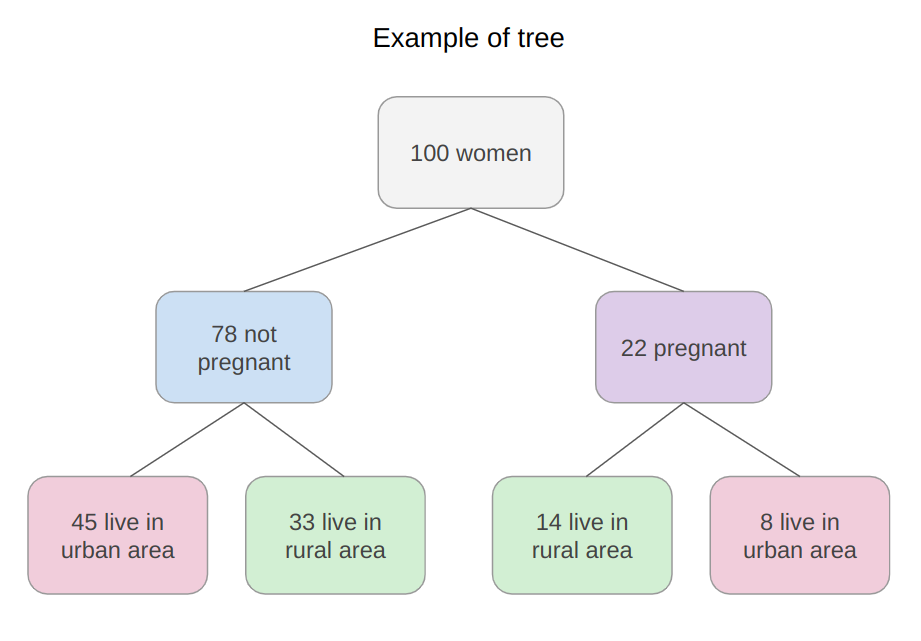
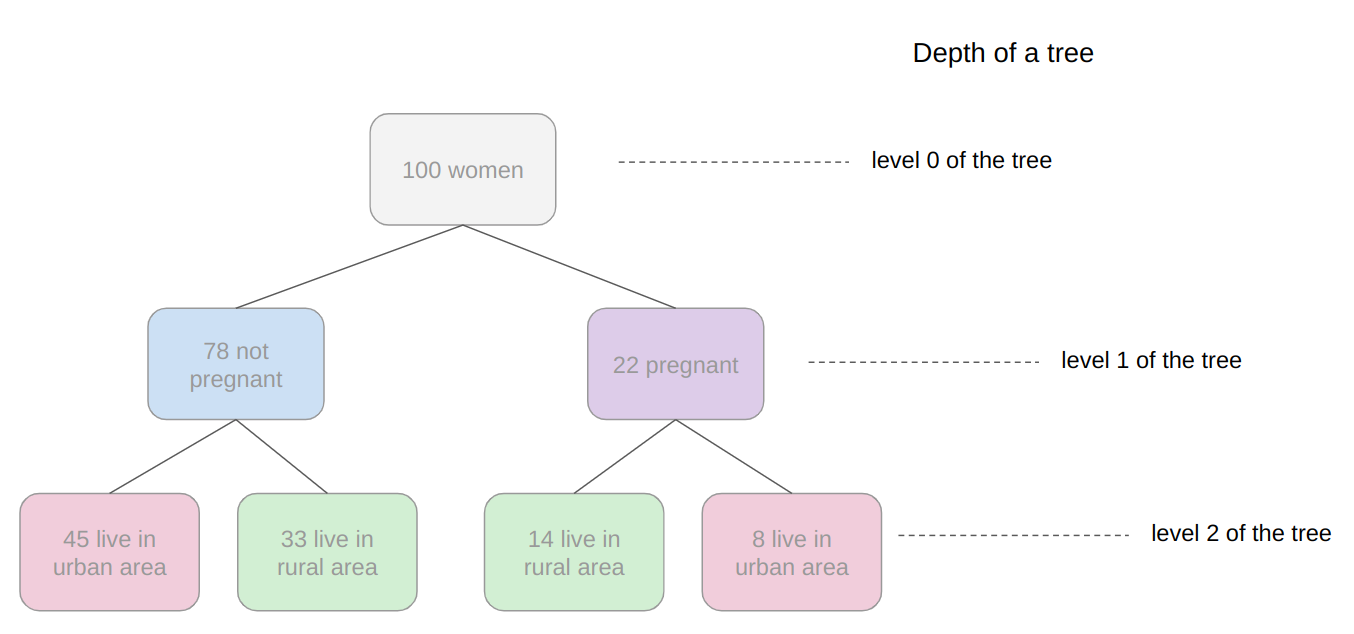
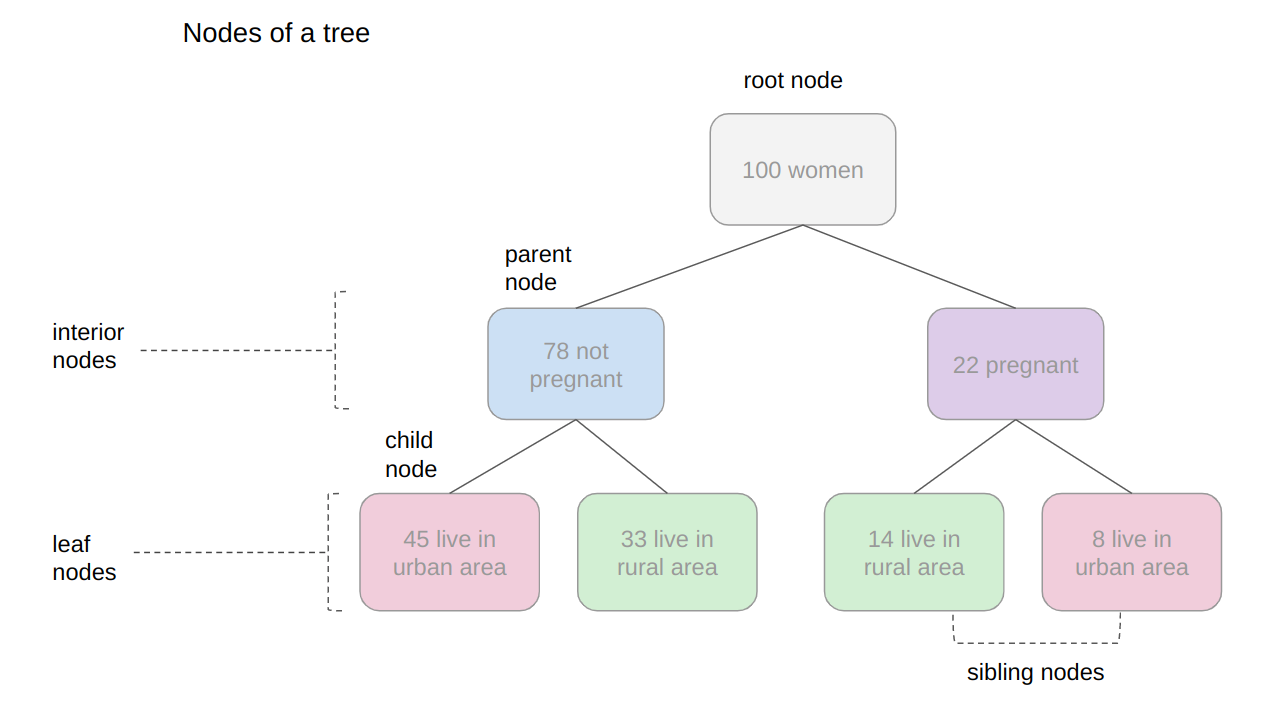
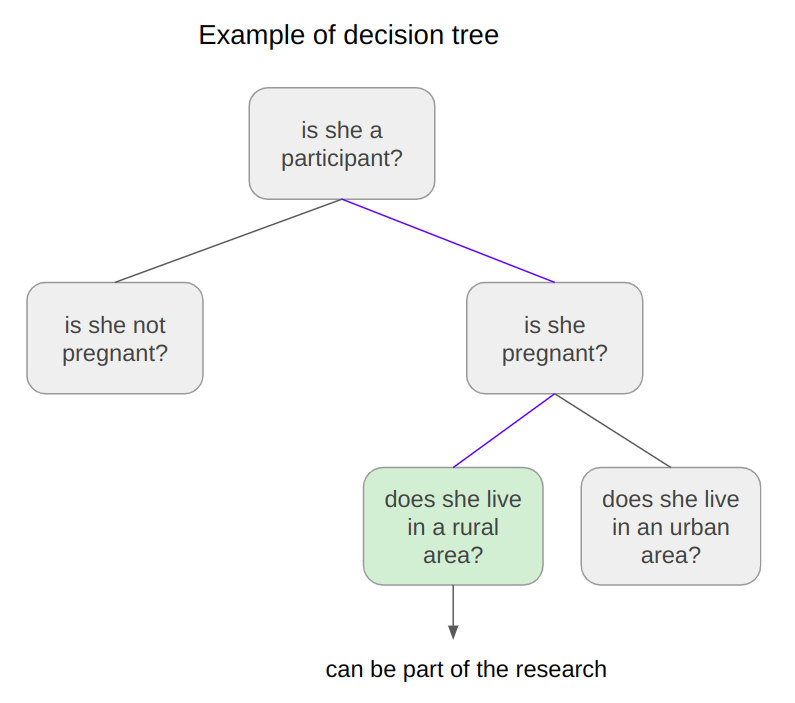
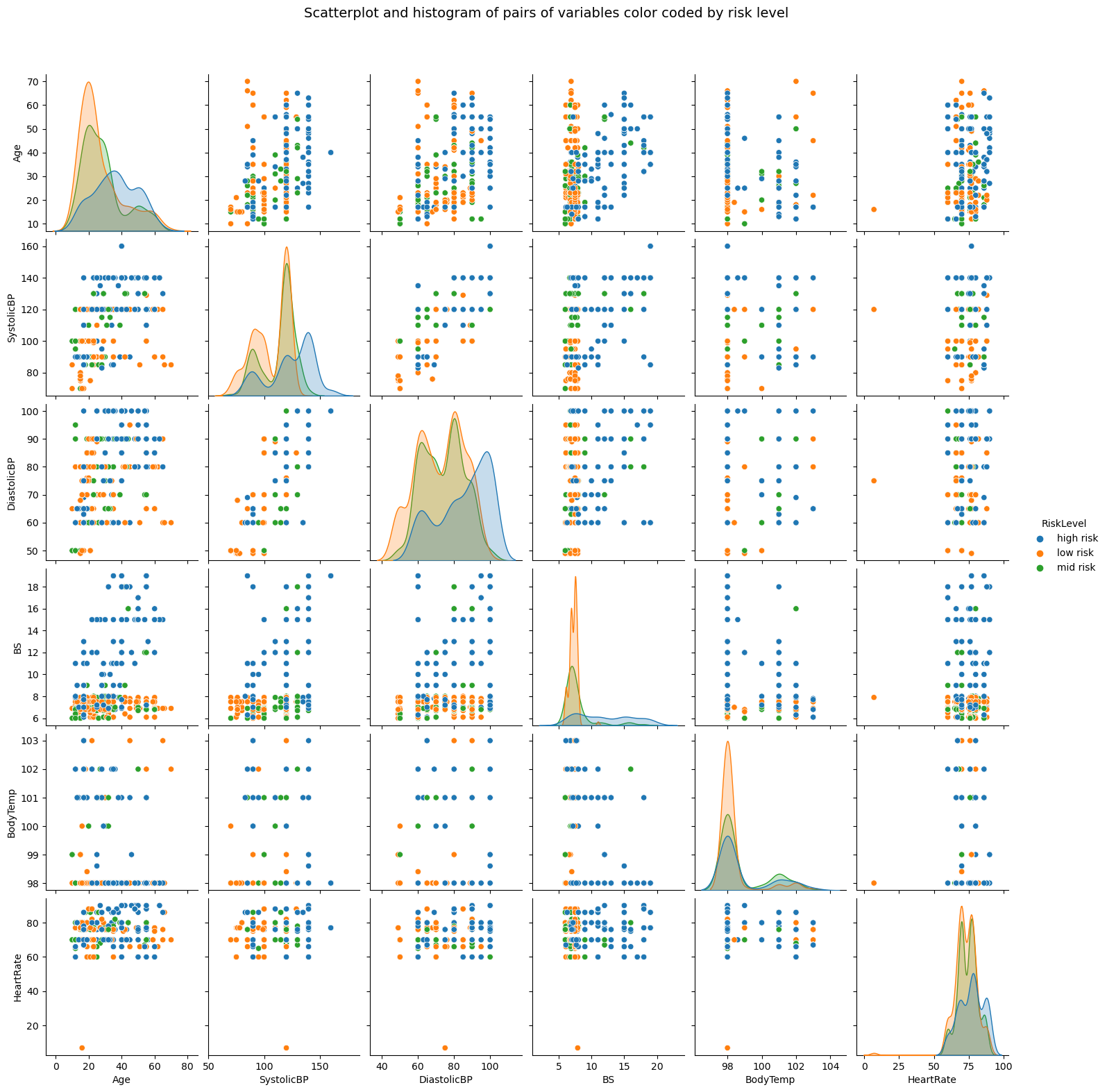
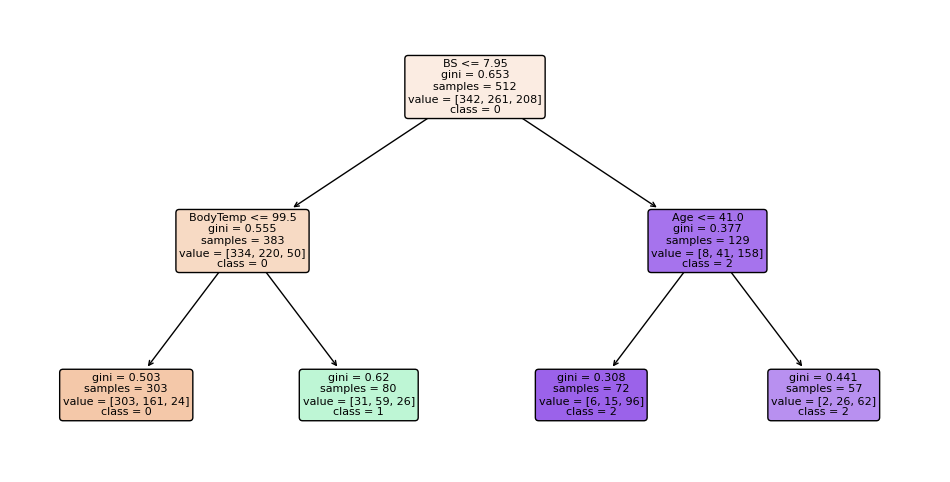
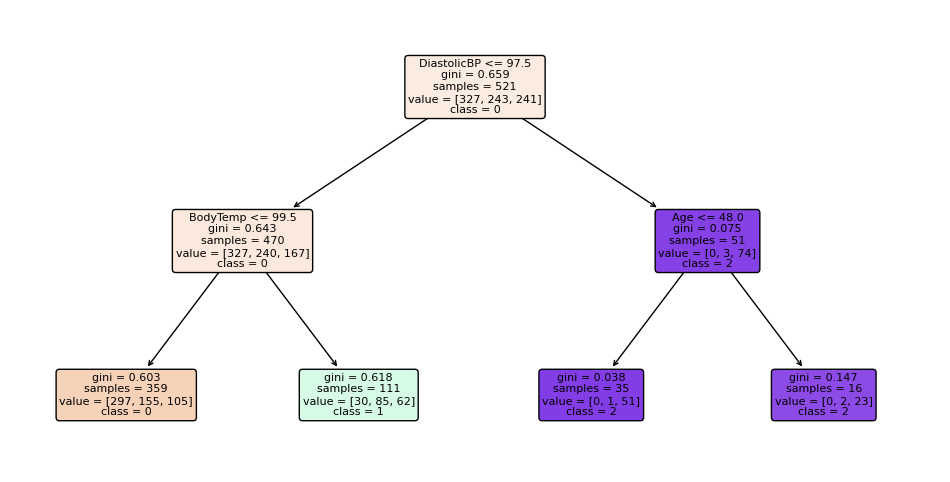
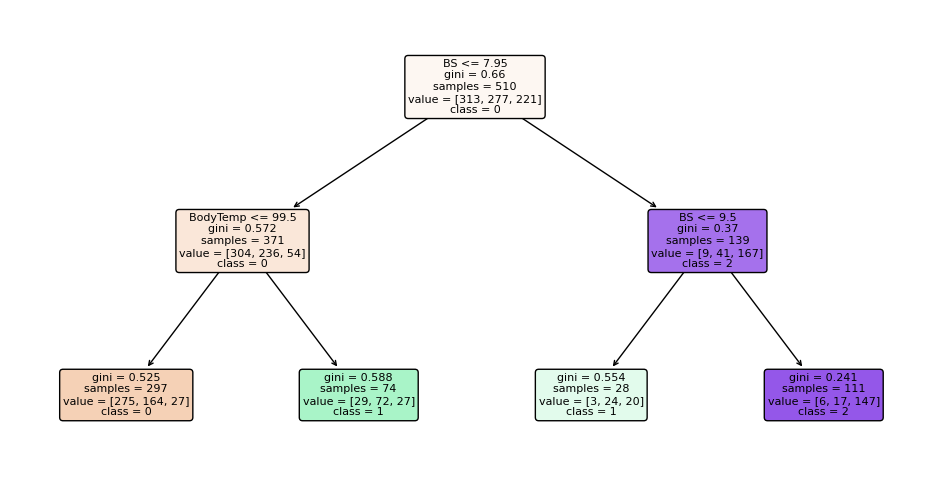
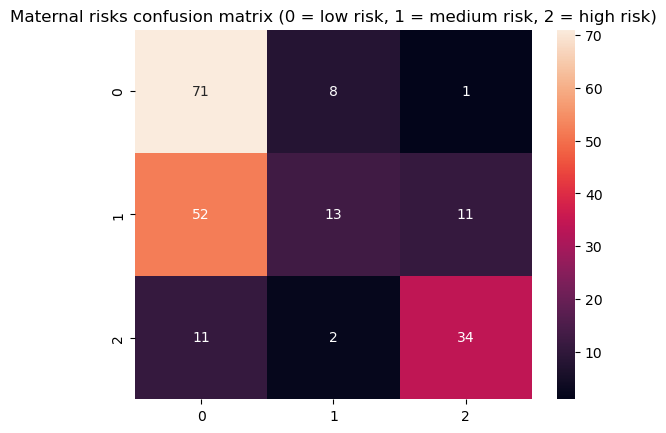
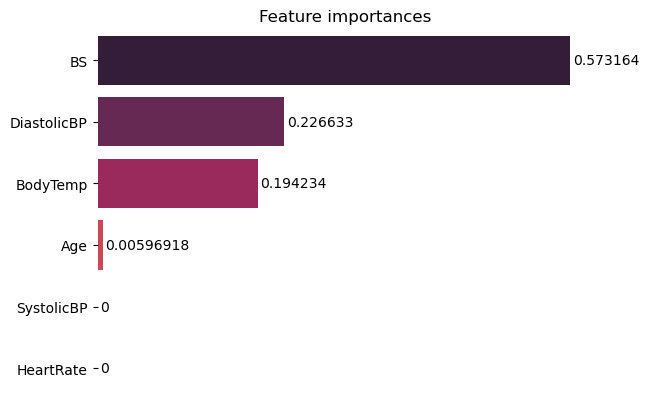
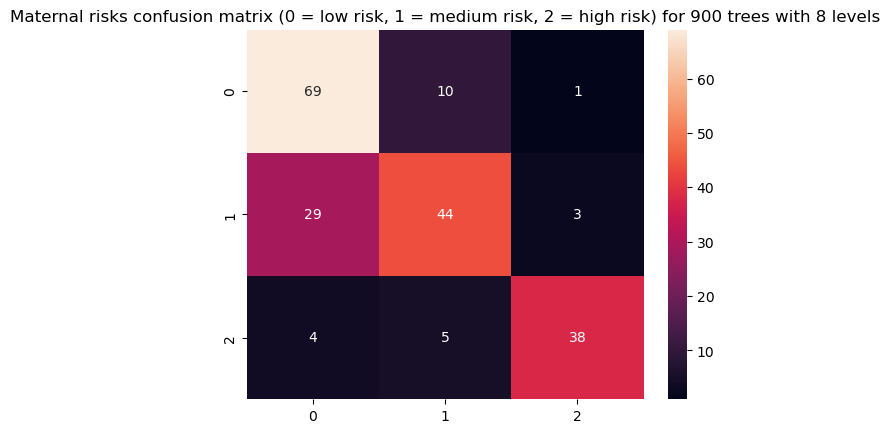
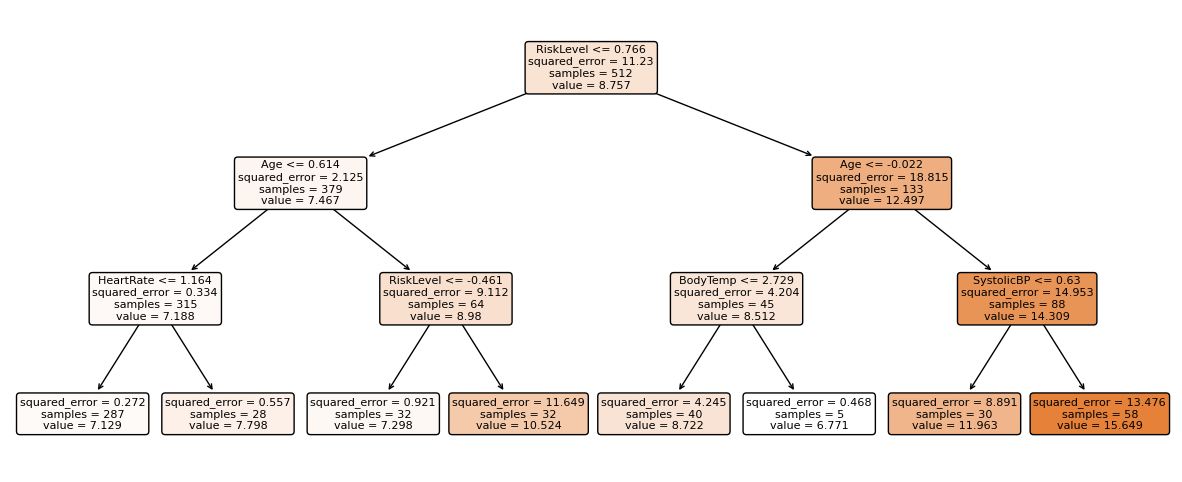
Sign in Welcome! Log into your account your username your password Forgot your password? Get help Password recovery Recover your password your email A password will be e-mailed to you. HomeProgrammingDefinitive Information to the Random Forest Algorithm with Python and Scikit-Be taught Programming Definitive Information to the Random Forest Algorithm with Python and Scikit-Be taught By Admin November 28, 2022 0 2 Share FacebookTwitterPinterestWhatsApp Introduction The Random Forest algorithm is likely one of the most versatile, highly effective and widely-used algorithms for classification and regression, constructed as an ensemble of Choice Timber. When you aren’t acquainted with these – no worries, we’ll cowl all of those ideas. On this in-depth hands-on information, we’ll construct an instinct on how resolution bushes work, how ensembling boosts particular person classifiers and regressors, what random forests are and construct a random forest classifier and regressor utilizing Python and Scikit-Be taught, via an end-to-end mini-project, and reply a analysis query. Think about that you just’re are at present a part of a analysis group that’s analysing knowledge about ladies. The group has collected 100 knowledge data and desires to have the ability to arrange these preliminary data by dividing the ladies into classes: being or not pregnant, and residing in rural or city areas. The researchers wish to perceive what number of ladies could be in every class. There’s a computational construction that does precisely that, it’s the tree construction. By utilizing a tree construction, it is possible for you to to characterize the totally different divisions for every class. Choice Timber How do you populate the nodes of a tree? That is the place resolution bushes come into focus. First, we will divide the data by being pregnant, after that, we will divide them by residing in city or rural areas. Discover, that we may do that in a distinct order, dividing initially by what space the ladies reside and after by their being pregnant standing. From this, we will see that the tree has an inherent hierarchy. In addition to organizing info, a tree organizes info in a hierarchical method – the order that the data seems issues and results in totally different bushes because of this. Under, is an instance of the tree that has been described: Within the tree picture, there are 7 squares, the one on prime that accounts for the entire of 100 womem, this prime sq. is related with two squares under, that divide the ladies primarily based on their variety of 78 not pregnant and 22 pregnant, and from each earlier squares there are 4 squares; two related to every sq. above that divide the ladies primarily based on their space, for the not pregnant, 45 reside in an city space, 33 in a rural space and for the pregnant, 14 reside in a rural space and eight in an city space. Simply by wanting a the tree, it’s straightforward to grasp these divisions and see how every “layer” is derived from earlier ones, these layers are the tree ranges, the degrees describe the depth of the tree: Observe within the picture above that the primary tree degree is degree 0 the place there is just one sq., adopted by degree 1 the place there are two squares, and degree 2 the place there are 4 squares. It is a depth 2 tree. In degree 0 is the sq. that originates the tree, the primary one, known as root node, this root has two little one nodes in degree 1, which might be father or mother nodes to the 4 nodes in degree 2. See that the “squares” we have now been mentioning to this point, are literally known as nodes; and that every earlier node is a father or mother to the next nodes, which might be its kids. The kid nodes of every degree which have the identical father or mother are known as siblings, as will be seen within the subsequent picture: Within the earlier picture, we additionally show the extent 1 as being the inside nodes, as soon as they’re between the basis and the final nodes, that are the leaf nodes. The leaf nodes are the final a part of a tree, if we had been to say from the 100 preliminary ladies, what number of are pregnant and residing in rural areas, we may do that by wanting on the leaves. So the quantity on the leaves would reply the primary analysis query. If there have been new data of ladies, and the tree that was beforehand used to categorize them, was now used to resolve if a lady may or could not be a part of the analysis, wouldn’t it nonetheless perform? The tree would use the identical standards, and a lady could be ellegible to take part if pregnant and residing in a rural space. By wanting on the picture above, we will see that the solutions to the questions of every tree node – “is she a participant?”, “is she pregnant?”, “does she reside in a rural space?”