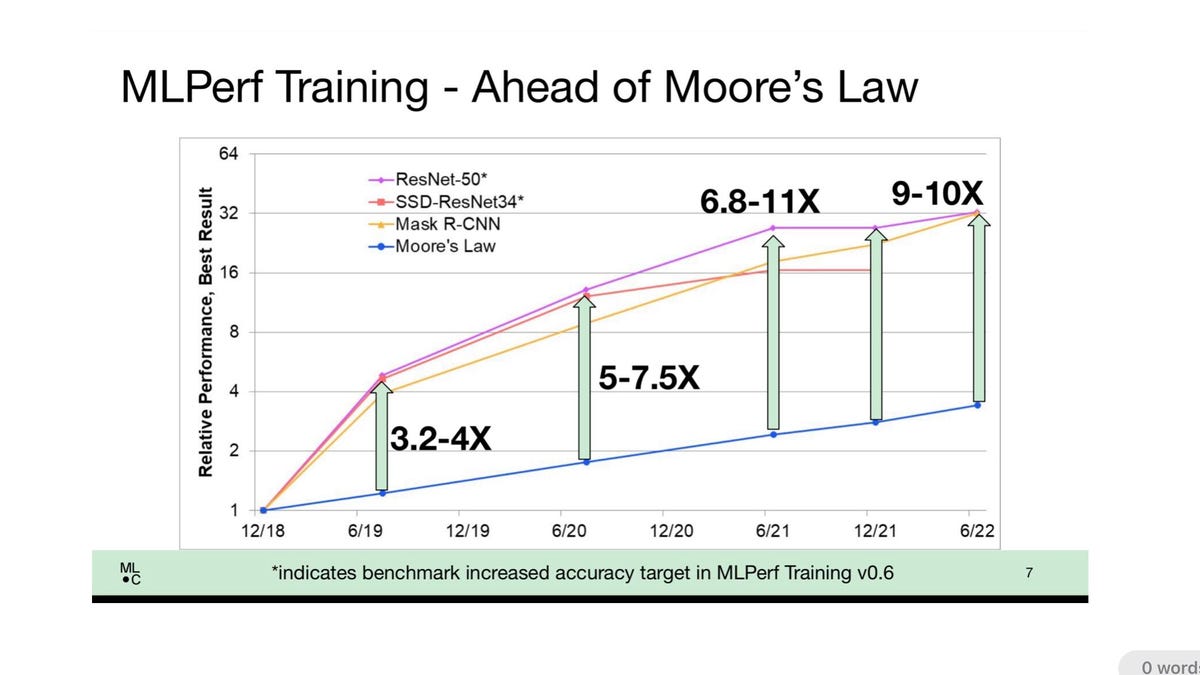
MLCommons director David Kanter made the purpose that enhancements in each {hardware} architectures and deep studying software program have led to efficiency enhancements on AI which might be ten occasions what can be anticipated from conventional chip scaling enhancements alone.
MLCommons
Google and Nvidia cut up the highest scores for the twice-yearly benchmark check of synthetic intelligence program coaching, based on information launched Wednesday by the MLCommons, the business consortium that oversees a well-liked check of machine studying efficiency, MLPerf.
The model 2.0 spherical of MLPerf coaching outcomes confirmed Google taking the highest scores when it comes to lowest period of time to coach a neural community on 4 duties for commercially out there techniques: picture recognition, object detection, one check for small and one for big photographs, and the BERT pure language processing mannequin.
Nvidia took the highest honors for the opposite 4 of the eight exams, for its commercially out there techniques: picture segmentation, speech recognition, advice techniques, and fixing the reinforcement studying job of enjoying Go on the “mini Go” dataset.
Additionally: Benchmark check of AI’s efficiency, MLPerf, continues to achieve adherents
Each firms had excessive scores for a number of benchmark exams, nonetheless, Google didn’t report outcomes for commercially out there techniques for the opposite 4 exams, just for these 4 it received. Nvidia reported outcomes for all eight of the exams.
The benchmark exams report what number of minutes it takes to tune the neural “weights,” or parameters, till the pc program achieves a required minimal accuracy on a given duties, a course of known as “coaching” a neural community.
Throughout all distributors, coaching occasions confirmed vital enhancements because of each better horsepower and smarter software program approaches. In a media briefing, the MLCommons’s government director, David Kanter defined that in broad strokes, the outcomes present that coaching has elevated in efficiency higher than Moore’s Legislation, the standard rule of thumb that claims a chip’s doubling in transistors each 18 to 24 months quickens laptop efficiency.
