
Each information warehouses and information lakes can maintain massive quantities of information for evaluation. As you could recall, information warehouses include curated, structured information, have a predesigned schema that’s utilized when the information is written, name on massive quantities of CPU, SSDs, and RAM for velocity, and are supposed to be used by enterprise analysts. Knowledge lakes maintain much more information that may be unstructured or structured, initially saved uncooked and in its native format, usually use low-cost spinning disks, apply schemas when the information is learn, filter and rework the uncooked information for evaluation, and are supposed to be used by information engineers and information scientists initially, with enterprise analysts ready to make use of the information as soon as it has been curated..
Knowledge lakehouses, akin to the topic of this evaluate, Dremio, bridge the hole between information warehouses and information lakes. They begin with a knowledge lake and add quick SQL, a extra environment friendly columnar storage format, a knowledge catalog, and analytics.
Dremio describes its product as a knowledge lakehouse platform for groups that know and love SQL. Its promoting factors are
- SQL for everybody, from enterprise person to information engineer;
- Totally managed, with minimal software program and information upkeep;
- Help for any information, with the flexibility to ingest information into the lakehouse or question in place; and
- No lock-in, with the pliability to make use of any engine as we speak and tomorrow.
In line with Dremio, cloud information warehouses akin to Snowflake, Azure Synapse, and Amazon Redshift generate lock-in as a result of the information is contained in the warehouse. I don’t utterly agree with this, however I do agree that it’s actually arduous to maneuver massive quantities of information from one cloud system to a different.
Additionally in keeping with Dremio, cloud information lakes akin to Dremio and Spark supply extra flexibility because the information is saved the place a number of engines can use it. That’s true. Dremio claims three benefits that derive from this:
- Flexibility to make use of a number of best-of-breed engines on the identical information and use circumstances;
- Straightforward to undertake extra engines as we speak; and
- Straightforward to undertake new engines sooner or later, merely level them on the information.
Opponents to Dremio embrace the Databricks Lakehouse Platform, Ahana Presto, Trino (previously Presto SQL), Amazon Athena, and open-source Apache Spark. Much less direct opponents are information warehouses that help exterior tables, akin to Snowflake and Azure Synapse.
Dremio has painted all enterprise information warehouses as their opponents, however I dismiss that as advertising and marketing, if not precise hype. In any case, information lakes and information warehouses fulfill completely different use circumstances and serve completely different customers, regardless that information lakehouses at the least partially span the 2 classes.
Dremio Cloud overview
Dremio server software program is a Java information lakehouse utility for Linux that may be deployed on Kubernetes clusters, AWS, and Azure. Dremio Cloud is principally the Dremio server software program operating as a totally managed service on AWS.
Dremio Cloud’s features are divided between digital personal clouds (VPCs), Dremio’s and yours, as proven within the diagram beneath. Dremio’s VPC acts because the management airplane. Your VPC acts as an execution airplane. In the event you use a number of cloud accounts with Dremio Cloud, every VPC acts as an execution airplane.
The execution airplane holds a number of clusters, referred to as compute engines. The management airplane processes SQL queries with the Sonar question engine and sends them by way of an engine supervisor, which dispatches them to an applicable compute engine based mostly in your guidelines.
Dremio claims sub-second response instances with “reflections,” that are optimized materializations of supply information or queries, just like materialized views. Dremio claims uncooked velocity that’s 3x sooner than Trino (an implementation of the Presto SQL engine) because of Apache Arrow, a standardized column-oriented reminiscence format. Dremio additionally claims, with out specifying some extent of comparability, that information engineers can ingest, rework, and provision information in a fraction of the time because of SQL DML, dbt, and Dremio’s semantic layer.
Dremio has no enterprise intelligence, machine studying, or deep studying capabilities of its personal, however it has drivers and connectors that help BI, ML, and DL software program, akin to Tableau, Energy BI, and Jupyter Notebooks. It may additionally connect with information sources in tables in lakehouse storage and in exterior relational databases.
