Whereas it’s technically nonetheless the brand new child on the block, the Compute Categorical Hyperlink (CXL) customary for host-to-device connectivity has shortly taken maintain within the server market. Designed to supply a wealthy I/O characteristic set constructed on high of the present PCI-Categorical requirements – most notably cache-coherency between units – CXL is being ready to be used in every little thing from higher connecting CPUs to accelerators in servers, to with the ability to connect DRAM and non-volatile storage over what’s bodily nonetheless a PCIe interface. It’s an formidable and but widely-backed roadmap that in three brief years has made CXL the de facto superior machine interconnect customary, resulting in rivals requirements Gen-Z, CCIX, and as of yesterday, OpenCAPI, all dropping out of the race.
And whereas the CXL Consortium is taking a fast victory lap this week after successful the interconnect wars, there may be far more work to be executed by the consortium and its members. On the product entrance the primary x86 CPUs with CXL are simply barely transport – largely relying on what you wish to name the limbo state that Intel’s Sapphire Ridge chips are in – and on the performance entrance, machine distributors are asking for extra bandwidth and extra options than had been within the authentic 1.x releases of CXL. Successful the interconnect wars makes CXL the king of interconnects, however within the course of, it implies that CXL wants to have the ability to handle a number of the extra complicated use circumstances that rival requirements had been being designed for.
To that finish, at Flash Reminiscence Summit 2022 this week, the CXL Consortium is on the present to announce the following full model of the CXL customary, CXL 3.0. Following up on the two.0 customary, which was launched on the tail-end of 2020 and launched options corresponding to reminiscence pooling and CXL switches, CXL 3.0 focuses on main enhancements in a few essential areas for the interconnect. The primary of which is the bodily facet, the place is CXL doubling its per-lane throughput to 64 GT/second. In the meantime, on the logical facet of issues, CXL 3.0 is drastically increasing the logical capabilities of the usual, permitting for complicated connection topologies and materials, in addition to extra versatile reminiscence sharing and reminiscence entry modes inside a bunch of CXL units.
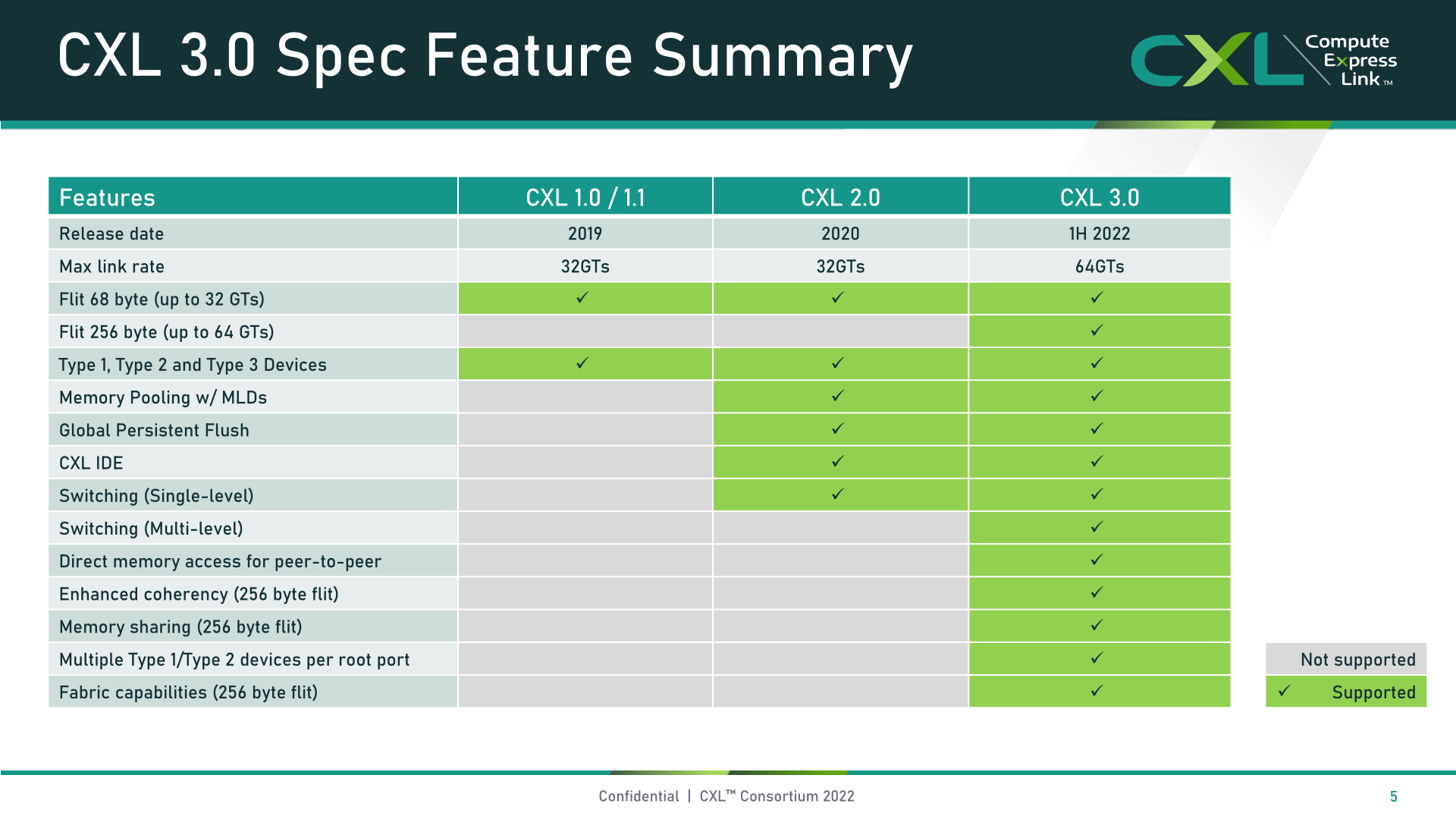
CXL 3.0: Constructed On High of PCI-Categorical 6.0
