
Easy steps to make your Jupyter Notebooks nice

Writing Jupyter Notebooks which can be reproducible, maintainable, and simple to know shouldn’t be as simple as you would possibly suppose. In truth, it’s fairly the alternative. It’s really actually onerous. On this article, I’m going to clarify why it’s so onerous and offer you some suggestions for finest practices that helped me to realize higher reproducibility and maintainability.
First, let me offer you a brief introduction what Jupiter Notebooks are. Mainly, a Jupyter Pocket book is an interactive doc. You’ll be able to write plain textual content with Markdown syntax and likewise use mathematical formulation through LaTeX syntax. Moreover, you may add code to a pocket book that the reader can execute to supply some output resembling a visualization.
As an example, you can visualize a perform that’s based mostly on numerous parameters. The reader might use sliders to alter the values of those parameters and the visualization is up to date each time a worth is modified (see the instance under). You could possibly additionally add code that performs reside queries to some database to get the newest gross sales numbers and to plot them in an pie chart as an illustration.
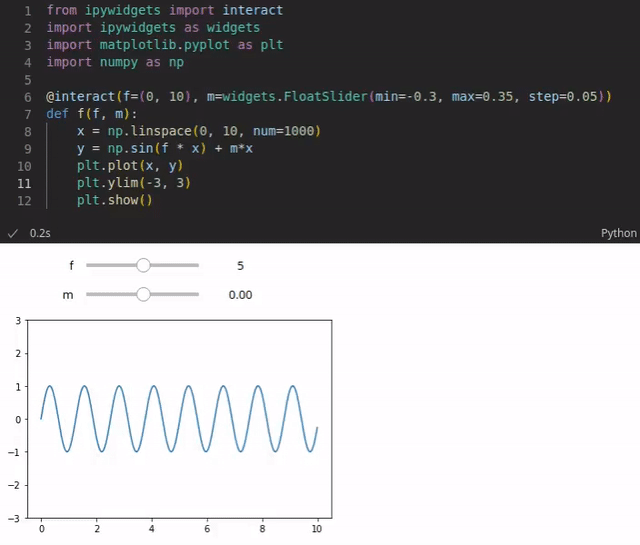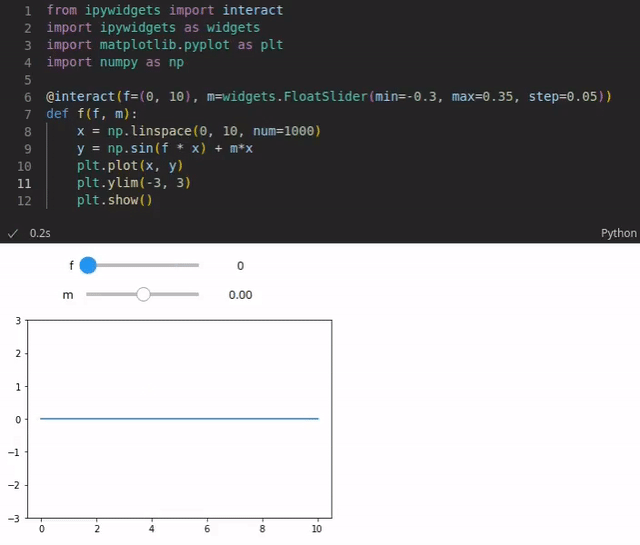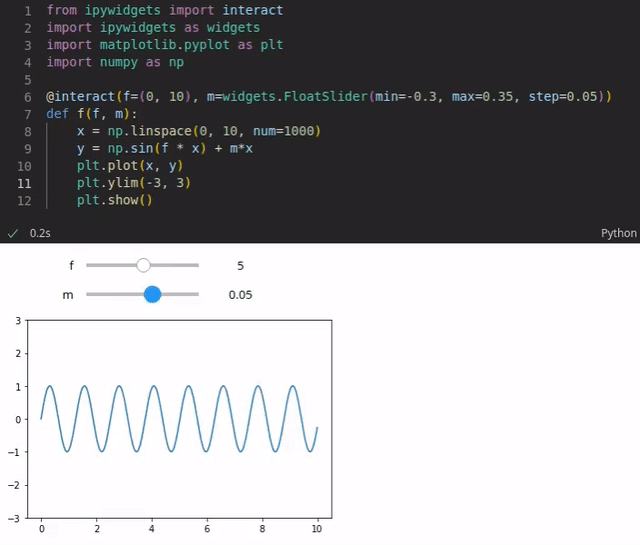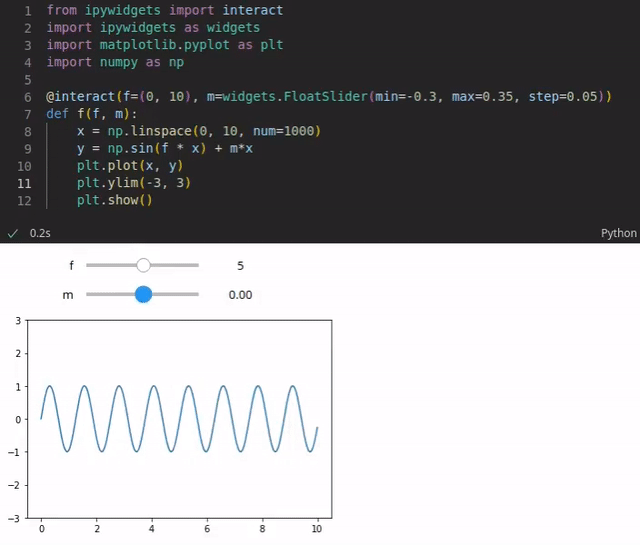
The code is often written in Python. Nonetheless, greater than 100 programming languages are supported resembling Java, R, Julia, Scala and so forth. Notebooks could be written and executed within the browser. Nonetheless, though writing notebooks within the browser is feasible (rudimentary code completion exists), it’s restricted. Fortuitously, you can even use IDEs resembling Visible Studio Code or PyCharm (within the Skilled model) which offer extra highly effective options.
You can too use cloud companies to jot down and execute notebooks. Google, as an illustration, gives with Google Colab an answer that lets you run notebooks within the cloud and share them with everybody. Even GPUs could be accessed in Google Colab at no cost for intensive computational duties.