- are sure, sure, and sure, so it appears that evidently the tree can ideed result in a call, on this case, that the girl may participate within the analysis. That is the essense of resolution bushes in, accomplished in a guide method. Utilizing Machine Studying, we will assemble a mannequin that constructs this tree routinely for us, in such a strategy to maximize the accuracy of the ultimate choices. Notice: there are a number of kinds of bushes in Laptop Science, corresponding to binary bushes, basic bushes, AVL bushes, splay bushes, purple black bushes, b-trees, and so on. Right here, we’re specializing in giving a basic thought of what’s a call tree. If it is determined by the reply of a sure or no query for every node and thus every node has at most two kids, when sorted in order that the “smaller” nodes are on the left, this classifies resolution bushes as binary bushes. Within the earlier examples, observe how the tree may both classify new knowledge as participant or non participant, or the questions may be modified to – “what number of are members?”, “what number of are pregnant?”, “what number of reside in a rural space?”- main us to search out the amount of pregnant members that reside in a rural space. When the info is assessed, this implies the tree is performing a classification process, and when the amount of knowledge is discovered, the tree is performing a regression process. Which means the choice tree can be utilized for each duties – classification and regression. Now that we perceive what a call tree is, how can or not it’s used, and what nomenclature is used to explain it, we will marvel about its limitations. Understanding Random Forests What occurs to the choice if some participant lives on the division between city and rural areas? Would the tree add this document to rural or city? It appears arduous to suit this knowledge into the construction we at present have, because it’s pretty clear lower. Additionally, what if a lady that lives on a ship participates within the analysis, wouldn’t it be thought of rural or city? In the identical means because the earlier case, it’s a challeging knowledge level to categorise contemplating the obtainable choices within the tree. By pondering a bit extra in regards to the resolution tree instance, we’re in a position to see it may well appropriately classify new knowledge contemplating it already follows a sample the tree already has – however when there are data that differ from the preliminary knowledge that outlined the tree, the tree construction is just too inflexible, making the data not classifiable. Which means the choice tree will be strict and restricted in its prospects. A super resolution tree could be extra versatile and in a position to accomodate extra nuanced unseen knowledge. Resolution: Simply as “two pairs of eyes see higher than one”, two fashions sometimes provide you with a extra correct reply than one. Accounting for the variety in data representations (encoded within the tree construction), the rigidity of the sligtly totally different constructions between a number of related bushes aren’t as limiting anymore, because the shortcomings of 1 tree will be “made up for” by one other. By combining many bushes collectively, we get a forest. Relating to the reply to the preliminary query, we already know that it will likely be encoded within the tree leaves – however what adjustments when we have now many bushes as a substitute of 1? If the bushes are mixed for a classification, the end result will likely be outlined by nearly all of solutions, that is known as majority voting; and within the case of a regression, the quantity given by every tree within the forest will likely be averaged. Ensemble Studying and Mannequin Ensembles This technique is called ensemble studying. When empliying ensemble studying, you’ll be able to combine any algorithms collectively, so long as you’ll be able to make sure that the output will be parsed and mixed with different outputs (both manually, or utilizing present libraries). Usually, you ensemble a number of fashions of the identical sort collectively, corresponding to a number of resolution bushes, however you are not restricted to only be a part of same-model sort ensembles. Ensembling is a virtually assured strategy to generalize higher to an issue, and to squeeze out a slight efficiency increase. In some circumstances, ensembling fashions yields a vital improve in predictive energy, and generally, simply slight. This is determined by the dataset you are coaching and evaluating on, in addition to the fashions themselves. Becoming a member of resolution bushes collectively yields vital efficiency boosts compred to particular person bushes. This method was popularized within the analysis and utilized machine studying communities, and was so widespread that the ensemble of resolution bushes was colloquially named a forest, and the widespread sort of forest that was being created (a forest of resolution bushes on a random subset of options) popularized the title random forests. Given wide-scale utilization, libraries like Scikit-Be taught have applied wrappers for RandomForestRegressors and RandomForestClassifiers, constructed on prime of their very own resolution tree implementations, to permit researchers to keep away from constructing their very own ensembles. Let’s dive into random forests! How the Random Forest Algorithm Works? The next are the fundamental steps concerned when executing the random forest algorithm: Decide numerous random data, it may be any quantity, corresponding to 4, 20, 76, 150, and even 2.000 from the dataset (known as N data). The quantity will rely upon the width of the dataset, the broader, the bigger N will be. That is the place the random half within the algorithm’s title comes from! Construct a call tree primarily based on these N random data; In keeping with the variety of bushes outlined for the algorithm, or the variety of bushes within the forest, repeat steps 1 and a pair of. This generates extra bushes from units of random knowledge data; After step 3, comes the ultimate step, which is predicting the outcomes: In case of classification: every tree within the forest will