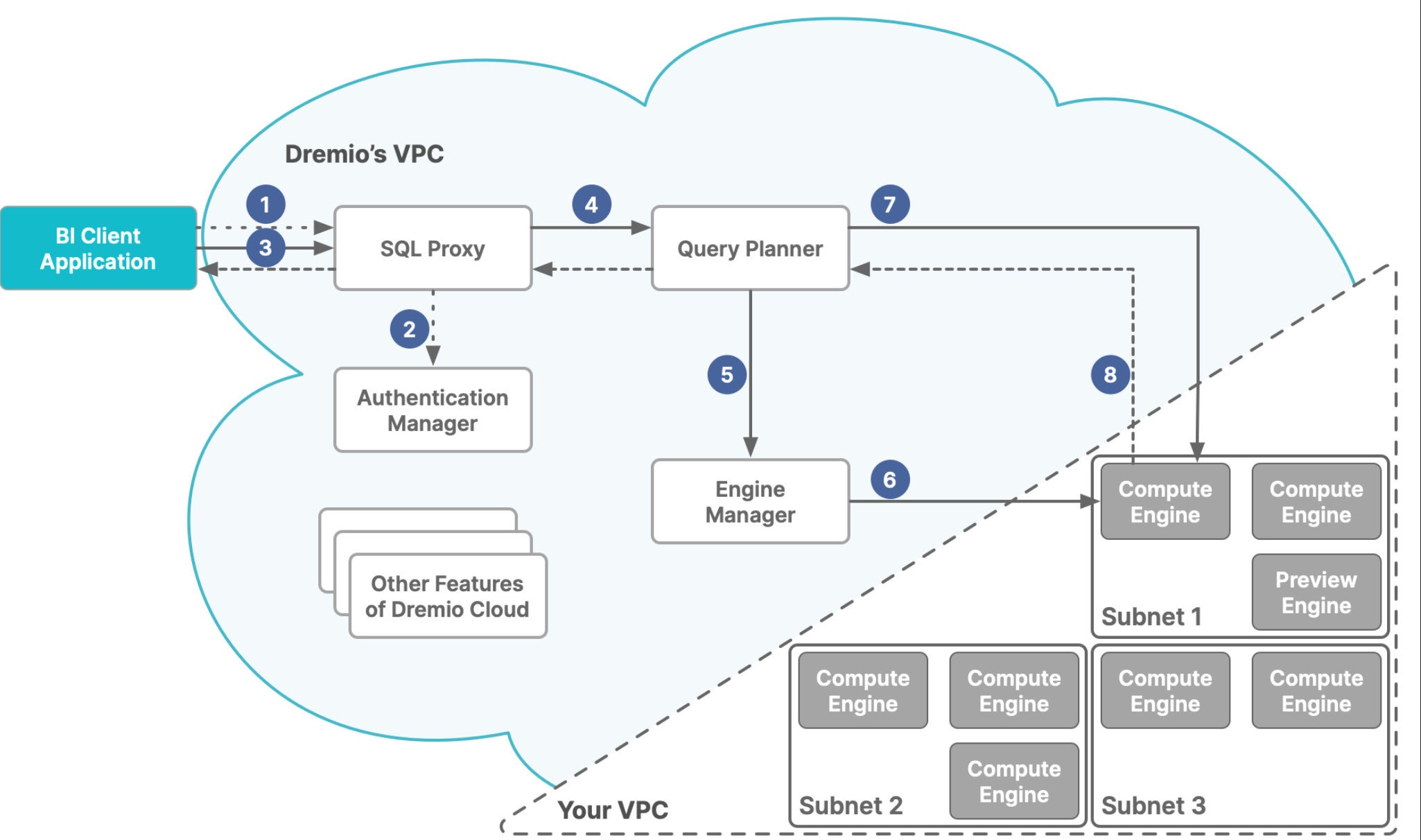 IDG
IDGDremio Cloud is break up into two Amazon digital personal clouds (VPCs). Dremio’s VPC hosts the management airplane, together with the SQL processing. Your VPC hosts the execution airplane, which comprises the compute engines.
Dremio Arctic overview
Dremio Arctic is an clever metastore for Apache Iceberg, an open desk format for enormous analytic datasets, powered by Nessie, a local Apache Iceberg catalog. Arctic offers a contemporary, cloud-native different to Hive Metastore, and is supplied by Dremio as a forever-free service. Arctic gives the next capabilities:
- Git-like information administration: Brings Git-like model management to information lakes, enabling information engineers to handle the information lake with the identical greatest practices Git permits for software program growth, together with commits, tags, and branches.