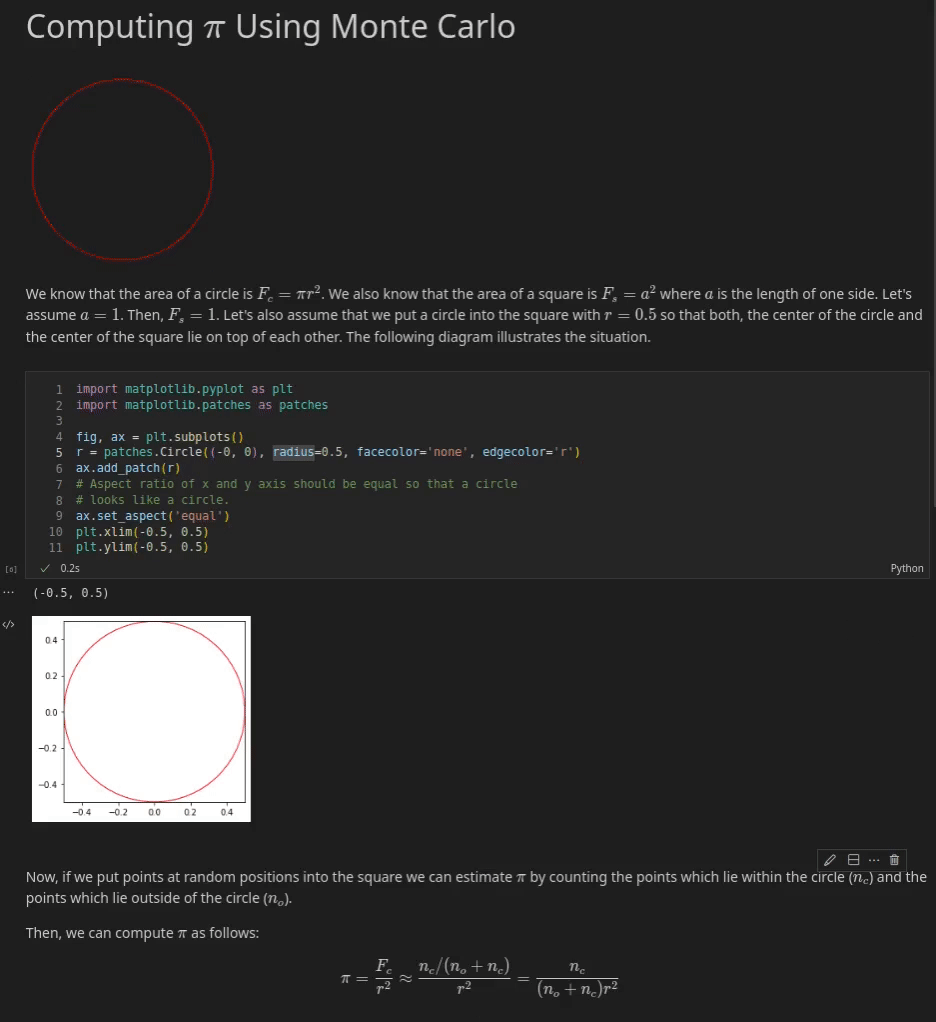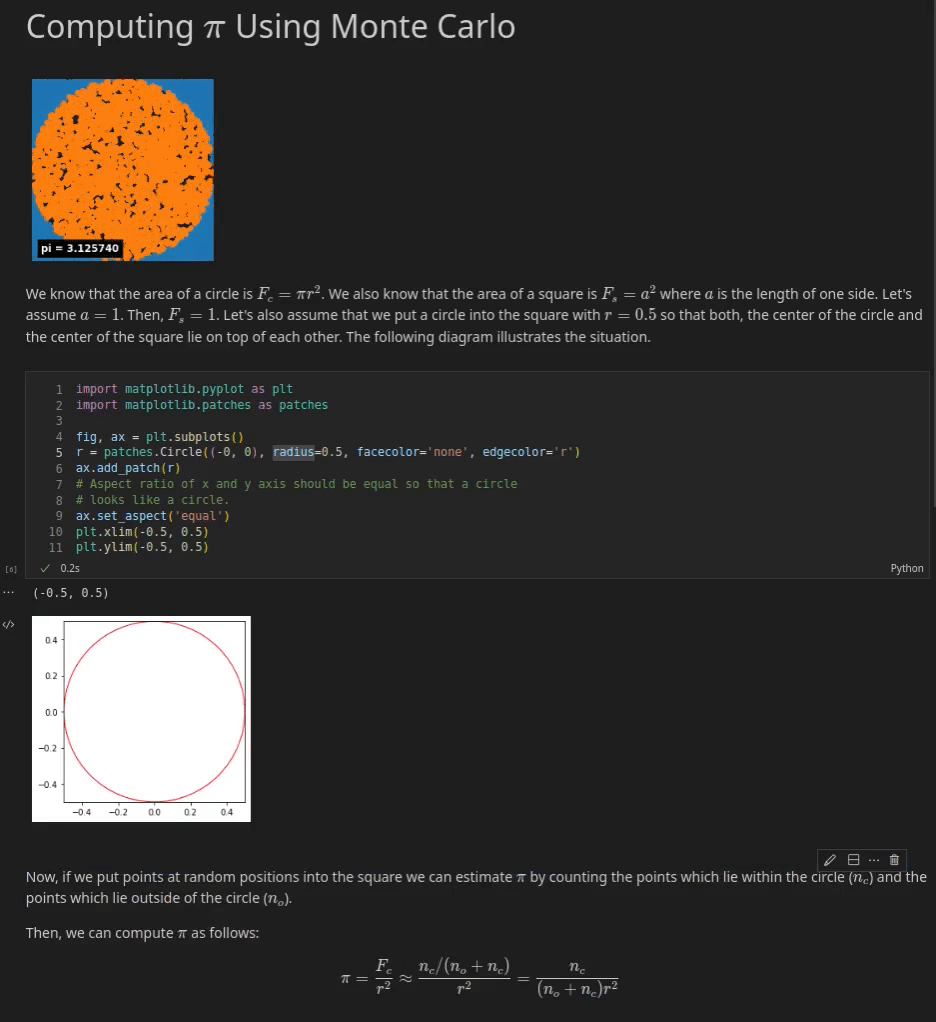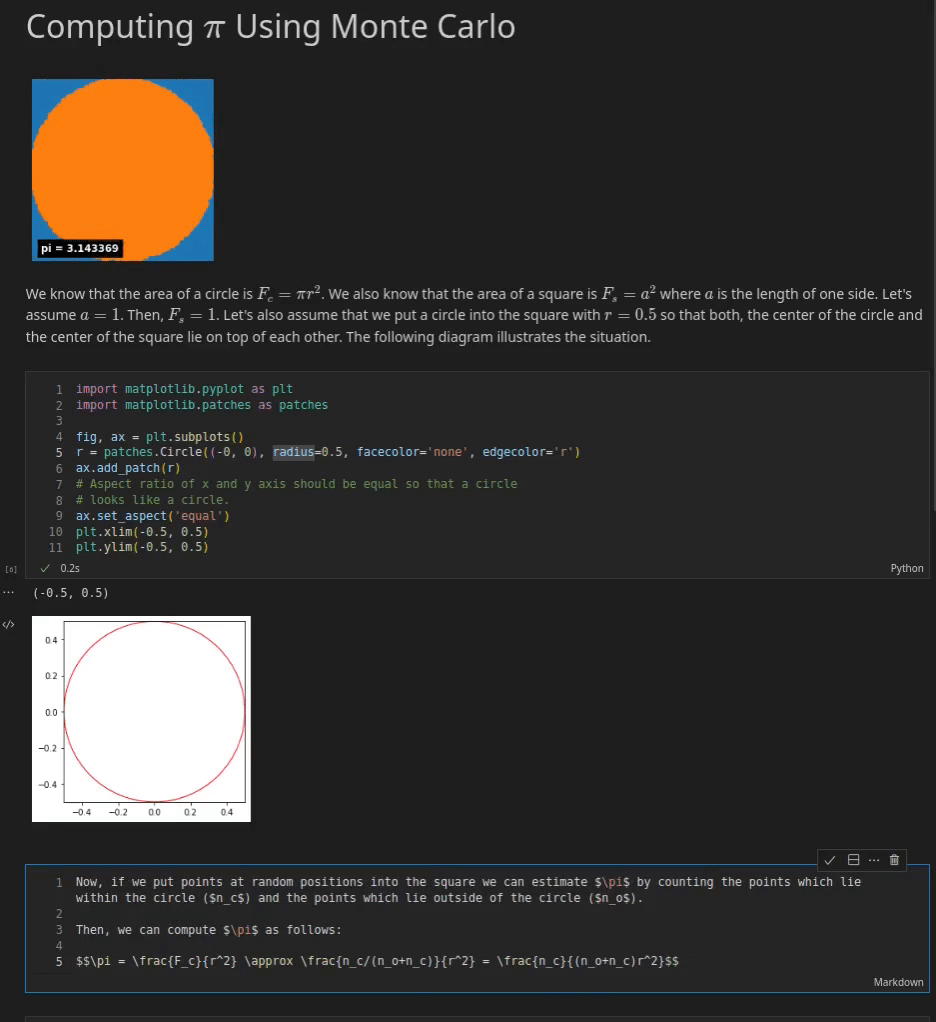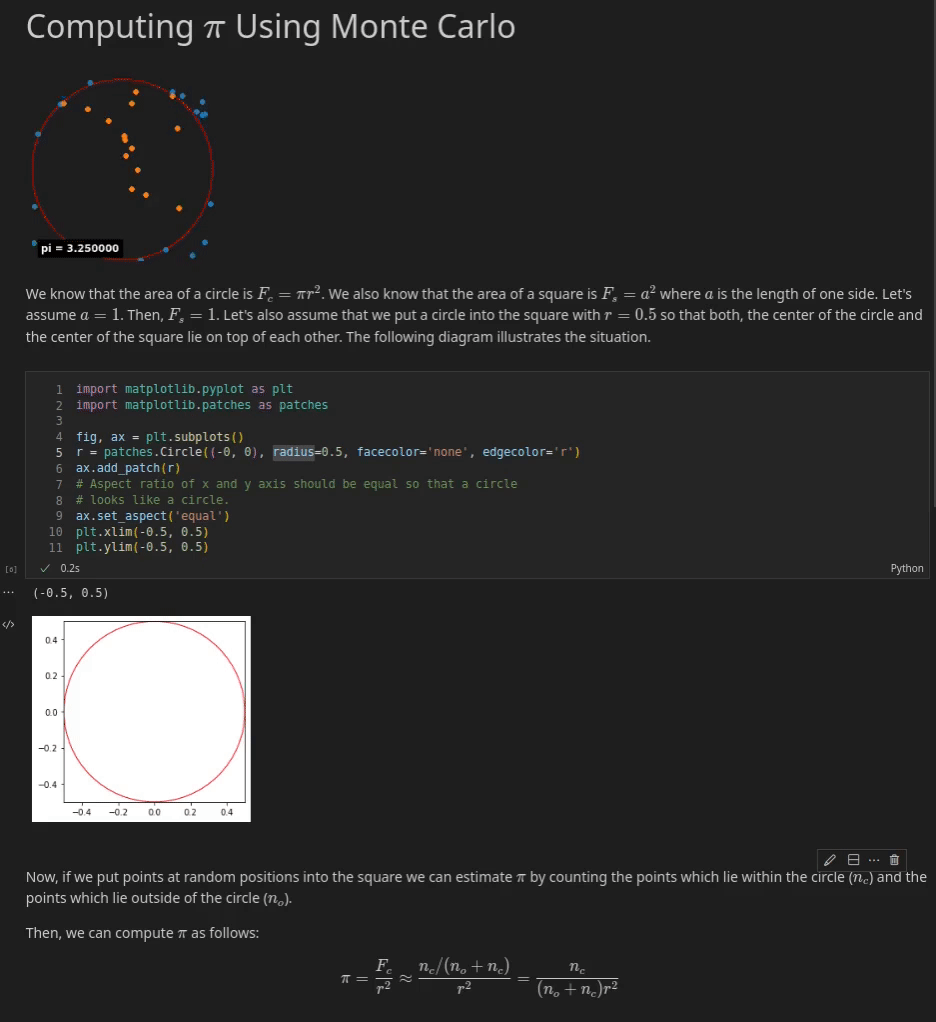
Under you may see an instance of a Jupyter Pocket book which explains tips on how to approximate π with a Monte Carlo Methodology. You’ll be able to see three cells. The primary cell is a Markdown cell which supplies an introduction to the pocket book. It incorporates, textual content, an animation and a few simple arithmetic equations that are rendered through MathJax.
The second cell is a code cell that incorporates Python code. If this cell is executed the code produces a easy plot of a circle inside a sq..
The third cell is a Markdown cell once more which jumps between modifying mode and the rendered end result when the cell is executed. In modifying mode you may see the plain Markdown textual content.
