
At Stack Overflow, we understand the central role search plays in helping technologists solve their problems, so we’re constantly striving to improve the way you find the information you need. Today, we’re excited to share details about our latest experiment that aims to make your search results in Stack Overflow for Teams Enterprise even more relevant and useful.
As part of our ongoing journey to improve search functionality, which we first launched in January with our Improved Search initiative, we’re introducing an ML-powered reranking system that may refine the order of search outcomes. We all know you need essentially the most related content material on the high of your search outcomes when utilizing our Search Bar, API, or Slack/Microsoft Groups integrations. The truth is, our knowledge reveals that 88% of clicks occur throughout the first 10 outcomes. By way of this experiment, we’ll assist be sure that essentially the most related solutions seem larger up within the search outcomes itemizing so yow will discover one of the best solutions quicker.
As a consumer, you could discover refined however optimistic adjustments in your search expertise:
- Extra related outcomes on the high of the listing
- Improved context-based rating primarily based in your particular question
- Enhanced efficiency of our OverflowAI options, which depend on high search outcomes
This experiment is designed to be non-intrusive, and we’re beginning small to make sure the very best end result for our customers.
Improved Search shouldn’t be a one-time initiative—it is a dedication that requires steady funding in knowledge science, machine studying, and software program engineering. This reranking experiment is simply step one in a sequence of deliberate search relevance enhancements and experiments.
As we roll out this experiment, we need to guarantee you that:
- We’re beginning conservatively with a phased rollout technique.
- We’ll be intently monitoring varied metrics to make sure a optimistic influence.
- Your privateness and knowledge safety stay our high precedence. There will likely be no adjustments to how your knowledge is saved.
