
Kafka enables real-time data processing and movement across distributed systems, supporting use cases such as log aggregation, messaging, event sourcing, and data integration.
However, managing costs while maintaining Kafka’s performance and reliability can be challenging due to its complex architecture, the need for high throughput and low latency, and the substantial storage and computational resources required. Balancing these factors demands careful planning and optimization to ensure efficient operation without escalating expenses. In this article, we’ll explain what drives Kafka costs and walk you through how to set up the most cost-efficient Kafka clusters for your use cases.
Much of Kafka’s costs come from the underlying costs of the supporting computing infrastructure. If you can manage the drivers of that resource consumption, you can lower your overall costs. Here’s a breakdown of some key elements that drive Kafka costs:
- Compute: The number of brokers and their types (CPUxMemory).
- Data transfer: Charges are based on the amount of data transferred in and out of Kafka clusters. In the public cloud, where your application resides, providers charge for data transfer based on volume, source, and destination. Egress (read) costs are a significant consideration, especially for large volumes of data (usually the case when it comes to solutions like Kafka).
- Storage: The storage capacity required to meet the retention requirements.
An example of Aiven’s Kafka pricing plans:

As your workload scales and requires extra brokers/CPUs/RAM/storage, so does the plan your Kafka cluster requires.
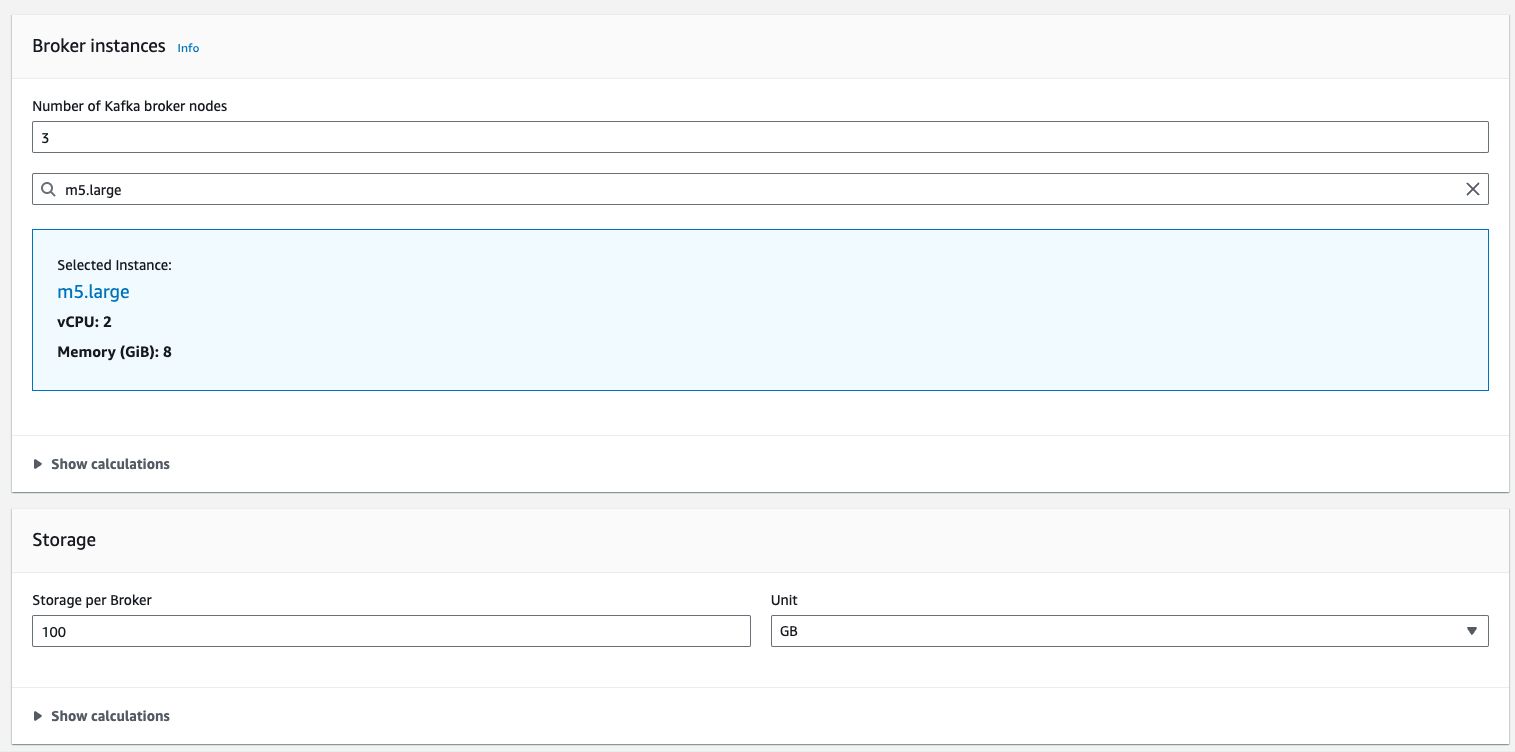
An instance of AWS MSK calculation components:
Since Kafka is open-source software program managed by the Apache Basis, you possibly can obtain it and set up it totally free. Nevertheless, you’ll doubtless wish to set up it right into a high-capacity, extremely out there cluster, in all probability on a cloud occasion. Many cloud suppliers present a managed Kafka, and every has its personal value construction. There are three deployment sorts: serverless, hosted, and self-hosted, and every has distinctive value implications.
