SIMD CPUs, we now have to rethink reminiscence administration.
- New information constructions. All information constructions for the core operators, akin to
be a part of,combination,kind, and so forth., have to be designed to assist vectorizations from the bottom up. - Systematic optimization. Our objective with StarRocks was to enhance efficiency by 5x in comparison with different market-leading merchandise (with the identical {hardware} configuration). To achieve that objective, we had to verify all parts within the database system had been optimized.
Vectorizing operators and expressions
The lion’s share of our engineering efforts when vectorizing StarRocks went into vectorizing operators and expressions. These efforts may be summarized as Batch Compute By Columns, which is illustrated within the following picture.
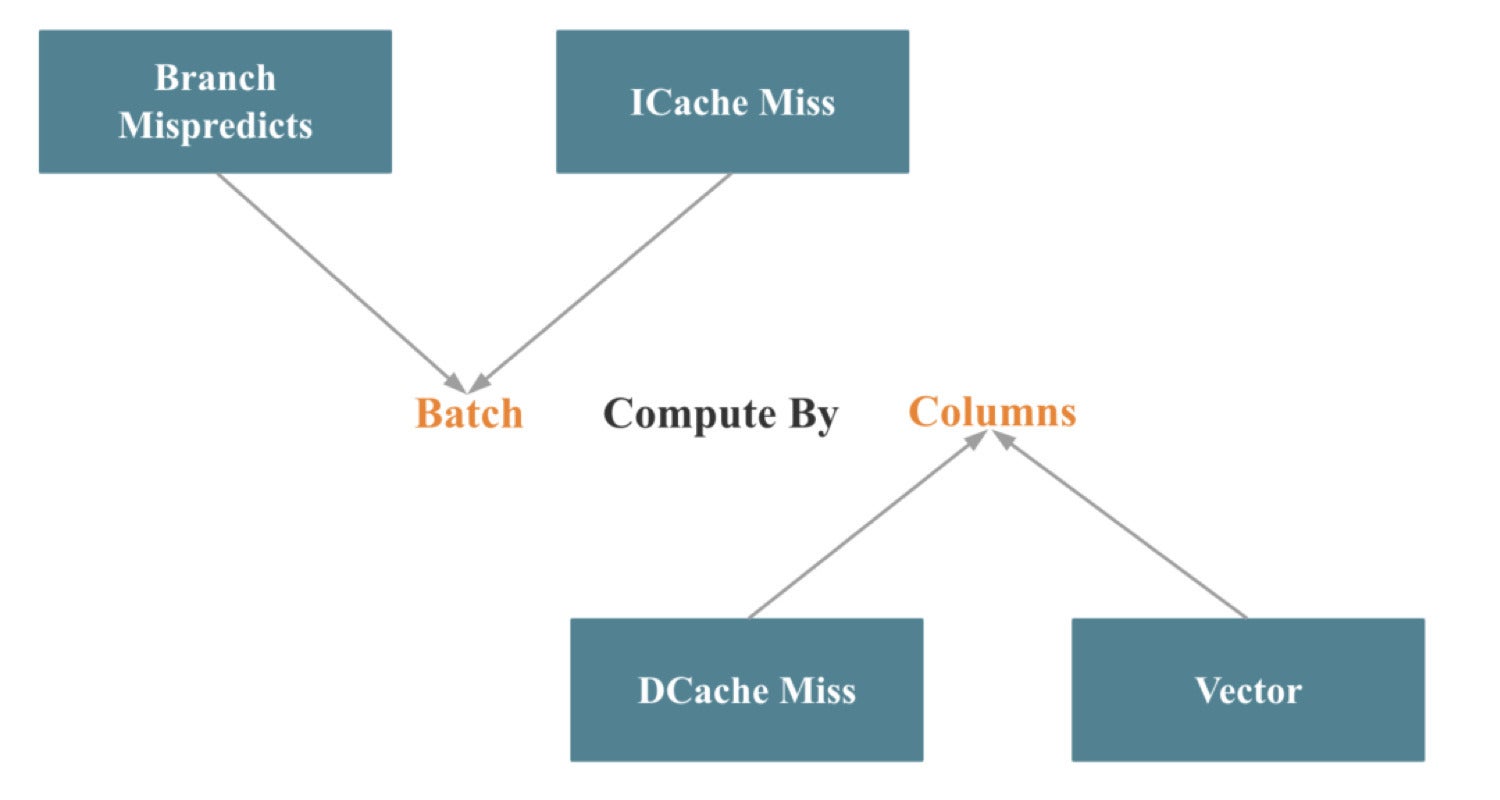 CelerData
CelerDataEquivalent to Intel’s High-down Microarchitecture Evaluation Technique mentioned earlier on this article, Batch reduces department mispredictions and instruction cache misses. By Columns reduces information cache misses and makes it simpler to invoke SIMD optimization.
