Regardless of how we have a look at it, knowledge consumption is probably one of many central person journeys of any knowledge platform, if not the principle one. Consuming knowledge in some way represents the end result of all of the multi-team efforts put into the platform over time: knowledge ingestion, cataloging, transformation , high quality management or expertise enablement simply to call a number of.
On the finish of the times, knowledge consumption is the ultimate deliverable for knowledge groups.
Paradoxically, knowledge consumption can also be one of many areas that generates extra friction between central IT knowledge groups — the groups chargeable for constructing the information platform and mannequin its contents — and the information shoppers embedded into the enterprise areas — chargeable for consuming the information and producing insights that finally can flip into enterprise worth.
Why is that? On one hand, knowledge shoppers count on a easy and acquainted strategy to entry the information, that must be workable from day one with little to none adaptation efforts. Information must be of their “native” format, the format through which they’re used to work with. And then again, the central IT groups are incentivized to generate a novel and standardized means for knowledge consumption as an alternative of sustaining a rising variety of particular interfaces. As a rule, the usual tends to be closely influenced by the platform underlying expertise, priming expertise simplicity over enterprise customers wants.
The end result tends to be suboptimal for each events, with a barely canonical strategy to entry the information that in the long run requires in depth integration plumbing and transformation downstream within the enterprise areas, producing technical debt for either side.

The Information Mesh paradigm acknowledges and appreciates this pressure and takes a VERY clear place in its decision: it undoubtedly stands up for the information shoppers. Fairly than imposing a standardized strategy to work dictated by expertise, the platform ought to adapt to their person wants and provide the information in essentially the most handy means — evokating a native feeling.
We can’t focus on Information Mesh intimately on this article, however in essence, it means decentralization of knowledge possession — transferring the accountability from a central IT knowledge group to the enterprise areas the place the consumption occurs.
With that precept in thoughts, the answer to the information consumption drawback could be fairly easy: to switch the consumption accountability into the enterprise areas. Below this state of affairs the shoppers themselves will purchase the accountability for producing knowledge interfaces into their most well-liked native format for the information merchandise underneath the enterprise area they personal.
However because the mesh grows so do its inter-domain use circumstances and the necessity for knowledge sharing, so we are able to finish in a undesired state of affairs the place the information interfaces are tightly coupled to the shoppers, limiting and even neglecting knowledge product sharing amongst totally different shoppers.

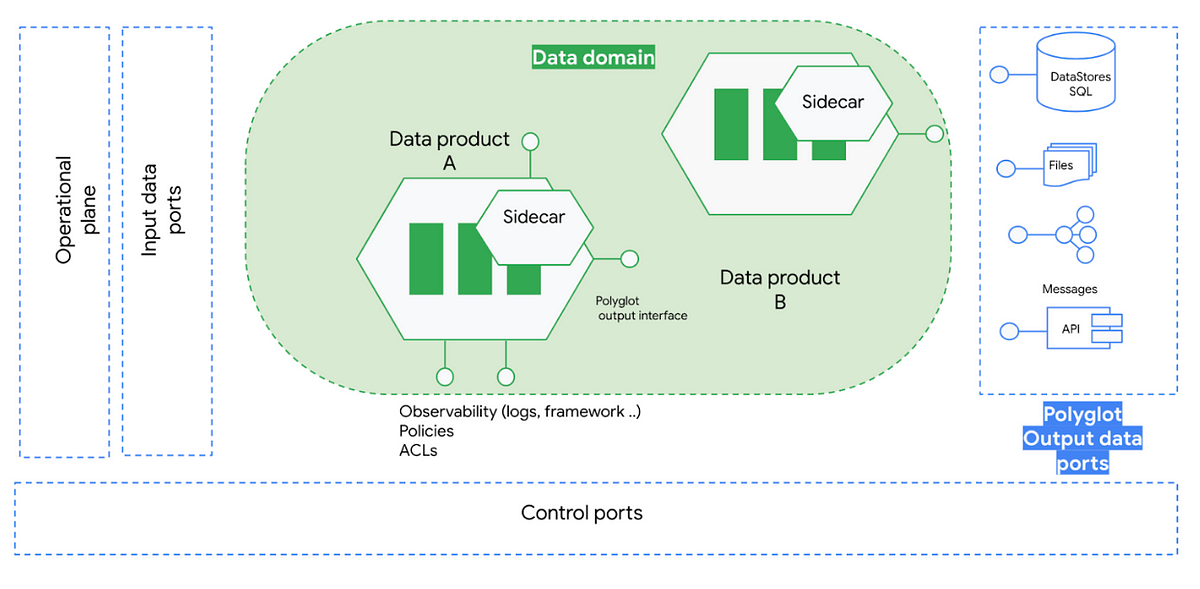
With the last word objective to make sure reusability, knowledge mesh’s reply to this drawback is to introduce the idea of polyglot knowledge, an abstraction to obviously differentiate between the information semantics and the information consumption format/syntax. Below this new state of affairs, the information shoppers may instantiate the information of their prefered format from an inventory of predefined consumption patterns that hopefully cowl all of the potential use circumstances.
In concept, it is a very elegant method with a very clear separation of duties between knowledge semantics and its underlying expertise. However in observe as Information Mesh doesn’t prescribe any type of technical structure, generally it may be very summary and difficult to conceptualize or implement such an answer.
The thought of this text is to current an opinionated expertise structure that implements this polyglot knowledge sample operating in Google Cloud utilizing as many open supply parts as potential.