Beginning with the bodily points of CXL, the brand new model of the usual delivers on the long-awaited replace to include PCIe 6.0. Each earlier variations of CXL, that’s to say 1.x and a pair of.0, had been constructed on high of PCIe 5.0, so that is the primary time since CXL’s introduction in 2019 that its bodily layer has been up to date.
Itself a significant replace to the interior workings of the PCI-Categorical customary, PCIe 6.0 but once more doubled the quantity of bandwidth obtainable over the bus to 64 GT/second, which for a x16 card works out to 128GB/sec. This was completed by transitioning PCIe from utilizing binary (NRZ) signaling to quad-state (PAM4) signaling and incorporating a set packet (FLIT) interface, permitting it to double speeds with out the drawbacks of working at even larger frequencies. Since CXL in flip is constructed on high of PCIe, this meant that the usual wanted to be up to date to account for the operational modifications to PCIe.

The top end result for CXL 3.0 is that it inherits the total bandwidth enhancements of PCIe 6.0 – together with all of the enjoyable stuff like ahead error correction (FEC) – doubling CXL’s whole bandwidth as in comparison with CXL 2.0.
Notably, in keeping with the CXL Consortium they’ve been in a position to accomplish all of this with out a rise in latency. This was one of many challenges the PCI-SIG confronted in designing PCIe 6.0, as the required error correction would add latency to the method, ensuing within the PCI-SIG utilizing a low-latency type of FEC. Nonetheless, CXL 3.0 takes issues one step additional in making an attempt to cut back latency, leading to 3.0 having the identical latency as CXL 1.x/2.0.
In addition to the bottom PCIe .60 replace, the CXL Consortium has additionally tweaked their FLIT dimension. Whereas CXL 1.x/2.0 used a comparatively small 68 byte packet, CXL 3.0 bumps this as much as 256 bytes. The a lot bigger FLIT dimension is likely one of the key communications modifications with CXL 3.0, because it provides the usual many extra bits within the header FLIT, which in flip are wanted to allow the complicated topologies and materials the three.0 customary introduces. Although as an added characteristic, CXL 3.0 additionally gives a low-latency “variant” FLIT mode that breaks up the CRC into 128 byte “sub-FLIT granular transfers”, which is designed to mitigate store-and-forward overheads within the bodily layer.
Notably, the 256 byte FLIT dimension retains CXL 3.0 according to PCIe 6.0, which itself makes use of a 256 byte FLIT. And like its underlying bodily layer, CXL helps utilizing the big FLIT not solely on the new 64 GT/sec switch fee, but in addition 32, 16, and eight GT/sec, basically permitting the brand new protocol options for use with slower switch charges.
