
Detect, analyze, and mitigate knowledge and mannequin drift in an automatic trend
By Natasha Savic and Andreas Kopp
Change is the one fixed in life. In machine studying, it reveals up as drift of knowledge, mannequin predictions, and decaying efficiency, if not managed rigorously.

On this article, we focus on knowledge and mannequin drift and the way it impacts the efficiency of manufacturing fashions. You’ll be taught strategies to determine and to mitigate drift and MLOps greatest practices to transition from static fashions to evergreen AI providers utilizing Azure Machine Studying.
We additionally embody a pattern pocket book if you wish to check out the ideas in sensible examples.
Many machine studying tasks conclude after a part of intensive knowledge and have engineering, modeling, coaching, and analysis with a passable mannequin that’s deployed to manufacturing. Nevertheless, the longer a mannequin is in operation, the extra issues can creep in that may stay undetected for fairly a very long time.
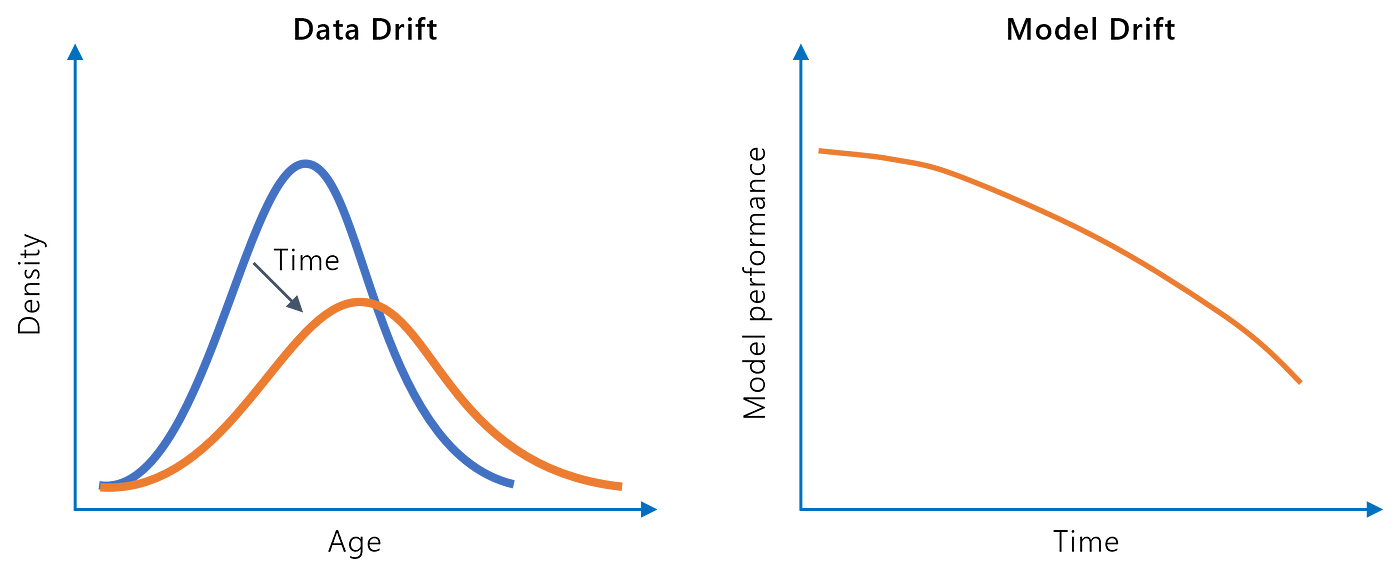
Knowledge drift signifies that distributions of enter knowledge change over time. Drift can result in a spot between what the mannequin has initially discovered from the coaching knowledge and the inferencing observations throughout manufacturing. Let’s take a look at a number of examples of knowledge drift:
- Actual-world modifications: an initially small demographic group more and more seems within the labor market (e.g., warfare refugees); new regulatory frameworks come into play influencing person consent (e.g., GDPR)
- Knowledge acquisition issues: incorrect measurements as a consequence of a damaged IoT sensor; an initially obligatory enter area of an internet kind turns into optionally available for privateness causes
- Knowledge engineering issues: unintended coding or scaling modifications or swap of variables
Mannequin drift is accompanied by a lower in mannequin efficiency over time (e.g., accuracy drop in a supervised classification use case). There are two primary sources of mannequin drift:
- Actual-world modifications are additionally known as idea drift: The connection between options and goal variables has modified in the actual world. Examples: the collapse of journey actions throughout a pandemic and; rise of inflation impacts shopping for conduct.
- Knowledge drift: The described drift of enter knowledge may additionally have an effect on mannequin high quality. Nevertheless, not each prevalence of knowledge drift is essentially an issue. When drift happens on much less necessary options the mannequin may reply robustly, and efficiency just isn’t affected. Allow us to assume {that a} demographic cohort (a selected mixture of age, gender, and earnings) happens extra usually throughout inferencing than seen throughout coaching. It received’t trigger complications if the mannequin nonetheless predicts the outcomes for this cohort accurately. It’s extra problematic if the drift leads the mannequin into much less populated and/or extra error-prone areas of the function house.
Mannequin drift usually stays undetected till new floor reality labels can be found. The unique check knowledge is now not a dependable benchmark as a result of the real-world perform has modified.
The next illustration summarizes the varied sorts of drift:

