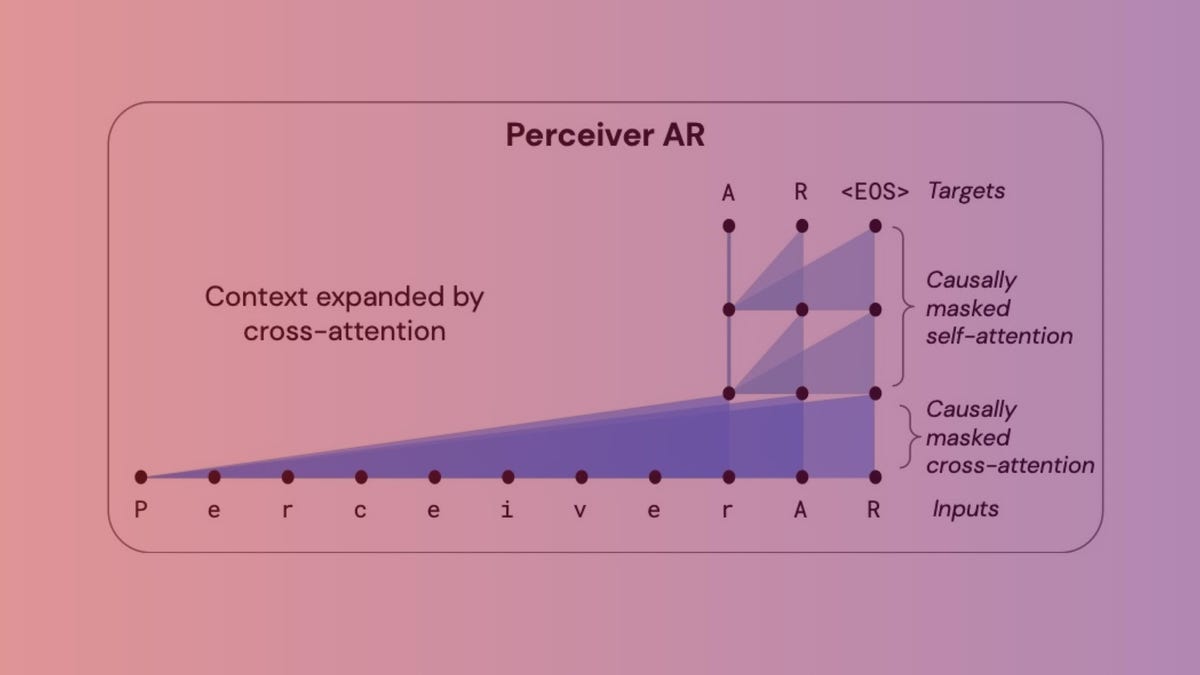
DeepMind and Google Mind’s Perceiver AR structure reduces the duty of computing the combinatorial nature of inputs and outputs right into a latent area, however with a twist that the latent area has “causal masking” so as to add the auto-regressive order of a typical Transformer.
DeepMind/Google Mind
One of many alarming features of the extremely in style deep studying section of synthetic intelligence is the ever-larger measurement of the applications. Consultants within the area say computing duties are destined to get larger and largest as a result of scale issues.
Such larger and greater applications are useful resource hogs, and that is a crucial difficulty within the ethics of deep studying for society, a dilemma that has caught the eye of mainstream science journals reminiscent of Nature.
That is why it is fascinating any time that the time period effectivity is introduced up, as in, Can we make this AI program extra environment friendly?
Scientists at DeepMind, and at Google’s Mind division, not too long ago tailored a neural community they launched final yr, Perceiver, to make it extra environment friendly when it comes to its pc energy requirement.
The brand new program, Perceiver AR, is called for the “autoregressive” facet of an growing variety of deep studying applications. Autoregression is a method for having a machine use its outputs as new inputs to this system, a recursive operation that types an consideration map of how a number of parts relate to 1 one other.
The Transformer, the wildly in style neural community Google launched in 2017, has this autoregressive facet. And lots of fashions since do, together with GPT-3 and the primary model of the Perceiver.