Lastly, CXL 3.0 is absolutely backwards appropriate with earlier variations of CXL. So units and hosts can downgrade as wanted to match the remainder of the {hardware} chain, albeit shedding newer options and speeds within the course of.
CXL 3.0 Options: Enhanced Coherency, Reminiscence Sharing, Multi-Degree Topologies, and Materials
Apart from additional bettering on total I/O bandwidth, the aforementioned protocol modifications for CXL have additionally been carried out in service of enabling new options inside the usual. CXL 1.x was born as a (comparatively) easy host-to-device customary, however now that CXL is the dominant machine interconnect protocol for servers, it must increase its capabilities each to accommodate extra superior units, and finally to accommodate higher use circumstances.
Kicking issues off on the characteristic stage, the most important information right here is that the usual has up to date the cache coherency protocol for units with reminiscence (Sort-2 and Sort-3, in CXL parlance). Enhanced coherency, as CXL calls it, permits for units to again invalidate knowledge that’s being cached by a bunch. This replaces the bias-based coherency method utilized in earlier variations of CXL, which to maintain issues transient, maintained coherency not a lot by sharing management of a reminiscence area, however fairly by both placing the host or machine answerable for controlling entry. Again invalidation, in distinction, is far nearer to a real shared/symmetric method, permitting CXL units to tell a bunch when the machine has made a change.