Serverless:
- A turn-key answer. The seller is accountable for protecting the cluster alive, safe, scaleable, together with many of the lifecycle-related administration. The infrastructure layer is totally clear to the person.
- Utilization-based pricing.
- Often takes below account the variety of partitions, visitors, storage, and working hours.
Hosted:
- The appliance deployment, lifecycle administration, safety, and monitoring are managed by the seller.
- Offers the person extra freedom but additionally will increase threat and operational burden because the person is required to handle each the applying and sure points of the infrastructure.
- Commonplace server prices: hours, visitors, storage, variety of vCPUs, and quantity of reminiscence.
Self-hosted:
- The person is accountable for each facet of the cluster, from infrastructure to the applying itself.
- Frequent deployment sort in high-velocity, secured, and controlled environments the place a devoted infrastructure is required for each efficiency and a better degree of elasticity.
- Self-hosted will be cost-efficient in two situations: very small scale or very huge (large) scale, the place the margins taken by the seller are vital. A fast tip: take the quick monitor and ask your self upfront if there’s a correlation between enterprise outcomes and the size of our Kafka.
Kafka is a dynamic server with extremely variable workloads. Smaller environments (processing a couple of megabytes per second) might not have the identical necessities as giant environments for environment friendly utilization. Nevertheless, managing fluctuations between high and low peaks is essential in large-scale streaming environments. The Kafka setting should effectively take in these variations.
Decreasing prices isn’t a matter of one-time fixes; it’s a steady course of. As demand scales, your Kafka cluster will want extra computing sources. When you can configure your clusters to function in a cost-efficient method, you possibly can guarantee dynamic demand by no means breaks the financial institution. Price discount is definitely the end result of being cost-efficient.
Attaining cost-efficiency in high-volatility environments is important for reducing total prices. To do that successfully, some key actions should be taken:
- Repeatedly optimize: It begins by eliminating inactive sources like matters, idle shopper teams, and idle connections. These sources eat useful sources out of your cluster, contribute to CPU, Reminiscence, and storage utilization, and enhance rebalances. If they aren’t wanted, it’s best to remove them.
- Shrink your payload: Allow client-level compression and use extra environment friendly information codecs like Avro or Protobuf. The final one does require a sure curve, however as soon as carried out, your CFO will really feel the financial savings, and your utility will try.
- Keep away from the default: Repeatedly fine-tune your brokers to match your present workload by updating its num.community.threads and num.io.threads. There isn’t any one-size-fits-all configuration. You must iterate and experiment. Discovering the candy spot of each will enhance your cluster throughput and responsiveness with out including extra {hardware}, which is able to enhance your spending.
- Undertake dynamic sizing: Shift from static to dynamic useful resource allocation. Guarantee your Kafka clusters use solely the mandatory {hardware}/sources at any given second.
Hopefully, we’ve acquired you on board for cost-efficient Kafka clusters. However to get the advantages in the true world, you’ll must decide to the work required. Under, we lay out precisely what you have to be doing to ensure your Kafka clusters run effectively.
An environment friendly Kafka cluster must be consistently adjusted so that you’re utilizing solely the sources which can be required now. Cluster hundreds will change over time, so what makes it environment friendly will change as effectively. The duties beneath needs to be carried out recurrently primarily based on fixed monitoring.
- Determine and scale back inactive matters and partitions. Inactive matters imply matters that haven’t been accessed in a sure period of time. Every implementation has its personal enterprise logic. To securely mark a subject as inactive, you want to monitor every matter over sufficient time (primarily based in your setting data) to make sure no shopper teams periodically eat information from these matters past the time window that you simply outlined as sufficient to declare inactivity.Now that we’ve recognized the matters and partitions to be diminished, let’s repair it. We’ve three choices for a way to do this:
-
- Possibility 1: Delete: That is an irreversible motion, however the perfect one for producing vital financial savings. Give it some thought like picture compression. You could have totally different ranges of compression, and every can have an effect on the picture otherwise. The upper the ratio, the decrease the standard of the picture. On this case, deletion will present probably the most financial savings, however on the identical time, it will increase the danger of harming some functions or use circumstances.