predict the class to which the brand new document belongs. After that, the brand new document is assigned to the class that wins the bulk vote. In case of regression: every tree within the forest predicts a worth for the brand new document, and the ultimate prediction worth will likely be calculated by taking a mean of all of the values predicted by all of the bushes within the forest. Every tree match on a random subset of options will essentially haven’t any data of another options, which is rectified by ensembling, whereas holding the computational value decrease. Recommendation: Since Random Forest use Choice Timber as a base, it is extremely useful to grasp how Choice Timber work and have some observe with them individually to construct an instinct on their construction. When composing random forests, you will be setting values corresponding to the utmost depth of a tree, the minimal variety of sampels required to be at a leaf node, the factors to guess decide inside splits, and so on. to assist the ensemble higher match a dataset, and generalize to new factors. In observe, you will sometimes be utilizing Random Forests, Gradient Boosting or Excessive Gradient Boosting or different tree-based methodologies, so having a superb grasp on the hyperparameters of a single resolution tree will assist with constructing a robust instinct for tuning ensembles. With an instinct on how bushes work, and an understanding of Random Forests – the one factor left is to observe constructing, coaching and tuning them on knowledge! Constructing and Coaching Random Forest Fashions with Scikit-Be taught There was a purpose for the examples used to this point contain being pregnant, residing space and girls. In 2020, researchers from Bangladesh seen that the mortality amongst pregnant ladies was nonetheless very excessive, specifically contemplating ones that reside in rural areas. Due to that, they used an IOT monitoring system to analyse the danger of maternal well being. The IOT system collected knowledge from totally different hospitals, neighborhood clinics, and maternal well being cares from the agricultural areas of Bangladesh. The collected knowledge was then organized in a comma-separated-value (csv) file and uploaded to UCI’s machine studying repository. That is the info that we are going to use to observe and attempt to perceive if a pregnant lady has a low, medium or excessive threat of mortality. Notice: you’ll be able to obtain the dataset right here. Utilizing Random Forest for Classification Since we wish to know if lady has a low, medium or excessive threat of mortality, this implies we’ll carry out a classification with three courses. When an issue has greater than two courses, it’s known as a multiclass drawback, versus a binary drawback (the place you select between two courses, sometimes 0 and 1). On this first instance, we’ll implement a multiclass classification mannequin with a Random Forest classifier and Python’s Scikit-Be taught. We are going to observe the standard machine studying steps to unravel this drawback, that are loading libraries, studying the info, abstract statistics and creating knowledge visualizations to raised perceive it. Then, preprocessing and splitting the info adopted by producing, coaching and evaluating a mannequin. Importing Libraries We’ll be utilizing Pandas to learn the info, Seaborn and Matplotlib to visualise it, and NumPy for the good utility strategies: import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt Importing the Dataset The next code imports the dataset and hundreds it right into a python DataFrame: dataset = pd.read_csv("../../datasets/random-forest/maternal_health_risk.csv") To have a look at the primary 5 traces of the info, we execute the head() command: dataset.head() This outputs: Age SystolicBP DiastolicBP BS BodyTemp HeartRate RiskLevel 0 25 130 80 15.0 98.0 86 excessive threat 1 35 140 90 13.0 98.0 70 excessive threat 2 29 90 70 8.0 100.0 80 excessive threat 3 30 140 85 7.0 98.0 70 excessive threat 4 35 120 60 6.1 98.0 76 low threat Right here we will see all of the attributes collected throughout the analysis. Age: ages in years. SystolicBP: higher worth of Blood Strain in mmHg, a big attribute throughout being pregnant. DiastolicBP: decrease worth of Blood Strain in mmHg, one other vital attribute throughout being pregnant. BS: blood glucose ranges by way of a molar focus, mmol/L. HeartRate: resting coronary heart charge in beats per minute. RiskLevel: threat degree throughout being pregnant. BodyTemp: the physique temperature. Now that we perceive extra about what’s being measured, we will have a look at the kinds of knowledge with data(): dataset.data() This leads to: <class 'pandas.core.body.DataFrame'> RangeIndex: 1014 entries, 0 to 1013 Information columns (complete 7 columns): # Column Non-Null Depend Dtype --- ------ -------------- ----- 0 Age 1014 non-null int64 1 SystolicBP 1014 non-null int64 2 DiastolicBP 1014 non-null int64 3 BS 1014 non-null float64 4 BodyTemp 1014 non-null float64 5 HeartRate 1014 non-null int64 6 RiskLevel 1014 non-null object dtypes: float64(2), int64(4), object(1) reminiscence utilization: 55.6+ KB From wanting on the RangeIndex line, we will see that there are 1014 data, and the column Non-Null Depend informs that the info would not have any lacking values. This implies, we can’t have to make any therapy for lacking knowledge! Within the Dtype column, we will see the kind of every variable. Presently, float64 columns such BS and BodyTemp have numerical values that will range in any vary, corresponding to 15.0, 15.51, 15.76, 17.28, making them numerically steady (you’ll be able to at all times add a 0 to a floating level quantity, advert infinitem). Then again, variables corresponding