Scores on the venerable ImageNet job, for instance, the place a neural community is educated to assign a classifier label to tens of millions of photographs, is 9 to 10 occasions quicker immediately than easy chip enhancements would suggest, stated Kanter.
“We have carried out rather a lot higher than Moore’s Legislation,” stated Kanter. “You’d anticipate to get about three and a half occasions higher efficiency, assuming that transistors linearly relate to efficiency; because it seems, we’re getting 10x Moore’s Legislation.”
The advantages trickle all the way down to “the frequent man or lady,” stated Kanter, “the researcher with a single workstation” containing simply 8 chips, he stated.
Nvidia, which dominates gross sales of the GPU chips that make up the vast majority of AI computing on this planet, routinely submits outcomes for many or the entire exams. These single workstations are seeing enhancements or 4 to eight occasions easy transistor scaling, he famous. “We’re placing much more capabilities into the palms of researchers, which permits us to run extra experiments and, hopefully, make extra discoveries.”
Google, whose TPU is among the principal opponents to Nvidia chips, has a a lot much less constant observe document with MLPerf. In December’s benchmark report, the corporate solely submitted one check quantity, for an experimental use of its TPU on the BERT check.
Google stated in ready remarks, “Google’s TPU v4 [version 4] ML supercomputers set efficiency information on 5 benchmarks, with a mean speedup of 1.42x over the subsequent quickest non-Google submission, and 1.5x vs our MLPerf 1.0 submission.”
Google’s reference to 5 benchmarks features a reported greatest rating on advice techniques for a analysis system that’s not commercially out there.
Requested by ZDNet why Google selected to compete with industrial techniques within the 4 classes and never the opposite 4, the corporate stated in an electronic mail response, “Our intent with submissions is to focus totally on workloads that maximize advantages past MLPerf for us.
“We decide on which fashions to submit based mostly on their resemblance to ML fashions used inside Google and by prospects of Google Cloud. Submitting and tuning benchmarks is a major quantity of labor so we focus our efforts to maximise advantages past MLPerf for us.
“Given this, we centered our efforts on 4 benchmarks for the Cloud out there class – BERT, ResNet, RetinaNet, MaskRCNN.”
Additionally: Google makes use of MLPerf competitors to showcase efficiency on gigantic model of BERT language mannequin
Nvidia emphasised the great scope of submissions by itself and by companions together with Dell and Lenovo. Computer systems utilizing Nvidia chips of 1 variety or one other have been chargeable for 105 techniques and 235 reported check outcomes out of the overall 264 reported outcomes.
“NVIDIA and its companions continued to offer one of the best general AI coaching efficiency and essentially the most submissions throughout all benchmarks with 90% of all entries coming from the ecosystem, based on MLPerf benchmarks launched immediately,” Nvidia government Shar Narasimhan stated in ready remarks.
“The NVIDIA AI platform coated all eight benchmarks within the MLPerf Coaching 2.0 spherical, highlighting its main versatility.”
Additionally: MLCommons unveils a brand new technique to consider the world’s quickest supercomputers
Amongst different developments, the MLPerf check continued to achieve adherents and garnered extra check outcomes than in previous. A complete of 21 organizations reported the 264 check outcomes, up from 14 organizations and 181 reported submissions within the December model 1.1 report.
The brand new entrants included Asustek; the Chinese language Academy of Sciences, or CASIA; laptop maker H3C; HazyResearch, the identify submitted by a single grad pupil; Krai, which has participated within the different MLPerf competitors, inference, however by no means earlier than in coaching; and startup MosaicML.
Amongst top-five industrial techniques, Nvidia and Google have been trailed by a handful of submitters that managed to realize third, fourth or fifth place.
Additionally: AI business, obsessive about pace, is detest to contemplate the vitality price in newest MLPerf benchmark
Microsoft’s Azure cloud unit took second place within the picture segmentation competitors, fourth place within the object detection competitors with high-resolution photographs, and third place within the speech recognition competitors, all utilizing techniques with AMD EPYC processors and Nvidia GPUs.
Laptop maker H3C took fifth place in 4 of the exams, the picture segmentation competitors, the thing detection competitors with high-resolution photographs, the suggestions engine, and Go sport enjoying, and was capable of additionally make it to fourth place in speech recognition. All of these techniques used Intel XEON processors and Nvidia GPUs.
Dell Applied sciences held the fourth place in object detection with the lower-resolution photographs, and fifth place within the BERT natural-language check, each with techniques utilizing AMD processors and Nvidia GPUs.
