To construct higher GPT-3-powered chatbots
As highly effective language fashions turn into more and more prevalent, the necessity for management over the content material they generate turns into ever extra urgent. These fashions, educated on huge quantities of textual content knowledge, have the flexibility to generate extremely convincing written content material, from information articles to social media posts. Nonetheless, with out correct oversight, they’ll additionally produce misinformation or numerous sorts of dangerous content material. It’s thus essential that apps utilizing these language fashions try to examine the veracity of the data generated by these AI techniques, with the intention to forestall the unfold of false, deceptive or dangerous data.
Like many others, in all probability together with your self since you’re studying this, I’ve used GPT-3 and ChatGPT fairly a bit, and in doing so I’ve recognized that fairly often they reply to questions very convincingly but incorrectly. Certainly, I explored this fairly deeply when GPT-3 was launched, within the type of examinations identical to these I’d take to a pupil in a science topic:
Lately, and thoroughly as a result of I used to be conscious of those limitations, I eagerly began creating my very own chatbots powered by GPT-3. First by patching some PHP libraries and writing the corresponding JavaScript code, and extra not too long ago purely in JavaScript:
Engaged on that final challenge, i.e. calling GPT-3 from pure JavaScript, I explored extra of OpenAI’s reference for the GPT-3 API, and located that one can very simply retrieve a sequence of scores related to every token produced by the language mannequin. It turns these scores are literally chances in logarithmic kind, delivered by GPT-3 token by token along with the textual content prediction. These chances measure the “likelihood” of the totally different tokens that GPT-3 produced. Whereas these chances might doubtlessly comprise details about how certain GPT-3 is in regards to the content material produced, this isn’t given. Subsequently I set myself to review this right here hands-on via a sequence of recent JavaScript apps you can construct upon.
Extra particularly, right here I’ll discover the way to retrieve these token chances and what values they take for texts that I do know are both appropriate or mistaken. I will even probe the impact of few-shot studying on these scores, to know if it really makes GPT-3 extra sure about its solutions or not.
If you’re studying this, GPT-3 wants no presentation. However in case, suffice to say that GPT-3 stands for Generative Pre-trained Transformer (now in model 3 however really consisting in numerous totally different fashions every at totally different model) and that it’s a state-of-the-art language mannequin that generates written content material given an enter.
While you feed some textual content into GPT-3 (known as a “immediate”) it’s break up into so-called tokens, that are items of variable measurement starting from single letters to syllables and even phrases (relying on numerous issues). The tokens are propagated via the community, which in consequence synthesizes new tokens that collectively kind new phrases, sentences, and paragraphs. These texts often have that means and fairly good grammatic, until you’re coping with an unique language that GPT-3 hasn’t seen a lot upon coaching. Nonetheless, they don’t seem to be essentially correct of their content material, particularly should you anticipate it to “assume” about an issue or make relationships between ideas, or should you ask about issues that the mannequin hasn’t seen throughout coaching (for instance it gained’t know who I’m, so it’ll in all probability make one thing up, see instance in a while).
One vital function of GPT-3 and different giant language fashions is that they’re “few-shot learners” which implies they’ll course of and “perceive” some data handed on in a immediate, after which might reply a query or execute a process primarily based on this data. There an entire preprint explaining this within the arXiv; and I’ve a number of instance tasks the place I exploit this function:
Now, the function of GPT-3 that I’m touching upon right here (and that isn’t a lot mentioned on the web, regardless of its big significance) is that apart from returning textual content, GPT-3 can return a likelihood related to every token that composes the created textual content. These chances, really returned in logarithmic kind, measure how seemingly every token is to happen within the context of the output textual content. Decrease log chances point out much less seemingly phrases and better log chances point out extra seemingly phrases.
In line with ChatGPT itself, GPT-3 makes use of these log chances to generate textual content that’s coherent and grammatically appropriate; apart from, it makes use of the log chances to generate the subsequent phrase primarily based on the more than likely phrase that may come subsequent, permitting it to generate contextually correct textual content. What I’ll examine right here is whether or not this additionally accommodates details about the accuracy of the content material. Spoiler alert: sure, a minimum of a bit; and furthermore, few-shot studying not solely improves the solutions themselves but additionally improves log chances.
Retrieving log chances upon calling GPT-3’s API
It is very important be aware that GPT-3, like different language fashions, just isn’t capable of inform the distinction between true and false data. It merely generates textual content primarily based on the patterns it has realized from the info it was educated on and what’s fed within the immediate for few-shot studying.
Token log chances can in precept assist detect incorrect data; however, how will we get them?