It’s comparatively straightforward to implement Batch computing. The troublesome half is the columnar processing for key operators like be a part of, combination, kind, and shuffle. Invoking as many SIMD optimizations as doable whereas doing columnar processing is much more of a problem, however discussing that might require its personal separate article.
The right way to enhance database efficiency with database vectorization
As we talked about, vectorizing databases is a scientific engineering effort. Up to now few years, we’ve applied lots of of optimizations whereas growing StarRocks. The next are the seven most necessary areas we targeted on for optimization.
Excessive-performance third-party libraries. There are lots of glorious open supply libraries for information constructions and algorithms. For StarRocks, we use many third-party libraries akin to Parallel Hashmap, Fmt, SIMD Json, and Hyper Scan.
Information constructions and algorithms. Extremely environment friendly information constructions and algorithms can scale back CPU cycles by an order of magnitude. Due to this, when StarRocks 2.0 launched, we launched a low-cardinality world dictionary. Utilizing this world dictionary, we will convert string-based operations into integer-based operations.
As illustrated within the following diagram, two string-based group by operations are transformed to at least one integer-based group by operation. Consequently, the efficiency of operations like scan, hash, equal, and mumcpy improved manyfold, and total question efficiency improved by greater than 300%.
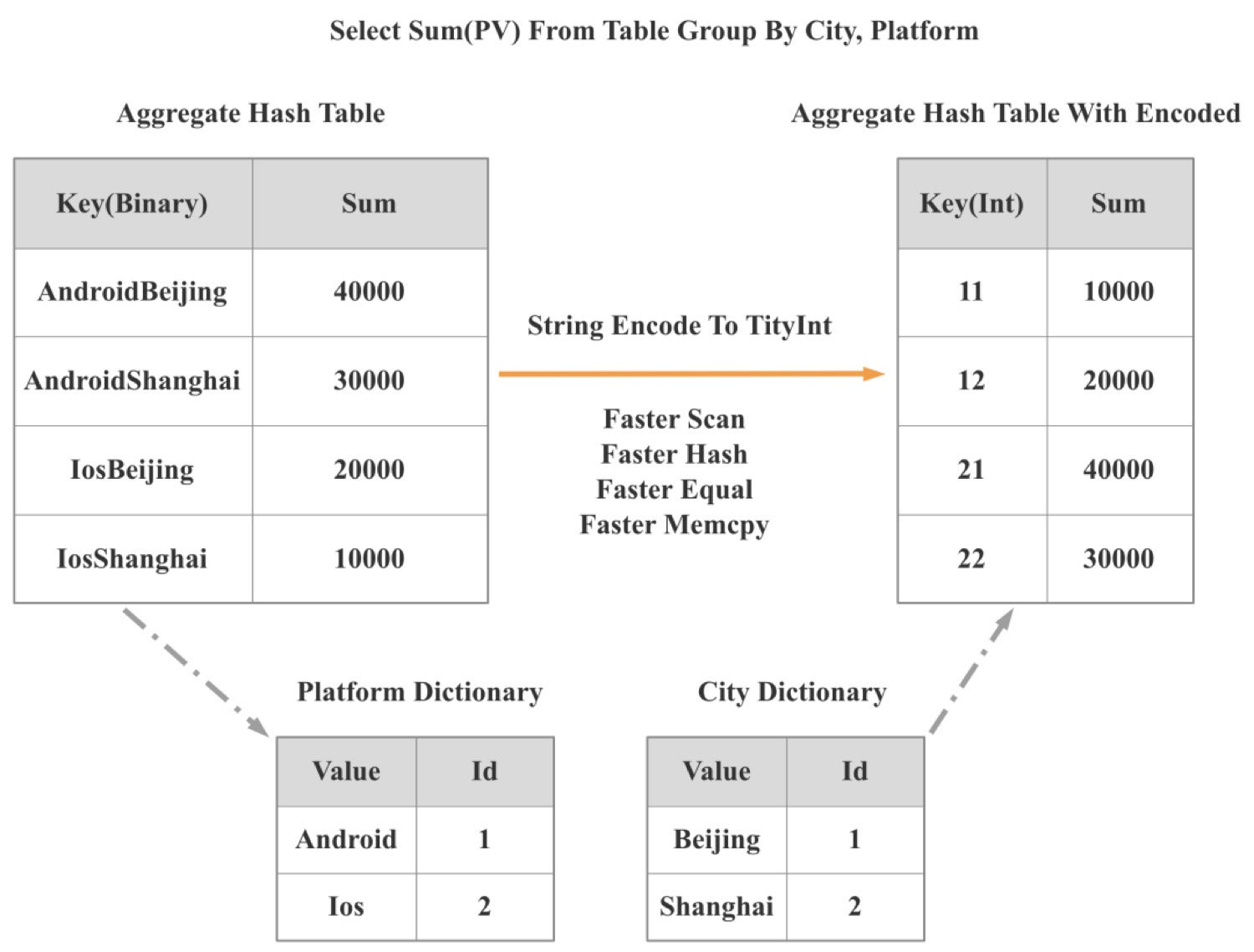 CelerData
CelerDataSelf-adaptive optimization. If we will perceive the context of a question, we will additional optimize the question execution. Usually, nonetheless, we don’t have the question context info till execution time. So our question engine should dynamically alter its technique primarily based on the context info it acquires throughout question execution. That is referred to as self-adaptive optimization.
The next code snippet exhibits an instance the place we dynamically select be a part of runtime filters primarily based on selectivity charge:
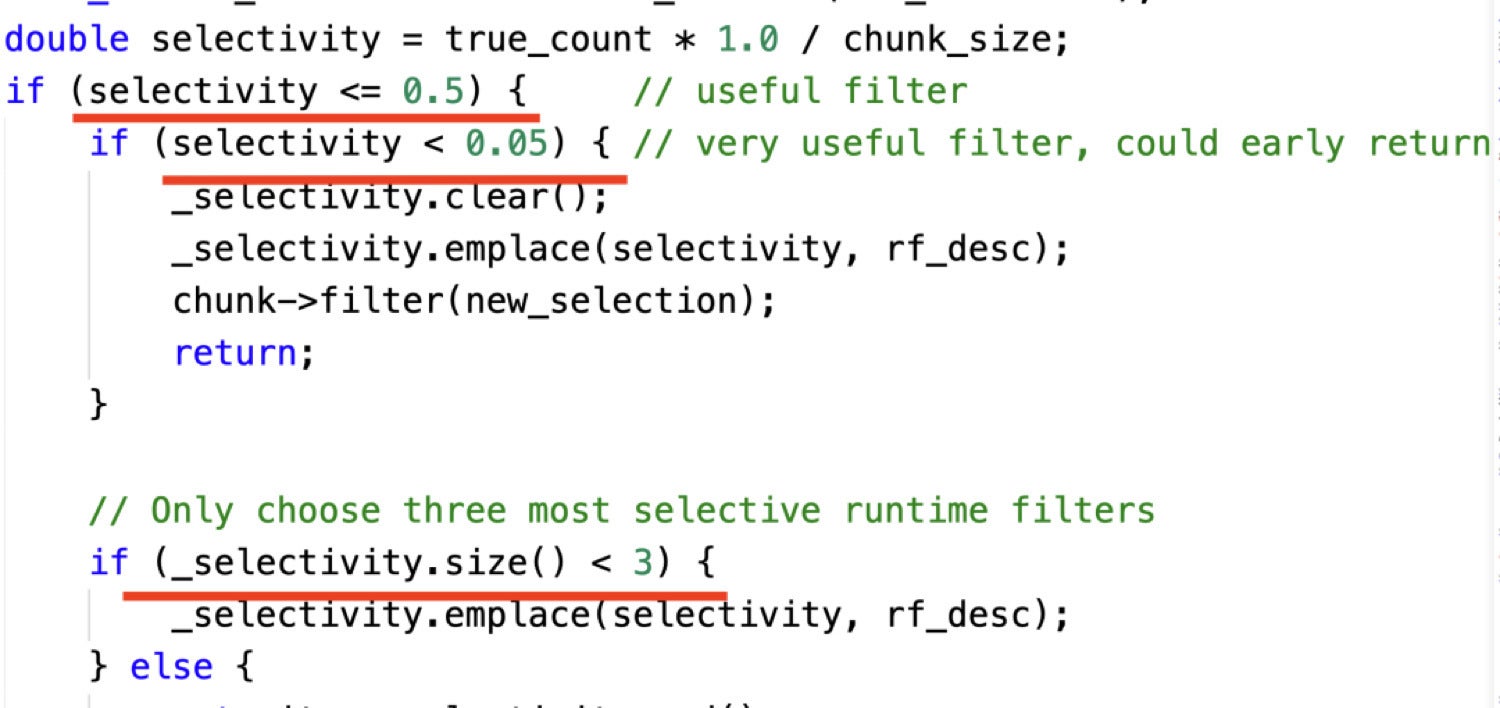 CelerData
CelerDataThere are three resolution factors that information the instance above:
- If a filter can’t filter the vast majority of information, then we aren’t going to make use of it.