The inclusion of again invalidation additionally opens the door to new peer-to-peer connectivity between units. In CXL 3.0, units can now straight entry one another’s reminiscence with out having to undergo a bunch, utilizing the improved coherency semantics to tell one another of their state. Skipping the host will not be solely quicker from a latency perspective, however in a setup involving a change, it means units aren’t consuming up treasured host-to-switch bandwidth with their requests. And whereas we’ll get into topologies a bit later, these modifications go hand-in hand with bigger topologies, permitting units to be organized into digital hierarchies, the place the entire units in a hierarchy share a coherency area.
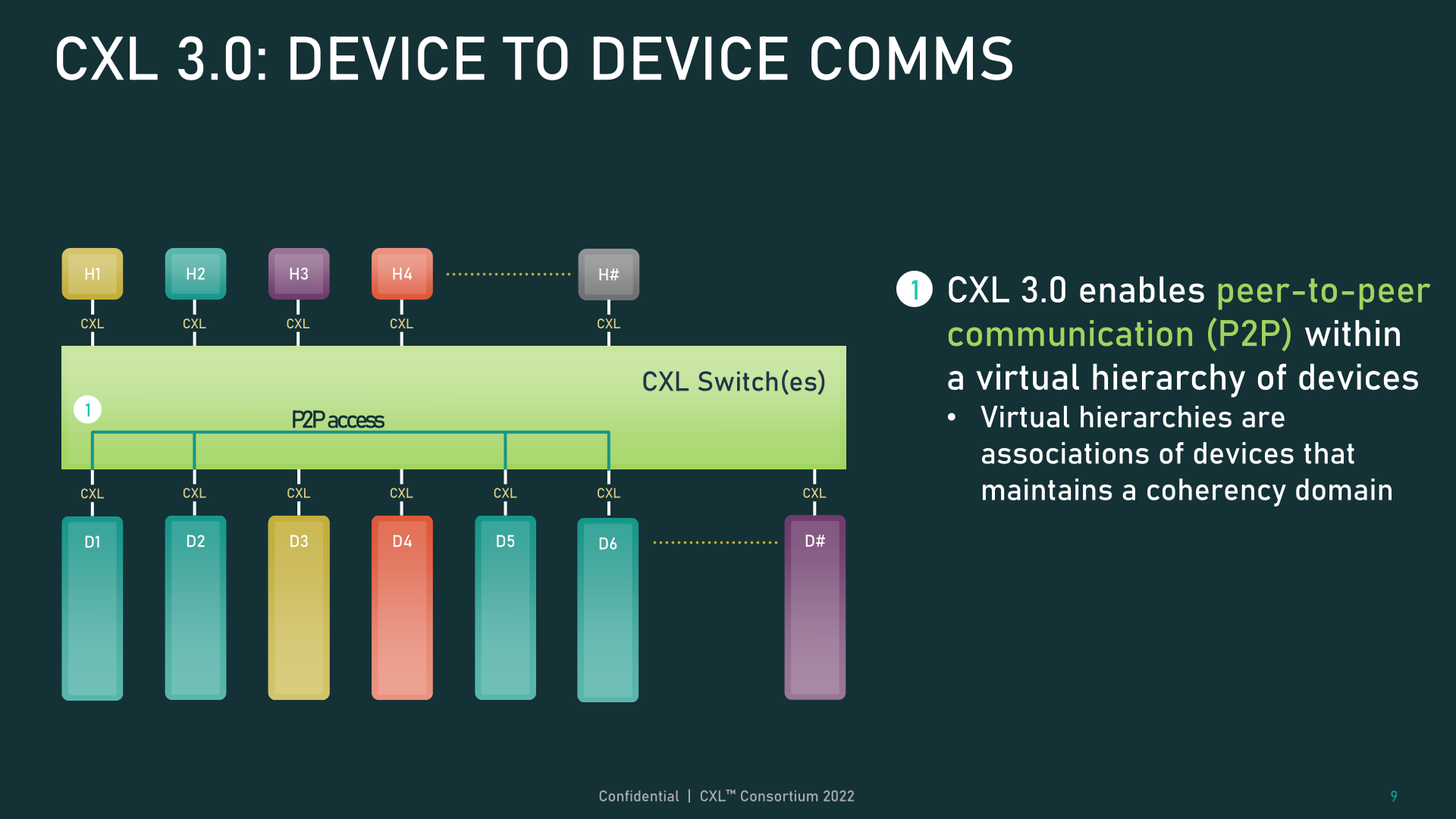
Together with tweaking cache performance, CXL 3.0 additionally introduces some essential updates to reminiscence sharing between hosts and units. Whereas CXL 2.0 provided reminiscence pooling, the place a number of hosts may entry a tool’s reminiscence however every needed to be assigned their very own devoted reminiscence section, CXL 3.0 introduces true reminiscence sharing. Leveraging the brand new enhanced coherency semantics, a number of hosts can have a coherent copy of a shared section, with again invalidation used to maintain all of the hosts in sync ought to one thing change on the machine stage.
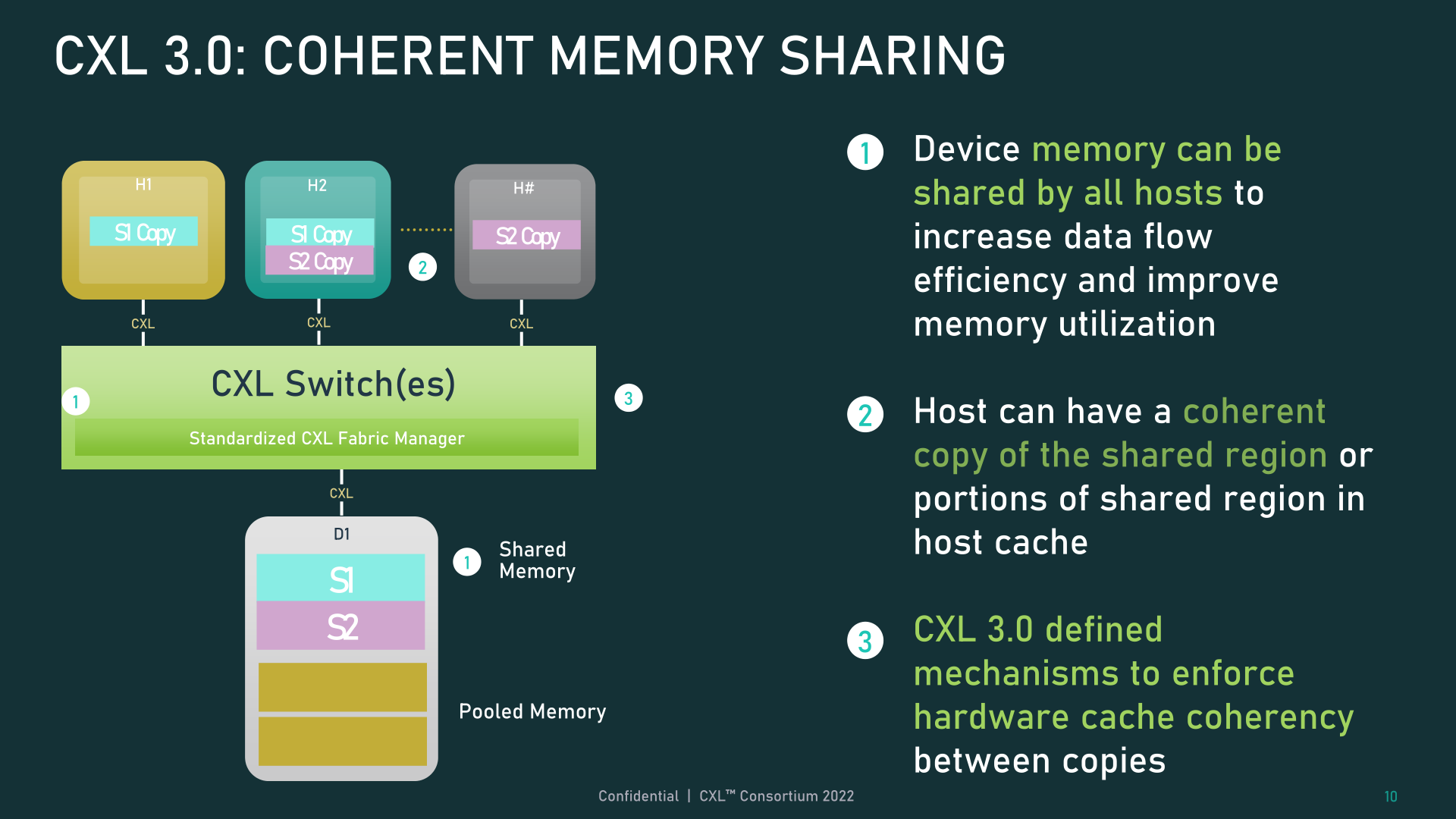