- Possibility 2: Recreate: When deleting a subject, there are two dangers. First, an utility may attempt to entry that matter, and if its exceptions will not be dealt with correctly, it can crash. Second, an utility may not crash however does count on the deleted information. Recreation is about recreating a subject to no less than keep away from the primary situation.
- Possibility 3: Archiving: Think about archiving the information to cheaper storage options as an alternative of deleting inactive matters and partitions. This ensures information retention insurance policies are met with out incurring excessive prices.
- Determine and scale back inactive connections.
-
- Connection monitoring: Observe all energetic and inactive connections in actual time. This helps determine stale connections that may be safely terminated.
- Connection limits: Configure connection limits to stop extreme useful resource consumption by inactive connections. This ensures that solely vital connections are maintained.
- Timeout settings: Alter timeout settings to robotically shut connections which have been inactive for a specified interval. This reduces the burden on sources and improves total system effectivity.
- Determine and scale back inactive shopper teams.
-
- Common audits: Conduct common audits of shopper teams to determine these which can be inactive. Inactive shopper teams may cause as much as 40% extra partition rebalances, impacting efficiency.
- Utilization metrics: Observe utilization metrics like offset motion over time to know exercise by sure shopper teams. This information can information choices on consolidating or eradicating inactive teams. If customers depend on the state of a deleted shopper group, they are going to recreate the group and skim offsets primarily based on their configuration, which could begin from the earliest message.
- Automated administration: Implement automated processes to handle shopper teams primarily based on their exercise ranges, guaranteeing sources are allotted effectively and cost-effectively.
- Compress information despatched from producers.
-
- Compression algorithms: Consider totally different compression algorithms (akin to GZIP, Snappy, or LZ4) to find out which supplies the perfect stability between compression ratio and efficiency on your workload.
- Consider algorithms:
-
- Efficiency testing: Conduct efficiency testing to measure the affect of compression on each information dimension and system efficiency. This ensures that the chosen compression methodology doesn’t adversely have an effect on system throughput.
- Ongoing evaluation: Periodically reassess compression settings to make sure they continue to be optimum as information patterns and workload traits evolve over time.
- Non-binary payloads.
- Knowledge format conversion: Serialize non-binary payloads (akin to JSON or XML) to binary codecs (akin to Avro or Protocol Buffers) to cut back information dimension and enhance transmission effectivity.
- Payload optimization: Implement payload optimization methods, akin to eradicating pointless metadata or utilizing extra environment friendly serialization strategies, to additional lower information dimension.
- Training and coaching: Educate builders and information engineers on the advantages of utilizing binary codecs and greatest practices for payload optimization. This ensures constant implementation throughout the group.
There are two foremost really useful methods to shrink your payload with out “paying” useful cluster sources: client-level compression and the usage of binary payload as an alternative of non-binary (JSON). Selecting and implementing even considered one of them can tremendously affect your visitors prices, in addition to storage and total throughput.
Consumer-level compression
Kafka helps a number of compression codecs that you should utilize to cut back the dimensions of your messages. The frequent compression sorts supported by Kafka embrace:
- GZIP: A preferred compression algorithm that gives a great stability between compression ratio and velocity. It is extensively used and supported by many instruments.
- Snappy: A quick compression algorithm with reasonable compression ratios, designed for velocity. It is a good selection when low latency is crucial.
- LZ4: One other quick compression algorithm, just like Snappy however typically quicker in decompression. It’s appropriate for situations the place each excessive velocity and cheap compression ratios are wanted.
- ZSTD: A more recent compression algorithm that gives excessive compression ratios and velocity, making it a good selection for situations the place maximizing storage financial savings is essential.
To allow compression on the producer degree, the compression.sort parameter must be set with one of many algorithms above. Since Kafka 3.8, it’s also possible to tune the compression algorithm degree and achieve larger ratios when accurately match with the producer workload (primarily message dimension).
No JSONs. Use binary codecs
Payload serialization utilizing Protobuf or Avro is usually employed to boost information high quality and governance. Nevertheless, it additionally performs a major function in lowering information dimension whereas providing a extra CPU- and memory-efficient deserialization course of in comparison with conventional decompression strategies. Implementing these serialization codecs does include a studying curve and requires managing an extra element, like a Schema Registry, to deal with and preserve schemas. However as soon as that is arrange, you possibly can count on a clean and dependable operation shifting ahead. A very good sense for the potential outcomes will be discovered here.
All of it is determined by your scale. As with every different utility, default parameters have been created to supply a turnkey answer for the most typical use circumstances to realize a faster onboarding course of with out an excessive amount of problem. Particularly in Kafka, understanding and tuning the totally different buffers and timers can considerably affect your complete cluster habits in serving far more information.
