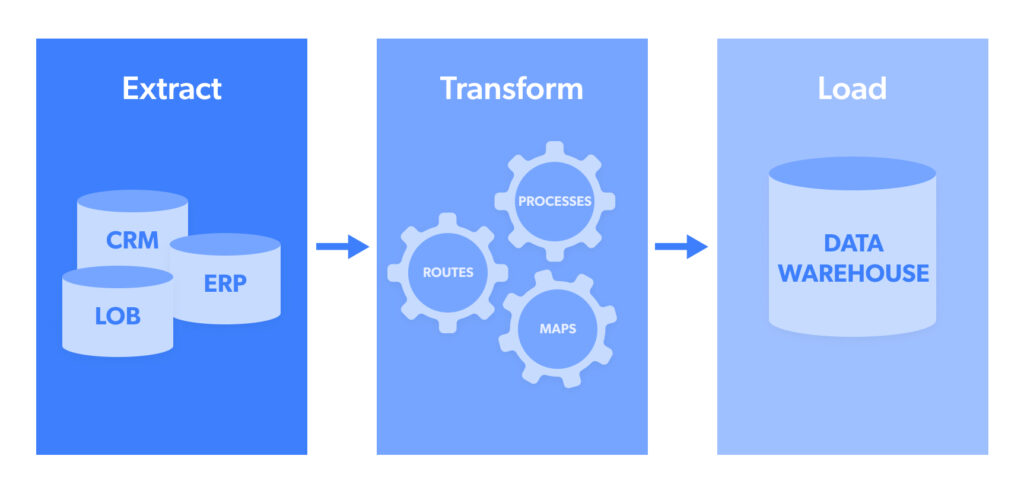
ETL (Extract, Remodel and Load) pipeline course of is an automatic improvement. It takes uncooked information information from a number of sources, extracts info helpful for evaluation, transforms it into file codecs that may serve enterprise analytics or statistical analysis wants, and masses it right into a focused information repository.
ETL pipelines are designed to optimize and streamline information assortment from greater than a supply and cut back the time used to investigate information. They’re additionally designed to transform these information into helpful codecs earlier than transferring them to a focused system for maximal utilization.
Whatever the efficiencies ETL pipelines supply, the entire goal is misplaced in the event that they can’t be constructed rapidly and subtly. This text provides a fast information on the required steps wanted to construct an ETL pipeline course of.
Constructing an ETL Pipeline Course of
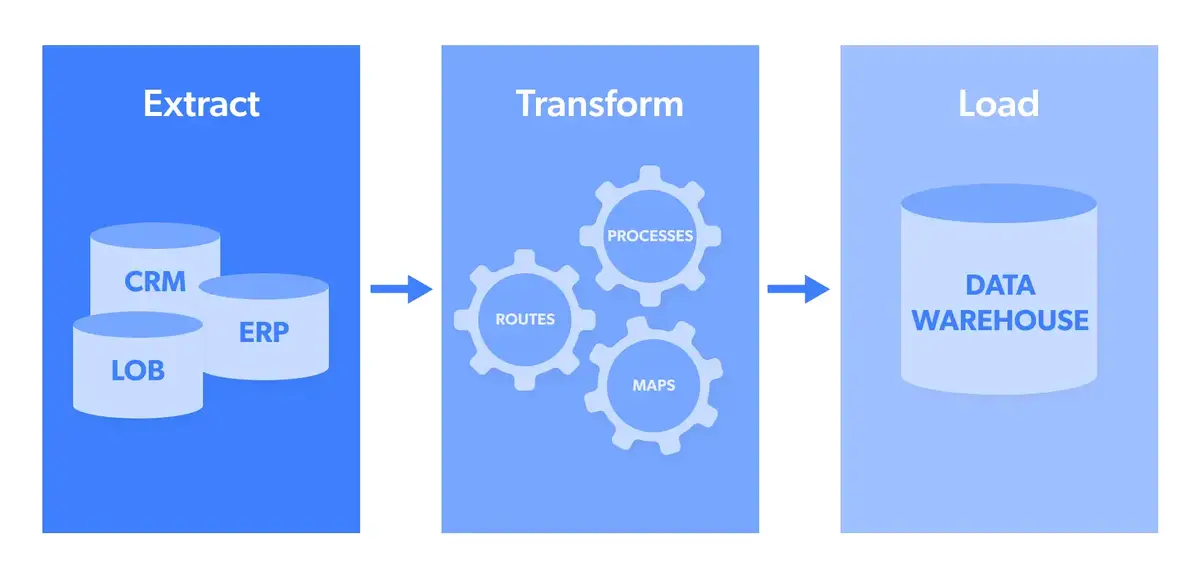
If you construct an ETL pipeline, the method should be within the ETL order, i.e.
Extraction is the act of extracting information from an information pool, corresponding to an open-source goal web site.
Transformation is a stage the place extracted information collected in a number of codecs is structured into a novel format after which transferred to a goal system.
Loading is the ultimate stage the place information is uploaded to a database to be analyzed to generate an actionable output.
The ETL pipeline course of is all about information extraction, copying, filtering, remodeling, and loading. However when constructing the method, we should undergo some important particulars, that are as follows:
Create and Copy Reference Knowledge
Having obtainable uncooked information at your disposal can support your huge information sourcing and resolve issues in a shorter time. But when uncooked information will not be obtainable, you’ll have to create a set of knowledge known as your ‘reference information’, together with a set of restricted values that your information might include. For instance, in a geographic information discipline, as you’ll specify the international locations allowed, copy these information as uncooked information to work on whereas conserving the supply/reference information.
Dedicate Particular Connectors and Extract Knowledge from Obtainable Sources
Distinct instruments that set up the connection are required for information extraction from sources. Knowledge will be saved utilizing file codecs like JSON, CSV, XML, API, and many others. To systematize processing appropriately, you could extract all of it from a spread of relational/non-relational database file format sources and convert it to a particular format to achieve the ETL pipeline constructing course of.
Cross-check and Filter Knowledge
Maintain related information and discard information that exceeds the required information vary. Analyze rejected information to determine causes for rejection and make needed changes to supply information. For instance, when you want information from the previous 12 months and reject information older than 12 months to validate information, filter information by extracting off inaccurate information and null columns, and many others.
Knowledge Transformation
Knowledge transformation is probably the most essential a part of the ETL pipeline course of, particularly when it isn’t automated. The transformation course of entails translating information into the specified type in keeping with particular person information use. Knowledge should be cleansed of duplicates, checked for integrity of knowledge requirements, aggregated information, and made prepared to be used. Additionally, features will be programmed to facilitate automation throughout information transformation.
Stage and Retailer the Remodeled Knowledge
Although It’s not really helpful to load reworked information into goal methods straight for storage or use, as a substitute, take the required step of knowledge staging. The staging stage is the place information diagnostics experiences are generated, and information is enabled for simple information recall in case of any havoc or malfunction. When that information is prepared, it may be transferred to a goal database.
Sequential Knowledge Scheduling
Scheduling is the ultimate stage of the ETL pipeline constructing course of. For efficient automation, it’s essential to schedule the information sequentially to load month-to-month, weekly, each day, or any customized time vary. The info loading schedules can embody a sequential time stamp to find out the load date rapidly for document functions. For environment friendly activity automation, scheduling ought to be accomplished to keep away from efficiency and reminiscence points.
Conclusion
In constructing an efficient ETL pipeline course of, there may be a couple of technique (batch processing and real-time stream processing) and information integration software program that can be utilized. Whichever technique you select, constructing the ETL pipeline course of within the above-listed order is the best way to ensure a profitable operation.

{kind=link}