- If a filter can filter virtually the entire information, then we solely maintain this filter.
- We maintain at most three filters.
SIMD optimization. As illustrated within the following diagram, StarRocks has loads of SIMD optimizations in its operators and expressions implementations.
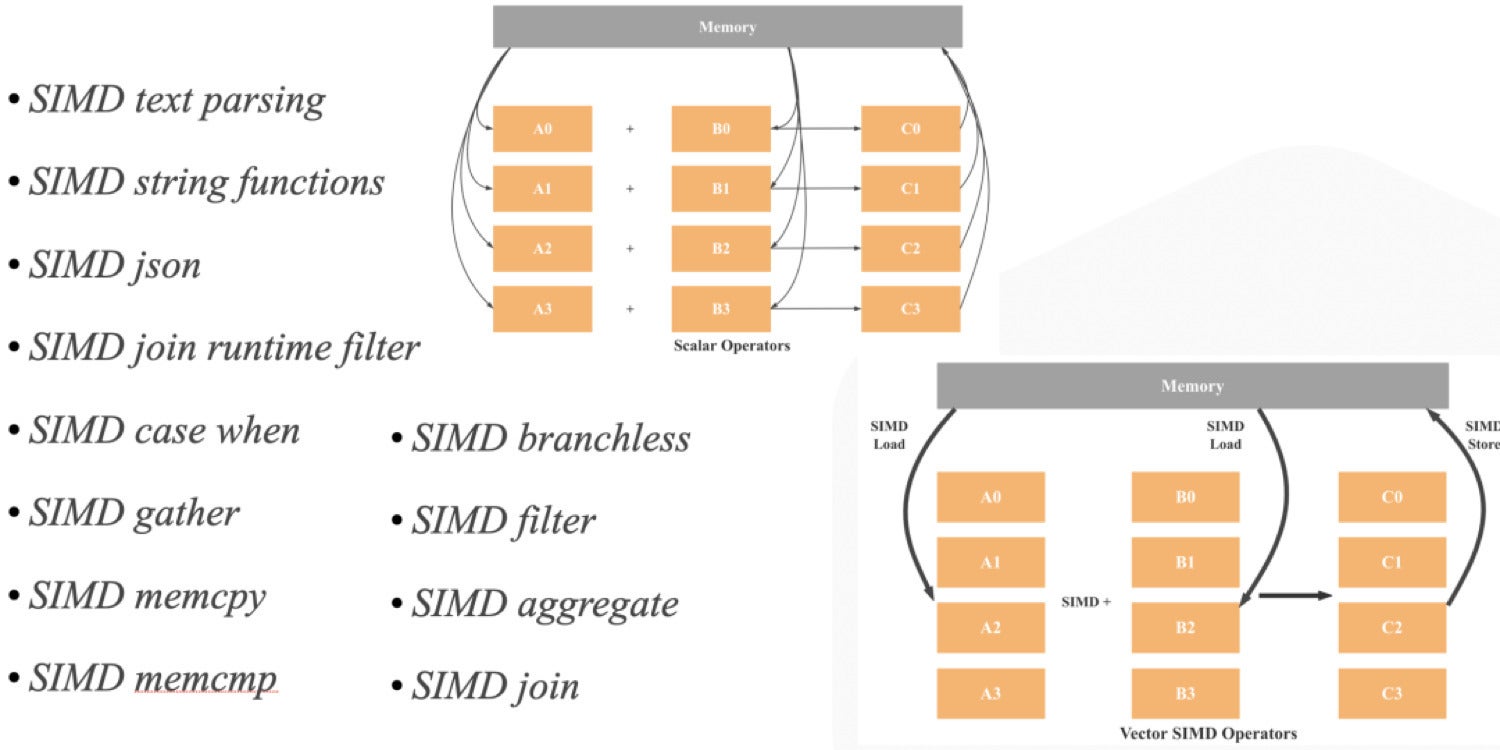 CelerData
CelerDataC++ low-level optimization. Even with the identical information constructions and algorithms, the efficiency of various C++ implementations might fluctuate. For instance, a transfer or copy operation is likely to be used, a vector is likely to be reserved, or a operate name is likely to be inline. These are simply among the optimizations we now have to think about.