These are crucial properties to “keep away from utilizing the default”:
- num.partitions: Defines the default variety of partitions per matter. Adjusting this could enhance parallelism and throughput.
- log.retention.hours / log.retention.bytes: Controls how lengthy information is retained on the dealer. Tuning these can assist handle storage utilization.
- log.phase.bytes: Determines the dimensions of every log phase file on disk. Smaller segments can result in extra frequent log cleanup however can enhance restoration time after a failure.
- log.cleaner.allow: Enabling this enables for compacted matters, which helps scale back the quantity of disk area utilized by matters with keyed information.
- compression.sort: Configures the compression algorithm for the producer. Choices embrace gzip, snappy, lz4, and zstd. Choosing the proper compression can scale back payload dimension and enhance throughput.
- acks: Determines the extent of acknowledgment the producer requires from the dealer. acks=all ensures information sturdiness however can enhance latency, whereas acks=1 or acks=0 can scale back latency however at the price of potential information loss.
- batch.dimension: Controls the utmost dimension of a batch of messages. Bigger batch sizes can enhance throughput however might enhance latency.
- linger.ms: Introduces a small delay earlier than sending batches, permitting extra information to build up in a batch. This will enhance throughput however may enhance latency.
- retries: Configures the variety of retry makes an attempt when a request fails. Increased retry counts can enhance reliability however enhance producer latency.
- fetch.min.bytes: Specifies the minimal quantity of information the dealer ought to ship to the buyer in a fetch request. Rising this could scale back the variety of fetch requests however might enhance latency.
- fetch.max.wait.ms: Controls the utmost time the dealer will wait earlier than sending information to the buyer. Tuning this alongside fetch.min.bytes can stability throughput and latency.
- max.ballot.information: Limits the variety of information returned in a single ballot request. Adjusting this can assist with reminiscence administration and processing velocity on the buyer aspect.
- session.timeout.ms: Determines how lengthy the buyer can go with out sending a heartbeat to the dealer earlier than it’s thought-about lifeless. Shorter timeouts can detect failures quicker however might result in extra frequent rebalances.
- socket.ship.buffer.bytes and socket.obtain.buffer.bytes: Tuning these properties can assist optimize the community efficiency of the Kafka brokers.
- duplicate.fetch.max.bytes: Units the utmost information dimension a dealer will attempt to fetch from one other dealer. This impacts replication efficiency.
- min.insync.replicas: Defines the minimal variety of replicas that should acknowledge a write for it to be thought-about profitable. Tuning this improves sturdiness at the price of probably larger latency.
- message.max.bytes: Units the utmost dimension of a message that Kafka can settle for. That is vital when coping with giant messages.
- duplicate.lag.time.max.ms: Determines the utmost lag time a follower can have earlier than it’s thought-about out of sync. Adjusting this helps in sustaining information consistency throughout replicas.
- auto.create.matters.allow: Disabling this in manufacturing environments can stop the unintended creation of matters with default settings, which could not be preferrred for efficiency.
There are not any silver bullets and that’s the reason we don’t advocate a sure worth per property. Adjusting the above values should be completed fastidiously, not in manufacturing first, and constantly tuned and iterated on.
Shifting from static to dynamic useful resource allocation in Kafka entails implementing methods and instruments that modify useful resource utilization primarily based on present demand. This ensures that your Kafka clusters use the mandatory sources at any given second, optimizing efficiency and value.
Implement monitoring and alerting programs
- Actual-time monitoring: Use monitoring instruments to trace useful resource utilization metrics akin to CPU, reminiscence, disk I/O, and community throughput.
- Alerting mechanisms: Arrange alerts for thresholds that point out when sources are under- or over-utilized.
Instance instruments:
- Prometheus and Grafana: Accumulate and visualize metrics and arrange alerts.
- Datadog: Offers monitoring, alerting, and dashboards for real-time visibility.
- CloudWatch (AWS), Azure Monitor, Google Cloud Monitoring: Native cloud monitoring providers.
Implement useful resource quotas and limits
- Quotas: Outline quotas to restrict the quantity of sources that may be consumed or produced by particular person Kafka clusters or tenants.
- Useful resource limits: Set useful resource limits to stop any single course of or person from consuming extreme sources.
Instance instruments:
- Apache Kafka’s Quota Administration: Controls the speed at which information is produced and consumed.
You gained’t discover any such information for comparable elements as a result of Kafka is actually distinctive. When you’re simply starting your Kafka journey, it is likely to be smart to bookmark this information for future reference. Nevertheless, when you’re scaling up or anticipate vital development in your Kafka utilization, we strongly advocate getting ready now by following the rules we have outlined. Failing to take action might result in substantial and unexpectedly fast value will increase. Completely happy streaming!

{kind=link}