We’re excited in regards to the potential enhancements this experiment might convey to your Stack Overflow For Groups Enterprise expertise. Keep tuned for future updates as we proceed to refine and improve our search capabilities.
In the event you’re within the technical facets of our experiment, here is a extra detailed have a look at what’s occurring behind the scenes.
We’re implementing a cross-encoder reranker, particularly the `cross-encoder/ms-marco-MiniLM-L-6-v2` mannequin. This mannequin has been fine-tuned on the MS Marco Passage Rating activity, a large-scale data retrieval corpus constructed from actual consumer queries on Bing. This offers us a stable baseline to work with, because it’s designed to know the nuanced relationships between search queries and potential outcomes.
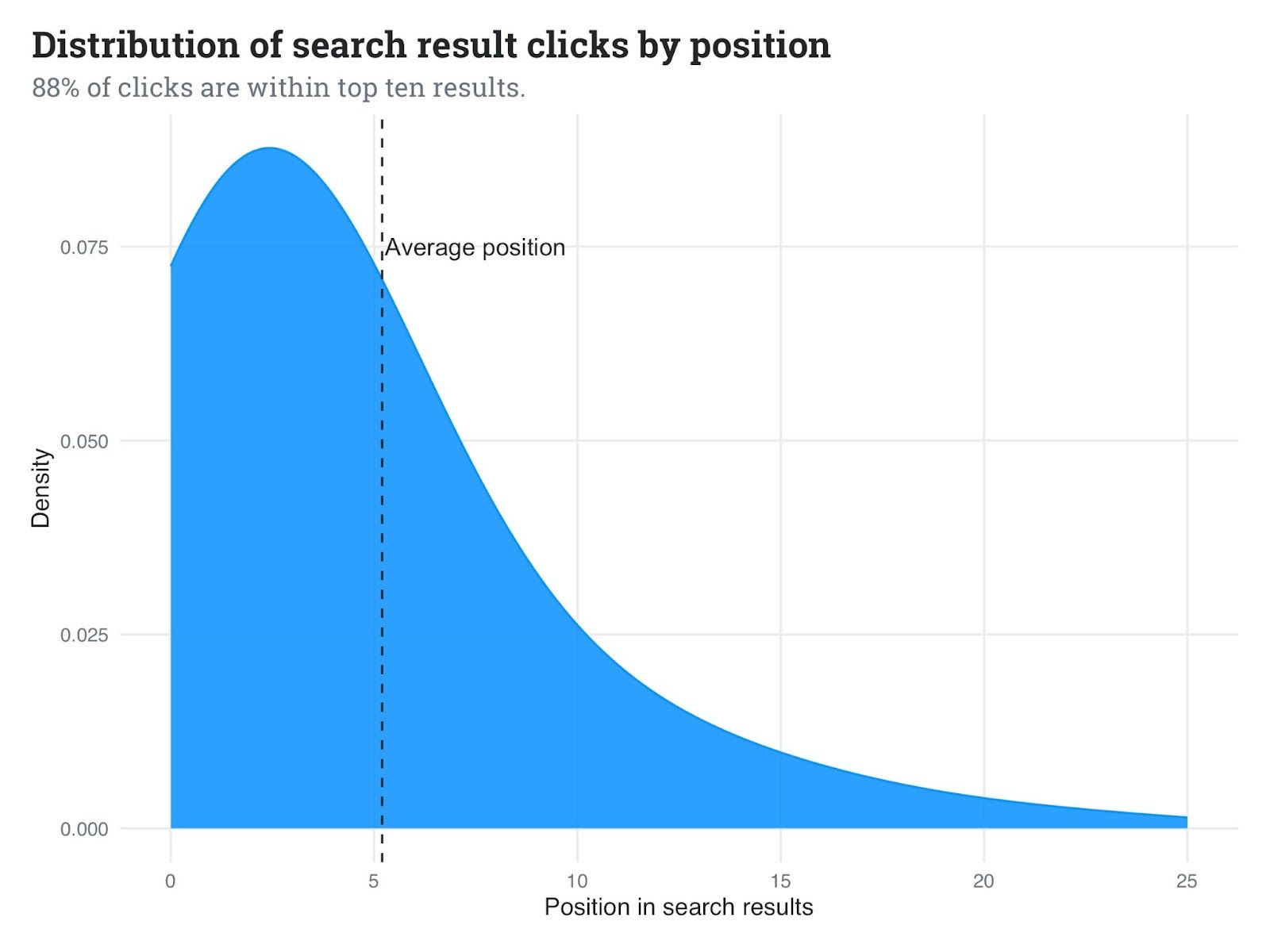
Our knowledge reveals that 88% of clicks occur throughout the first 10 outcomes. In combination, we discover that our clients are clicking roughly the sixth end result on common. By enhancing the order inside this significant set, we are able to considerably improve the search expertise and the efficiency of OverflowAI, our AI-driven options. We additionally know that clients of our OverflowAI product depend upon the highest three outcomes to energy a lot of these options. Due to this fact, we’re focusing our reranking efforts on simply these high 10 outcomes retrieved by our hybrid search algorithm.
Implementation of the reranking system will enhance buyer’s means to seek out content material which they’ll discover larger of their outcomes and extra prone to click on into.
In open benchmarks, this mannequin has proven spectacular enhancements in Imply Reciprocal Rank (MRR) in comparison with a baseline of lexical search utilizing BM25 on the MS Marco dataset.
- Baseline (BM25): 17.29 MRR@10
- Cross-encoder mannequin: 39.01 MRR@10
Nonetheless, it is vital to notice that these numbers mirror efficiency on the dataset the mannequin was fine-tuned on. In our particular use case, with our clients’ personal and distinctive knowledge, we anticipate extra modest enhancements. Many components can affect precise efficiency in a real-world setting, so we additionally use an inner dataset for offline evaluations.
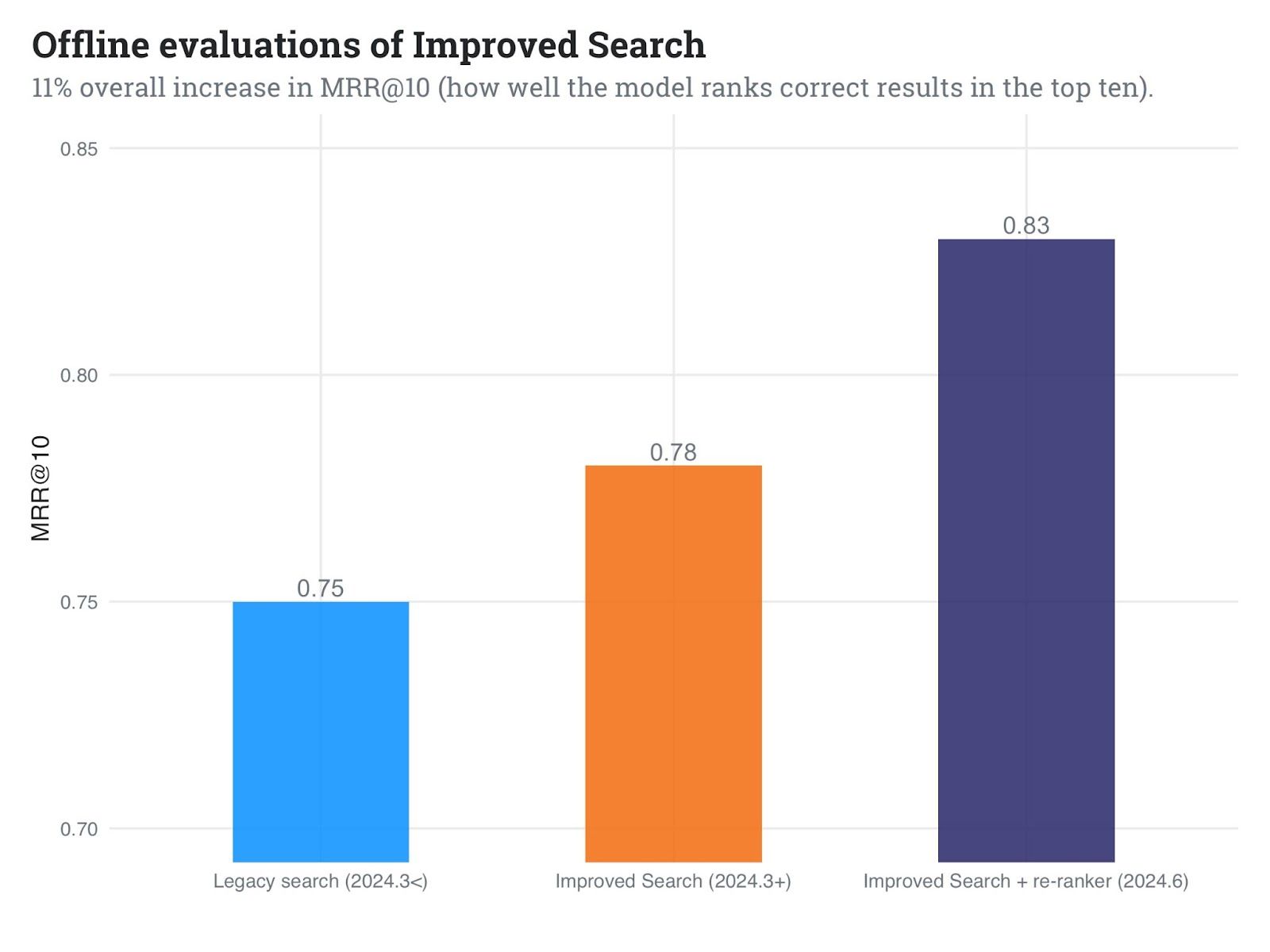