- Knowledge optimization (coming quickly): Robotically maintains and optimizes information to allow sooner processing and scale back the guide effort concerned in managing a lake. This contains guaranteeing that the information is columnarized, compressed, compacted (for bigger information), and partitioned appropriately when information and schemas are up to date.
- Works with all engines: Helps all Apache Iceberg-compatible applied sciences, together with question engines (Dremio Sonar, Presto, Trino, Hive), processing engines (Spark), and streaming engines (Flink).
Dremio information file codecs
A lot of the efficiency and performance of Dremio relies on the disk and reminiscence information file codecs used.
Apache Arrow
Apache Arrow, which was created by Dremio and contributed to open supply, defines a language-independent columnar reminiscence format for flat and hierarchical information, organized for environment friendly analytic operations on fashionable {hardware} like CPUs and GPUs. The Arrow reminiscence format additionally helps zero-copy reads for lightning-fast information entry with out serialization overhead.
Gandiva is an LLVM-based vectorized execution engine for Apache Arrow. Arrow Flight implements RPC (distant process calls) on Apache Arrow, and is constructed on gRPC. gRPC is a contemporary, open-source, high-performance RPC framework from Google that may run in any setting; gRPC is usually 7x to 10x sooner than REST message transmission.
Apache Iceberg
Apache Iceberg is a high-performance format for enormous analytic tables. Iceberg brings the reliability and ease of SQL tables to large information, whereas making it doable for engines akin to Sonar, Spark, Trino, Flink, Presto, Hive, and Impala to securely work with the identical tables, on the identical time. Iceberg helps versatile SQL instructions to merge new information, replace present rows, and carry out focused deletes.
Apache Parquet
Apache Parquet is an open-source, column-oriented information file format designed for environment friendly information storage and retrieval. It offers environment friendly information compression and encoding schemes with enhanced efficiency to deal with advanced information in bulk.
Apache Iceberg vs. Delta Lake
In line with Dremio, the Apache Iceberg information file format was created by Netflix, Apple, and different tech powerhouses, helps INSERT/UPDATE/DELETE with any engine, and has sturdy momentum within the open-source neighborhood. Against this, once more in keeping with Dremio, the Delta Lake information file format was created by Databricks, helps INSERT/UPDATE with Spark and SELECT with any SQL question engine, and is primarily used together with Databricks.
The Delta Lake documentation on GitHub begs to vary. For instance, there’s a connector that enables Trino to learn and write Delta Lake information, and a library that enables Scala and Java-based initiatives (together with Apache Flink, Apache Hive, Apache Beam, and PrestoDB) to learn from and write to Delta Lake.
Dremio question acceleration
Along with the question efficiency that’s derived from the file codecs used, Dremio can speed up queries utilizing a columnar cloud cache and information reflections.
Columnar Cloud Cache (C3)
Columnar Cloud Cache (C3) permits Dremio to realize NVMe-level I/O efficiency on Amazon S3, Azure Knowledge Lake Storage, and Google Cloud Storage through the use of the NVMe/SSD constructed into cloud compute situations, akin to Amazon EC2 and Azure Digital Machines. C3 solely caches information required to fulfill your workloads and may even cache particular person microblocks inside datasets. In case your desk has 1,000 columns and also you solely question a subset of these columns and filter for information inside a sure timeframe, then C3 will cache solely that portion of your desk. By selectively caching information, C3 additionally dramatically reduces cloud storage I/O prices, which might make up 10% to fifteen% of the prices for every question you run, in keeping with Dremio.