It must be famous, nonetheless, that this doesn’t totally substitute pooling. There are nonetheless use circumstances the place CXL 2.0-style pooling can be preferable (sustaining coherency comes with trade-offs), and CXL 3.0 helps mixing and matching the 2 modes as needed.
Additional augmenting this improved host-device performance, CXL 3.0 does away with the earlier limitations on the variety of Sort-1/Sort-2 units that may be hooked up downstream of a single CXL root port. Whereas CXL 2.0 solely allowed for a single certainly one of these processing units to be current downstream of a root port, CXL 3.0 lifts these limitations totally. Now a CXL root port can help a full mix-and-match setup of Sort-1/2/3 units, relying on a system builder’s objectives. Notably, this implies with the ability to connect a number of accelerators to a single change, bettering density (extra accelerators per host), and making the brand new peer-to-peer switch options much more helpful.

The opposite large characteristic change for CXL 3.0 is help for multi-level switching. This builds upon CXL 2.0, which launched help for CXL protocol switches, however solely allowed for a single change to reside between a bunch and its units. Multi-level switching, then again, permits for a number of layers of switches – which is to say, switches feeding into different switches – which vastly will increase the sorts and complexities of networking topologies supported.

Even with simply two layers of switches, that is sufficient flexibility to allow non-tree topologies, corresponding to rings, meshes, and different cloth setups. And the person nodes might be hosts or units, with none restrictions on varieties.
