
Benchmark real-time anomaly detection strategies

On this weblog publish, we’ll evaluate the Histogram-based Outlier Rating (HBOS) a proximity-based outlier detection algorithm that proved to be quick with linear time complexity, and an ensemble methodology known as isolation Forest.
We are going to talk about the working precept behind these two algorithms in addition to their respective efficiency on the MacBook Professional M1 for 17 completely different datasets.
The Outlier Detection DataSets (ODDS) group overtly offers information units that can be utilized to benchmark anomaly detection algorithms. They supply completely different sorts of information for a number of areas and all the time present the bottom fact that we are able to use to evaluate outlier detection tasks.
The Histogram-based Outlier Rating (HBOS) is a machine-learning algorithm to determine information outliers. The algorithm was printed in 2012 by Goldstein, Markus, and Andreas Dengel in a paper known as “Histogram-based outlier rating (HBOS): A quick unsupervised anomaly detection algorithm.” [1].
That is achieved by making a histogram of the information for every dimension after which calculating a rating primarily based on how doubtless a selected information level is to fall throughout the histogram bins for every dimension.
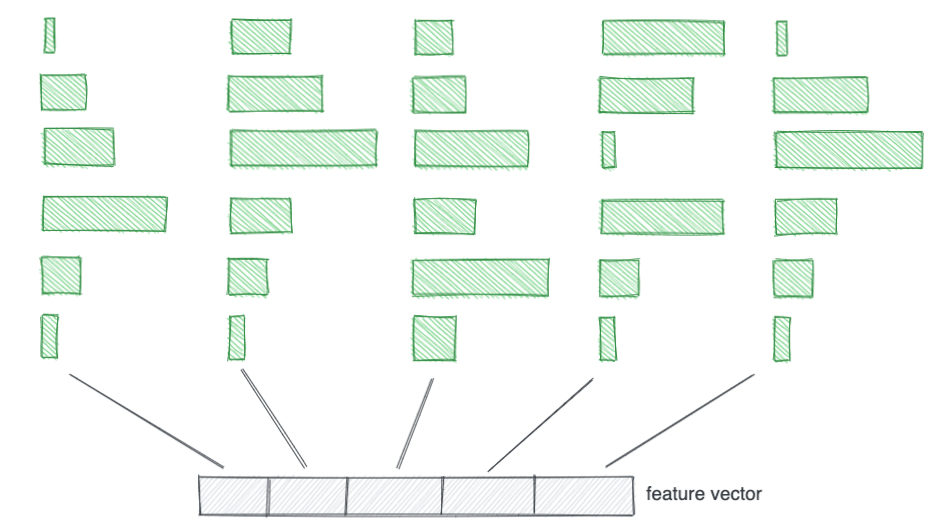
The upper the rating, the extra doubtless it’s that the information level is an outlier.
To calculate the rating of an occasion (a knowledge level), we have a look at which bins the occasion falls into. More often than not, the function vector will occupy very doubtless bins as within the illustration beneath.

Then again, a function vector that comes from an anomaly will occupy unlikely bins in a single or a number of of its dimensions as illustrated within the image beneath.

The metric proposed within the unique paper [1] to compute the anomaly rating is the next:
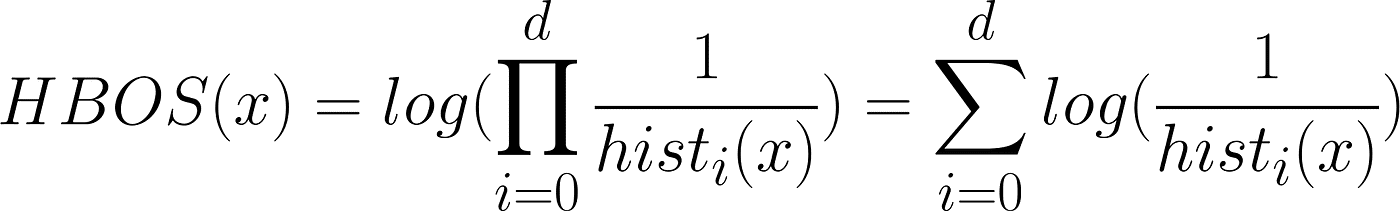
The concept is to multiply the inverse of the ensuing bins for every function vector dimension.
From our earlier instance, the rating is considerably greater for the primary function vector that describes an outlier that falls into not possible bins:

And the extra doubtless function vector could have a decrease rating:
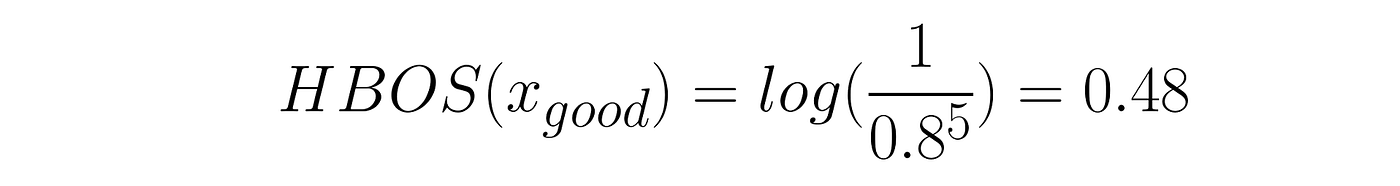
Chances are you’ll surprise why the HBOS equation makes use of the log perform?
The objective to use the log is to get an anomaly rating that’s much less delicate to extraordinarily small bin values and the errors that it may possibly carry due to errors unavoidable with floating-point precision.
The log is monotonically rising and due to this fact doesn’t change the order of the rating.
HBOS could be efficient at figuring out outliers in each low-dimensional and high-dimensional information in an environment friendly means. However, the binning methodology of the histogram for every dimension will have an effect on the time complexity. Within the case of the repair binning methodology (as within the illustration above), the bins have equal sizes and the time complexity is linear, i.e. O(n).
A dynamic binding methodology can also be doable and inspired in case we have no idea the distribution of every dimension or if we face long-tail distributions. However in that case, the time complexity turns into O(n log(n)).
Isolation forest (iForest) is an anomaly detection algorithm that works by isolating samples and assigning them a rating primarily based on how straightforward they’re to isolate. The algorithm was first offered in 2008 by Liu, Fei Tonym Kai Ming Ting, and Zhi-Hua Zhou in a paper known as “Isolation forest” [2].
The iForest algorithm is easy to implement and can be utilized with any type of information (numeric, categorical, and many others.).

An isolation tree is constructed by splitting the information recursively. For example, to construct a call tree on 100 information factors with 10 dimensions, we’d first separate the 100 information factors into two elements, then cut up the separated elements into extra elements, and so forth and so forth.
To separate the information factors, we merely choose a random attribute from the ten dimensions and cut up the information in keeping with a random worth set on the chosen attribute.
Even when there are various random processes concerned in choosing the attribute and worth for splitting the information, it’s extra doubtless that an outlier can be cut up early.
For example we need to construct an isolation tree and separate the folks in keeping with their wealth. Elon Musk is projected to grow to be the world’s first trillionaire. So the vary of doable values for this attribute is 0 to 1 trillion. We randomly choose a quantity from 0 to 1 trillion–let’s say 2.5 billion–and we already separated the mass of those that personal lower than that from the rich folks.
The actual fact is that outliers find yourself on shorter paths in an isolation tree. The smaller the trail, the extra doubtless it’s that the information level is an outlier, and the upper the anomaly rating.
Lastly, the iForest algorithm builds a bunch of isolation bushes that output an anomaly rating and compute the common anomaly rating between all of the isolation bushes.
For this weblog publish, we used the Pyod library for benchmarking outlier detection algorithms.
It offers a simple strategy to evaluate completely different algorithms and select the very best one for a given information set. PyOD additionally affords quite a lot of options that make it handy for each analysis and manufacturing. Right here is the hyperlink to their web site if you need to run the identical benchmark on a unique machine:
Concerning the setup for the take a look at, the benchmark was executed with the next configuration:
- Mannequin Title: MacBook Professional
- Chip: Apple M1
- Max. CPU clock fee: 3.2 GHz
- Whole Variety of Cores: 8 (4 efficiency and 4 effectivity)
- Reminiscence: 16 GB
And right here we go, the common consequence from 10 unbiased trials:
On this planet of anomaly detection, there are various contenders, however for this weblog publish, we determined to check HBOS and iForest. Each of those strategies have been proven to be efficient in real-time purposes, however which one is healthier?
Overall, HBOS is normally a quicker methodology, however it is perhaps much less correct than iForest relying on the kind of dataset.
So, it actually depends upon your wants as to which methodology is healthier. If velocity is extra necessary, then HBOS is the best way to go. But when accuracy is paramount, and also you’re utilizing a high-dimensional function vector then you could need to use iForest.

{kind=link}