
All machine studying fields—Supervised, Unsupervised, Semi-supervised, and Reinforcement studying, use a number of algorithms for various kinds of duties like prediction, classification, regression, and so on. Every machine studying algorithm handles one particular drawback, and this manner newbies can dive into one in every of these to determine options, one after the other.
Here’s a compilation of the highest machine studying algorithms which might be ceaselessly utilized in all machine studying fields.
Now, you possibly can follow ML algorithms right here.
Forming relationships between two variables is sort of the place to begin of a mannequin, and linear regression in machine studying achieves that. The connection between the dependent and impartial variables is established by aligning them on a regression line. Then, the target is to seek out the perfect match line that explains the connection between each variables.

The linear regression line is represented by a mathematical equation by,
y = mx + c
The place y is the dependent variable, x is the impartial variable, m is the slope, and c is the intercept.
Now, when the dependent variable is dichotomous (binary), logistic regression is used to estimate the discrete values (not like linear regression that handles steady values) inside a set of impartial variables.
This algorithm is utilized in predictive evaluation the place likelihood of an occasion incidence is predicted based mostly on logit perform, which is why additionally it is referred to as ‘logit regression’.

Mathematically, it’s represented by,
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
The place x is the enter worth, y is the anticipated output, b0 is the bias, and b1 is the coefficient for x.
ANNs are utilized in many of the current AGI-related fashions that use self-supervised studying. This algorithm tries to imitate the human mind by copying the behaviour and connections of the neurons. The construction of ANNs has three or extra layers which might be interconnected for processing enter knowledge.
These are utilized in varied good home equipment in addition to automation units like automated vehicles, good audio system and lights, and rather more.

Convolutional neural networks (CNNs), probably the most used neural networks in current developments, are a sort of ANNs. These are principally pc vision-based networks the place the primary layer is the enter layer, the layers in between are the hidden layers that do this computing, and the third layer is the output layer.

An optimisation algorithm for minimising value perform by updating parameters of the machine studying mannequin. It’s used inside varied machine studying algorithms and is mostly utilized in deep studying. It’s utilized in varied fields like robotics, pc video games, mechanical engineering, and extra.
There are three varieties of gradient descent algorithms:
- Batch gradient descent: Processes all of the coaching knowledge for every iteration of gradient descent. If the dataset is massive, this methodology is simply too costly.
- Stochastic gradient descent: This processes one coaching instance per iteration, leading to parameters getting up to date each single time.
- Mini batch gradient descent: The quickest gradient descent that processes massive quantities of iterations in small batches, matching comparable iterations.
A supervised studying algorithm used for visualization of a map of attainable outcomes for a sequence of selections. Mainly, it splits the dataset into two or extra homogeneous for comparability of attainable outcomes after which makes selections based mostly on benefits and possibilities.

It’s like making a execs and cons record, and making selections based mostly on anticipations and potentiality of various choices however, in machine studying, it’s based mostly on a mathematical assemble.
Bayesian likelihood is a sort of likelihood idea the place as an alternative of frequency of a phenomenon, likelihood is interpreted by quantification of a private perception or information representing an affordable expectation. The Naive Bayes is used for classification issues, and it assumes that options within the algorithm are impartial of one another and are usually not impacted by adjustments in one another.
For instance, the load and measurement of a desk can change and possibly interrelated however don’t change the basic incontrovertible fact that it’s a desk. This simplistic algorithm is able to dealing with massive datasets and making predictions in real-time.
Bayes’ theorem is given by,
P (X|Y) = (P (Y|X) x P (X)) /P (Y)
The place P(X) is the likelihood of X being true, P(X/Y) is the conditional likelihood the place X is true when Y is true as nicely.
This supervised machine studying algorithm classifies all new instances based mostly on outdated instances saved which might be segregated into totally different courses based mostly on their similarity scores. Okay Nearest Neighbours (KNN) is used for each regression and classification issues.
Okay refers back to the variety of close by factors thought-about throughout segregation and classification of a set of recognized teams. The algorithm does classification by a majority vote of the neighbouring Okay factors.
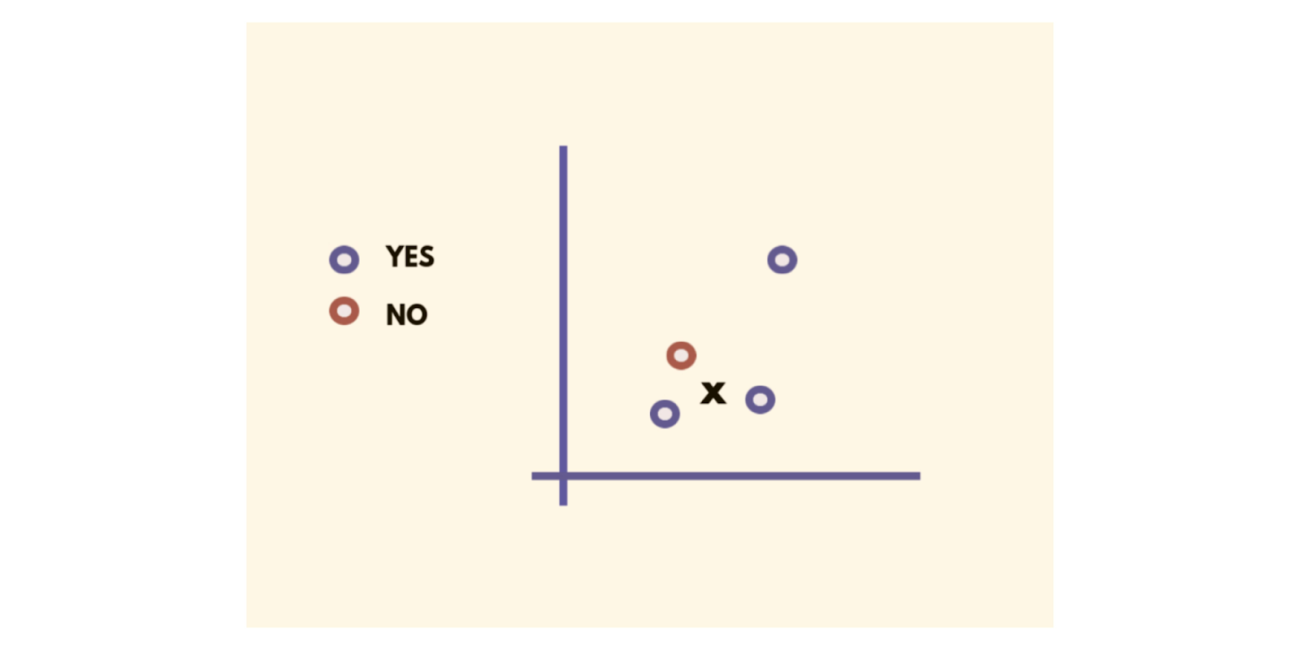
Main use instances and real-life purposes of the algorithm may be present in advice programs of OTT platforms like Amazon and Netflix, and likewise facial recognition programs.
For clustering duties, Okay-means is an unsupervised machine studying algorithm based mostly on distance. The algorithm classifies datasets into Okay clusters the place inside one set, the information factors stay homogenous, however not in numerous clusters.

