Utilizing native BigQuery performance to generate a dynamic, distinctive row identifier in SQL
There are a variety of various causes you would possibly need to construct a hash of every row of information in a BigQuery dataset, however they’re largely associated to the truth that there isn’t any enforced main key in BigQuery.
Which means your information would possibly include duplicate rows, whether or not it’s from upstream information assortment or transmission errors, misconfigured information ingestion instruments, or just a results of by accident loading one thing twice.
Or one thing else. Who is aware of?
Regardless of the supply of duplicates, it’s best to at all times attempt to perceive what they’re and doubtless filter them out (in addition to establish the foundation trigger, if you happen to care about that sort of factor… FYI you most likely ought to).
In the event you do have duplicate rows in your information, as quickly as you begin making use of extra advanced transformations like joins, you threat amplifying the errors and invalidating downstream processes, fashions and choices, costing hard-earned belief and probably inflicting different unpredictable, undesirable outcomes.
Or perhaps no one will discover. Would that be that higher or worse?
Wherever your information is coming from, it’s at all times a precious step in any information high quality assurance course of (and in your information transformation circulation) to verify that every row of your supply information is exclusive for each your peace of thoughts, and the reassurance of downstream information customers and methods.
A simplified definition of a hash operate is that it’s a operate which outputs a singular, fastened size string from an arbitrary string enter. It’s really a bit extra technical than that as it’s an array of bytes, but it surely behaves like a string in order that’s a reasonably great way of it.
A very powerful factors to grasp are that:
- any change to the enter will lead to a distinct hash
- it solely works a method — you can not back-calculate the enter from the hash, however you can confirm whether or not the inputs have been similar or not
- hashing lets you verify whether or not the inputs have been precisely the identical, which may be nice for environment friendly validation, particularly between totally different methods as then you should utilize language-specific implementations of the identical algorithm
There are just a few totally different native features and methods we’ll deploy to unravel this downside in a sublime, succinct and dynamic method.
For these examples we’re going to use the zoo_elephants desk, which comprises solely fabricated information in regards to the annual watermelon consumption of some imaginary elephants, and which is public, so obtainable to question for any authenticated BigQuery consumer. There are not any duplicates within the information (however we wish/must show that). To examine the information in your BigQuery console execute the next question:
SELECT *
FROM flowfunctions.examples.zoo_elephants
You will note the information in your outcomes panel, with the easy schema:
animal STRING,
title STRING,
12 months INT64,
watermelons INT64
That is a particularly sturdy and highly effective operate which (amongst variety of use-cases) lets you add a single column to a Widespread Desk Expression which is a JSON illustration of every row. To see the way it works, do that question out:
WITH
inbound_zoo_elephants AS (
SELECT *
FROM flowfunctions.examples.zoo_elephants
)
SELECT *,
TO_JSON_STRING(inbound_zoo_elephants) AS row_json
FROM inbound_zoo_elephants
You will note the output information now has a further column containing a JSON illustration of the information, for instance the row_json column of the primary row comprises the worth:
{"animal":"Elephant","title":"Beepbeep","12 months":2018,"watermelons":1032}
In the event you add a true elective pretty_print parameter to the operate:
TO_JSON_STRING(inbound_zoo_elephants, true) AS row_json
Then you can also make it fairly printed, with line breaks used to current the information in rows:
{
"animal": "Elephant",
"title": "Beepbeep",
"12 months": 2018,
"watermelons": 1032
}
This output is longer however simpler to learn, which is perhaps helpful. Nevertheless in our use-case the extra white area is pointless.
2. MD5()
Now for the hash operate… there are just a few totally different choices which give totally different lengths and varieties of outputs. We’re going to use a easy one, the MD5, which though it’s apparently cryptographically damaged, returns 16 characters and suffices for our use-case. Different choices are FARM_FINGERPRINT (which returns a signed integer of variable size), SHA1, SHA256 and SHA512, which return 20, 32 and 64 bytes respectively and are safer for cryptographic use circumstances. Nevertheless MD5 is seemingly the shortest one, subsequently it takes up much less display actual property (plus this isn’t a cryptographic use-case), so we’re going to go along with that:
WITH
inbound_zoo_elephants AS (
SELECT *
FROM flowfunctions.examples.zoo_elephants
),add_row_json AS (
SELECT *,
TO_JSON_STRING(inbound_zoo_elephants) AS row_json
FROM inbound_zoo_elephants
)
SELECT *,
MD5(row_json) AS row_hash
FROM add_row_json
You will note that therow_hash_column worth for the primary row will likely be one thing like:
xFkt7kQAks91FtJTt5d5lA==
This comprises alphanumeric in addition to particular characters, which can work for our goal however can trigger different points.