Jupyter Notebooks have change into very talked-about. In October 2020 roughly 10 million public notebooks have been out there on GitHub. Notebooks are particularly standard within the tutorial group for instructional functions. Additionally information scientists are closely utilizing notebooks for information evaluation and exploratory process.
Specifically the mix of textual content and code makes them very fascinating. It permits the writer to clarify ideas in Markdown with expressive formulation and on the similar time it’s potential to point out an implementation as code in the identical doc. This distinctive attribute of Jupyter Notebooks permits higher reproducibility of analysis outcomes and distribution of instructional content material.
Regardless of their reputation, Jupyter Notebooks have been topic to criticism (e.g. I don’t like notebooks) as the way in which you may write code would possibly lead to dangerous habits. Listed here are some examples:
Naming of Notebooks
One anti-pattern that may be noticed generally is that notebooks don’t have expressive names. As a substitute notebooks generally begin with “Untitled” or finish with “-Copy” of their names. That is as a result of default habits of Jupyter working within the browser. Each time you create a brand new pocket book an untitled pocket book is created and each time you create a duplicate of an present pocket book, the brand new pocket book will get the suffix “-Copy”.
You would possibly assume that a variety of pocket book names endure from this anti-pattern if that is the default habits of Jupyter. However surprisingly, as found by a research [1], lower than 2% of the notebooks analyzed by the research (a subset of notebooks downloaded from GitHub) even have “Untitled” and fewer than 0.7% have “-Copy” of their names. So it doesn’t appear to be a giant difficulty.
Nonetheless, the identical research additionally discovered that just about 30% of the examined notebooks have characters of their names that aren’t really useful by the POSIX absolutely transportable filenames information which permits solely the characters [A-Za-z0–9.-_]. Notebooks with non-portable filenames would possibly trigger issues on some techniques and subsequently needs to be averted.