This algorithm is utilized in clustering Fb customers who’ve widespread pursuits based mostly on their likes and dislikes, and likewise segmentation of comparable eCommerce merchandise.
One other supervised studying algorithm, Random bushes is a group of a number of determination bushes which might be constructed on totally different samples throughout coaching. It builds on the accuracy of determination bushes by mapping selections from totally different bushes onto a single tree referred to as a CART mannequin (Classification and Regression Bushes).

This helps in growing accuracy when in a dataset, a big chunk of knowledge is lacking. The ultimate prediction relies on the prediction end result which is voted the best. This algorithm is generally utilized in eCommerce advice engines and monetary fashions.
SVMs are supervised machine studying algorithms that plot particular person knowledge into quite a few dimensional areas, based mostly on the variety of options. Classification is carried out by figuring out the hyper-plane that distincts two units of help vectors.
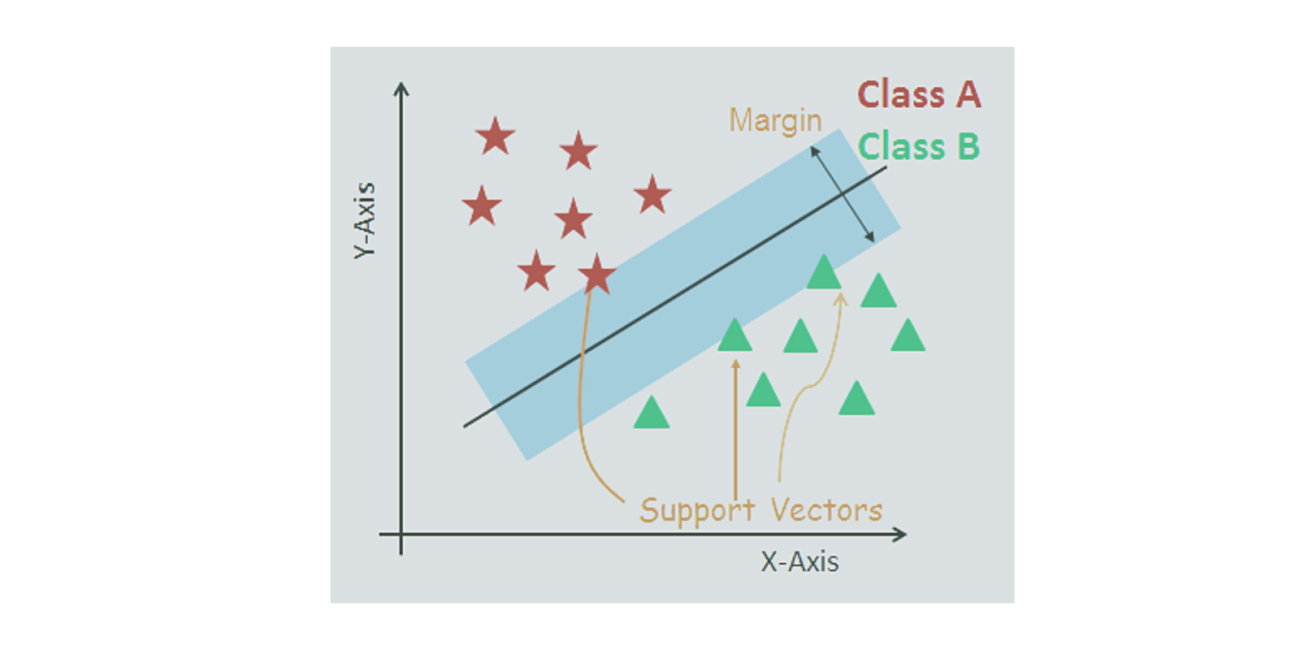
Merely, SVMs are for representing coordinates of particular person observations. These are popularly utilized in machine studying purposes like facial features classification, speech recognition, and picture detection.

{kind=link}