Instinct and overview of Energetic Studying terminology and fingers on Uncertainty Sampling calculation.
· Energetic studying is the title used for the method of prioritizing the information which must be labelled as a way to have the best influence to coaching a supervised mannequin.
· Energetic studying is a method through which the educational algorithm can interactively question a consumer (trainer or oracle) to label new information factors with the true labels. The method of energetic studying can be known as optimum experimental design.
· Energetic studying is motivated by the understanding that not all labelled examples are equally vital.
· Energetic Studying is a strategy that may typically vastly cut back the quantity of labeled information required to coach a mannequin. It does this by prioritizing the labeling work for the consultants.
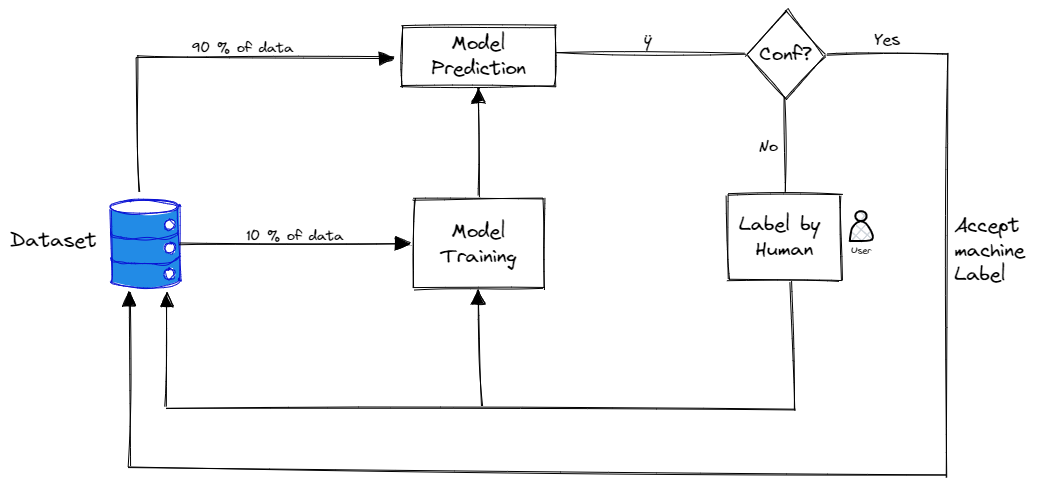
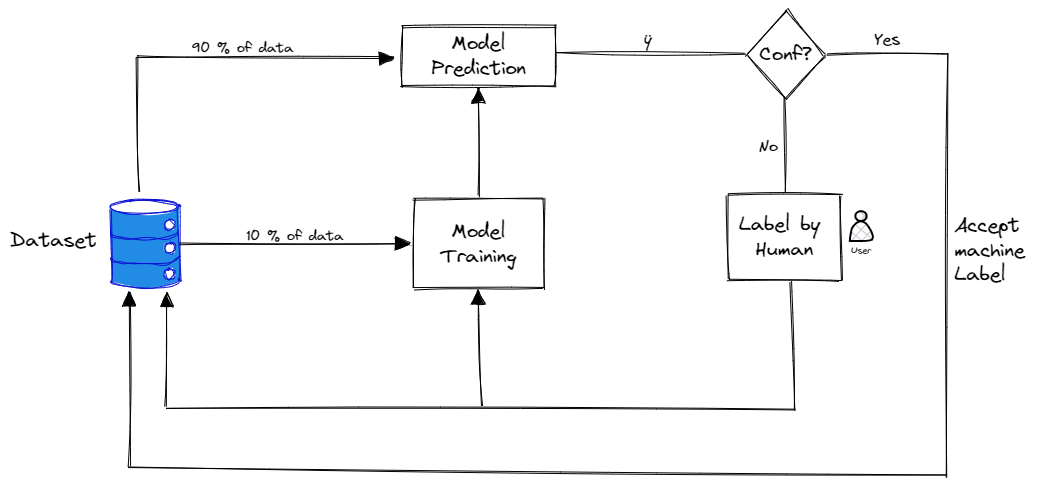
- Energetic Studying Permits to scale back price whereas enhancing accuracy.
- Is an enhancement on high of your current mannequin.
- It’s a technique/algorithm, not a mannequin.