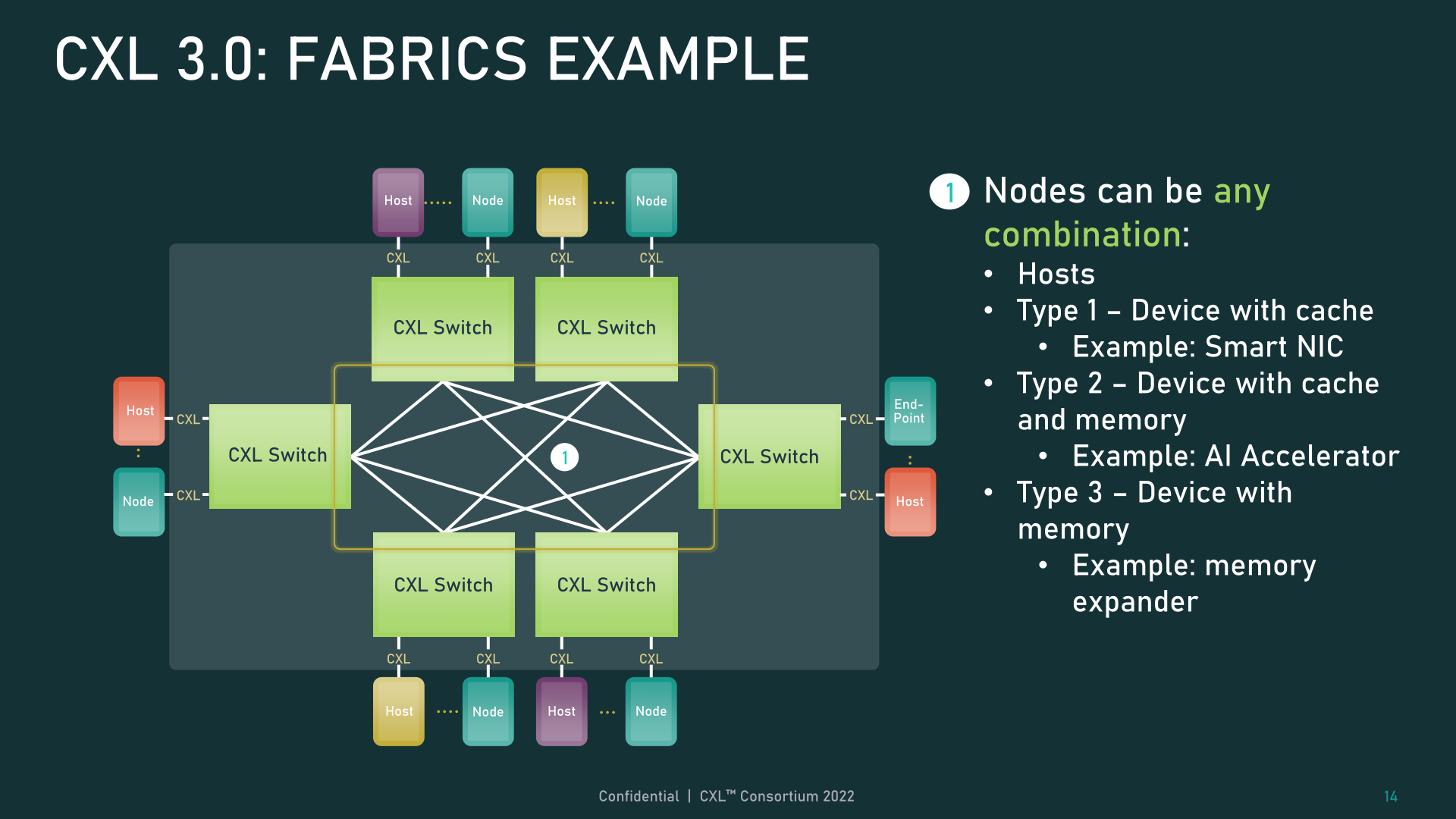
In the meantime, for really unique setups, CXL 3.0 may even help backbone/leaf architectures, the place site visitors is routed by top-level backbone nodes whose solely job is to additional route site visitors again to lower-level (leaf) nodes that in flip comprise precise hosts/units.