to Age, SystolicBP, DiastolicBP, and HeartRate are of the sort int64, which means that the numbers solely change by the unit, corresponding to 11, 12, 13, 14 – we can’t have a coronary heart charge of 77.78, it’s both 77 or 78 – these are numerically discrete values. And we even have RiskLevel with a object sort, this often signifies that the variable is a textual content, and we’ll in all probability want to rework it right into a quantity. For the reason that threat degree grows from low to excessive, there’s an implied order within the classes, this means it’s a categorically ordinal variable. Notice: you will need to have a look at the kind of every knowledge, and see if it is sensible in response to its context. As an example, it would not make sense to have half of a coronary heart charge unit, so this implies the interger sort is ample for a discrete worth. When that does not occur, you’ll be able to change the kind of the info with Pandas’ astype() propety – df['column_name'].astype('sort'). After knowledge sorts, we will use describe() to take a peak at some descriptive statistics, such because the imply values of every column, the usual deviation, quantiles, minimal and most knowledge values: dataset.describe().T The above code shows: depend imply std min 25% 50% 75% max Age 1014.0 29.871795 13.474386 10.0 19.0 26.0 39.0 70.0 SystolicBP 1014.0 113.198225 18.403913 70.0 100.0 120.0 120.0 160.0 DiastolicBP 1014.0 76.460552 13.885796 49.0 65.0 80.0 90.0 100.0 BS 1014.0 8.725986 3.293532 6.0 6.9 7.5 8.0 19.0 BodyTemp 1014.0 98.665089 1.371384 98.0 98.0 98.0 98.0 103.0 HeartRate 1014.0 74.301775 8.088702 7.0 70.0 76.0 80.0 90.0 RiskLevel 1014.0 0.867850 0.807353 0.0 0.0 1.0 2.0 2.0 Discover that for many columns, the imply values are removed from the normal deviation (std) – this means that the info would not essentially observe a effectively behaved statistical distribution. If it did, it will’ve helped the mannequin when predicting the danger. What will be accomplished right here is to preprocess the info to make it extra consultant as if it had been knowledge from the entire world inhabitants, or extra normalized. However, a bonus when utilizing Random Forest fashions for classification, is that the inherent tree construction can deal effectively with knowledge that has not been normalized, as soon as it divides it by the worth in every tree degree for every variable. Additionally, as a result of we’re utilizing bushes and that the ensuing class will likely be obtained by voting, we aren’t inherently evaluating between totally different values, solely between identical kinds of values, so adjusting the options to the identical scale is not vital on this case. Which means the Random Forest classification mannequin is scale invariant, and also you needn’t carry out function scaling. On this case, the step in knowledge preprocessing we will take is to rework the explicit RiskLevel column right into a numerical one. Visualizing the Information Earlier than reworking RiskLevel, let’s additionally shortly visualize the info by wanting on the mixtures of factors for every pair of options with a Scatterplot and the way the factors are distributed by visualizing the histogram curve. To try this, we’ll use Seaborn’s pairplot() which mixes each plots. It generates each plots for every function mixture and shows the factors shade coded in response to their threat degree with the hue property: g = sns.pairplot(dataset, hue='RiskLevel') g.fig.suptitle("Scatterplot and histogram of pairs of variables shade coded by threat degree", fontsize = 14, y=1.05); The above code generates: When wanting on the plot, the best state of affairs could be to have a transparent separation between curves and dots. As we will see, the three kinds of threat courses are largely blended up, since bushes internally draw traces when delimiting the areas between factors, we will hypothesize that extra bushes within the forest may be capable to restrict extra areas and higher classify the factors. With the fundamental exploratory knowledge evaluation accomplished, we will preprocess the RiskLevel column. Information Preprocessing for Classification To make sure there are solely three courses of RiskLevel in our knowledge, and that no different values have been added erroneously, we will use distinctive() to show the column’s distinctive values: dataset['RiskLevel'].distinctive() This outputs: array(['high risk', 'low risk', 'mid risk'], dtype=object) The courses are checked, now the subsequent step is to rework every worth right into a quantity. Since there’s an order between classifications, we will use the values 0, 1 and a pair of to suggest low, medium and excessive dangers. There are various methods to vary the column values, following Python’s easy is healthier that complicated motto, we’ll use the .exchange() technique, and easily exchange them with their integer representations: dataset['RiskLevel'] = dataset['RiskLevel'].exchange('low threat', 0).exchange('mid threat', 1).exchange('excessive threat', 2) After changing the values, we will divide the info into what will likely be used for coaching the mannequin, the options or X, and what we wish to predict, the labels or y: y = dataset['RiskLevel'] X = dataset.drop(['RiskLevel'], axis=1) As soon as the X and y units are prepared, we will use Scikit-Be taught’s train_test_split() technique to additional divide them into the prepare and check units: from sklearn.model_selection import train_test_split SEED = 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=SEED) Recommendation: keep in mind to make use of a random state seed if you wish to make the end result reproducible. We have used a random state seed so you’ll be able to reproduce the