- However will be onerous. “Energetic studying is simple to grasp, not straightforward to execute on”
The important thing thought behind energetic studying is {that a} machine studying algorithm can obtain larger accuracy with fewer coaching labels whether it is allowed to decide on the information from which it learns. — Energetic Studying Literature Survey, Burr Settles
As a substitute of amassing all of the labels for all the information directly, Energetic Studying prioritizes which information the mannequin is most confused about and requests labels for simply these. The mannequin then trains a bit on that small quantity of labeled information, after which once more asks for some extra labels for essentially the most complicated information.
By prioritizing essentially the most complicated examples, the mannequin can focus the consultants on offering essentially the most helpful info. This helps the mannequin be taught sooner, and lets the consultants skip labeling information that wouldn’t be very useful to the mannequin. The result’s that in some instances we will vastly cut back the variety of labels we have to gather from consultants and nonetheless get an important mannequin. This implies money and time financial savings for machine studying initiatives!
Steps for energetic studying
There are a number of approaches studied within the literature on the right way to prioritize information factors when labelling and the right way to iterate over the method. We are going to nonetheless solely current the most typical and simple strategies.
The steps to make use of energetic studying on an unlabeled information set are:
- The very first thing which must occur is {that a} very small subsample of this information must be manually labelled.
- As soon as there’s a small quantity of labelled information, the mannequin must be skilled on it. The mannequin is after all not going to be nice, however will assist us get some perception on which areas of the parameter area should be labelled first to enhance it.
- After the mannequin is skilled, the mannequin is used to foretell the category of every remaining unlabeled information level.
- A rating is chosen on every unlabeled information level primarily based on the prediction of the mannequin. Within the subsequent subsection, we’ll current a few of the attainable scores mostly used.
- As soon as the most effective method has been chosen to prioritize the labelling, this course of will be iteratively repeated: a brand new mannequin will be skilled on a brand new labelled information set, which has been labelled primarily based on the precedence rating. As soon as the brand new mannequin has been skilled on the subset of information, the unlabelled information factors will be run by the mannequin to replace the prioritization scores to proceed labelling. On this approach, one can preserve optimizing the labelling technique because the fashions turn out to be higher and higher.
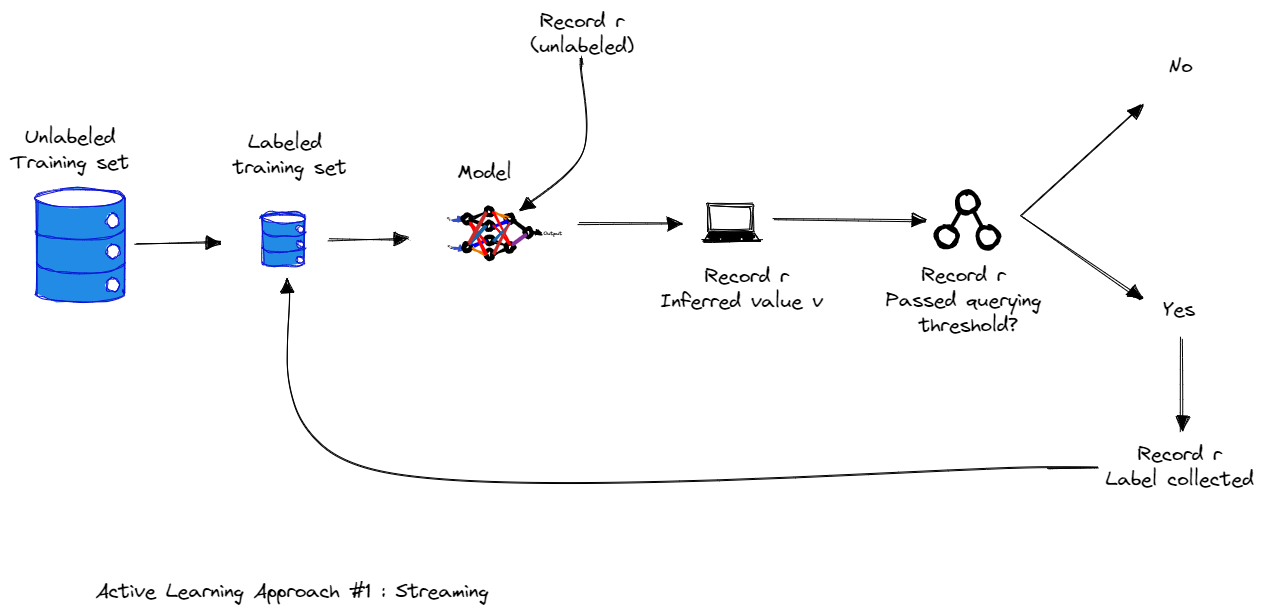
2.1 Energetic Studying Method #1 : Streaming
In stream-based energetic studying, the set of all coaching examples is offered to the algorithm as a stream. Every instance is shipped individually to the algorithm for consideration. The algorithm should make a right away choice on whether or not to label or not label this instance. Chosen coaching examples from this pool are labelled by the oracle, and the label is instantly obtained by the algorithm earlier than the subsequent instance is proven for consideration.