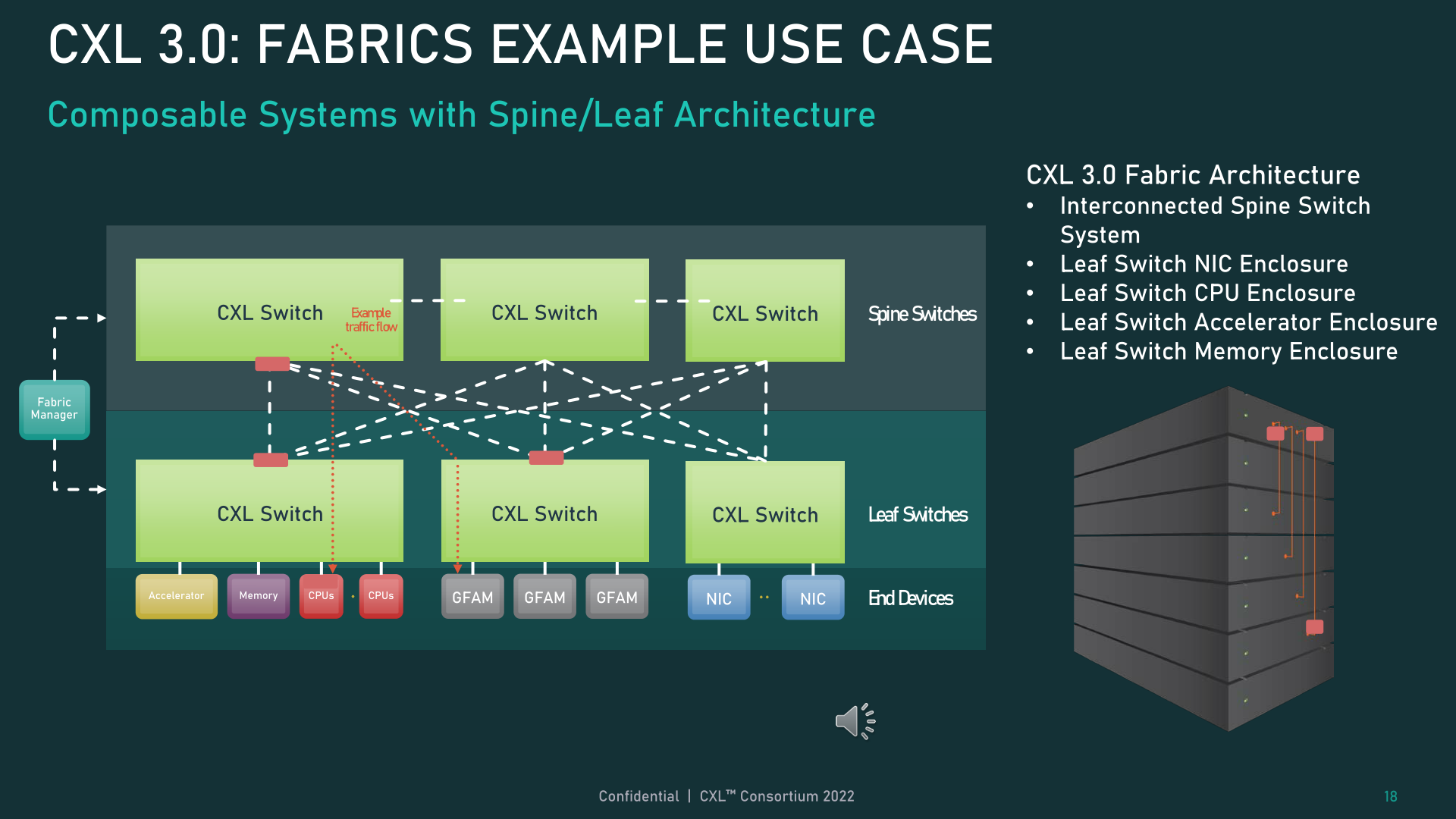
Lastly, all of those new reminiscence and topology/cloth capabilities can be utilized collectively in what the CXL Consortium is asking World Cloth Hooked up Reminiscence (GFAM). GFAM, in a nutshell, takes CXL’s reminiscence growth board (Sort-3) thought to the following stage by additional disaggregating reminiscence from a given host. A GFAM machine, in that respect, is functionally its personal shared pool of reminiscence that hosts and units can attain out to on an as-needed foundation. And a GFAM machine can comprise each unstable and non-volatile reminiscence collectively, corresponding to DRAM and flash reminiscence.
