
Functions of Autoencoders
Dimensionality discount with autoencoders utilizing non-linear knowledge

There are such a lot of sensible functions of autoencoders. Dimensionality discount is one among them.
There are such a lot of methods for dimensionality discount. Autoencoders (AEs) and Principal Part Evaluation (PCA) are well-liked amongst them.
PCA just isn’t appropriate for dimensionality discount in non-linear knowledge. In distinction, autoencoders work rather well with non-linear knowledge in dimensionality discount.
On the finish of this text, you’ll be capable to
- Use Autoencoders to scale back the dimensionality of the enter knowledge
- Use PCA to scale back the dimensionality of the enter knowledge
- Examine the efficiency of PCA and Autoencoders in dimensionality discount
- See how Autoencoders outperform PCA in dimensionality discount
- Study key variations between PCA and Autoencoders
- Study when to make use of which methodology for dimensionality discount
I like to recommend you to learn the next articles because the stipulations for this text.
First, we’ll carry out dimensionality discount on the MNIST knowledge (see dataset Quotation on the finish) utilizing PCA and examine the output with the unique MNIST knowledge.
- Step 1: Purchase and put together the MNIST dataset.
- Step 2: Apply PCA with solely two parts. The unique dimensionality of the enter knowledge is 784.
- Step 3: Visualize compressed MNIST digits after PCA.

- Step 4: Examine the PCA output with the unique MNIST digits.

As you may see within the two outputs, the MNIST digits usually are not clearly seen after making use of PCA. It’s because we solely stored two parts that don’t seize a lot of the patterns within the enter knowledge.
- Step 5: Visualize take a look at knowledge utilizing the 2 principal parts.
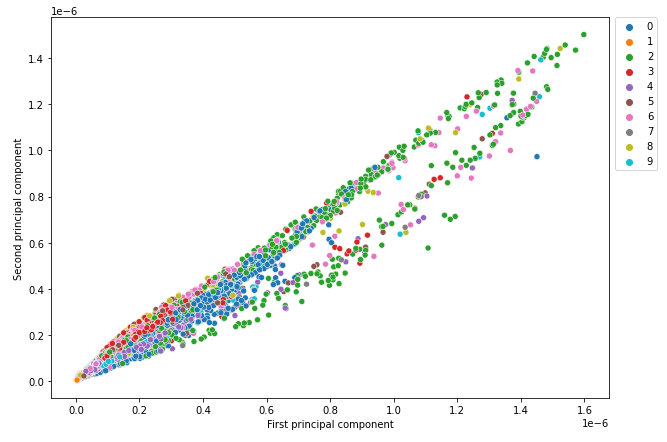
All of the digits should not have clear separate clusters. It signifies that the PCA mannequin with solely two parts can not clearly distinguish between the 9 digits within the take a look at knowledge.
Now, we’ll construct a deep autoencoder to use dimensionality discount to the identical MNIST knowledge. We additionally maintain the dimensionality of the latent vector two-dimensional in order that it’s straightforward to match the output with the earlier output returned by PCA.
- Step 1: Purchase and put together the MNIST dataset as beforehand.
- Step 2: Outline the autoencoder structure.
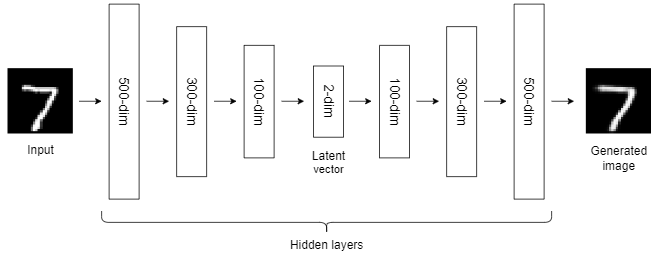
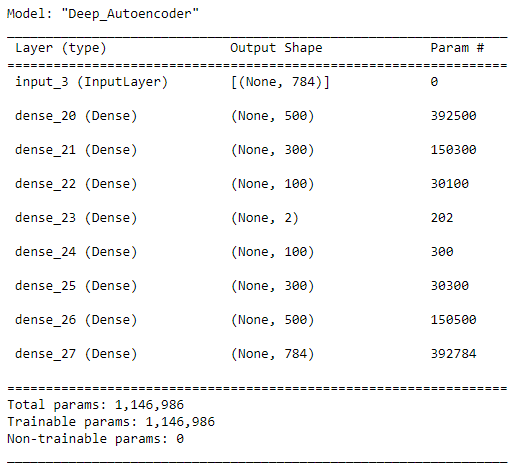
There are over a million parameters within the community. So, that may require a variety of computational energy to coach this mannequin. When you use a conventional CPU for this, it’s going to take a variety of time to finish the coaching course of. It’s higher to make use of a strong NVIDIA GPU or Colab free GPU to hurry up the coaching course of by an element of 10 or 20.
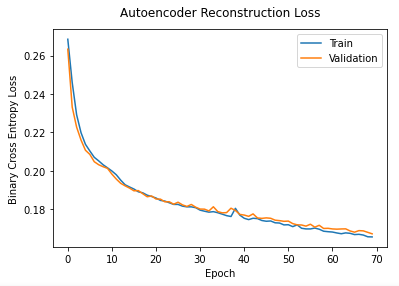
- Step 3: Compile, prepare and monitor the loss perform.
- Step 4: Visualize compressed MNIST digits after autoencoding.

