Correlation and speculation assessments for various datatypes and assumptions
This put up covers the statistical assessments to detect dependence between pairs of characteristic, regardless of their datatype, and the which take a look at to make use of primarily based on the properties of your knowledge.
You’ll typically end up utilizing statistical assessments throughout exploratory knowledge evaluation. In a supervised setting, it may very well be to see if there’s a dependence between characteristic and goal variables, in order to resolve if the dataset can be utilized for predicting goal end result. In an unsupervised setting you may be utilizing statistical assessments to see if there are options which have dependence between themselves. Such relationships may level to redundant options, which you will wish to take away. The take a look at you utilize will depend on the characteristic sort and dataset properties.
Options can have differing types i.e. qualitative (nominal/ordinal) and quantitative(steady/discrete). As such for every pair of variables we’ve got to make use of the suitable statistical take a look at. As well as every statistical take a look at assumes sure behaviour from the dataset (e.g. usually distributed, monotonic relationship and so forth). As such statistical assessments additionally must be chosen primarily based on which of those assumptions maintain.
Allow us to think about iris dataset and engineer a couple of options to elucidate the completely different sort of statistical assessments you could know
For pairs of variables, the place each are quantitative we use statistical assessments that give us a measure referred to as correlation. Correlation is outlined because the affiliation between two random variables. In statistics it usually refers back to the diploma a pair of variables are linearly associated.
Notice: A compulsory warning that should be talked about when speaking about correlation is “Correlation doesn’t indicate causation”. Try this text for extra about this.
Let’s take a look at the completely different correlation assessments that can be utilized.
Pearson Correlation Check
That is often known as the Pearson Product Second Correlation (PPMC) and is used to detect linear relationships between pairs of variables. It returns a price between -1 and +1. A -1 means there’s a robust adverse correlation i.e. as one variable will increase the opposite decreases. A+1 means that there’s a robust constructive correlation i.e. as one variable will increase so does the opposite. A 0 signifies that there is no such thing as a correlation (that is additionally referred to as zero correlation).
You must use the pearson correlation take a look at when
- Each variables are quantitative
- Each variable are usually distributed
- The info has no outliers
- The connection between variables are assumed to be linear
We will use scipy’s stats library to calculate correlation.
Notice: The bundle additionally offers p-values (take a look at why p-values are essential right here) which characterize the likelihood an uncorrelated dataset can produce the identical correlation. p-values are used to make sure the correlation numbers are dependable.
Spearman Correlation Check
That is often known as Spearman Rank-Order Correlation take a look at or Spearman Rank Correlation take a look at, and is used to detect the existence of monotonic relationship between variables. It additionally returns a price between -1 and +1, the place -1 signifies a adverse monotonic relationship and +1 signifies a constructive one.
You must use the spearman correlation take a look at when
- The variables are quantitative or ordinal
- Variables don’t meet normality assumption
- Variables have a monotonic relationship
Notice: Spearman correlation or Spearman Rank Correlation known as so as a result of it was designed for use on ordinal variables. Nonetheless, due to its non-parametric nature its additionally used on quantitative variables that wouldn’t have a standard distribution
We will once more use the scipy’s stats bundle to calculate spearman correlation.
Kendall-Tau Correlation Check
That is additionally referred to as Kendall Rank correlation take a look at and is used to detect the existence of monotonic relationship.
You must use Kendall-Tau when
- Variables are ordinal or quantitative
- Variable are assumed to have a monotonic relationship
- Pattern dimension of your knowledge is small (varies for dataset, however a tough rule of thumb is under 500)
We will once more use the scipy’s stats bundle to calculate kendall-tau correlation.
For pairs of variables, the place one is quantitative and one is qualitative we are able to use the next statistical assessments
ANOVA take a look at
ANalysis of VAriance (ANOVA), often known as one-way ANOVA, is used to check the imply of greater than 2-groups (basically we group by the qualitative variable and take the imply of the quantitative variable). It’s arrange as a speculation take a look at to establish if the imply of two or extra teams are equal (null speculation), or if no less than one group’s imply is completely different from the others (alternate speculation). Because it’s a speculation take a look at, we use the p-value to reject (if p-value<0.05) or settle for the null-hypothesis.
Accepting the null speculation signifies that options wouldn’t have a dependence between them, whereas rejecting it means options do have a dependence between them.
Notice: When you have got solely 2-groups, you can even use a t-test. Nonetheless empirically the p-value of t-test and ANOVA typically line up.
You must use ANOVA when
- Dependent variable is quantitative and impartial variable is qualitative
- Residuals are usually distributed (A residual is the distinction between a person worth and the imply of all values for a gaggle)
- Variances are equal between teams (referred to as ‘homoscedasticity’)
- There is no such thing as a dependence between the person values of a gaggle with one another, or inside themselves.
We will use scipy’s stats bundle to calculate ANOVA take a look at p-values.
Kruskal-Wallis take a look at
That is often known as Kruskal-Wallis H take a look at or Kruskal–Wallis ANOVA, because it’s a non-parametric various to one-way ANOVA. It’s once more used as a speculation take a look at to check the imply of greater than 2-groups (just like ANOVA) however the assumptions concerning the dataset are completely different.
You must apply the Kruskal-Wallis take a look at when
- The dependent variable must be quantitative or ordinal
- The impartial variable ought to have no less than two teams
- There is no such thing as a dependence between the person values of a gaggle with one another, or inside themselves.
So, the variety of assumption are basically lesser than that of ANOVA (i.e. no want for normality or homoscedasticity)
Notice: While you solely have 2-groups, you can even use a Mann-Whitney U take a look at. Empirically the p-values from each Kruskal-Wallis or Mann-Whiteny are often shut
We will use scipy’s stats bundle to calculate Kruskal-Wallis take a look at p-values.
For pairs of variables, the place each are qualitative we use the chi-sqaured take a look at.
Chi-sqaure take a look at
Additionally it is referred to as the chi-sqaure take a look at of independence and it’s additionally a speculation take a look at. We create a crosstabusing the qualitative variables. (see picture under) We then take a look at if there may be any distinction between the noticed frequencies within the tables and anticipated frequencies if there was no relationship between the variables. The null speculation assumes there is no such thing as a distinction between noticed and anticipated frequencies. So if we settle for the null speculation (e.g. p-value > 0.05) then we are saying the variables should not depending on one different.
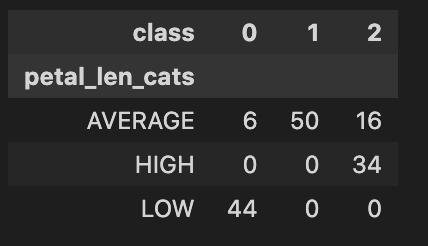
You must use a chi-sqaure take a look at when
- Each variables are qualitative
- All observations are impartial
- We observe no less than a frequency of 5 in every group created when knowledge is grouped by the person pairs of categorical values.
We use scipy’s stats bundle to calculate the p-values for chi-squared take a look at.
On this put up we coated each statistical take a look at you would want to verify characteristic dependence.
- Pearson Correlation Check
- Spearman Correlation Check
- Kendall-Tau Correlation Check
- ANOVA take a look at
- Kruskal-Wallis H take a look at
- Chi-Sq. Check
Notice: It’s to be famous that even when uncooked options don’t present dependence with one another or the goal variable on above assessments, with characteristic engineering (like binning a quantitative variable or collapsing a qualitative one) a dependence may pop up. As such as an alternative of merely making use of the assessments we must always nonetheless examine, perceive, and rework knowledge as required to establish dependence/relationships.

{kind=link}