Palms-on information to implement and validate self-training utilizing Python
Semi-Supervised Studying is an actively researched area within the machine studying neighborhood. It’s sometimes utilized in enhancing the generalizability of a supervised studying downside (i.e. coaching a mannequin primarily based on offered enter and ground-truth or precise output worth per remark) by leveraging excessive volumes of unlabeled knowledge (i.e. observations for which inputs or options can be found however a floor fact or precise output worth will not be identified). That is often an efficient technique in conditions the place availability of labeled knowledge is proscribed.
Semi-Supervised Studying may be carried out by means of a wide range of methods. A type of methods is self-training. You’ll be able to confer with Half-1 for particulars on the way it works. In a nutshell, it acts as a wrapper which may be built-in on prime of any predictive algorithm (that has the aptitude to generate an output rating through a predict operate). The unlabeled observations are predicted by the unique supervised mannequin and probably the most assured predictions by the mannequin are fed again for re-training the supervised mannequin. This iterative course of is anticipated to enhance the supervised mannequin.
To get began, we are going to arrange a few experiments to create and examine baseline fashions which is able to use self-training on prime of standard ML algorithms.
Experiment setup
Whereas semi-supervised studying is feasible for all types of knowledge, textual content and unstructured knowledge are probably the most time-consuming and costly to label. A number of examples embrace classifying emails for intent, predicting abuse or malpractice in e mail conversations, classifying lengthy paperwork with out availability of many labels. The upper the variety of distinctive labels anticipated, the tougher it will get to work with restricted labeled knowledge. Therefore, we take the next 2 datasets (in rising order of complexity from a classification perspective):
IMDB critiques knowledge: Hosted by Stanford, this can be a sentiment (binary- constructive and detrimental) classification dataset of film critiques. Please refer right here for extra particulars.
20Newsgroup dataset: It is a multi-class classification dataset the place each remark is a information article and it’s labeled with one information matter (politics, sports activities, faith and so forth). This knowledge is offered by means of the open supply library scikit-learn too. Additional particulars on this dataset may be learn right here.
A number of experiments are performed utilizing these 2 datasets at totally different volumes of labeled observations to get a generalized efficiency estimate. In direction of the top of the publish, a comparability is offered to research and reply the next questions:
- Does self-training work successfully and constantly on each algorithms?
- Is self-training appropriate for each binary and multi-class classification issues?
- Does self-training proceed so as to add worth as we add extra labeled knowledge?
- Does including greater volumes of unlabeled knowledge proceed to enhance mannequin efficiency?
Each datasets may be downloaded from their respective sources offered above or from Google Drive. All of the codes may be referenced from GitHub. Every thing has been carried out utilizing Python 3.7 on Google Colab and Google Colab Professional.
To guage how every algorithm would do on the 2 datasets, we take a number of samples of labeled knowledge (low quantity to excessive quantity of labeled knowledge) and apply self-training accordingly.
Understanding the enter
Newsgroup coaching dataset offers 11,314 observations unfold throughout 20 classes. We create a labeled take a look at dataset of 25% (~2800 observations) from this and randomly break up the remaining into labeled (~4,200 observations are thought-about with their newsgroup label) and unlabeled observations (~4,300 observations are thought-about with out their information group label). Inside every experiment, a portion of this labeled knowledge is taken into account (ranging from 20% and going upto 100% of labeled coaching quantity) to see whether or not improve within the quantity of labeled observations in coaching results in efficiency saturation (for self-training) or not.
For the IMDB dataset, two coaching batches are thought-about: (1) utilizing 2,000 unlabeled observations and (2) 5,000 unlabeled observations. Labeled observations used are 20, 100, 400, 1000, 2000. Once more, the speculation stays that improve in variety of labeled observations, would scale back the efficiency hole between a supervised learner and a semi-supervised learner.
Implementing the ideas of self-training and pseudo labelling
Every supervised algorithm is run on the IMDB film evaluation sentiment dataset, and the 20NEWSGROUP datasets. For each datasets, we’re modeling for a classification downside (binary classification within the former case and multi-class within the latter case). Each algorithm is examined for efficiency at 5 totally different ranges of labeled knowledge starting from very low (20 or so labeled samples per class) to excessive (1000+ labeled samples per class).
On this article, we are going to carry out self-training on a few algorithms — logistic regression ( by means of sklearn’s implementation of sgd classifer utilizing a log loss goal) and vanilla neural community (by means of sklearn’s implementation of mulit-layer perceptron module).
We’ve already mentioned that self-training is a wrapper technique. That is made obtainable straight from sklearn for sklearn’s mannequin.match() strategies and comes as a part of the sklearn.semi_supervised module. For non-sklearn strategies, we first create the wrapper after which move it over to pytorch or Tensorflow fashions. Extra on that in later.
Let’s begin by studying the datasets:
Let’s additionally create a easy pipeline to name the supervised sgd classifier and the SelfTrainingClassifier utilizing sgd as the bottom algorithm.
Tf-Idf — logit classification
The above code is fairly easy to know, however lets rapidly break it down:
- First, we import the required libraries and use a couple of hyperparameters to arrange logistic regression (regularization alpha, regularization kind being ridge, and a loss operate which is log loss on this case).
- Subsequent, we offer count-vectorizer parameters the place n_grams are fabricated from minimal 1 phrase and most 2 tokens. Ngrams, that seem in lower than 5 paperwork OR in over 80% of corpus, should not thought-about. A tf-idf transformer takes the rely vectorizer output and creates a tf-idf matrix of the textual content per document-word as options for the mannequin. You’ll be able to learn extra about rely vectorizer and tf-idf vectorizer right here and right here respectively.
- Then, we outline an empty DataFrame (df_sgd_ng on this case) that shops all efficiency metrics and knowledge on labeled and unlabeled volumes used.
- Subsequent, in n_list, we outline 5 ranges to outline what % of coaching knowledge is handed as labeled (from 10% in increment of 10% as much as 50%). Equally, we outline two parameter lists to iterate on (kbest and threshold). Normally, coaching algorithms present likelihood estimates per remark. Observations the place the estimate is above a threshold, are thought-about by SelfTraining in that iteration to be handed to the coaching technique as pseudo labels. If a threshold is unavailable, kbest can be utilized to counsel that prime N observations primarily based on their values must be thought-about for passing as pseudo labels.
- The same old train-test break up is adopted subsequent. Put up this, utilizing a masking vector, coaching knowledge is constructed by first protecting 50% of knowledge as unlabeled and throughout the remaining 50% knowledge, utilizing n_list, labeled quantity is taken into account in increments (i.e. 1/fifth of complete labeled knowledge is added incrementally in every subsequent run until all of labeled knowledge is used). The identical labeled coaching knowledge is every time used independently for normal supervised studying as effectively.
To coach the classifier, a easy pipeline is constructed: Beginning with (1) rely vectorizer to create tokens adopted by (2) TfIdf transformer to transform tokens into significant options utilizing the term_freq*Inverse_doc_freq calculation. That is then adopted by (3) becoming a Classifier to the TfIdf matrix of values.