For instance, you could triple-click on it to pick out it, and if you happen to double-click then you definately solely get the string as much as the primary particular character (on this case: =). This may very well be an issue if you’re — like me— a human who’s liable to human error.
Go on, attempt to choose it. Then deselect it. Then choose it once more. It’s fairly annoying, isn’t it?
3. TO_HEX
The ultimate operate we’ll use to tidy up this output will convert the messy(ish) output of the earlier step to a pleasant tidy hexadecimal string, which is actually merely a string containing a mixture of the numbers 0-9 and the letters a-f.
WITH
inbound_zoo_elephants AS (
SELECT *
FROM flowfunctions.examples.zoo_elephants
),add_row_json AS (
SELECT *,
TO_JSON_STRING(inbound_zoo_elephants) AS row_json
FROM inbound_zoo_elephants
),add_row_hash AS (
SELECT *,
MD5(row_json) AS row_hash
FROM add_row_json
)
SELECT *,
TO_HEX(row_hash) AS hex_row_hash
FROM add_row_hash
Execute this code and you will notice that the worth of the the hex_row_hash column is one thing like:
c4592dee440092cf7516d253b7977994
Which is now 32 beautiful lowercase hexadecimal characters.
Attempt double-clicking on that and you’ll realise that the expertise of choosing it’s a way more human-proof interplay. And over a lifetime this can prevent roughly 33% when it comes to the variety of clicks required to pick out this, comparable to a probable decrease error charge and hopefully a decrease probability of repetitive pressure damage.
Notice that the output will solely include decrease case letters, so when you’ve got a selected penchant for capital letters ( I don’t), then you’ll be able to legitimately change the TO_HEX row to:
UPPER(TO_HEX(row_hash)) AS hex_row_hash
Which supplies the output:
DCBADCD29D37091C34BAFE4EE114DBA0
Nevertheless it is a redundant step, so we won’t do that. Plus I solely like to make use of capital letters for SQL key phrases as I discover it faster and simpler to scan and perceive the code construction with my human (and in addition considerably crappy) eyes.
So now the Widespread Desk Expression-structured question is obvious, with every CTE names giving a transparent description of the particular motion it’s taking:
WITH
inbound_zoo_elephants AS (
SELECT *
FROM flowfunctions.examples.zoo_elephants
),add_row_json AS (
SELECT *,
TO_JSON_STRING(inbound_zoo_elephants) AS row_json
FROM inbound_zoo_elephants
),add_row_hash AS (
SELECT *,
MD5(row_json) AS row_hash
FROM add_row_json
),add_row_hash_hex AS (
SELECT *,
TO_HEX(row_hash) AS hex_row_hash
FROM add_row_hash
)SELECT *
FROM add_row_hash_hex
It is a very helpful construction for creating and debugging, however fairly verbose and never particularly useable. As a primary step, now we all know that all the steps work we are able to refactor the code to be extra succinct:
WITH
inbound_zoo_elephants AS (
SELECT *
FROM flowfunctions.examples.zoo_elephants
)SELECT *,
TO_HEX(MD5(TO_JSON_STRING(inbound_zoo_elephants))) AS hex_row_hash
FROM inbound_zoo_elephants
That is shorter, however nonetheless not reuseable. Let’s bundle it up right into a easy operate to make it fast and easy to reuse at any time when we want it.
CREATE OR REPLACE FUNCTION `flowfunctions.hash.hex_md5_row_hash`(row_json STRING)
AS (
TO_HEX(MD5(row_json))
);
You may recreate this in your personal undertaking and dataset by altering the project_id (flowfunctions within the code above) and dataset_name (hash within the code).
And truly I like so as to add a single-line description to that customers can see the documentation in-place, which minimises activity switching and provides precious, natively obtainable metadata. Additionally, you will need to know that you simply go within the row_json parameter as TO_JSON_STRING (cte_name) so I clarify this right here within the description choice:
CREATE OR REPLACE FUNCTION `flowfunctions.hash.hex_md5_row_hash`(row_json STRING)
OPTIONS (
description="Returns: [STRING] Hexadecimal encoding of an MD5 hash of the JSON string illustration of a row. The row_json argument needs to be handed as TO_JSON_STRING(cte_name) the place cte_name is the title of a previous frequent desk expression"
)
AS (
TO_HEX(MD5(row_json))
);
Nice! Now within the console it seems to be like this:

Now we are able to name the operate like this:
SELECT flowfunctions.hash.hex_md5_row_hash(row_json STRING)
Or mirroring the syntax of the earlier question:
WITH
inbound_zoo_elephants AS (
SELECT *
FROM flowfunctions.examples.zoo_elephants
)SELECT *,
flowfunctions.hash.hex_md5_row_hash(inbound_zoo_elephants) AS hex_row_hash
FROM inbound_zoo_elephants
Which is arguably extra verbose than the earlier code, so you may very well simply need to use the earlier model, eliminating pointless (on this case) operate dependencies:
TO_HEX(MD5(TO_JSON_STRING(inbound_zoo_elephants))) AS hex_row_hash
Both means, to realize our goal of definitively proving that there are not any duplicates in our dataset we want yet one more step within the question to check the general row rely with the distinctive row rely:
WITH
inbound_zoo_elephants AS (
SELECT *
FROM flowfunctions.examples.zoo_elephants
),add_row_hash AS (
SELECT *,
TO_HEX(MD5(TO_JSON_STRING(inbound_zoo_elephants))) AS hex_row_hash
FROM inbound_zoo_elephants
)SELECT
COUNT(*) AS information,
COUNT(DISTINCT hex_row_hash) AS unique_records
FROM add_row_hash
Which returns:

For the reason that values for information match the unique_records, we are able to conclude that every row is certainly distinctive. Nice, we are able to keep on with our evaluation with out worrying about duplicates and their influence.