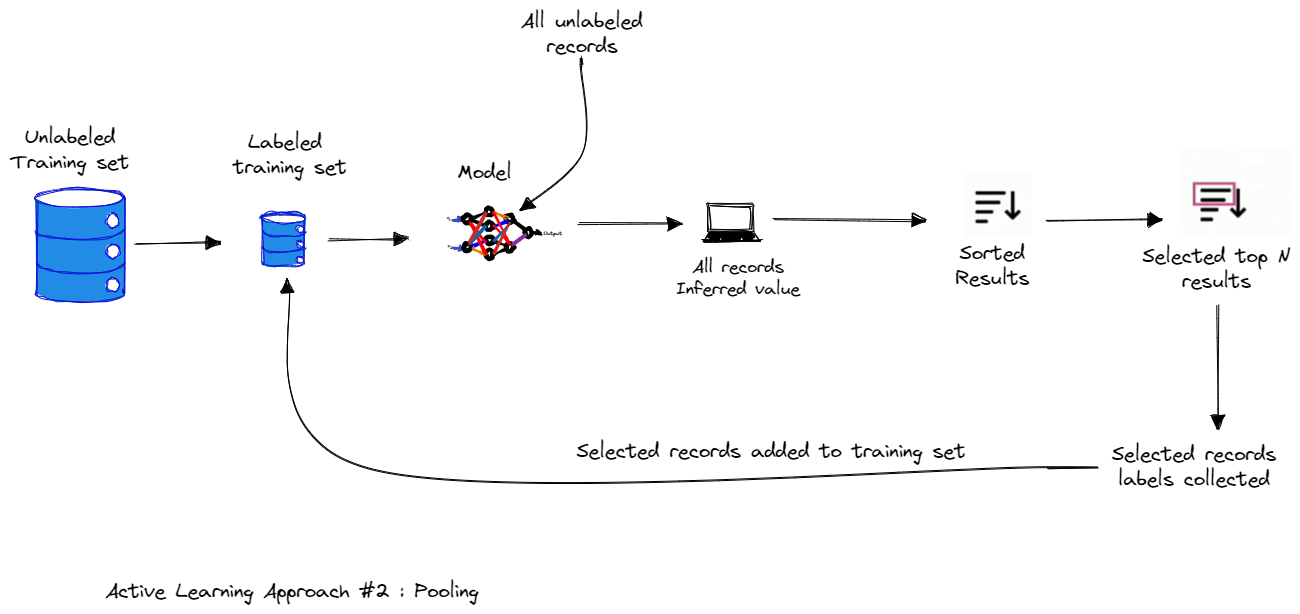
2.2. Energetic Studying Method #2: Pooling
In pool-based sampling, coaching examples are chosen from a big pool of unlabeled information. Chosen coaching examples from this pool are labelled by the oracle.
2.3 Energetic Studying Method #3: Question by Committee
Question by committee in phrases is the usage of a number of fashions as a substitute of 1.
An alternate method, known as Question by Committee, maintains a set of fashions (the committee) and choosing essentially the most “controversial” information level to label subsequent, that’s one the place the fashions disagreed on. Utilizing such a committee could permit us to beat the restricted speculation a single mannequin can specific, although on the onset of a job we nonetheless haven’t any approach of realizing what speculation we must be utilizing.
The method of figuring out essentially the most beneficial examples to label subsequent is known as “sampling technique” or “question technique”. The scoring perform within the sampling course of is known as “acquisition perform”. Knowledge factors with greater scores are anticipated to supply greater worth for mannequin coaching in the event that they get labeled. There are totally different sampling methods resembling Uncertainty Sampling, Variety Sampling, Anticipated Mannequin Change…, On this article we’ll focus solely on the uncertainty measures which is essentially the most used technique.
