
Be aware: That is an up to date doc primarily based on elements of two older articles.
Occasion-driven structure is a paradigm that enables low coupling between providers—notably in a microservices structure. It removes the necessity for providers to actively find out about one another and question one another utilizing synchronous API’s. This permits us to scale back latency (avoiding “microservice hell”) and make it simpler to alter providers in isolation.
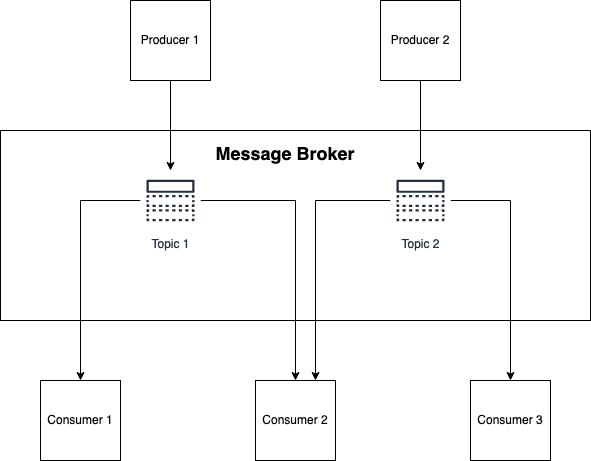
In a nutshell, this method makes use of a message dealer which manages quite a lot of subjects (also called logs or streams). One service produces to a subject, whereas different providers eat from the subject.
Every of those little black bins will doubtless wish to have a few of its personal state as a way to do its work. (Stateless providers do exist, however for one thing to be actually stateless, there are a selection of tradeoffs and ache factors it’s good to handle, and sometimes replicate a extra advanced microservice structure. As a rule, these architectures might be described as a “distributed massive ball of mud.”)
Our aim in introducing a message dealer is to scale back dependencies between these bins. Which means if service A has some info, service B shouldn’t ask service A for that info straight—service A will publish that info into a subject. Service B can then eat the data and reserve it to its personal knowledge retailer or do some work with it.
Ignoring the extra technical challenges with this method on the manufacturing or consuming facet (comparable to marrying the manufacturing of messages with database transactions), what sort of knowledge is helpful to ship by way of subjects? How will we simply and safely transfer our saved knowledge from one service to a different? And what do our subjects and providers appear to be in several conditions?
Let’s begin answering these questions.
Kafkaesque
For the needs of this dialogue, I will probably be utilizing Apache Kafka because the expertise underlying the message dealer in query. Apart from the benefits in issues like its means to scale, get better and course of issues shortly, Kafka has some properties that make its subjects extra helpful than an ordinary easy queue or message bus:
- Messages have keys related to them. These keys can be utilized in compaction methods (which deletes all messages with the identical key apart from the most recent one). That is helpful in upsert subjects, which I’ll talk about extra beneath.
- Messages are solely deleted by compaction or retention settings (e.g. delete any message that’s older than seven days)—they aren’t deleted manually or as quickly as they’re seen.
- Any variety of customers (or fairly, client teams) can learn from the identical matter, and so they every handle their very own offsets.
The upshot of those properties is that messages keep completely within the matter—or till they’re cleaned up by retention or compaction—and act as a report of reality.
Kafka additionally lets you construction your knowledge. You may ship any sort of byte knowledge by way of Kafka, however it’s strongly really helpful to make use of a schema framework comparable to Avro or Protobuf. I’ll go one step additional and advocate that each message in a subject ought to use the identical schema. There are quite a few advantages to this, however that could be a matter for one more article.
With these properties and strongly structured knowledge, we are able to design subjects for every of the next conditions:
- Entity subjects – “that is the present state of X”
- Occasion subjects – “X occurred”
- Request and response subjects” – “Please do X” → “X has been finished”
Entity subjects: The supply of reality
An entity matter is likely one of the most useful methods to make use of Kafka to ferry knowledge between providers. Entity subjects report the present state of an object.