Really, given the aforementioned crap high quality of my eyesight, I’m going so as to add a pink/inexperienced icon simply so I don’t must do any advanced psychological arithmetic:
WITH
inbound_zoo_elephants AS (
SELECT *
FROM flowfunctions.examples.zoo_elephants
),add_row_hash AS (
SELECT *,
TO_HEX(MD5(TO_JSON_STRING(inbound_zoo_elephants))) AS hex_row_hash
FROM inbound_zoo_elephants
)SELECT
COUNT(*) AS information,
COUNT(DISTINCT hex_row_hash) AS unique_records,
CASE
WHEN COUNT(*) = COUNT(DISTINCT hex_row_hash)
THEN '' ELSE '
'
END AS unique_check_icon
FROM add_row_hash
Phew, now I don’t want to check any numbers in my head, a inexperienced gentle lets me know issues are all good:
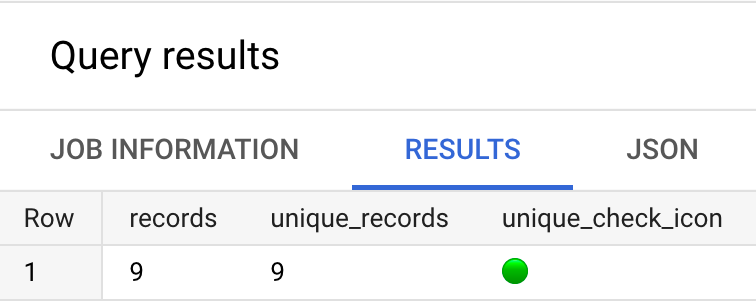
Whist utilizing this sort of method is clearly a bit of pointless on such a easy instance, really it does assist to shortly establish potential discrepancies and points in additional advanced queries.
The flexibility to verify column matches or similarity throughout a extra vital variety of rows in a fast and dependable method, and with out having to depart your BigQuery console workflow is a robust small productiveness enhance. And small productiveness boosts add up…
You is perhaps pondering:
- Wasn’t this text imagined to be a couple of easy row hash, not row duplication testing, opinionated SQL construction assertions, pointless operate improvement or making BigQuery show silly site visitors lights?
- Can’t you obtain the identical factor with a a lot much less code, utilizing DISTINCT and UNIONS and subqueries and stuff?
To which I’d reply:
- Yeah, I do know. Nevertheless this manner of wanting on the downside surfaced just a few adjoining and helpful methods that are worthwhile investigating, as they’ll then be put to make use of in myriad different methods. Additionally, I put this query to you: which kind of journey do you like… a) those the place you arrive instantly at your vacation spot with out distraction, or b) those the place you get to your vacation spot, however uncover a number of new and attention-grabbing locations alongside the best way?
- Yeah, no matter. There are at all times some ways to realize something, in life and code. Some include drawbacks, some with alternatives, however most include each. In actuality you most likely need to know which rows really are duplicates so you’ll be able to flag and/or filter and/or use for information high quality assurance, and this system offers you that functionality. Additionally, you will now have a stable distinctive be part of key, which might act like a (non-enforced) main key. Plus, advanced nested subqueries and peculiar self-join contortions can shortly grow to be unimaginable to learn or intuit, and in line with The Zen of SQL:
TFSQL10.1: Readability counts
It’s a good suggestion to write down clear, modular, sequential code, with the target of creating it not simply useful and environment friendly, however simple to learn and perceive. Nevertheless, I digress:
A Easy Technique to Construct a Distinctive Row Hash in BigQuery:
TO_HEX(MD5(TO_JSON_STRING(input_data)))
And if you happen to want a proof of the way to outlineinput_data, then verify the TO_JSON_STRING() part above.