Ambiguous execution order
Cells in a Jupyter pocket book could be executed in arbitrary orders. You don’t have to start out on the first cell and finish with the final cell. You could possibly additionally begin with the second cell, leap again to the primary cell after which execute the third cell. You could possibly additionally execute cells a number of occasions in a row.
That is additionally a standard habits when writing a pocket book as a result of usually you write some code in a cell, you execute the cell and then you definitely modify and execute the cell repeatedly till you’re glad with the outcomes of that cell. Generally you additionally want to return to a beforehand executed cell to reinitialize a variable or as a result of it’s worthwhile to modify a beforehand outlined perform.
Because of that it’s generally troublesome to comply with the execution order which could negatively have an effect on the pocket book’s reproducibility.
Within the beforehand cited research [1] it was discovered that ambiguous execution order is a matter for a lot of notebooks. 14% of the analyzed notebooks have this difficulty.
Let’s take a look at a associated instance that demonstrates an extra downside. Within the following you may see 4 cells.
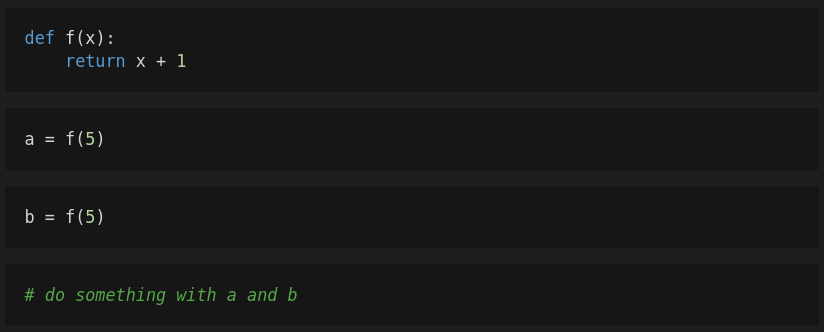
First, you execute the primary cell in order that the perform f is outlined. Then you definitely execute the second cell after which the variable a can have the worth 6. Subsequent, you are modifying the third cell however determine to barely change the code of the perform f. As a substitute of incrementing the variable x by one, the perform ought to increment x by two. After you might have modified the perform, you execute the primary cell once more in order that your modifications take impact and then you definitely execute the third cell. The variable b will get the worth 7. The next cells are working with these two variables.
In case you share this pocket book with different individuals, these individuals won’t be able to breed your outcomes as a result of they solely see the model of f that increments the variable x by two. If these individuals execute the pocket book step-by-step the variables a and b can have the worth 7 as a substitute of 6 and seven respectively.
Lacking modularization
In [1] it was discovered that
- solely 10% of the analyzed notebooks had native imports (i.e. imports of modules saved within the repository listing)
- 54% of the notebooks outline features
- lower than 9% of the notebooks outline courses
These outcomes present that modularization isn’t used usually for Jupyter Notebooks. That is fascinating as modularization is a properly established sample in software program engineering with many advantages. It helps to
- cut back code (e.g. much less copy&paste)
- break up advanced code into smaller items which can be simpler to know
- produce code that may be examined extra simply
- cut back the variety of world variables in a pocket book which can lead to decrease reminiscence utilization (native variables get freed extra usually as they exist solely of their native scope)
Nonetheless, not utilizing modularization can have many causes. As an example, notebooks with out features could also be easy sufficient in order that this abstraction shouldn’t be required. A pocket book may also not use modules as a result of the writer needs to simplify the distribution of a pocket book. That is simpler if only one single file must be distributed as a substitute of a number of recordsdata which might be the case if code is moved into modules.
Lacking exams
In software program engineering testing is a standard apply. Numerous testing methods exist resembling integration testing, regression testing or unit testing. You will discover a pleasant overview of various approaches on Wikipedia. Unit exams, as an illustration, are automated exams which check small items of a software program, usually a single perform.
Numerous frameworks exist for writing unit exams. For Python the module unittest is properly established and simple to make use of. In line with [1] solely few notebooks (lower than 2%) import well-known testing modules which may be an indicator that testing shouldn’t be extensively used.
Despite the fact that having no exams is an anti-pattern in software program engineering typically, it may be cheap for almost all of notebooks. Many notebooks are used for information analyzing and exploration to check speculation or for instructional functions to show one thing. Writing exams for these purposes usually doesn’t make a lot sense as a result of lacking floor truths in case of analyzing and exploration duties or as a result of the demonstration produces the anticipated outcomes.