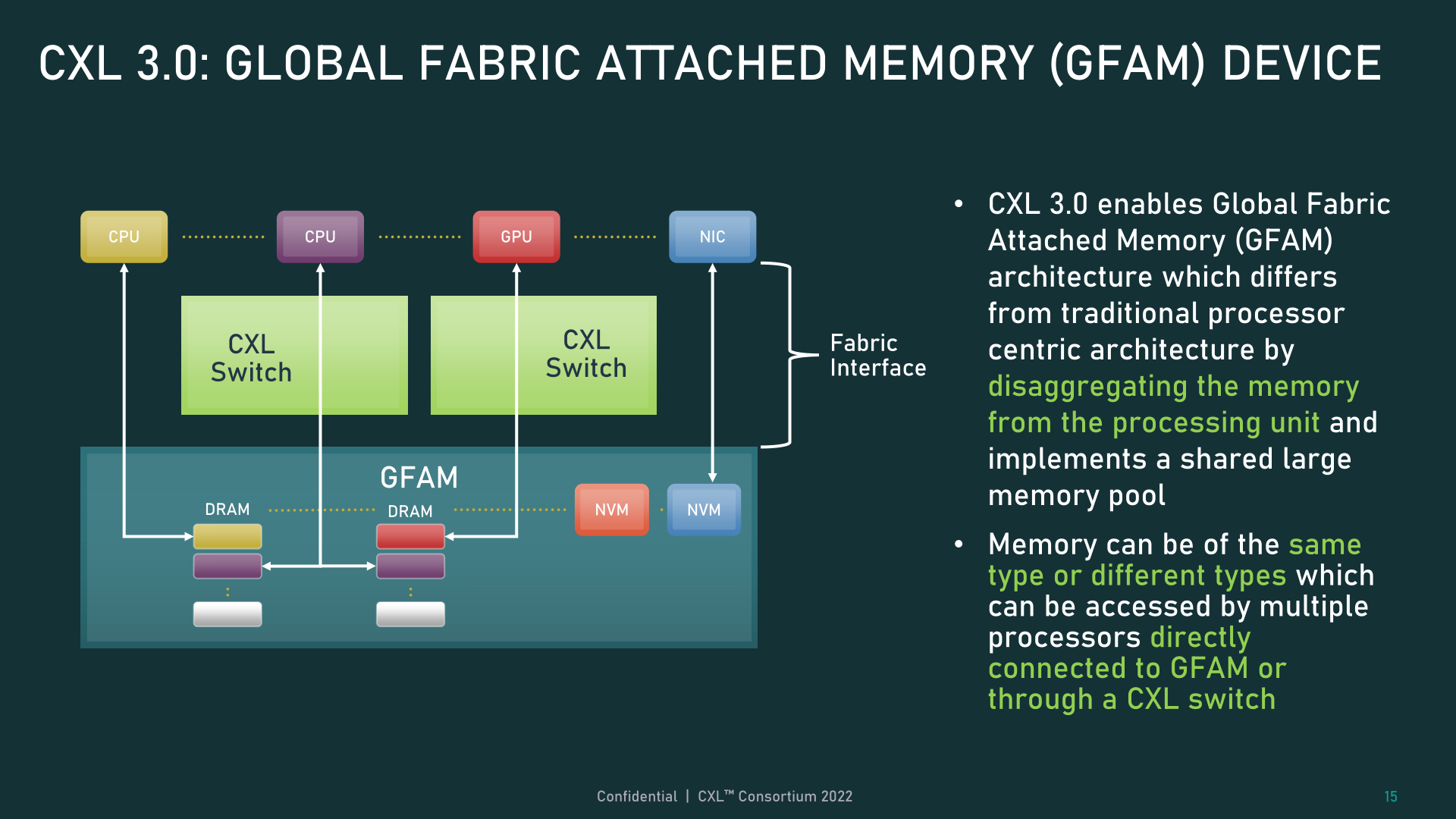
GFAM, in flip, is what’s going to enable CXL for use to effectively help giant, multi-node setups. Because the Consortium makes use of in certainly one of their examples, GFAM permits CXL 3.0 to supply the required efficiency and effectivity for implementing MapReduce over a cluster of CXL-connected machines. MapReduce, after all, is a very talked-about algorithm to be used with accelerators, so increasing CXL to raised deal with a workload widespread to clustered accelerators is an apparent (and arguably needed) subsequent step for the usual. Although it does blur the strains a bit between the place a neighborhood interconnect corresponding to CXL ends, and a community interconnect corresponding to InfiniBand begins.
Finally, the most important differentiator would be the variety of nodes supported. CXL’s addressing mechanism, which the Consortium calls Port Based mostly Routing (PBR), helps as much as 2^12 (4096) units. So a CXL setup can solely scale to date, particularly as accelerators, hooked up reminiscence, and different units shortly eat up ports.
Wrapping issues up, the finished CXL 3.0 customary is being launched to the general public at the moment, the primary day of FMS 2022. Formally, the Consortium doesn’t provide any steering on when to anticipate CXL 3.0 present up in units – that’s as much as tools producers – however it’s cheap to say it is not going to be immediately. With CXL 1.1 hosts simply now transport – by no means thoughts CXL 2.0 hosts – the precise productization of CXL is lagging the requirements by a few years, which is typical for these giant trade interconnect requirements.


{kind=link}