Right here’s a slight modification of the code I introduced not too long ago to name GPT-3’s API completely from JavaScript, amended to get the token log chances as effectively:
// Your OpenAI API key
const apiKey = “(your API key right here)”;fetch(
`https://api.openai.com/v1/completions`,
{
physique: JSON.stringify({
“mannequin”: “text-davinci-003”,
“immediate”: “The place is Luciano Abriata from?”,
“temperature”: 0,
“max_tokens”: 20,
“logprobs”: 1}), //Observe we request for logprobs
methodology: “POST”,
headers: {
“content-type”: “software/json”,
Authorization: “Bearer ” + apiKey,
},
}
).then((response) => {
if (response.okay) {
response.json().then((json) => {
console.log(json);
});
}
});
The fetch() name consists of every thing that’s wanted to name GPT-3 and get texts and token chances. And the immediate consists of data for few-shot studying, positioned earlier than the query “The place is Luciano Abriata from?”
Let’s see what occurs if we name the above perform with a immediate that solely consists of the query “The place is Luciano Abriata from?”, that’s, with none aiding data that explains I’m from Argentina.
We anticipate GPT-3 is not going to know the place I’m from, as I’m not a star. And certainly, it “makes up” that I’m from Italy:
(Enjoyable truth: it’s not a lot off, as a result of my ancestors have been all Italian… right here, GPT-3 seemingly made a guess primarily based on my title… however no, I used to be born and grew up in Argentina.)
Now, what will we see within the console log? A lot of fascinating outputs, apart from the output textual content itself. Let’s analyze a very powerful components:
First, you see the article textual content which incorporates the output: Luciano Abriata is from Italy.
However then a number of strains above textual content, you see an array containing the tokens that make up that textual content. And some strains above this, you’ve token_logprobs, an array of the identical measurement that lists the log chances for every token.
You possibly can see that token_logprobs reaches a minimal of -0.49 at token 9, “Italy”, whereas all different tokens are very near 0 (besides these on the finish that are additionally adverse, however we don’t care about these closing tokens).
That is in precept excellent news, as a result of it implies that GPT-3 is offering a clue that this piece of data is perhaps mistaken, or “made up”. Let’s no rush to attract any conclusions but, although, and let’s discover this additional.
What if we offer some data within the immediate, after which ask about it? One thing like this:
Luciano Abriata is a scientist born in Argentina, now working in Switzerland. He works on structural biology, digital actuality, NMR, scientific writing, programming, and many others. The place is Luciano Abriata from?
// Your OpenAI API key
const apiKey = “(your API key right here)”;fetch(
`https://api.openai.com/v1/completions`,
{
physique: JSON.stringify({
“mannequin”: “text-davinci-003”,
“immediate”: “Luciano Abriata is a scientist from Argentina, now working
in Switzerland. He works on structural biology, digital
actuality for chemistry, NMR, and many others.
The place is Luciano Abriata from?”,
“temperature”: 0,
“max_tokens”: 20,
“logprobs”: 1}), //Observe we request for logprobs
methodology: “POST”,
headers: {
“content-type”: “software/json”,
Authorization: “Bearer ” + apiKey,
},
}
).then((response) => {
if (response.okay) {
response.json().then((json) => {
console.log(json);
});
}
});
On this case, GPT-3 not solely replies accurately saying that I’m from Argentina, but it surely additionally says this confidently: “Argentina”, once more in token 9, has a log likelihood very near 0:
Extra thorough checks by representing token chances as colours on the produced textual content
To check the ability of log chances in flagging doubtlessly incorrect data, I wrote this straightforward net app (hyperlink close to the tip) that processes a immediate with GPT-3 and shows the produced textual content coloured at every token by its log likelihood:
On this app, which you’ll strive in a hyperlink I present under, coloration keys for every token are injected by way of HTML’s <font> tag as follows:
- log prob. > -0.1 → inexperienced
- -0.3 > log prob. > -0.1 → yellow
- -0.5 > log prob. > -0.3 → orange
- log prob. < -0.5 → pink
Let’s analyze this a bit: the query is about an individual that I made up, and about whom GPT-3 replies moderately than saying it doesn’t know, though temperature is 0 so it’s not anticipated to make up stuff… Clearly, one can’t depend on the temperature parameter as a technique to forestall the technology of faux data.
Now, discover that of the 4 most vital options invented for this fictional character (he’s Italian, a thinker and professor of philosophy, and on the College of Rome La Sapienza) some are flagged strongly:
“thinker and professor of philosophy” averages a log likelihood of round -1, and “Rome La” of round -1.5.
In the meantime, “Sapienza” in all probability stays unflagged, i.e. with excessive log likelihood, as a result of it’s a excellent continuation for “College of Rome La”. Likewise, “Italian” in all probability stays excessive as a result of it comes quickly after “Giulio”, which is a really Italian title.
Thus, it looks as if a low log likelihood is indicative of probably inaccurate data, however a excessive worth doesn’t guarantee factual accuracy.
It looks as if a low log likelihood is indicative of probably inaccurate data, however a excessive worth doesn’t guarantee factual accuracy.
Let’s now strive altering “Giulio” by “John”, i.e. asking “Who’s John Caranchani?”:
This time it made up that the character is Italian-American, and has flagged this data with a fairly dangerous rating.
Yet one more check, utilizing the sometimes French title “Philippe”:
It now makes up that the character is French, and flags this in orange.
