
Diffusion fashions have been gaining reputation prior to now few months. These generative fashions have been in a position to outperform GANs on picture synthesis with lately launched instruments like OpenAI’s DALL.E2 or StabilityAI’s Secure Diffusion and Midjourney.
Just lately, DALL-E launched Outpainting, a brand new characteristic which lets customers increase the unique borders of a picture, including visible parts of the identical fashion by pure language description prompts.
Essentially, era fashions that work on the diffusion technique can generate photos by first randomising the coaching knowledge by including Gaussian noise, after which recovering the info by reversing the noise course of. The diffusion probabilistic mannequin (diffusion mannequin) is a parameterised Markov chain skilled utilizing totally different inferences to provide photos matching the info after a given time.
The genesis
Picture synthesis got here into existence in 2015 when Google Analysis introduced the Tremendous Decision diffusion mannequin (SR3) that would take low-resolution enter photos and use the diffusion mannequin to create high-resolution outputs with out dropping any data. This labored by progressively including pure noise to the high-resolution picture after which progressively eradicating it with the steering of input-low decision picture.
The Class-Conditional Diffusion Mannequin (CDM) is skilled on ImageNet knowledge to create high-resolution photos. These fashions now kind the premise for text-to-image diffusion fashions to supply high-quality photos.
The rise of text-to-image fashions
Launched in 2021, DALL.E2 was developed with the concept of zero-shot studying. On this technique, the text-to-image mannequin is skilled in opposition to billions of photos with their embedded caption. Although the code is just not but open, DALL.E2 was introduced concurrently with CLIP (Contrastive Language-Picture Pre-training) which was skilled on 400 million photos with textual content, scraped instantly from the web.
The identical yr, OpenAI launched GLIDE, which generates photorealistic photos with text-guided diffusion fashions. DALL.E2’s CLIP steering approach can generate various photos however on the stake of excessive constancy. To attain photorealism, GLIDE makes use of classifier-free steering, which provides the flexibility to edit along with zero-shot era.
GLIDE, after coaching on text-conditional diffusion strategies, is fine-tuned for unconditional picture era by changing the coaching textual content token with empty sequences. This fashion the mannequin is ready to retain its capability to generate photos unconditionally together with text-dependent outputs.

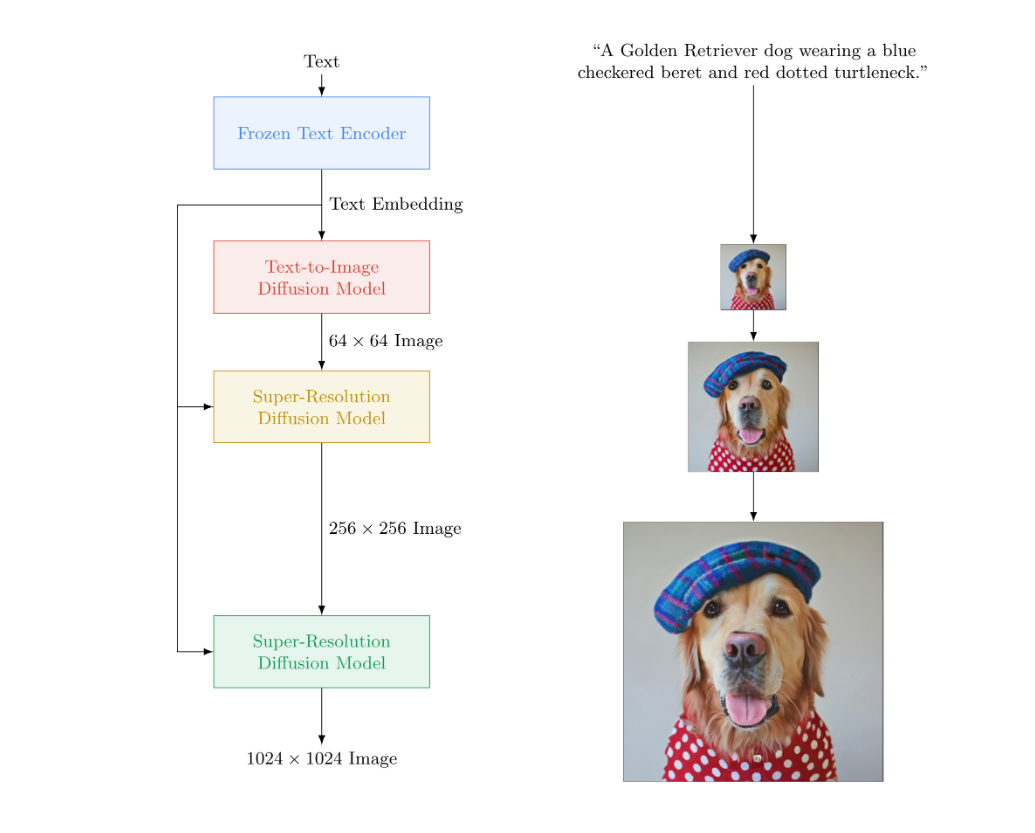
Then again, Google’s Imagen expands on a big transformer language mannequin (LM) and understands textual content to mix it with high-fidelity diffusion fashions like GLIDE, de-noising diffusion probabilistic strategies, and cascaded diffusion fashions. This then leads to the manufacturing of photorealistic photos with deep degree language understanding in text-to-image synthesis.
Just lately, Google expanded on Imagen with DreamBooth, which isn’t only a text-to-image generator however permits add of a set of photos to vary the context. This software analyses the topic of the enter picture, separates it from the context or atmosphere and synthesises it into a brand new desired context with high-fidelity.
Latent Diffusion Fashions, utilized by Secure Diffusion, make use of the same technique to CLIP embedding for era of photos however also can extract data from an enter picture. For instance, an preliminary picture will likely be encoded into an already information-dense area known as the latent area. Much like GAN, this area will extract related data from the area and cut back its measurement whereas conserving as a lot data as attainable.
Now with conditioning, once you enter context, which could be both textual content or photos, and merge them within the latent area together with your enter picture, the mechanism will perceive one of the best ways to mould the picture into the context enter and put together the preliminary noise for the diffusion course of. Much like Imagen, now the method includes decoding the generated noise map to assemble a closing high-resolution picture.
Future good (photos)
Coaching, sampling and evaluating knowledge has allowed diffusion fashions to be extra tractable and versatile. Although there are main enhancements in picture era with diffusion fashions over GANs, VAE, and flow-based fashions, they depend on the Markov chain to generate samples, making it slower.
Whereas OpenAI has been working in direction of the proper image-generation software, there was a large leap within the making of a number of diffusion fashions, the place they use varied strategies to enhance the standard of the output, alongside rising the constancy, whereas decreasing the rendering time. This consists of Google’s Imagen, Meta’s ‘Make-A-Scene’, Secure Diffusion, Midjourney, and so on.
Moreover, diffusion fashions are helpful for knowledge compression since they cut back high-resolution photos on the worldwide web permitting wider accessibility for the viewers. All this can ultimately result in diffusion fashions turning into viable for artistic makes use of in artwork, pictures and music.

{kind=link}