Uncertainty sampling is a set of methods for figuring out unlabeled gadgets which can be close to a call boundary in your present machine studying mannequin. Though it’s straightforward to establish when a mannequin is assured — there’s one consequence with very excessive confidence — you’ve gotten some ways to calculate uncertainty, and your selection will rely in your use case and what’s the best in your explicit information.
Probably the most informative examples are those that the classifier is the least sure about.
The instinct right here is that the examples for which the mannequin has the least certainty will seemingly be essentially the most troublesome examples — particularly, the examples that lie close to the category boundaries. The training algorithm will achieve essentially the most details about the category boundaries by observing the troublesome examples.
Let’s take a concrete instance, say you are attempting to construct a multi class classification to differentiate between 3 courses Cat, Canine, Horse. The mannequin would possibly give us a prediction like the next:
This output is almost certainly from softmax, which converts the logits to a 0–1 vary of scores utilizing the exponents.
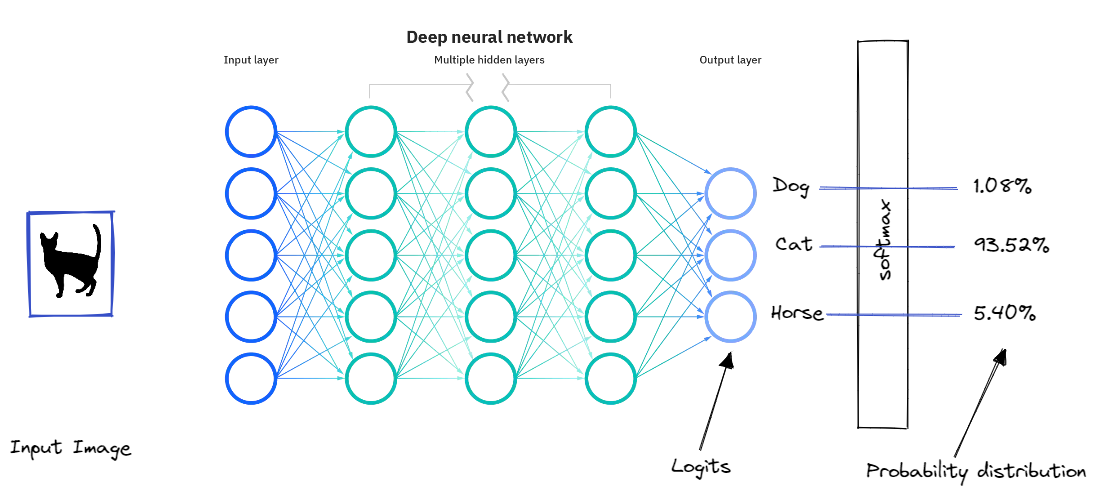
3.1. Least confidence:
Least confidence takes the distinction between 1 (100% confidence) and essentially the most confidently predicted label for every merchandise.
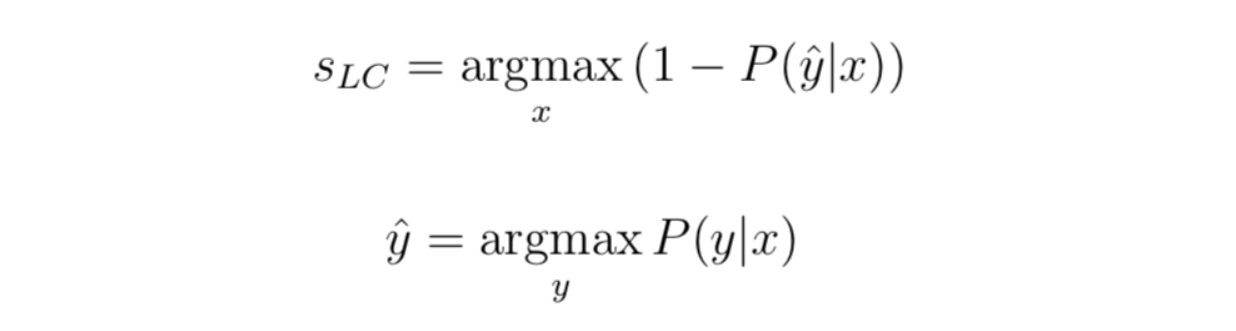
Though you’ll be able to rank order by confidence alone, it may be helpful to transform the uncertainty scores to a 0–1 vary, the place 1 is essentially the most unsure rating. In that case, we have now to normalize the rating. We subtract the worth from 1, multiply the consequence by n/(1-n) with n being the variety of labels. We do that as a result of the minimal confidence can by no means be lower than the one divided by the variety of labels, which is when all labels have the identical predicted confidence.