As an instance these ideas and provides some inspiration, I’ve constructed a simplistic python bundle — not manufacturing prepared! — known as `polyexpose` that orchestrates and streamline knowledge serving with totally different syntaxes making use of various cloud applied sciences like Google Cloud Storage, SPARK, hasura or Google Kubernetes Engine.
The precise use will likely be to bundle this bundle code along with the specified knowledge product after which letting the shoppers select their most well-liked consumption format for the information product.

Who ought to personal this bundle/code?
With Information Mesh, the central knowledge group position shifts from “full knowledge platform management” to a enablement position targeted on “platform engineering”. In my opinion, the important thing accountability of the redefined knowledge group is to construct artifacts/software program/accelerators like ingestion frameworks, observability APIs, coverage execution engines or knowledge high quality engines with the last word objective of enabling generic software program builders within the enterprise areas to totally embrace the data-driven advantages.
Now let’s dig on this knowledge consumption artifact. In an effort to outline the totally different knowledge syntaxes to help, I’ve give you three totally different consumption personas that I imagine are pretty generic and could be present in virtually each group.
- Information analysts — Used to work with SQL as their major knowledge interface
- Information software builders — APIs are the golden commonplace for software builders, thus we must always respect that and provide an API interface to knowledge — GQL. One other frequent sample relies on occasion pushed architectures, so we must always be capable of generate actual time even like knowledge from out knowledge product.
- Information scientists — As a part of the experimentation lifecycle, Information Scientists are used to load plain textual content recordsdata, in my expertise this method is commonly seen seen as an anti-pattern from the IT division lens, however once more, the Information Mesh method acknowledges and celebrates the heterogeneity of knowledge consumption patterns.
With these patterns in thoughts, our knowledge publicity framework ought to help the next knowledge entry mechanisms.
An preliminary technical structure blueprint may seem like this:

Lets now dig in each part:
- Finish person interface: I’ve chosen to bundle the software program right into a python bundle. python is with none doubt the de-facto commonplace for knowledge engineering, giving to our customers a really acquainted interface. Concerning UX, the fundamental workflow of polyxpose is:
# 1 Generates polyexpose shopper
shopper = polyExpose(config.yaml)... # 2 Execute initialization actions (e.g. load catalog)# 3 Choose desk
desk = shopper.get_table("table_name")# 4 Allow publicity mode
EXPOSE_MODE = SQL | GQL | CSV | EVENT
desk.expose_as(EXPOSE_MODE)# 5 Entry knowledge through SQL question, pub/sub shopper, studying CSV or calling a GQL API
For extra detailed info verify this pocket book with and finish to finish run.
- Major knowledge storage: On the very core of the implementation, I’ve chosen Apache Iceberg as the interior desk format for analytic tables. Iceberg is tightly built-in with engines like Spark and brings quite a lot of nice options like schema evolution, time journey, hidden partitioning or scan planning and file filtering. The Iceberg tables are deployed on Google Cloud Storage.
- SQL interface: Since we’re utilizing Iceberg for inside knowledge illustration, SPARK SQL appears to be the default selection for exposing a SQL engine to finish customers. We mainly use a GCP dataproc cluster the place quite a lot of predefined spark templates are already deployed, the SPARK SQL execution is certainly one of them.