identical outcomes as from the information. Right here, we’re utilizing 20% of the info for testing and 80% for coaching. Coaching a RandomForestClassifier Take a look at our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and truly study it! Scikit-Be taught applied ensembles underneath the sklearn.ensemble module. An ensemble of resolution bushes used for classification, during which a majority vote is taken is applied because the RandomForestClassifier. Having the prepare and check units, we will import the RandomForestClassifier class and create the mannequin. To start out, let’s create a forest with three bushes, by setting n_estimators parameter as 3, and with every tree having three ranges, by setting max_depthto 2: from sklearn.ensemble import RandomForestClassifier rfc = RandomForestClassifier(n_estimators=3, max_depth=2, random_state=SEED) Notice: The default worth for n_estimators is 100. This boosts the predictive energy and generalization of the ensemble, however we’re making a smaller one to make it simpler to visualise and examine it. With simply 3 bushes – we will visualize and examine them manually to additional construct our instinct of each the person bushes, and their co-dependence. The identical applies for max_depth, which is None, that means the bushes can get deeper and deeper to suit the info as required. To suit the mannequin across the knowledge – we name the match() technique, pasing within the coaching options and labels: rfc.match(X_train, y_train) y_pred = rfc.predict(X_test) We will now examine the anticipated labels towards the true labels to guage how effectively the mannequin did! Earlier than evaluating the mannequin, let’s have a look into the ensemble. To look slightly deeper into the mannequin, we will visualize every of the bushes and the way they’re dividing the info. This may be accomplished through the use of the tree module constructed into Scikit-Be taught, after which looping via every of the estimators within the ensemble: from sklearn import tree options = X.columns.values courses = ['0', '1', '2'] for estimator in rfc.estimators_: print(estimator) plt.determine(figsize=(12,6)) tree.plot_tree(estimator, feature_names=options, class_names=courses, fontsize=8, stuffed=True, rounded=True) plt.present() The above code shows the tree plots: Discover how the three bushes are totally different. The primary one begins with the BS function, the second with DiastolicBP, and the third with BS once more. Though the third appears at a distinct variety of samples. On the appropriate department, the primary two bushes additionally resolve utilizing Age on the leaf degree, whereas the third tree ends with BS function. With simply three estimators, it is clear how scaling up offers a wealthy, various illustration of the data that may be efficiently ensembled right into a highly-accurate mannequin. The extra bushes within the forest, the extra various the mannequin will be. There is a level of diminishing returns, although, as with many bushes match on a random subset of options, there will likely be a good bit of comparable bushes that do not supply a lot range within the ensemble, and which is able to begin to have an excessive amount of voting energy and skew the ensemble to be overfit on the coaching dataset, hurting generalization to the validation set. There was a hypotesis made earlier about having extra bushes, and the way it may enhance the mannequin outcomes. Let’s check out the outcomes, generate a brand new mannequin and see if the hipothesis holds! Evaluating the RandomForestClassifier Scikit-Be taught makes it straightforward to create baselines by offering a DummyClassifier, which outputs predictions with out utilizing the enter options (completely random outputs). In case your mannequin is healthier than the DummyClassifier, some studying is occurring! To maximise the educational – you’ll be able to check out numerous hyperparameters routinely through the use of a RandomizedSearchCV or GridSearchCV. In addition to having a baseline, you’ll be able to consider your mannequin’s efficiency from the lens of a number of metrics. Some conventional classification metrics that can be utilized to guage the algorithm are precision, recall, f1-score, accuracy, and confusion matrix. Here’s a transient clarification on every of them: Precision: when our goal is to grasp what appropriate prediction values had been thought of appropriate by our classifier. Precision will divide these true optimistic values by the samples that had been predicted as positives; $$precision = frac{textual content{true positives}}{textual content{true positives} + textual content{false positives}}$$ Recall: generally calculated together with precision to grasp how lots of the true positives had been recognized by our classifier. The recall is calculated by dividing the true positives by something that ought to have been predicted as optimistic. $$recall = frac{textual content{true positives}}{textual content{true positives} + textual content{false negatives}}$$ F1 rating: is the balanced or harmonic imply of precision and recall. The bottom worth is 0 and the best is 1. When f1-score is the same as 1, it means all courses had been appropriately predicted – this can be a very arduous rating to acquire with actual knowledge (exceptions nearly at all times exist). $$textual content{f1-score} = 2* frac{textual content{precision} * textual content{recall}}{textual content{precision} + textual content{recall}}$$ Confusion Matrix: when we have to know the way a lot samples we obtained proper or mistaken for every class. The values that had been appropriate and appropriately predicted are known as true positives, those that had been predicted as positives however weren’t