The transition from regular conduct to float could be vastly totally different. Demographic modifications in the actual world usually result in gradual knowledge or mannequin drift. Nevertheless, a damaged sensor may trigger abrupt deviations from the traditional vary. Seasonal fluctuations in shopping for conduct (e.g., Christmas season) are manifested as a recurring drift.
If we now have timestamps for our observations (or the info factors are at the least organized chronologically), the next could be finished to detect, analyze and mitigate drift.

We are going to describe these strategies in additional element under and experiment with them utilizing a predictive upkeep case research.

The choices to research and mitigate knowledge and mannequin drift depend upon the provision of present knowledge over the machine studying mannequin’s lifecycle.
Allow us to assume {that a} financial institution collected historic knowledge to coach a mannequin to help credit score lending selections. The aim is to foretell whether or not a mortgage software needs to be accepted or rejected. Labeled coaching knowledge was collected within the interval from January to December 2020.
The financial institution’s knowledge scientists have spent the primary quarter of 2021 coaching and evaluating the mannequin and determined to deliver it to manufacturing in April 2021. Allow us to take a look at three choices the staff can use for accumulating manufacturing knowledge:

State of affairs 1: Static mannequin
Right here, the staff doesn’t gather any manufacturing knowledge. Maybe they didn’t think about this in any respect since their venture scope solely lined delivering the preliminary mannequin. Another excuse may very well be open knowledge privateness questions (storing regulated private knowledge).
Clearly, there may be not a lot that may be finished to detect knowledge or mannequin drift past analyzing the historic coaching knowledge. Drift might solely be uncovered when mannequin customers begin complaining concerning the mannequin predictions have gotten more and more unsuitable for enterprise selections. Nevertheless, since suggestions just isn’t systematically collected, gradual drift will probably stay undiscovered for a very long time.
Apparently, many productive machine studying fashions are run on this mode in the present day. Nevertheless, machine studying lifecycle administration procedures like MLOps are getting extra traction in apply to handle points like these.
The static mannequin strategy is perhaps acceptable if the mannequin is educated on consultant knowledge and the function/goal relationship is steady over time (e.g., organic phenomena which change at an evolutionary tempo).
State of affairs 2: Gathering manufacturing knowledge
The staff decides to gather noticed enter knowledge (options) from the manufacturing part along with the corresponding mannequin predictions.
This strategy is easy to implement if there aren’t any knowledge safety issues or different organizational hurdles. By evaluating the current manufacturing knowledge with unique coaching observations, drift in options and predicted labels could be discovered. Important shifts in key options (by way of function significance) can be utilized as a set off for additional investigation.
Nevertheless, important data is lacking to seek out out if there’s a downside with the mannequin: we should not have new floor reality labels to guage the manufacturing predictions. This may result in the next conditions:
- Digital drift (false constructive): We observe knowledge drift, however the mannequin nonetheless works as desired. This will likely get the staff to accumulate new labeled knowledge for retraining though it’s pointless (from a mannequin drift perspective).
- Idea drift (false unfavourable): Whereas there isn’t a drift within the enter knowledge, the real-world perform has moved away from what the mannequin had discovered. Therefore, an more and more outdated mannequin results in inaccurate enterprise selections.
State of affairs 3: Evergreen mannequin
On this state of affairs, the financial institution not solely analyzes manufacturing enter and predictions for potential drift but in addition collects labeled knowledge. Relying on the enterprise context, this may be finished in one of many following methods:
- Enterprise models contribute newly labeled knowledge factors (as was finished for the preliminary coaching)
- Human-in-the-loop suggestions: The mannequin predictions from the manufacturing part are systematically reviewed. Particularly false approvals and false rejections, discovered by area consultants, and the corresponding options with the corrected labels are collected for retraining.
Incorporating human-in-the-loop suggestions requires adjustment of processes and methods (e.g., enterprise customers can overwrite or flag incorrect predictions of their functions).
The primary benefits are that idea drift could be recognized with excessive reliability and the mannequin can recurrently be refreshed by retraining.