The autoencoder output is a lot better than the PCA output. It’s because autoencoders can study advanced non-linear patterns within the knowledge. In distinction, PCA can solely study linear patterns within the knowledge.
- Step 5: Visualize take a look at knowledge within the latent house to see how the autoencoder mannequin is able to distinguishing between the 9 digits within the take a look at knowledge.
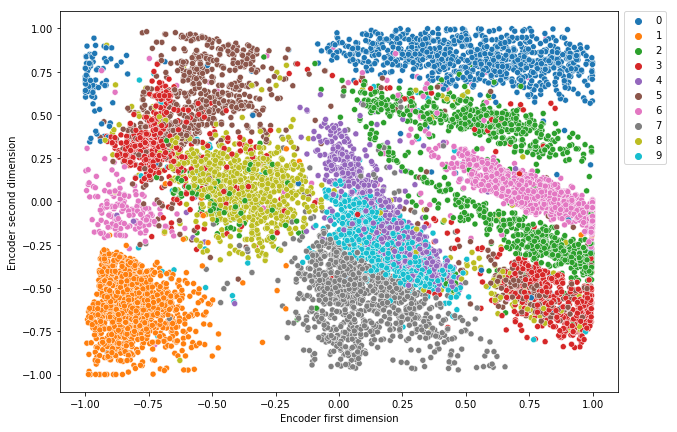
Many of the digits have clear separate clusters. It signifies that the autoencoder mannequin can clearly distinguish between most digits within the take a look at knowledge. Some digits overlap, for instance, there may be an overlap between digits 4 and 9. It signifies that the autoencoder mannequin can not clearly distinguish between digits 4 and 9.
- Step 6 (Non-obligatory): Use the identical autoencoder mannequin however with out utilizing any activation perform within the hidden layers,
activation=Nonein every hidden layer. You’ll get the next output.

This output is even worse than the PCA output. I used this experiment to point out you the significance of activation features in neural networks. Activation features are wanted within the hidden layers of neural networks to study non-linear relationships within the knowledge. With out activation features within the hidden layers, neural networks are large linear fashions and behave even worse than common machine studying algorithms! So, it’s worthwhile to use the suitable activation perform for neural networks.
- Structure: PCA is a common machine studying algorithm. It makes use of Eigendecomposition or Singular Worth Decomposition (SVD) of the covariance matrix of the enter knowledge to carry out dimensionality discount. In distinction, Autoencoder is a neural network-based structure that’s extra advanced than PCA.
- Dimension of the enter dataset: PCA typically works properly with small datasets. As a result of Autoencoder is a neural community, it requires a variety of knowledge in comparison with PCA. So, it’s higher to make use of Autoencoders with very massive datasets.
- Linear vs non-linear: PCA is a linear dimensionality discount approach. It may solely study linear relationships within the knowledge. In distinction, Autoencoder is a non-linear dimensionality discount approach that may additionally study advanced non-linear relationships within the knowledge. That’s why the Autoencoder output is a lot better than the PCA output in our instance as there are advanced non-linear patterns within the MNSIT knowledge.
- Utilization: PCA is barely used for dimensionality discount. However, Autoencoders usually are not restricted to dimensionality discount. They produce other sensible functions comparable to picture denoising, picture colonization, super-resolution, picture compression, function extraction, picture era, watermark elimination, and so forth.
- Computational assets: Autoencoders require extra computational assets than PCA.
- Coaching time: PCA takes much less time to run as in comparison with autoencoders.
- Interpretability: Autoencoders are much less interpretable than PCA.
You’ll be able to construct totally different autoencoder architectures by making an attempt totally different values for the next hyperparameters. After doing, let me know the ends in the remark part.
- Variety of layers
- Variety of nodes in every layer
- Dimension of the latent vector
- Sort of activation perform within the hidden layers
- Sort of optimizer
- Studying charge
- Variety of epochs
- Batch measurement
Take into account the next diagram that consists of all of the outputs we obtained earlier than.

- The primary row represents the unique MNIST digits.
- The second row represents the output returned by PCA with solely two parts. The digits usually are not clearly seen.
- The third row represents the output returned by the autoencoder with a two-dimensional latent vector that’s a lot better than the PCA output. The digits are clearly seen now. The reason being that the autoencoder has discovered advanced non-linear patterns within the MNIST knowledge.
- The final row represents the output returned by the autoencoder with none activation perform within the hidden layers. That output is even worse than the PCA output. I included this to point out you the significance of activation features in neural networks. Activation features are wanted within the hidden layers of neural networks to study non-linear relationships within the knowledge. With out activation features within the hidden layers, neural networks are large linear fashions and behave even worse than common machine studying algorithms!

{kind=link}