positives are known as false positives. The identical nomenclature of true negatives and false negatives is used for destructive values; Accuracy: describes what number of predictions our classifier obtained proper. The bottom accuracy worth is 0 and the best is 1. That worth is often multiplied by 100 to acquire a share: $$accuracy = frac{textual content{variety of appropriate predictions}}{textual content{complete variety of predictions}}$$ Notice: It is virtually inconceivable to acquire a 100% accuracy on any actual knowledge that you just’d wish to apply machine studying to. When you see a 100% accuracy classifier, or perhaps a near-100% end result – be skeptical, and carry out analysis. A typical trigger for these points are knowledge leakage (leaking a part of the coaching check right into a check set, straight or not directly). There is not any consesnsus on what “a superb accuracy is”, primarily as a result of it is determined by your knowledge – generally, a 70% accuracy will likely be excessive! Generally, that’ll be a extremely low accuracy. Usually talking, over 70% is ample for a lot of fashions, however that is on the area researcher to find out. You possibly can execute the next script to import the mandatory libraries and have a look at the outcomes: from sklearn.metrics import classification_report, confusion_matrix cm = confusion_matrix(y_test, y_pred) sns.heatmap(cm, annot=True, fmt='d').set_title('Maternal dangers confusion matrix (0 = low threat, 1 = medium threat, 2 = excessive threat)') print(classification_report(y_test,y_pred)) The output will look one thing like this: precision recall f1-score assist 0 0.53 0.89 0.66 80 1 0.57 0.17 0.26 76 2 0.74 0.72 0.73 47 accuracy 0.58 203 macro avg 0.61 0.59 0.55 203 weighted avg 0.59 0.58 0.53 203 Within the classification report, observe that the recall is excessive, 0.89 for sophistication 0, each precision and recall are excessive for sophistication 2, 0.74, 0.72 – and for sophistication 1, they’re low, specifically the recall of 0.17 and a precision of 0.57. The connection between the recall and precision for all three courses individually is captured within the F1 rating, which is the harmonic imply between recall and precision – the mannequin is doing okay for sophistication 0, pretty dangerous for sophistication 1 and first rate for sophistication 2. The mannequin is having a really arduous time when figuring out the medium threat circumstances. The accuracy achieved by our random forest classifier with solely 3 bushes is of 0.58 (58%) – this implies it’s getting the a bit greater than half of the outcomes proper. It is a low accuracy, and maybe might be improved by including extra bushes. By wanting on the confusion matrix, we will see that a lot of the errors are when classifying 52 data of medium threat as low threat, what offers additional perception to the low recall of sophistication 1. It is biased in direction of classifying medium-risk sufferers as low-risk sufferers. One other factor that may be checked to generate much more perception is what options are most considered by the classifier when predicting. This is a vital step to take for explainable machine studying programs, and helps determine and mitigate bias in fashions. To see that, we will entry the feature_importances_ property of the classifier. This may give us a listing of percentages, so we will additionally entry the feature_names_in_ property to get the title of every function, arrange them in a dataframe, kind them from highest to lowest, and plot the end result: features_df = pd.DataFrame({'options': rfc.feature_names_in_, 'importances': rfc.feature_importances_ }) features_df_sorted = features_df.sort_values(by='importances', ascending=False) g = sns.barplot(knowledge=features_df_sorted, x='importances', y ='options', palette="rocket") sns.despine(backside = True, left = True) g.set_title('Function importances') g.set(xlabel=None) g.set(ylabel=None) g.set(xticks=[]) for worth in g.containers: g.bar_label(worth, padding=2) Discover how the classifier is usually contemplating the blood sugar, then slightly of the diastolic stress, physique temperature and just a bit of age to decide, this may also should do with the low recall on class 1, perhaps the medium threat knowledge has to do with options that aren’t being taken into a lot consideration by the mannequin. You possibly can attempt to mess around extra with function importances to analyze this, and see if adjustments on the mannequin have an effect on the options getting used, additionally if there is a vital relationship between a few of the options and the anticipated courses. It’s lastly time to generate a brand new mannequin with extra bushes to see the way it impacts the outcomes. Let’s create the rfc_ forest with 900 bushes, 8 ranges and the identical seed. Will the outcomes enhance? rfc_ = RandomForestClassifier(n_estimators=900, max_depth=7, random_state=SEED) rfc_.match(X_train, y_train) y_pred = rfc_.predict(X_test) Calculating and displaying the metrics: cm_ = confusion_matrix(y_test, y_pred) sns.heatmap(cm_, annot=True, fmt='d').set_title('Maternal dangers confusion matrix (0 = low threat, 1 = medium threat, 2 = excessive threat) for 900 bushes with 8 ranges') print(classification_report(y_test,y_pred)) This outputs: precision recall f1-score assist 0 0.68 0.86 0.76 80 1 0.75 0.58 0.65 76 2 0.90 0.81 0.85 47 accuracy 0.74 203 macro avg 0.78 0.75 0.75 203 weighted avg 0.76 0.74 0.74 203 This exhibits how including extra bushes, and extra specialised bushes (increased ranges), has improved our metrics. We nonetheless have a low recall for sophistication 1, however the accuracy is now of 74%. The F1-score when classyfing excessive threat circumstances is of 