Every thing else remaining the identical, the pipeline for self-training is created and known as the place as a substitute of becoming a classifier straight, it’s wrapped into SelfTrainingClassifier() as follows:

Lastly, for every kind of classifier, the outcomes are evaluated on take a look at dataset through a operate name to eval_and_print_metrics_df()

The next picture reveals how the console output seems like when operating supervised classification adopted by self-trained classification:

Tf-Idf — MLP classification
The self-training for MLP classifier (i.e. a vanilla feed ahead neural community) is finished in precisely the identical method with the one variations developing within the classifier’s hyperparameters and its name.
Be aware: MLP from scikit-learn implementation is a non-GPU implementation and thus giant datasets with very dense layers or deep networks might be very gradual to coach. The above is an easier setup (2 hidden layers with 100 and 50 neurons and max_iter=25) to check the generalizability of self-training. In Half-3, we might be implementing all of self coaching primarily based on ANNs, CNNs, RNNs and transformers utilizing GPU assist on Google Colab Professional leveraging Tensorflow and Pytorch.
For MLP, the primary console output has been offered under:

The above console output implies that upon operating a supervised classifier first, the mannequin was fitted on 10% of coaching knowledge (as labeled). The efficiency on take a look at knowledge for such a classifier is 0.65 of Micro-F1 and 0.649 of accuracy. Upon beginning self coaching with 4,307 unlabeled samples along with present labeled volumes, pseudo labels of unlabeled observations might be pushed for subsequent iteration of coaching solely if their output likelihood for anybody class is at the very least as excessive as the edge (0.4 on this case). In first iteration, 3,708 pseudo labels are added to 869 labeled observations for a 2nd coaching of the classifier. On subsequent predictions, one other 497 pseudo labels are added and so forth until no extra pseudo labels may be added.
To make comparability metrics constant, we create a easy utility right here. This takes the coaching and take a look at dataset together with the fitted classifier (which modifications primarily based on whether or not we’re utilizing supervised studying or semi-supervised studying in that analysis step) and in case of semi-supervised studying, whether or not we’re utilizing threshold or kbest (when direct likelihood outputs should not doable like with Naive Bayes or SVM). This operate creates a dictionary of efficiency (micro-averaged F1 and accuracy) at totally different ranges of labeled and unlabeled quantity alongside data on threshold or kbest, if used. This dictionary is appended into the general efficiency DataFrame (like df_mlp_ng and df_sgd_ng proven in earlier Github gists).
Lastly, lets see the complete size comparability outputs and understand what we’ve discovered to date when totally different volumes of labeled observations are thought-about with self-training at totally different thresholds.