Incorporating enterprise suggestions and common retraining is an important a part of mature MLOps practices (see our reference structure instance for Azure Machine Studying under).
It’s important to have a detection mechanism that measures drift systematically. Ideally, such a mechanism is a part of an built-in MLOps workflow that compares coaching and inference distributions on a steady foundation. We have now compiled a number of mechanisms that help knowledge and mannequin drift administration.
We’re utilizing a predictive upkeep use case primarily based on an artificial dataset in our pattern pocket book. The aim is to foretell gear failure primarily based on options like pace or warmth deviations, operator, meeting line, days because the final service, and many others.
To determine drift, we mix statistical strategies and distribution overlaps (knowledge drift) in addition to predictive strategies (mannequin/idea drift). For each drift sorts, we’ll briefly introduce the strategy used.
Drift detection begins by partitioning a dataset of chronologically sorted observations right into a reference and present window. The reference (or baseline) window represents older observations and is commonly similar to the preliminary coaching knowledge. The present window usually displays more moderen knowledge factors seen within the manufacturing part. This isn’t a strict 1:1 mapping because it is perhaps wanted to regulate the home windows to higher find when drift occurred.

We first must differentiate between numerical and categorical/discrete knowledge. For the statistical exams, each varieties of knowledge will bear distinct non-parametric exams that present a p-value. We’re dealing with totally different pattern sizes and don’t make assumptions concerning the precise distribution of our knowledge. Subsequently, non-parametric approaches are a helpful strategy to check the similarity of two samples without having to know the precise likelihood distribution.

These exams permit us to simply accept or reject the null speculation with a level of confidence, as outlined by the p-value. As such, you may management the sensitivity of the check by adjusting the brink for the p-value. We suggest a extra conservative p-value equivalent to 0.01 by default. The bigger your pattern will get, the extra inclined it’s to select up on noise. Different generally used strategies to determine the drift between distributions are the Wasserstein Distance for steady and the JS Divergence for likelihood distributions.
Listed here are some greatest practices to restrict the variety of false alarms in drift detection:
- Scope the drift analyses to a shortlist of key options if in case you have many variables in your dataset
- Use a sub-sample as a substitute of all knowledge factors in case your dataset is massive
- Cut back the p-value threshold additional or choose an alternate check for bigger knowledge volumes
Whereas statistical exams are helpful to determine drift, it’s onerous to interpret the magnitude of the drift in addition to through which course it happens. Given a variable like age, did the pattern become old or youthful and the way is the age unfold? To reply these questions, it’s helpful to visualise the distributions. For this, we add one other non-parametric methodology: the Kernel Density Estimation (KDE). Since we now have two totally different knowledge sorts, we’ll carry out a pre-processing step on the explicit knowledge to transform it right into a pseudo-numerical notation by encoding the variables. The identical ordinal encoder object is used for each the reference and the present distributions to make sure consistency:
Now that we now have encoded our knowledge, we will visually examine both the whole dataset or chosen variables of curiosity. We use the Kernel Density Estimation capabilities of the reference and present samples to compute their intersection in p.c. The next steps had been tailored from this pattern:
- Move the info right into a KDE perform as in scipy.stats.gaussian_kde() with the bandwidth methodology “scott”. The parameter determines the diploma of smoothing of the distribution.
- Take the vary (min and max of each distributions) and compute the intersection factors of each KDE capabilities inside this vary through the use of the differential of each capabilities.
- Carry out pre-processing for variables which have a continuing worth to keep away from errors and align the size of each distributions.
- Approximate the world underneath the intersection factors utilizing the composite trapezoidal rule as per numpy.trapz().
- Plot the reference and present distributions, intersection factors in addition to the world of intersection with the proportion of overlap.
- Add the respective statistical check (KS or Chi-Sq.) to the title and supply a drift indication (Drift vs. No Drift)
The steps could be understood in additional depth by trying out the code samples. The results of the KDE intersections seems to be as follows:

A short inspection of the plots tells us:
- Which variables have considerably totally different distributions between the reference and present pattern?
- What’s the magnitude and course of the drift?
If we take a look at the variable “operator”, we will see that there was a considerable change by way of which worker was working the machine between when the mannequin was fitted versus in the present day. For instance, it may have occurred that an operator has retired and, consequently, doesn’t function any machines anymore (operator 2). Conversely, we see that new operators have joined who weren’t current earlier than (e.g., operator 6).
Now that we now have seen learn how to uncover drift in options and labels, allow us to discover out if the mannequin is affected by knowledge or idea drift.
Just like earlier than, we stack the historic (coaching) observations and lately labeled knowledge factors collectively in a chronological dataset. Then, we evaluate mannequin efficiency primarily based on the newest observations, as the next overview illustrates.

On the core, we need to reply the query: Does a more moderen mannequin carry out higher in predicting on most up-to-date knowledge than a mannequin educated on older observations?
We most likely don’t know prematurely if and the place drift has crept in.
Subsequently, in our first try, we’d use the unique coaching knowledge as reference and the inference observations as present home windows. If we discover the existence of drift by this, we’ll probably check out totally different reference and present home windows to pinpoint the place precisely drift crept in.
A few choices exist for predictive mannequin drift detection:

Every possibility has particular benefits. Because of the primary different, you have already got a educated candidate prepared for deployment if mannequin 2 outperforms mannequin 1. The second possibility will probably cut back false positives, on the expense of being much less delicate to float. Different 3 reduces pointless coaching cycles in instances the place no drift is recognized.
Let’s take a look at learn how to use possibility 1 to seek out drift in our predictive upkeep use case. The aggregated dataset consists of 45,000 timestamped observations which we spilt into 20,000 references, 20,000 present, and 5,000 most up-to-date observations for the check.
We outline a scikit-learn pipeline to preprocess numerical and categorical options and practice two LightGBM classifiers for comparability:
After repeating the final step for the present classifier, we evaluate the efficiency metrics to seek out out if there’s a noticeable hole between the fashions:

The present mannequin outperforms the reference mannequin by a big margin. Subsequently, we will conclude that we certainly have recognized mannequin drift and that the present mannequin is a promising candidate for changing the manufacturing mannequin. A visible method of inspection is to check the distributions of confidence scores of each classifiers:

The histograms on the left present a transparent distinction between the anticipated class possibilities of the reference and present fashions and subsequently additionally affirm the existence of mannequin drift.
Lastly, we reuse our KDE plots and statistical exams from the info drift part to measure the extent of the drift. The intersection between the KDE plots for each classifiers quantities to solely 85%. Moreover, the outcomes of the KS check recommend that the distributions aren’t similar.
On this instance, the outcomes had been to be anticipated as a result of we deliberately constructed drift into our artificial predictive upkeep dataset. With a real-world dataset, outcomes received’t all the time be as apparent. Additionally, it is perhaps essential to strive totally different reference and present window splits to reliably discover mannequin drift.
We are going to now concentrate on embedding drift detection and mitigation in an MLOps structure with Azure Machine Studying. The next part leverages ideas equivalent to Azure ML Datasets, Fashions, and Pipelines. The demo repository offers an instance of an Azure ML pipeline for producing the info drift detection plots. To automate the re-training of fashions, we suggest utilizing the most recent Azure MLOPs code samples and documentation. The next illustration offers a pattern structure together with all the things we discovered about knowledge and mannequin drift to date.

