
Dropout layers have been the go-to technique to cut back the overfitting of neural networks. It’s the underworld king of regularisation within the fashionable period of deep studying.
On this period of deep studying, virtually each knowledge scientist should have used the dropout layer at some second of their profession of constructing neural networks. However, why dropout is so frequent? How does the dropout layer work internally? What’s the downside that it solves? Is there any different to dropout?

When you have related questions concerning dropout layers, then you might be within the right place. On this weblog, you’ll uncover the intricacies behind the well-known dropout layers. After finishing this weblog, you’ll be snug answering completely different queries associated to dropout and in case you are extra of an progressive individual, you would possibly give you a extra superior model of dropout layers.
Let’s begin… 
This weblog is split into the next sections:
- Introduction: The issue it tries to unravel
- What’s a dropout?
- How does it remedy the issue?
- Dropout Implementation
- Dropout throughout Inference
- The way it was conceived
- Tensorflow implementation
- Conclusion
So earlier than diving deep into its world, let’s handle the primary query. What’s the downside that we try to unravel?
The deep neural networks have completely different architectures, generally shallow, generally very deep attempting to generalise on the given dataset. However, on this pursuit of attempting too exhausting to be taught completely different options from the dataset, they generally be taught the statistical noise within the dataset. This positively improves the mannequin efficiency on the coaching dataset however fails massively on new knowledge factors (check dataset). That is the issue of overfitting. To deal with this downside we have now varied regularisation strategies that penalise the weights of the community however this wasn’t sufficient.
One of the simplest ways to cut back overfitting or one of the best ways to regularise a fixed-size mannequin is to get the typical predictions from all doable settings of the parameters and mixture the ultimate output. However, this turns into too computationally costly and isn’t possible for a real-time inference/prediction.
The opposite approach is impressed by the ensemble strategies (resembling AdaBoost, XGBoost, and Random Forest) the place we use a number of neural networks of various architectures. However this requires a number of fashions to be educated and saved, which over time turns into an enormous problem because the networks develop deeper.
So, we have now a fantastic answer generally known as Dropout Layers.
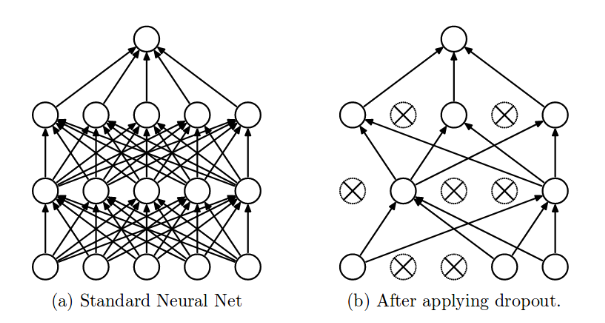
The time period “dropout” refers to dropping out the nodes (enter and hidden layer) in a neural community (as seen in Determine 1). All of the ahead and backwards connections with a dropped node are briefly eliminated, thus creating a brand new community structure out of the guardian community. The nodes are dropped by a dropout chance of p.
Let’s attempt to perceive with a given enter x: {1, 2, 3, 4, 5} to the absolutely linked layer. We’ve a dropout layer with chance p = 0.2 (or preserve chance = 0.8). Throughout the ahead propagation (coaching) from the enter x, 20% of the nodes could be dropped, i.e. the x may turn into {1, 0, 3, 4, 5} or {1, 2, 0, 4, 5} and so forth. Equally, it utilized to the hidden layers.
As an example, if the hidden layers have 1000 neurons (nodes) and a dropout is utilized with drop chance = 0.5, then 500 neurons could be randomly dropped in each iteration (batch).
Typically, for the enter layers, the preserve chance, i.e. 1- drop chance, is nearer to 1, 0.8 being one of the best as advised by the authors. For the hidden layers, the better the drop chance extra sparse the mannequin, the place 0.5 is essentially the most optimised preserve chance, that states dropping 50% of the nodes.
So how does dropout solves the issue of overfitting?
Within the overfitting downside, the mannequin learns the statistical noise. To be exact, the primary motive of coaching is to lower the loss operate, given all of the models (neurons). So in overfitting, a unit could change in a approach that fixes up the errors of the opposite models. This results in complicated co-adaptations, which in flip results in the overfitting downside as a result of this complicated co-adaptation fails to generalise on the unseen dataset.
Now, if we use dropout, it prevents these models to repair up the error of different models, thus stopping co-adaptation, as in each iteration the presence of a unit is extremely unreliable. So by randomly dropping a couple of models (nodes), it forces the layers to take roughly duty for the enter by taking a probabilistic method.
This ensures that the mannequin is getting generalised and therefore decreasing the overfitting downside.
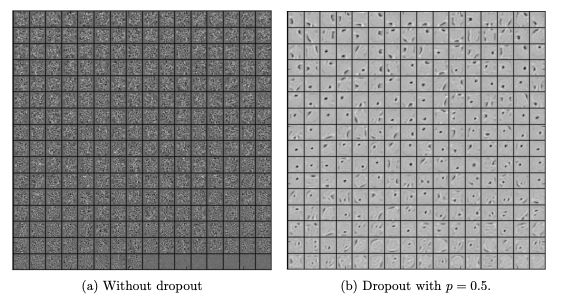
From determine 2, we will simply make out that the hidden layer with dropout is studying extra of the generalised options than the co-adaptations within the layer with out dropout. It’s fairly obvious, that dropout breaks such inter-unit relations and focuses extra on generalisation.
Sufficient of the speaking! Let’s head to the mathematical clarification of the dropout.
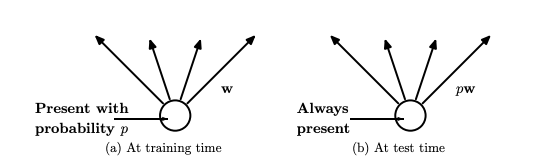
Within the authentic implementation of the dropout layer, throughout coaching, a unit (node/neuron) in a layer is chosen with a preserve chance (1-drop chance). This creates a thinner structure within the given coaching batch, and each time this structure is completely different.
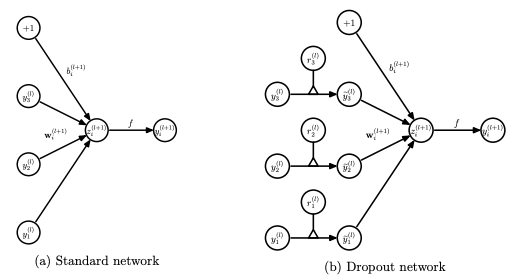
In the usual neural community, throughout the ahead propagation we have now the next equations:

the place:
z: denote the vector of output from layer (l + 1) earlier than activation
y: denote the vector of outputs from layer l
w: weight of the layer l
b: bias of the layer l
Additional, with the activation operate, z is remodeled into the output for layer (l+1).
Now, if we have now a dropout, the ahead propagation equations change within the following approach:
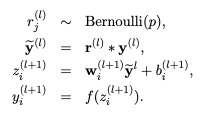
So earlier than we calculate z, the enter to the layer is sampled and multiplied element-wise with the impartial Bernoulli variables. r denotes the Bernoulli random variables every of which has a chance p of being 1. Mainly, r acts as a masks to the enter variable, which ensures only some models are stored based on the preserve chance of a dropout. This ensures that we have now thinned outputs “y(bar)”, which is given as an enter to the layer throughout feed-forward propagation.
Now, we all know the dropout works mathematically however what occurs throughout the inference/prediction? Will we use the community with dropout or can we take away the dropout throughout inference?
This is among the most essential ideas of dropout which only a few knowledge scientists are conscious of.
In line with the unique implementation (Determine 3b) throughout the inference, we don’t use a dropout layer. Which means all of the models are thought of throughout the prediction step. However, due to taking all of the models/neurons from a layer, the ultimate weights might be bigger than anticipated and to take care of this downside, weights are first scaled by the chosen dropout fee. With this, the community would have the ability to make correct predictions.
To be extra exact, if a unit is retained with chance p throughout coaching, the outgoing weights of that unit are multiplied by p throughout the prediction stage.
If we observe the unique implementation, we have to multiply the weights with the dropout chance throughout the prediction stage. Simply to take away any processing throughout this stage, we have now an implementation generally known as “inverse dropout”.
The intention of multiplying weights with dropout chance is to make sure that the ultimate weights are of the identical scale, thus the predictions are right. In inverse dropout, this step is carried out throughout the coaching itself. On the coaching time, all of the weights that stay after the dropout operation is multiplied by the inverse of preserve chance, i.e. w * (1/p).
To achieve mathematical proof of why each operations are related on the layer weights, I like to recommend going by means of a weblog by Lei Mao.
Lastly!! We’ve lined the in-depth evaluation of the dropout layers that we use with virtually all of the neural networks.
Dropouts can be utilized with most kinds of neural networks. It’s a useful gizmo to cut back overfitting in a mannequin. It is much better than the accessible regularisation strategies and can be mixed with max-norm normalisation which supplies a major increase over simply utilizing dropout.
Within the upcoming blogs, we might be taught extra about such fundamental layers that are utilized in virtually all networks. Batch normalisation, layer normalisation, and a focus layers to call a couple of.
[1] Nitish Srivastava, Dropout: A Easy Approach to Forestall Neural Networks from Overfitting, https://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
[2] Jason Brownlee, A Light Introduction to Dropout for Regularizing Deep Neural Networks, https://machinelearningmastery.com/dropout-for-regularizing-deep-neural-networks/
[3] Lei Mao, Dropout Defined, https://leimao.github.io/weblog/Dropout-Defined/#:~:textual content=Duringpercent20inferencepercent20timepercent2Cpercent20dropoutpercent20does,werepercent20multipliedpercent20bypercent20pkeeppercent20.
[4] Juan Miguel, Dropout defined and implementation in Tensorflow, http://laid.delanover.com/dropout-explained-and-implementation-in-tensorflow/

{kind=link}