The desk above for logistic regression may be defined as follows:
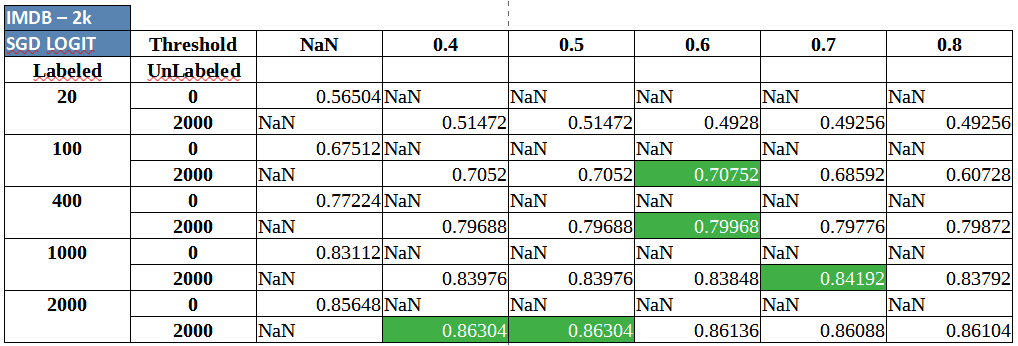
We begin with 5 sizes of labeled dataset (869, 1695 and so forth until 4178). Utilizing every iteration of labeled knowledge, we prepare a supervised classifier mannequin first and doc the mannequin efficiency on take a look at knowledge (Accuracy numbers with Threshold column = NaN). Throughout the identical iteration, we observe up with including 4,307 samples of unlabeled knowledge. The pseudo labels generated are selectively handed into the supervised classifier however provided that they exceed the pre-decided likelihood threshold. In our experiments, we labored with 5 equally spaced thresholds (0.4 to 0.8, with step dimension of 0.1). The accuracies for respective threshold primarily based self-training is mirrored per labeled quantity iteration. Typically, it may be seen that utilizing unlabeled knowledge results in a efficiency enchancment (however, basically, as labeled quantity will increase, the enhance from self-training, and basically from different semi-supervised strategies additionally, saturates).
The next desk offers a comparability utilizing a MLP:

Related tables are produced under for the IMDB sentiment classification dataset. The code proceed to be in the identical pocket book and may be accessed right here.
IMDB evaluation sentiment classification utilizing Semi-Supervised Logistic Regression:

IMDB evaluation sentiment classification utilizing Semi-Supervised MLP/ Neural Community:


Two key and constant insights that may must be clearly noticed are:
- Self-training, nearly all the time, appears to supply a small and diverse, however particular enhance at totally different volumes of labeled knowledge.
- Including extra unlabeled knowledge (2,000 vs. 5,000 unlabeled observations) appears to supply delta enchancment in efficiency constantly.
Lots of the outcomes, throughout datasets and algorithms above, spotlight one thing barely odd as effectively. Whereas there’s a efficiency enhance in most conditions the place self coaching is concerned, the outcomes that generally including labels at mid-low confidence pseudo labels (likelihood round 0.4 to 0.6) together with excessive confidence labels results in a greater classifier total. For mid-high thresholds, it is smart as a result of utilizing very excessive thresholds would mainly suggest working with one thing near supervised studying however success with low thresholds goes in opposition to regular heuristics and our instinct. On this case, it may be attributed to 3 reasons- (1) The possibilities should not effectively calibrated and (2) the dataset has less complicated cues within the unlabeled knowledge that are getting picked up within the preliminary set of pseudo labels even at decrease confidence ranges (3) the bottom estimator itself will not be sturdy sufficient and must be tuned to a robust extent. Self-training must be utilized on prime of a barely tuned classifier.
So, there you might have it! Your very first set of self coaching pipelines that may leverage unlabeled knowledge and a starter code to generate a easy comparative examine on how a lot quantity of labeled knowledge and what threshold for pseudo labels may enhance mannequin efficiency considerably. There may be nonetheless loads left on this train – (1) calibrating possibilities earlier than passing them to self-training, (2) enjoying with totally different folds of labeled and unlabeled datasets to have a extra strong comparability. This could hopefully function place to begin when engaged on self-training.
All of the codes used on this publish may be accessed from GitHub.
Sneak peak into SOTA utilizing GANs and Again-Translation
Lately, researchers have began leveraging knowledge augmentation to enhance semi-supervised studying by means of use of GANs, and BackTranslation. We want to perceive these higher and examine such algorithms in opposition to self-training employed on neural networks and transformers by means of the usage of CNNs, RNNs, and BERT. The latest SOTA methods for semi-supervised studying have been MixText and Unsupervised Information Augmentation for Consistency Coaching which might even be subjects touched upon in Half-3.
Thanks for studying and see you within the subsequent one!