0.85, which suggests excessive threat circumstances at the moment are extra simply recognized when in comparison with 0.73 within the earlier mannequin! In a day-to-day venture, it is likely to be extra vital to determine excessive threat circumstances, as an example with a metric much like precision, which is also called sensitivity in statistics. Strive tweaking a few of the mannequin parameters and observe the outcomes. To this point, we have now obtained an general understanding of how Random Forest can be utilized for classifying knowledge – within the subsequent part, we will use the identical dataset differently to see how the identical mannequin predicts values with regression. Utilizing Random Forests for Regression On this part we’ll examine how a Random Forest algorithm can be utilized to unravel regression issues utilizing Scikit-Be taught. The steps adopted to implement this algorithm are nearly equivalent to the steps carried out for classification, apart from the kind of mannequin, and kind of predicted knowledge – that may now be steady vales – there is just one distinction within the knowledge preparation. Since regression is completed for numerical values – let’s decide a numerical worth from the dataset. We have seen that blood sugar was vital within the classification, so it needs to be predictable primarily based on different options (since if it correlates with some function, that function additionally correlates with it). Following what we have now accomplished for classification, let’s first import the libraries and the identical dataset. If in case you have already accomplished this for the classification mannequin, you’ll be able to skip this half and go on to getting ready knowledge for coaching. Importing Libraries and Information import pandas as pd import numpy as np import maplotlib.pyplot as plt import seaborn as sns dataset = pd.read_csv("../../datasets/random-forest/maternal_health_risk.csv") Information Preprocessing for Regression It is a regression process, so as a substitute of predicting courses, we will predict one of many numerical columns of the dataset. On this instance, the BS column will likely be predicted. This implies the y knowledge will comprise blood sugar knowledge, and X knowledge will comprise the entire options apart from blood sugar. After separating the X and y knowledge, we will break up the prepare and check units: from sklearn.model_selection import train_test_split SEED = 42 y = dataset['BS'] X = dataset.drop(['BS'], axis=1) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=SEED) Coaching a RandomForestRegressor Now that we have now scaled our dataset, it’s time to prepare our algorithm to unravel this regression drawback, to vary it up a bit – we’ll create a mannequin with 20 bushes within the forest and each with 4 ranges. To do it, you’ll be able to execute the next code: from sklearn.ensemble import RandomForestRegressor rfr = RandomForestRegressor(n_estimators=20, max_depth=3, random_state=SEED) rfr.match(X_train, y_train) y_pred = rfr.predict(X_test) Yow will discover particulars for the entire parameters of RandomForestRegressor within the official documentation. Since plotting and 20 bushes would require a while and dedication, we will plot simply the primary one to take a look at how it’s totally different from the classification tree: from sklearn import tree options = X.columns first_tree = rfr.estimators_[0] plt.determine(figsize=(15,6)) tree.plot_tree(first_tree, feature_names=options, fontsize=8, stuffed=True, rounded=True); Discover that the regression tree already has a worth assigned to the info that falls on every node. These are the values that will likely be averaged when combining the 20 bushes. Folllowing what we have now accomplished with classification, you may as well plot function importances to see what variables the regression mannequin is taking extra into consideration when calculating values. It’s time to proceed to the final and remaining step when fixing a machine studying drawback and consider the efficiency of the algorithm! Evaluating a RandomForestRegressor For regression issues the metrics used to guage an algorithm are imply absolute error (MAE), imply squared error (MSE), and root imply squared error (RMSE). Imply Absolute Error (MAE): after we subtract the anticipated values from the precise values, acquiring the errors, sum absolutely the values of these errors and get their imply. This metric offers a notion of the general error for every prediction of the mannequin, the smaller (nearer to 0) the higher. $$mae = (frac{1}{n})sum_{i=1}^{n}left | Precise – Predicted proper |$$ Notice: You might also encounter the y and ŷ notation within the equations. The y refers back to the precise values and the ŷ to the anticipated values. Imply Squared Error (MSE): it’s much like the MAE metric, but it surely squares absolutely the values of the errors. Additionally, as with MAE, the smaller, or nearer to 0, the higher. The MSE worth is squared in order to make massive errors even bigger. One factor to pay shut consideration to, it that it’s often a tough metric to interpret as a result of measurement of its values and of the truth that they don’t seem to be in the identical scale of the info. $$mse = sum_{i=1}^{D}(Precise – Predicted)^2$$ Root Imply Squared Error (RMSE): tries to unravel the interpretation drawback raised with the MSE by getting the sq. root of its remaining worth, in order to scale it again to the identical items of the info. It’s simpler to interpret and good when we have to show or present the precise worth of the info with the error. It exhibits how a lot the info could range, so, if we have now an RMSE of 4.35, our mannequin could make an error both as a result of it