In our inner checks, we have noticed promising outcomes:
- Roughly 6% enchancment in MRR in comparison with our first implementation of Improved Search
- 11% enchancment in MRR in comparison with our legacy search implementation
In the course of the stay experiment, we’ll be monitoring a number of key metrics:
- Click on-By way of Charge (CTR)
- Latency
- Rating of clicked outcomes
- Relevance scores of clicked outcomes vs. remaining retrieved outcomes
We have been making ready for scale from the bottom up. To optimize efficiency and scalability whereas sustaining accuracy, we have employed ONNX Runtime. In our native experiments, this optimization has allowed us to:
- Scale back mannequin latency by roughly half
- Choose extra cost-efficient machines for deployment
These optimizations ought to assist us scale the experiment with out inflicting prices to skyrocket. Nonetheless, it is value noting that these outcomes are from native experiments and will differ in our manufacturing setting.
We’re taking a cautious strategy to make sure minimal disruption:
- Preliminary A/B testing with a subset of Enterprise consumer visitors
- Gradual enhance primarily based on efficiency and consumer suggestions
- Skill to shortly modify or disable the experiment if wanted
It is vital to notice that whereas we’re amassing efficiency metrics, we’re dedicated to sustaining the very best requirements of information privateness. No delicate consumer knowledge is or will likely be collected throughout this experiment.
As we observe the metrics, the information will both verify or reject our speculation. If profitable, we’ll promote the reranking system in its present type as a everlasting fixture in our search system. If unsuccessful, we’ll be taught from the information and analyze re-approach this drawback. In both case, we’ll come again to you with the outcomes so that you might be assured that we’re dedicated to transparency and steady enchancment.
As we collect knowledge and insights from this experiment, we’ll plan our subsequent steps within the search enchancment journey. Keep tuned for future weblog updates that may maintain you knowledgeable in regards to the impacts, classes realized, and subsequent steps.

{kind=link}