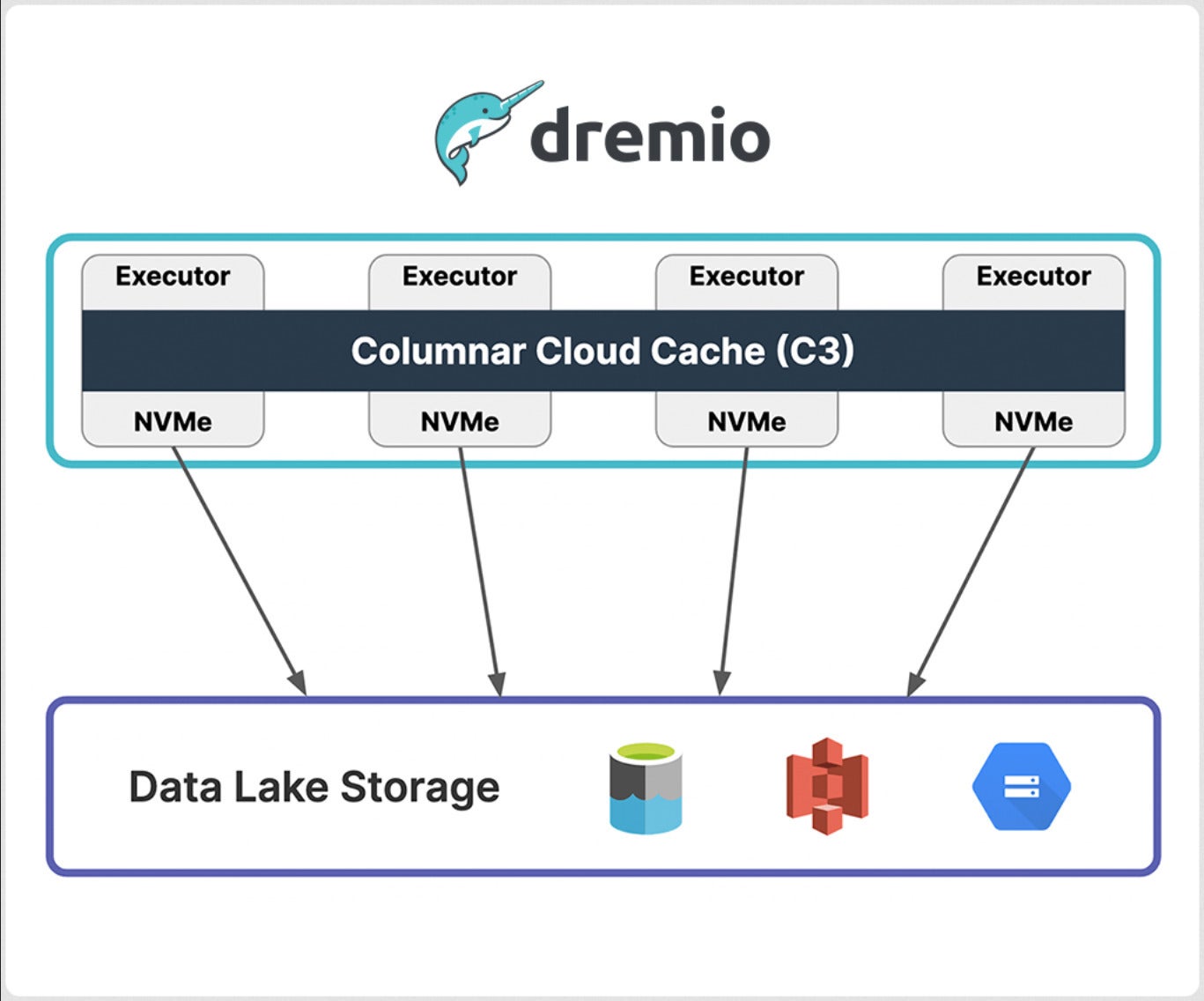 IDG
IDGDremio’s Columnar Cloud Cache (C3) characteristic accelerates future queries through the use of the NVMe SSDs in cloud situations to cache information utilized by earlier queries.
Knowledge Reflections
Knowledge Reflections allow sub-second BI queries and remove the necessity to create cubes and rollups previous to evaluation. Knowledge Reflections are information constructions that intelligently precompute aggregations and different operations on information, so that you don’t should do advanced aggregations and drill-downs on the fly. Reflections are utterly clear to finish customers. As a substitute of connecting to a selected materialization, customers question the specified tables and views and the Dremio optimizer picks one of the best reflections to fulfill and speed up the question.
Dremio Engines
Dremio encompasses a multi-engine structure, so you’ll be able to create a number of right-sized, bodily remoted engines for numerous workloads in your group. You’ll be able to simply arrange workload administration guidelines to route queries to the engines you outline, so that you’ll by no means have to fret once more about advanced information science workloads stopping an government’s dashboard from loading. Apart from eliminating useful resource rivalry, engines can shortly resize to deal with workloads of any concurrency and throughput, and auto-stop while you’re not operating queries.