Lacking dependencies
Jupyter Notebooks usually depend on numerous libraries and packages. In Python these dependencies are imported through the key phrase import. A model shouldn’t be specified for an import and subsequently, it isn’t potential to establish the required model of a bundle by simply its import. Nonetheless, if the variations of the dependencies are usually not documented elsewhere and if there isn’t a simple technique to set up all of the required dependencies, individuals might need issues executing a pocket book as a result of they in all probability will not have the ability to setup the required setting during which the pocket book is working.
Moreover, dependencies don’t have to be imported firstly of a pocket book. As a substitute, dependencies could be imported in every single place. Due to this fact, it may be troublesome to establish all required dependencies by simply trying firstly of a pocket book. As a substitute, you would need to scan the entire code.
And eventually, additionally the title of an import would possibly differ from the title of the bundle that have to be put in. As an example, to parse YAML recordsdata, PyYAML is extensively used. This bundle could be put in through pip set up pyyaml. Nonetheless, to make use of this bundle you must import yaml.
In line with [1] many notebooks don’t declare module dependencies.
Information inaccessibility
For a lot of notebooks to work information is required. As an example, notebooks about machine studying normally want a dataset that’s used for coaching. A validation set is used to find out the efficiency of the mannequin on unknown information. If this information shouldn’t be distributed with the pocket book and doesn’t exist, the outcomes of a pocket book can’t be reproduced.
In line with [1] inaccessibility of knowledge is a standard reason for errors when executing notebooks and two fundamental causes have been recognized. Both the information merely doesn’t exist, or in case the information is distributed with the pocket book, absolute paths are used to entry the information.
Restricted Reproducibility
A vital concept of Jupyter Notebooks is to make outcomes reproducible. This concept is one cause why notebooks acquire a lot reputation within the scientific group. Right here, reproducibility is essential as a result of the better it’s to breed outcomes the extra seemingly it’s that the outcomes produce new insights as others can reuse and construct in your work.
Nonetheless, based on [1] most of the analyzed notebooks on GitHub can’t be reproduced. The outcomes present that solely between 22% and 26% of the notebooks may very well be executed efficiently and that even solely 4.9% to fifteen% notebooks produced the identical outcomes.
There are principally three causes for non-reproducible notebooks which we’ve already mentioned:
- lacking dependencies
- out-of-order execution (and ensuing hidden states)
- information inaccessibility
To make sure that notebooks are simple to know, maintainable and reusable, and moreover to extend the chance {that a} pocket book’s outcomes could be reproduced, the next suggestions may be very useful:
- Use expressive names on your notebooks that describe what your pocket book is doing and use solely characters which can be included within the POSIX absolutely transportable filenames information.
- Keep away from ambiguous execution orders. To make sure that your pocket book is reproducible and creates the anticipated outcomes, restart the kernel and execute all cells of the pocket book earlier than you share your pocket book.
- Use modularization (i.e. modules, features, courses) if cheap.
- Use testing frameworks to check your code if cheap.
- Be certain that all information used within the pocket book is distributed along with the pocket book (or at the least could be downloaded) and that you simply’re utilizing relative paths to entry the information.
- Create a necessities.txt to pin the variations of all used dependencies and import all dependencies firstly of a pocket book.
- Distribute a pocket book with its outputs. This makes it simpler to breed the outcomes as everybody who executes the pocket book can confirm that the outcomes are the identical.
- Don’t redefine variables.
Jupyter Notebooks are simple to jot down, however numerous research have revealed that it appears to be onerous to jot down reproducible notebooks. Nonetheless, should you comply with some frequent finest practices, it certainly turns into extra seemingly that your notebooks could be reproduced, and that others can construct in your nice work. These finest practices additionally helped me to jot down good notebooks. From my standpoint, avoiding ambiguous execution orders, offering an inventory of used dependencies with their variations, and making the information that’s used within the pocket book simply accessible are crucial ones.
[1] Pimentel, João Felipe, et al. “Understanding and enhancing the standard and reproducibility of Jupyter notebooks.” Empirical Software program Engineering 26.4 (2021): 1–55.

{kind=link}