By contemplating drift mitigation as a part of an automatic Azure MLOps workflow, we will keep evergreen ML providers with manageable effort. To take action, we carry out the next steps:
- Ingest and model knowledge in Azure Machine Studying
This step is essential to take care of a lineage between the coaching knowledge, machine studying experiments, and the ensuing fashions. For automation, we use Azure Machine Studying pipelines which eat managed datasets. By specifying the model parameter (model=”newest”) you may guarantee to acquire the newest knowledge. - Practice mannequin
On this step, the mannequin is educated on the supply knowledge. This exercise will also be a part of an automatic Azure Machine Studying pipeline. We suggest including a number of parameters just like the dataset identify and model to re-use the identical pipeline object throughout a number of dataset variations. By doing so, the identical pipeline could be triggered in case mannequin drift is current. As soon as the coaching is completed, the mannequin is registered within the Azure Machine Studying mannequin registry. - Consider mannequin
Mannequin analysis is a part of the coaching/re-training pipeline. Moreover efficiency metrics to see how good a mannequin is, an intensive analysis additionally consists of reviewing explanations, checking for bias and equity points, the place the mannequin makes errors, and many others. It’ll usually embody human verification. - Deploy mannequin
That is the place you deploy a selected model of the mannequin. Within the case of evergreen fashions, we might deploy the mannequin that was fitted to the most recent dataset. - Monitor mannequin
Assortment of telemetry concerning the deployed mannequin. For instance, an Azure AppInsights workbook can be utilized to gather the variety of requests made to the mannequin occasion in addition to service availability and different user-defined metrics. - Acquire inference knowledge and labels
As a part of a steady enchancment of the service, all of the inferences which might be made by the mannequin needs to be saved right into a repository (e.g., Azure Knowledge Lake) alongside the bottom reality (if accessible). This can be a essential step because it permits us to determine the quantity of drift between the inference and the reference knowledge. Ought to the bottom reality labels not be accessible, we will monitor knowledge drift however not mannequin drift. - Measure knowledge drift
Based mostly on the earlier step, we will kick off the info drift detection through the use of the reference knowledge and contrasting it towards the present knowledge utilizing the strategies launched within the sections above. - Measure mannequin drift
On this step, we decide if the mannequin is affected by knowledge or idea drift. That is finished utilizing one of many strategies launched above. - Set off re-training
In case of mannequin or idea drift, we will set off a full re-training and deployment pipeline using the identical Azure ML pipeline we used for the preliminary coaching. That is the final step that closes the loop between a static and an evergreen mannequin. The re-training triggers can both be:
Computerized — Evaluating efficiency between the reference mannequin and present mannequin and mechanically deploying if the present mannequin efficiency is best than the reference mannequin.
Human within the loop — Examine knowledge drift visualization alongside efficiency metrics between reference and present mannequin and deploy with an information scientist/ mannequin proprietor within the loop. This state of affairs can be appropriate for extremely regulated industries. This may be finished utilizing PowerApps, Azure DevOps pipelines, or GitHub Actions.
On this article, we now have checked out sensible ideas to seek out and mitigate the drift of knowledge and machine studying fashions for tabular use instances. We have now seen these ideas in motion utilizing our demo pocket book with the predictive upkeep instance. We encourage you to adapt these strategies to your personal use instances and admire any suggestions.
Having the ability to systematically determine and handle the drift of manufacturing fashions is a giant step towards mature MLOps practices. Subsequently, we suggest integrating these ideas into an end-to-end manufacturing answer just like the MLOps reference structure launched above. The final a part of our pocket book consists of examples of learn how to implement drift detection utilizing automated Azure Machine Studying Pipelines.
Knowledge and mannequin drift administration is just one constructing block of a holistic MLOps imaginative and prescient and structure. Be happy to take a look at the documentation for basic details about MLOps and learn how to implement it utilizing Azure Machine Studying.
In our examples, we now have checked out tabular machine studying use instances. Drift mitigation approaches for unstructured knowledge like photographs and pure language are additionally rising. The Drift Detection in Medical Imaging AI repository offers a promising methodology of analyzing medical photographs at the side of metadata to detect mannequin drift.
All photographs until in any other case famous are by the authors.

{kind=link}