
All of us have skilled a time when we’ve got to lookup for a brand new home to purchase. However then the journey begins with plenty of frauds, negotiating offers, researching the native areas and so forth.
Home Value Prediction utilizing Machine Studying
So to cope with this sort of points Immediately we might be getting ready a MACHINE LEARNING Based mostly mannequin, educated on the Home Value Prediction Dataset.
You’ll be able to obtain the dataset from this hyperlink.
The dataset accommodates 13 options :
| 1 | Id | To rely the information. |
|---|---|---|
| 2 | MSSubClass | Identifies the kind of dwelling concerned within the sale. |
| 3 | MSZoning | Identifies the final zoning classification of the sale. |
| 4 | LotArea | Lot dimension in sq. ft. |
| 5 | LotConfig | Configuration of the lot |
| 6 | BldgType | Kind of dwelling |
| 7 | OverallCond | Charges the general situation of the home |
| 8 | YearBuilt | Unique building 12 months |
| 9 | YearRemodAdd | Transform date (similar as building date if no reworking or additions). |
| 10 | Exterior1st | Exterior masking on home |
| 11 | BsmtFinSF2 | Kind 2 completed sq. ft. |
| 12 | TotalBsmtSF | Complete sq. ft of basement space |
| 13 | SalePrice | To be predicted |
Importing Libraries and Dataset
Right here we’re utilizing
- Pandas – To load the Dataframe
- Matplotlib – To visualise the info options i.e. barplot
- Seaborn – To see the correlation between options utilizing heatmap
Python3
|
|
Output:

As we’ve got imported the info. So form technique will present us the dimension of the dataset.
Output:
(2919,13)
Knowledge Preprocessing
Now, we categorize the options relying on their datatype (int, float, object) after which calculate the variety of them.
Python3
|
|
Output:
Categorical variables : 4 Integer variables : 6 Float varibales : 3
Exploratory Knowledge Evaluation
EDA refers back to the deep evaluation of information in order to find totally different patterns and spot anomalies. Earlier than making inferences from knowledge it’s important to look at all of your variables.
So right here let’s make a heatmap utilizing seaborn library.
Python3
|
|
Output:

To research the totally different categorical options. Let’s draw the barplot.
Python3
|
|
Output:

The plot reveals that Exterior1st has round 16 distinctive classes and different options have round 6 distinctive classes. To findout the precise rely of every class we are able to plot the bargraph of every 4 options individually.
Python3
|
|
Output:

Knowledge Cleansing
Knowledge Cleansing is the best way to improvise the info or take away incorrect, corrupted or irrelevant knowledge.
As in our dataset, there are some columns that aren’t necessary and irrelevant for the mannequin coaching. So, we are able to drop that column earlier than coaching. There are 2 approaches to coping with empty/null values
- We will simply delete the column/row (if the characteristic or report will not be a lot necessary).
- Filling the empty slots with imply/mode/0/NA/and many others. (relying on the dataset requirement).
As Id Column won’t be taking part in any prediction. So we are able to Drop it.
Python3
|
|
Changing SalePrice empty values with their imply values to make the info distribution symmetric.
Python3
|
|
Drop information with null values (because the empty information are very much less).
Python3
|
|
Checking options which have null values within the new dataframe (if there are nonetheless any).
Python3
|
|
Output:

OneHotEncoder – For Label categorical options
One scorching Encoding is the easiest way to transform categorical knowledge into binary vectors. This maps the values to integer values. By utilizing OneHotEncoder, we are able to simply convert object knowledge into int. So for that, firstly we’ve got to gather all of the options which have the item datatype. To take action, we’ll make a loop.
Python3
|
|
Output:

Then as soon as we’ve got an inventory of all of the options. We will apply OneHotEncoding to the entire record.
Python3
|
|
Splitting Dataset into Coaching and Testing
X and Y splitting (i.e. Y is the SalePrice column and the remainder of the opposite columns are X)
Python3
|
|
Mannequin and Accuracy
As we’ve got to coach the mannequin to find out the continual values, so we might be utilizing these regression fashions.
- SVM-Help Vector Machine
- Random Forest Regressor
- Linear Regressor
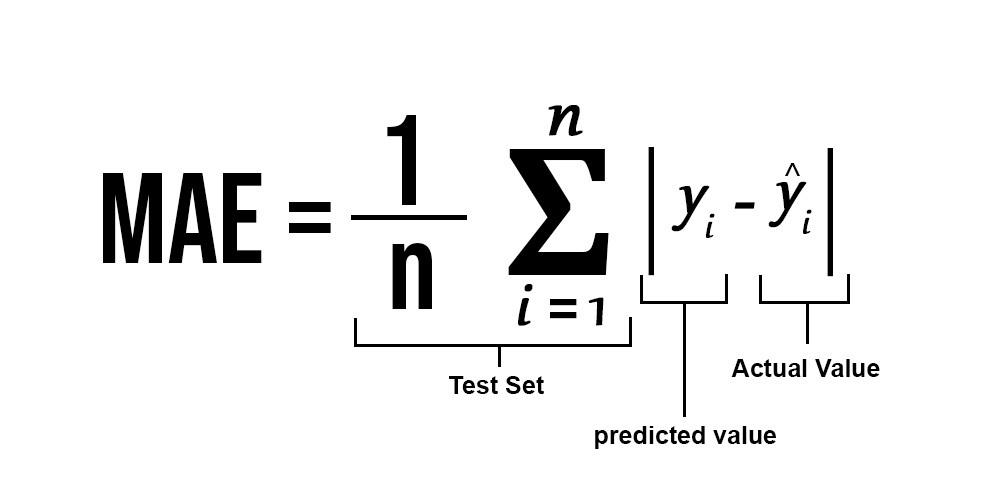
And To calculate loss we might be utilizing the mean_absolute_percentage_error module. It could simply be imported through the use of sklearn library. The method for Imply Absolute Error :
SVM – Help vector Machine
SVM can be utilized for each regression and classification mannequin. It finds the hyperplane within the n-dimensional aircraft. To learn extra about svm refer this.
Python3
|
|
Output :
0.18705129
Random Forest Regression
Random Forest is an ensemble approach that makes use of a number of of determination timber and can be utilized for each regression and classification duties. To learn extra about random forests refer this.
Python3
|
|
Output :
0.1929469
Linear Regression
Linear Regression predicts the ultimate output-dependent worth primarily based on the given impartial options. Like, right here we’ve got to foretell SalePrice relying on options like MSSubClass, YearBuilt, BldgType, Exterior1st and many others. To learn extra about Linear Regression refer this.
Python3
|
|
Output :
0.187416838
Conclusion
Clearly, SVM mannequin is giving higher accuracy because the imply absolute error is the least amongst all the opposite regressor fashions i.e. 0.18 approx. To get a lot better outcomes ensemble studying methods like Bagging and Boosting will also be used.

{kind=link}