- GQL interface: This one is a little more tough to implement as underneath the hood the GQL interface is uncovered utilizing the hasura graphQL engine. On the time of growth, hasura supported backends are Postgres and BigQuery, so when exposing knowledge through the GQL interface there may be and extra step that copies the information from GCS / Iceberg to BigQuery, then utilizing the hasura API we generate a brand new connection to BQ and monitor the information.
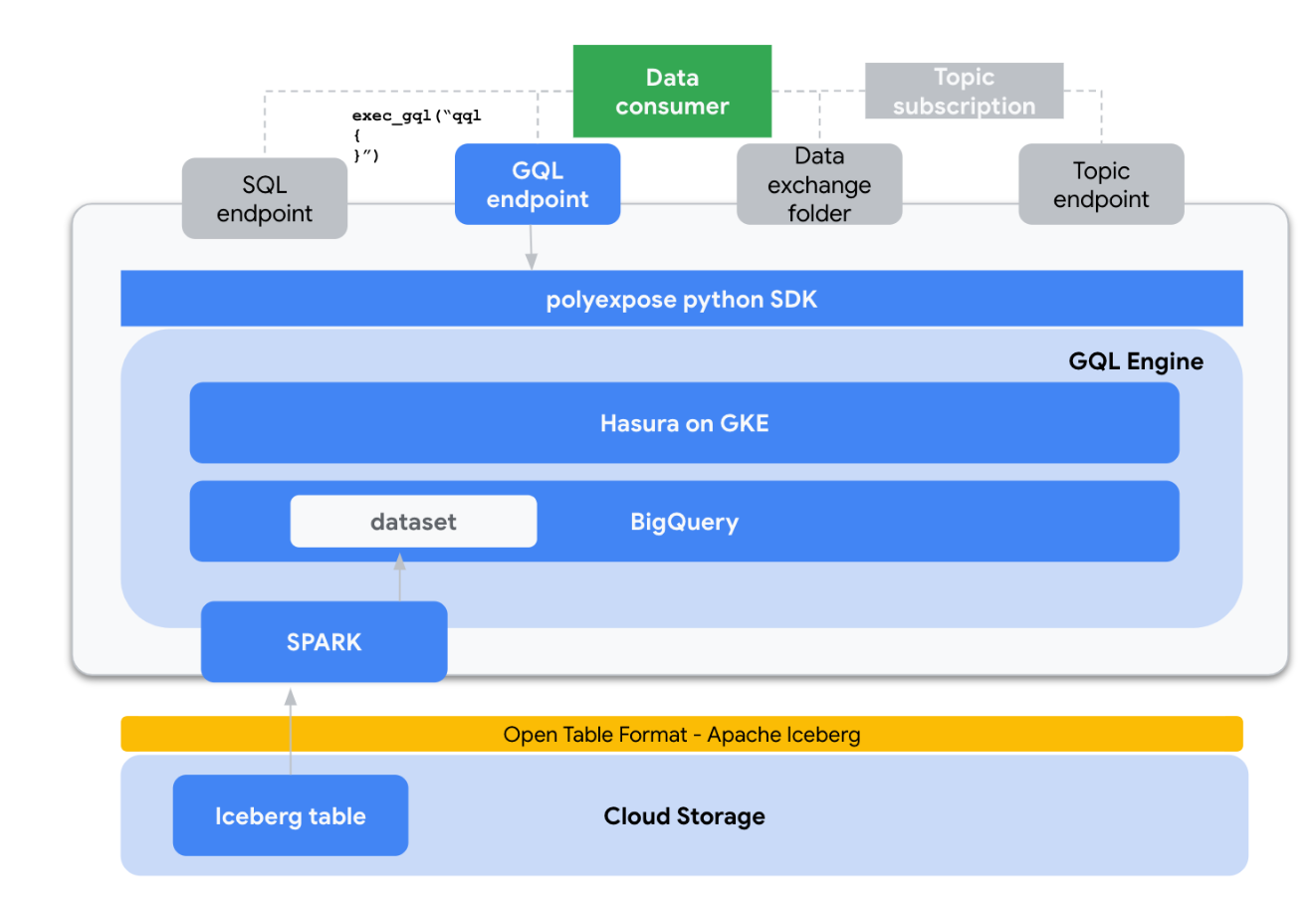
- CSV interface: We simply use SPARK for mutating the information body format, studying the Iceberg Tables and writing in plain CSV additionally in Google Cloud Storage.

- Occasions interface: This expose mode makes use of a pubsublite subject (KAFKA-compatible) together with SPARK Structured streaming to supply the information in an actual time occasion style. It wants the shopper to generate a subscription to the subject.

On this article, we now have explored the challenges related to knowledge consumption in a conventional centralized DWH structure and the way the Information Mesh paradigm proposes an answer: the polyglot knowledge output port abstraction, an important conceptual thought to obviously differentiate between knowledge semantics and technical particulars of its consumption. Then with the target of encourage readers I’ve proven a technical framework known as `polyexpose` for implementing this sample utilizing Google Cloud and open supply parts.
The `polyexpose` repository incorporates JUST an inspirational structure for exposing knowledge in several syntaxes, however it’s removed from being a productive answer, requiring in depth work on safety or entry controls unification simply to call a number of areas. Aside from that, different attention-grabbing areas I’d be taking a look at into the long run are:
- Implementation of knowledge contracts
- Implementation of worldwide insurance policies on totally different applied sciences

{kind=link}