Let’s now ask about one thing totally different: chemistry. What’s the molecular components of acetic acid?
We get an accurate reply, and all in inexperienced indicating superb scores.
What if we make up a molecule? Bizarric acid, as an illustration:
Seems prefer it does “notice” that it’s making up stuff. In fact, we’d moderately favor that GPT-3 replied “I don’t know” or “Bizarric acid doesn’t exist”. However a really dangerous rating is healthier than nothing.
Impact of passing data for few-shot studying
As mentioned earlier and in quite a few articles in all places, GPT-3 can extract data from items of textual content handed for few-shot studying, and thus reply to questions extra precisely -at least in keeping with the handed data.
How is it mirrored within the token chances?
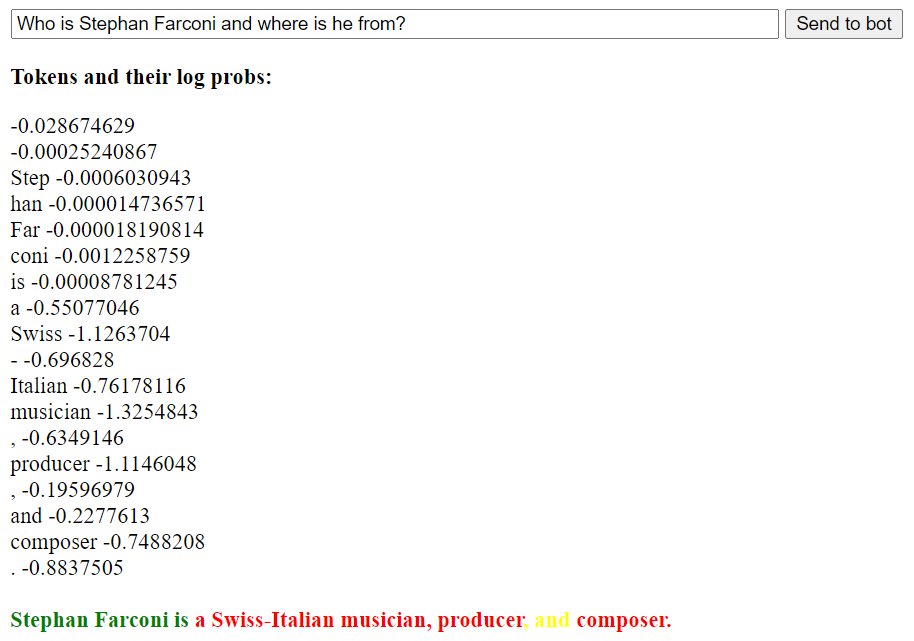
Let’s see an instance. I made up an individual known as Stephan Farconi, and need to know the place he’s from and what he does:
As anticipated, every thing was made up and flagged with dangerous scores.
Now let’s give GPT-3 some details about this particular person, and let’s ask once more:
The reply is now factually in step with the data handed, and GPT-3 flags part of it (“Greece”) as sure. Nonetheless, it’s not certain about “pc scientist”. Observe that “scientist” is an efficient continuation for “pc”, so in my interpretation GPT-3 is definitely “not sure” about the entire “pc scientist” idea.
Need to do that app?
Right here it’s:
https://lucianoabriata.altervista.org/checks/gpt-3/js-only/GPT3-JSonly-logprobs-color.html
Simply paste your OpenAI API key for GPT-3, enter a query or immediate and click on “Ship to bot”.
Please share your leads to the feedback! Did the token chances replicate the precise accuracy of the produced textual content?
Using GPT-3 and related language fashions in chatbot functions can current a big problem by way of producing correct and dependable data. Whereas new strategies will hopefully enhance on veracity, for the second an possibility is to make the most of token chances to measure the “certainty” that GPT-3 has on every token that constitutes its output. I confirmed you that utilizing this data it’s attainable to approximate the extent of confidence that GPT-3 has in its generated textual content -but it’s not solely protected.
From the few examples examined it seems to be like excessive scores all through all tokens are indicative of correct data, however low scores at some tokens don’t essentially suggest that the data is wrong. In fact, that is solely anecdotal proof, and a a lot bigger examine is required to judge this critically. This may very well be an fascinating challenge {that a} group doing analysis on AI might perform comparatively straightforward -just needing a adequate variety of individuals interacting with the system by asking questions and evaluating the solutions. (And be aware, as an additional caveat, that I selected my thresholds for interpretation of log chances considerably arbitrarily.)
I additionally confirmed you that few-shot studying helps to enhance not solely the accuracy of the solutions, particularly for questions that GPT-3 doesn’t “know” about, but additionally their reliability as measured by the token chances. Nonetheless, additionally right here we see that offering data via few-shot studying doesn’t assure excessive scores within the replies, even when the data in these solutions is appropriate.
Total, token chances look promising however, even with no full analysis, it’s clear that they’re fallible. Subsequently, it’s essential to make use of GPT-3 fastidiously, probably using token chances to enhance outputs however with out inserting undue belief in them.

{kind=link}