Laptop maker Inspur took fifth place in speech recognition with a system utilizing AMD EPYC processors and Nvidia GPUs, and held the third and fourth-place ends in advice techniques, with XEON-based and EPYC-based techniques, respectively.
Additionally: Graphcore brings new competitors to Nvidia in newest MLPerf AI benchmarks
Graphcore, the Bristol, England-based startup constructing computer systems with another chip and software program strategy, took fifth place in ImageNet. IT options supplier Nettrix took fourth place within the picture segmentation competitors and fourth place within the Go reinforcement studying problem.
In a briefing for journalists, Graphcore emphasised its means to offer aggressive scores versus Nvidia at decrease costs for its BowPOD machines with various numbers of its IPU accelerator chips. The corporate touted its BowPOD256, for instance, which had the fifth-place rating in ResNet picture recognition, being ten occasions quicker than an 8-way Nvidia DGX system, whereas costing much less cash.
“Crucial factor is unquestionably the economics,” stated Graphcore’s head of software program, Matt Fyles, in a media briefing. “We’ve had a development in previous of machines getting quicker however costlier, however now we have drawn a line within the sand, we can’t make it costlier.”
Additionally: To measure ultra-low energy AI, MLPerf will get a TinyML benchmark
Though some smaller Graphcore machines path one of the best scores or Nvidia and Graphcore by a coupe of minutes of coaching time, “None of our prospects care about a few minutes, what they care about is whether or not you are aggressive and you may then resolve the issue that they care about,” he stated.
Added Fyles, “There are a a lot of initiatives with hundreds of chips, however now business goes to broaden what else you are able to do with the platform somewhat than simply, We have to win this benchmark competitors — that is the race to the underside.”
As in previous studies, Superior Micro Units had bragging rights over Intel. AMD’s EPYC or ROME server processors have been utilized in 79 of 130 techniques entered, a better proportion than Intel XEON chips. Furthermore, 33 of the highest 40 outcomes throughout the eight benchmark exams have been AMD-based techniques.
As in previous, Intel, along with having its XEON processor in companion techniques, additionally made its personal entries with its Habana Labs unit, utilizing the XEON coupled with the Habana Gaudi accelerator chip as a substitute of Nvidia GPUs. Intel centered the trouble solely on the BERT pure language check however did not crack the highest 5.
Seven of the the eight benchmark exams have been all the identical because the December competitors. The one new entry was a substitute for one of many object detection duties, the place a pc has to stipulate an object in an image and hooked up a label to the define figuring out the thing.
On this new model, the extensively used COCO information set and SSD neural community have been changed with a brand new information set, OpenImages, and a brand new neural community, RetinaNet.
OpenImages makes use of picture information which might be larger than 1,200 by 1,600 pixels. The opposite object detection job nonetheless makes use of COCO, which makes use of lower-resolution, 640 by 480-pixel photographs.
Within the media briefing, the MLCommons’s Kanter defined that the OpenImages information set is mixed with a brand new benchmark neural web for submitters to make use of. The prior community was based mostly on the traditional ResNet neural web for picture recognition and picture segmentation.
The choice used within the new check, known as RetinaNet, improves accuracy by way of a number of enhancements to the ResNet construction. For instance, it provides what’s known as a “function pyramid,” which appears to be like in any respect the appears to be like on the context round an object, in all layers of the community, concurrently, somewhat than only one layer of a community, which provides context to allow higher classification.
Additionally: Nvidia makes a clear sweep of MLPerf predictions benchmark for synthetic intelligence
“Characteristic pyramids are a method from traditional laptop imaginative and prescient, so that is in some methods a riff on that traditional strategy utilized within the area of neural networks,” stated Kanter.
Along with the function pyramid, the underlying structure of RetinaNet, known as ResNeXt, handles convolutions with a brand new innovation on ResNet. Basic ResNet makes use of what are known as “dense convolutions” to filter pixels by the peak and width of a picture in addition to the RGB channels. The ResNeXt breaks the RGB filters into separate filters which might be generally known as “grouped convolutions.” These teams, working in parallel, study to focus on elements of the colour channels. That additionally contributes to better accuracy.
Additionally: Nvidia and Google declare bragging rights in MLPerf benchmarks as AI computer systems get greater and larger
Additionally: Google, Nvidia tout advances in AI coaching with MLPerf benchmark outcomes
Additionally: MLPerf benchmark outcomes showcase Nvidia’s high AI coaching occasions

{kind=link}