added 4.35 to the precise worth, or wanted 4.35 to get to the precise worth. The nearer to 0, the higher as effectively. $$rmse = sqrt{ sum_{i=1}^{D}(Precise – Predicted)^2}$$ We will use any of these three metrics to examine fashions (if we have to select one). We will additionally examine the identical regression mannequin with totally different argument values or with totally different knowledge after which contemplate the analysis metrics. This is called hyperparameter tuning – tuning the hyperparameters that affect a studying algorithm and observing the outcomes. When selecting between fashions, those with the smallest errors, often carry out higher. When monitoring fashions, if the metrics obtained worse, then a earlier model of the mannequin was higher, or there was some vital alteration within the knowledge for the mannequin to carry out worse than it was performing. You possibly can the next code to search out these values: from sklearn.metrics import mean_absolute_error, mean_squared_error print('Imply Absolute Error:', mean_absolute_error(y_test, y_pred)) print('Imply Squared Error:', mean_squared_error(y_test, y_pred)) print('Root Imply Squared Error:', np.sqrt(mean_squared_error(y_test, y_pred))) The output needs to be: Imply Absolute Error: 1.127893702896059 Imply Squared Error: 3.0802988503933326 Root Imply Squared Error: 1.755078018320933 With 20 bushes, the basis imply squared error is 1.75 which is low, besides – by elevating the variety of bushes and experimenting with the opposite parameters, this error may in all probability get even smaller. Benefits of utilizing Random Forest As with every algorithm, there are benefits and drawbacks to utilizing it. Within the subsequent two sections we’ll check out the professionals and cons of utilizing random forest for classification and regression. The random forest algorithm is just not biased, since, there are a number of bushes and every tree is skilled on a random subset of knowledge. Mainly, the random forest algorithm depends on the ability of “the gang”; due to this fact the general diploma of bias of the algorithm is lowered. This algorithm may be very secure. Even when a brand new knowledge level is launched within the dataset the general algorithm is just not affected a lot since new knowledge could impression one tree, however it is extremely arduous for it to impression all of the bushes. The random forest algorithm works effectively when you’ve gotten each categorical and numerical options. The random forest algorithm additionally works effectively when knowledge has lacking values or it has not been scaled. Disadvantages of utilizing Random Forest The principle drawback of random forests lies of their complexity. They require way more computational assets, owing to the massive variety of resolution bushes joined collectively, when coaching massive ensembles. Although – with trendy {hardware}, coaching even a big random forest would not take a whole lot of time. Going Additional – Hand-Held Finish-To-Finish Venture Your inquisitive nature makes you wish to go additional? We suggest testing our Guided Venture: “Arms-On Home Worth Prediction – Machine Studying in Python”. On this guided venture – you will discover ways to construct highly effective conventional machine studying fashions in addition to deep studying fashions, make the most of Ensemble Studying and traing meta-learners to foretell home costs from a bag of Scikit-Be taught and Keras fashions. Utilizing Keras, the deep studying API constructed on prime of Tensorflow, we’ll experiment with architectures, construct an ensemble of stacked fashions and prepare a meta-learner neural community (level-1 mannequin) to determine the pricing of a home. Deep studying is superb – however earlier than resorting to it, it is suggested to additionally try fixing the issue with less complicated methods, corresponding to with shallow studying algorithms. Our baseline efficiency will likely be primarily based on a Random Forest Regression algorithm. Moreover – we’ll discover creating ensembles of fashions via Scikit-Be taught through methods corresponding to bagging and voting. That is an end-to-end venture, and like all Machine Studying initiatives, we’ll begin out with – with Exploratory Information Evaluation, adopted by Information Preprocessing and at last Constructing Shallow and Deep Studying Fashions to suit the info we have explored and cleaned beforehand. Share FacebookTwitterPinterestWhatsApp Previous articlephp – Displaying customized meta field worth in a customized publish web pageNext articleConversion to Audio could Enhance Outcomes: Utilizing Siamese Networks for Nickname Classification | by David Harar | Nov, 2022 Adminhttps://www.handla.it RELATED ARTICLES Programming Definitive Information to Unit Testing in React Purposes with Jest and React-Testing November 27, 2022 Programming Linus Torvalds Biography November 26, 2022 Programming The Overflow #153: Easy methods to get a job in Japan November 25, 2022 LEAVE A REPLY Cancel reply Comment: Please enter your comment! Name:* Please enter your name here Email:* You have entered an incorrect email address! Please enter your email address here Website: Save my name, email, and website in this browser for the next time I comment. - Advertisment - Most Popular Methods to Work With PDF Paperwork Utilizing Python November 28, 2022 Amazon Chime is PAINFUL.. The final time I used Amazon Chime it… | by Teri Radichel | Bugs That Chunk | Nov, 2022 November 28, 2022 Information Verification Blockchain Know-how Anticipated to Clear up Issues Derived from Digital Transformation November 28, 2022 Chrome Zero Day Bug Actively Exploited within the Wild November 28, 2022 Load more Recent Comments


{kind=link}