For instance, let’s say you could have a Prospects service which is aware of all about all the purchasers that your organization works with. In a synchronous world, you’d have that service arrange an API so that every one different providers that have to find out about a buyer must question it. Utilizing Kafka, you as an alternative have that service publish to a Prospects matter, which all different providers eat from.
Client providers can dump this knowledge straight into their very own database. The cool factor about this paradigm is that every service can retailer the info nonetheless they like. They will discard fields or columns they don’t care about or map them to completely different knowledge buildings or representations. Most significantly, every service owns its personal knowledge. In case your Orders service must find out about clients, it doesn’t have to ask for it—it already has it proper there in its personal database.

One of many properties of Kafka—the truth that each message has a corresponding key—could be very efficient in enabling one of these matter. You set the important thing to no matter identifier you want for that buyer—an ID of some type. Then you possibly can depend on Kafka to guarantee that ultimately, you’re solely going to see a single report for the client with that ID: probably the most up-to-date model of the client.
One other property—partitioning—ensures that order is assured for any message with the identical key. This implies you can by no means eat messages out of order, so any time you see that buyer, for a proven fact that it’s the most recent model of that buyer you’ve but seen.
Shoppers can upsert the client into the database—insert it if it doesn’t exist, replace it if it does. Kafka even has a conference to indicate deletions: a message with a key however a null payload, also called a tombstone. This means that the report must be deleted. Because of compaction, all non-tombstone messages will ultimately disappear, leaving nothing however the deletion report (and that may be auto-compacted as properly).
As a result of entity subjects characterize an exterior view into state owned by an present service, you possibly can export as little info as you want. You may at all times improve that info in a while by including fields to the exported knowledge and re-publishing it. (Deleting fields is more durable, because you’d must comply with up with all customers of the info to see in the event that they’re truly utilizing these fields.)
Entity subjects are nice, however include one giant caveat: They supply eventual consistency. As a result of subjects are asynchronous, you might be by no means assured that what you could have in your database matches precisely with the producer’s database—it may be seconds and even minutes old-fashioned in case your dealer is experiencing slowdown. In the event you:
- want your knowledge to be 100% correct on the time of utilization, or
- it’s good to collate info from a couple of supply and each sources have hyperlinks that should match completely,
then utilizing asynchronous processing is probably going not what you need: it’s good to depend on good previous API queries.
Occasion subjects: Report of reality
Occasion subjects are a very completely different beast from entity subjects. Occasion subjects point out {that a} explicit factor occurred. Slightly than offering probably the most up-to-date model of a specific piece of knowledge, occasion subjects present a “dumb” report of the issues that occurred to it.
(Be aware that I’m not going to cowl occasion sourcing, which makes use of occasions to reconstruct the state of a report. I discover that sample to be of area of interest use in particular contexts, and I’ve by no means used it in manufacturing.)
Occasions are primarily used for 2 causes:
- Acquire details about consumer or software conduct. This typically powers analytics and guide or automated choice making.
- Fireplace off some activity or perform when a specific occasion happens. That is the idea of a choreography structure—a decentralized design the place every system solely is aware of its personal inputs.
Versus entity subjects, occasion subjects can solely seize what occurs on the precise second it occurs. You may’t arbitrarily add info to it as a result of that info could have modified. For instance, if you wish to later add a buyer’s handle to an order occasion, you’d actually need to cross-reference the handle on the time the occasion occurred, which is often way more work than it’s value.
To restate that, entity subjects ought to have as few fields as potential, because it’s comparatively straightforward so as to add them and arduous to delete them. Conversely, occasion subjects ought to have as many fields as you may suppose are ultimately obligatory, as a result of you possibly can’t append info after the actual fact.
Occasion subjects don’t want message keys as a result of they don’t characterize an replace to the identical object. They need to be partitioned accurately, although, since you’ll doubtless wish to work on occasions that occurred to the identical report so as.