Reminiscence administration optimization. The bigger the batch dimension, and the upper the concurrency, the extra usually reminiscence is allotted and launched, and the larger influence reminiscence administration can have on system efficiency.
With StarRocks, we applied a column pool information construction to reuse the reminiscence of columns and considerably improved question efficiency. The code snippet beneath exhibits an HLL (HyperLogLog) combination operate reminiscence optimization. By allocating HLL reminiscence by blocks, and by reusing these blocks, we improved the aggregation efficiency of HLL five-fold.
 CelerData
CelerDataCPU cache optimization. CPU cache misses have a big impact on efficiency. We are able to perceive this influence by way of CPU cycles. An L1 cache entry wants three CPU cycles, L2 wants 9 CPU cycles, L3 wants about 40 CPU cycles, and primary reminiscence entry wants about 200 CPU cycles. (See Programs Efficiency by Brendan Gregg.)
CPU cache misses grew to become an particularly important issue for us after we invoked SIMD optimization and the efficiency bottleneck shifted from CPU certain to reminiscence certain. The next code snippet exhibits how we decreased CPU misses via prefetching. We’d wish to level out, although, that prefetching must be your final resort to optimize CPU caching. It’s because it’s very troublesome to manage the timing and distance of a prefetch.
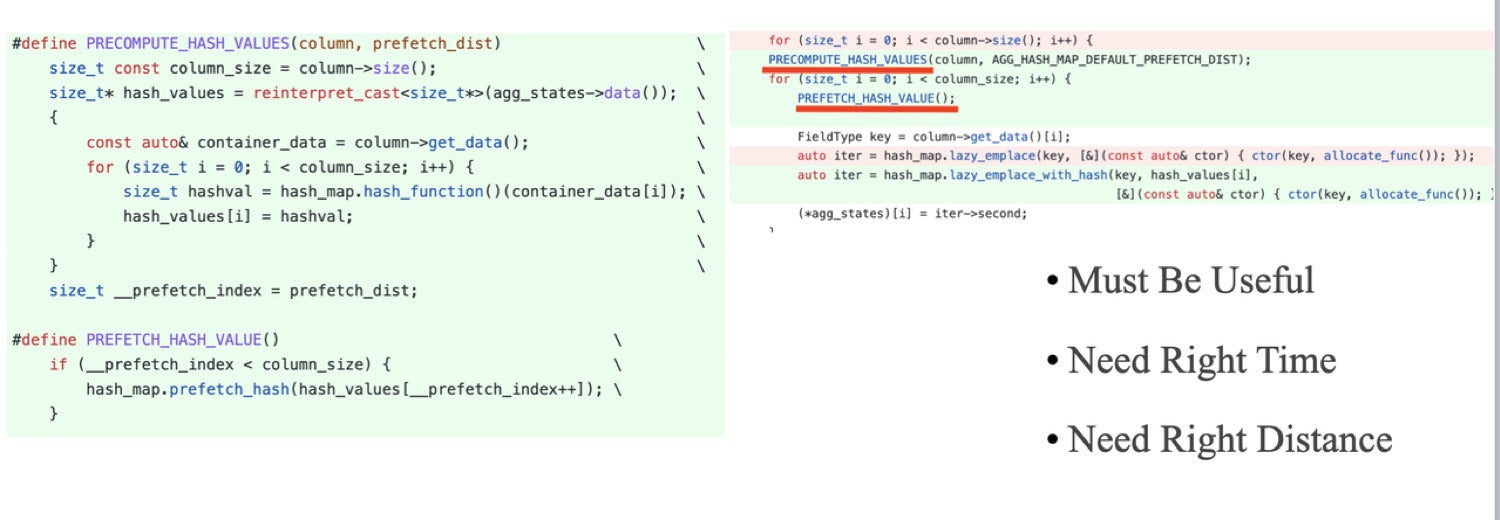 CelerData
CelerData
{kind=link}