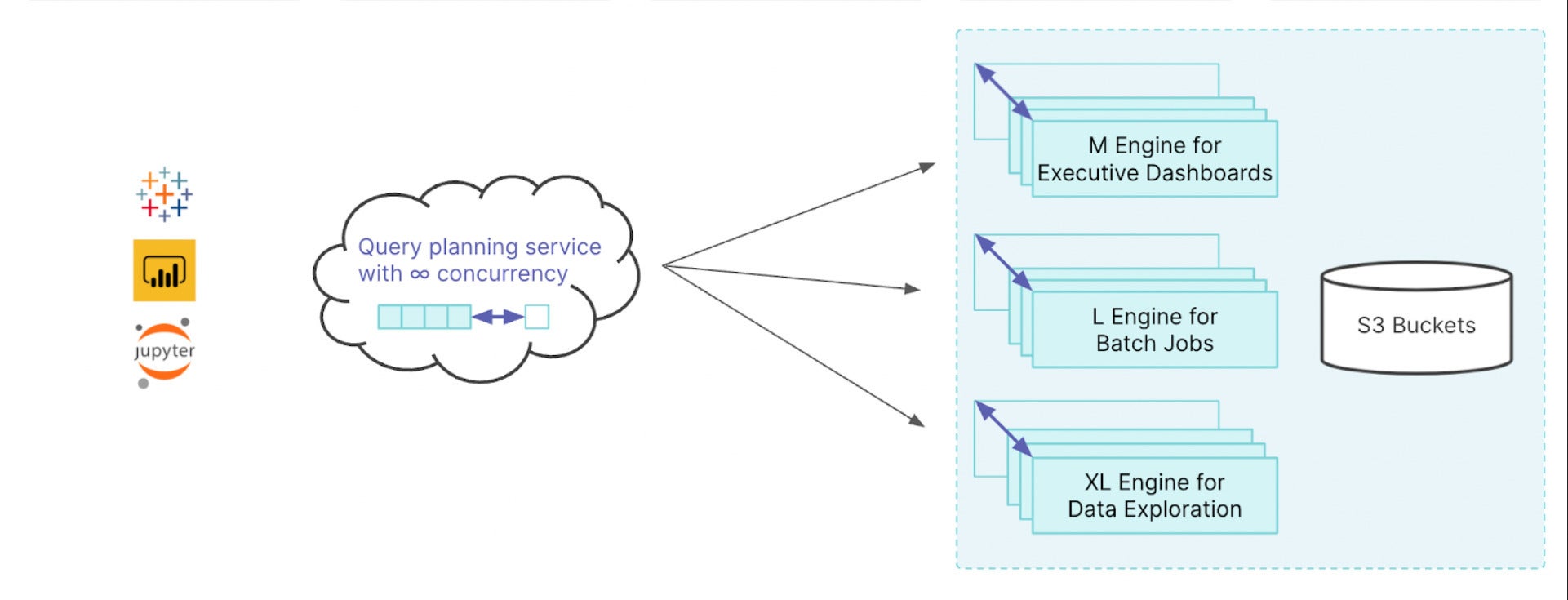 IDG
IDGDremio Engines are basically scalable clusters of situations configured as executors. Guidelines assist to dispatch queries to the specified engines.
Getting began with Dremio Cloud
The Dremio Cloud Getting Began information covers
- Including a knowledge lake to a venture;
- Making a bodily dataset from supply information;
- Making a digital dataset;
- Querying a digital dataset; and
- Accelerating a question with a mirrored image.
I received’t present you each step of the tutorial, since you’ll be able to learn it your self and run by way of it in your individual free account.
Two important factors are that:
- A bodily dataset (PDS) is a desk illustration of the information in your supply. A PDS can’t be modified by Dremio Cloud. The way in which to create a bodily dataset is to format a file or folder as a PDS.
- A digital dataset (VDS) is a view derived from bodily datasets or different digital datasets. Digital datasets usually are not copies of the information in order that they use little or no reminiscence and all the time replicate the present state of the mother or father datasets they’re derived from.

{kind=link}