Let’s apply this to our instance, the uncertainty rating could be :
(1–0.9352) * (3/2) = 0.0972.
Least confidence is the best and most used methodology, it provides you ranked order of predictions the place you’ll pattern gadgets with the bottom confidence for his or her predicted label.
3.2. Margin of confidence sampling
Probably the most intuitive type of uncertainty sampling is the distinction between the 2 most assured predictions. That’s, for the label that the mannequin predicted, how rather more assured was it than for the next-most-confident label? That is outlined as :
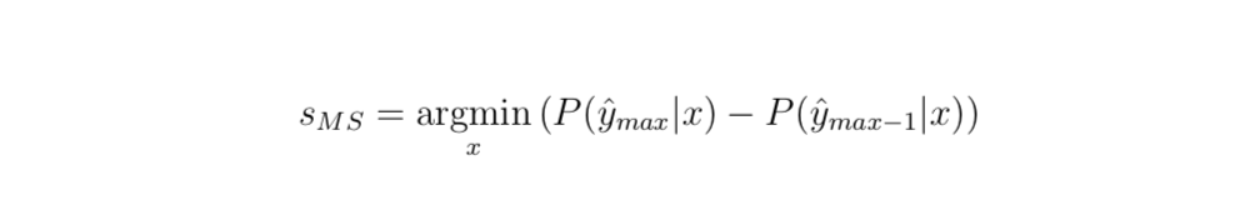
Once more, we will convert this to a 0–1 vary. We’ve got to subtract from 1.0 once more, however the most attainable rating is already 1, so there is no such thing as a must multiply by any issue.
Let’s apply margin of confidence sampling to our instance information. “Cat” and “Horse” are the most-confident and second-most-confident prediction. Utilizing our instance, this uncertainty rating could be 1.0 — (0.9352–0.0540) = 0.1188.
3.3. Ratio sampling
Ratio of confidence is a slight variation on margin of confidence, wanting on the ratio between the highest two scores as a substitute of the distinction.
Now let’s plug in our numbers once more: 0.9352 / 0.0540 = 17.3185.
3.4. Entropy Sampling
Entropy utilized to a chance distribution entails multiplying every chance by its personal log and taking the unfavorable sum:
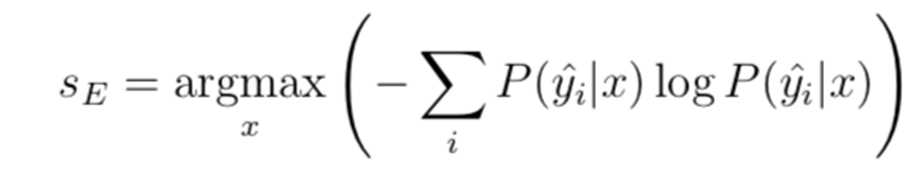
Let’s calculate the entropy on our instance information:
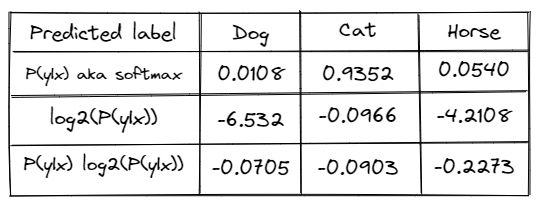
Summing the numbers and negating them returns 0 — SUM(–0.0705, –0.0903, –0.2273) = 0.3881
Dividing by the log of the variety of labels returns 0.3881/ log2(3) = 0.6151
Many of the focus of the machine studying neighborhood is in creating higher algorithms for studying from information. However getting helpful annotated datasets is troublesome. Actually troublesome. It may be costly, time-consuming, and you continue to find yourself with issues like annotations lacking from some classes. Energetic Studying is a good constructing block for this, and is beneath utilized in my view.
[1] https://www.manning.com/books/human-in-the-loop-machine-learning
[2] https://towardsdatascience.com/introduction-to-active-learning-117e0740d7cc
[3] https://www.cs.cmu.edu/~tom/10701_sp11/recitations/Recitation_13.pdf
[4] https://www.youtube.com/watch?v=l6HFdqk480o&characteristic=youtu.be

{kind=link}