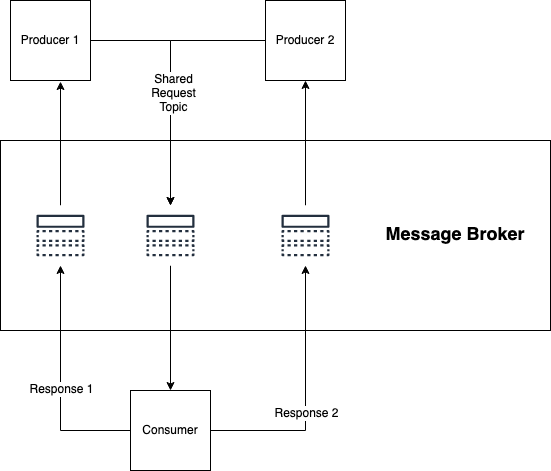
Request and response subjects: Async API
Request and response subjects are kind of what they sound like:
- A shopper sends a request message by way of a subject to a client;
- The patron performs some motion, then returns a response message by way of a subject again to the buyer.
This sample is rather less usually helpful than the earlier two. On the whole, this sample creates an orchestration structure, the place a service explicitly tells different providers what to do. There are a few the reason why you may wish to use subjects to energy this as an alternative of synchronous APIs:
- You wish to preserve the low coupling between providers {that a} message dealer provides us. If the service that’s doing the work ever modifications, the manufacturing service doesn’t have to find out about it, because it’s simply firing a request into a subject fairly than straight asking a service.
- The duty takes a very long time to complete, to the purpose the place a synchronous request would typically outing. On this case, it’s possible you’ll resolve to utilize the response matter however nonetheless make your request synchronously.
- You’re already utilizing a message dealer for many of your communication and wish to make use of the present schema enforcement and backwards compatibility which can be mechanically supported by the instruments used with Kafka.
One of many downsides of this sample is that you simply don’t get a right away response as as to if the request was profitable—or no less than efficiently acquired. Usually in a “do some motion” scenario, this info is absolutely useful to know instantly, particularly if it’s in a logical transaction of some type.
In the event you do use this sample, you’d doubtless change up the conventional sample of Kafka structure and have a number of producers with a single client. On this case the client owns the schema, not the producer, which is a non-obvious manner of working.
Becoming a member of and enhancing subjects
A standard use case for microservices is to be part of two subjects collectively or improve an present matter with further info. At Flipp, for instance, we could have a subject that incorporates product info and one other matter that provides a class to the product primarily based on some enter.
There are present instruments that assist with these use instances, comparable to Kafka Streams. These have their makes use of, however there are a lot of pitfalls concerned with utilizing them:
- Your subjects will need to have the identical key schema. Any change to the important thing schema could require re-partitioning, which may be costly.
- Your subjects must be roughly of equal throughput—if both matter has a lot bigger or has many extra messages than the opposite, you might be caught with the worst of each subjects. You may find yourself becoming a member of a “small, quick” matter (a lot of updates, small messages) with a “giant, gradual” one (fewer updates, greater messages) and must output a “giant, quick” matter, which may destroy your downstream providers.
- You might be basically doubling your knowledge utilization each time you remodel one matter into one other one. Though you get some great benefits of a much less stateful service, you pay the worth in load in your brokers and one more hyperlink in a sequence that may be damaged.
- The internals of those providers may be opaque and obscure. For instance, by default they use Kafka itself as its inner state, leading to extra pressure on the message dealer and plenty of non permanent subjects.
At Flipp, we now have began shifting away from utilizing Kafka Streams and like utilizing partial writes to knowledge shops. If subjects must be joined, we use a instrument like Deimos to make it straightforward to dump the whole lot to a neighborhood database after which produce them once more utilizing no matter schema and cadence is sensible.
Conclusion
Message brokers and subjects are a wealthy method to develop your structure, scale back dependencies, and enhance security and scalability. Designing your techniques and subjects is a non-trivial activity, and I’ve offered some patterns that I’ve discovered helpful. Like the whole lot else, they aren’t meant for use in each single scenario, however there are various instances the place utilizing them will make for a extra sturdy, performant and maintainable structure.
Tags: event-driven architectures, kafka, message brokers, subjects

{kind=link}