Perceiver AR follows a second model of Perceiver, referred to as Perceiver IO, launched in March, and the unique Perceiver a yr in the past this month.
The innovation of the unique perceiver was to take the Transformer and tweak it to let it eat every kind of enter, together with textual content sound and pictures, in a versatile type, relatively than being restricted to a selected type of enter, for which separate sorts of neural networks are often developed.
Perceiver is one in all an growing variety of applications that use auto-regressive consideration mechanisms to combine totally different modalities of enter and totally different activity domains. Different examples embrace Google’s Pathways, DeepMind’s Gato, and Meta’s data2vec.
Additionally: DeepMind’s ‘Gato’ is mediocre, so why did they construct it?
Then, in March, the identical workforce of Andrew Jaegle and colleagues that constructed Perceiver, launched the “IO” model, which enhanced the output of Perceiver to accommodate extra than simply classification, reaching a number of outputs with all type of construction, starting from textual content language output to optical circulation fields to audiovisual sequences to symbolic unordered units. It could even produced motion within the recreation StarCraft II.
Now, within the paper, Basic-purpose, long-context autoregressive modeling with Perceiver AR, Jaegle and workforce confront the query of how the fashions ought to scale as they grow to be increasingly more formidable in these multimodal enter and output duties.
The issue is, the auto-regressive high quality of the Transformer, and every other program that builds an consideration map from enter to output, is that it requires large scale when it comes to the a distribution over a whole bunch of hundreds of parts.
That’s the Achilles Heel of consideration, the necessity, exactly, to take care of something and every thing so as assemble the likelihood distribution that makes for the eye map.
Additionally: Meta’s ‘data2vec’ is a step towards One Neural Community to Rule Them All
As Jaegle and workforce put it, it turns into a scaling nightmare in computing phrases because the variety of issues that should be in comparison with each other within the enter will increase:
There’s a pressure between this type of long-form, contextual construction and the computational properties of Transformers. Transformers repeatedly apply a self-attention operation to their inputs: this results in computational necessities that concurrently develop quadratically with enter size and linearly with mannequin depth. Because the enter knowledge grows longer, extra enter tokens are wanted to watch it, and because the pat- terns within the enter knowledge develop extra refined and complex, extra depth is required to mannequin the patterns that outcome. Computational constraints drive customers of Transformers to both truncate the inputs to the mannequin (stopping it from observ- ing many sorts of long-range patterns) or prohibit the depth of the mannequin (denuding it of the expressive energy wanted to mannequin complicated patterns).
The unique Perceiver in actual fact introduced improved effectivity over Transformers by performing consideration on a latent illustration of enter, as a substitute of instantly. That had the impact of “[decoupling] the computational necessities of processing a big enter array from these required to make a community very deep.”
Perceiver AR’s comparability to a normal Transformer deep community and the improved Transformer XL.
DeepMind/Google Mind
The latent half, the place representations of enter are compressed, turns into a type of more-efficient engine for consideration, in order that, “For deep networks, the self-attention stack is the place the majority of compute happens” relatively than working on myriad inputs.
However the problem remained {that a} Perceiver can not generate outputs the best way the Transformer does as a result of that latent illustration has no sense of order, and order is crucial in auto-regression. Every output is meant to be a product of what got here earlier than it, not after.
Additionally: Google unveils ‘Pathways’, a next-gen AI that may be skilled to multitask
“Nevertheless, as a result of every mannequin latent attends to all inputs no matter place, Perceivers can’t be used instantly for autoregressive technology, which requires that every mannequin output rely solely on inputs that precede it in sequence,” they write.
With Perceiver AR, the workforce goes one additional and inserts order into the Perceiver to make it able to that auto-regressive operate.
The secret’s what’s referred to as “causal masking” of each the enter, the place a “cross-attention takes place, and the latent illustration, to drive this system to attend solely to issues previous a given image. That strategy restores the directional high quality of the Transformer, however with far much less compute.
The result’s a capability to do what the Transformer does throughout many extra inputs however with considerably improved efficiency.
“Perceiver AR can study to completely acknowledge long-context patterns over distances of not less than 100k tokens on an artificial copy activity,” they write, versus a tough restrict of two,048 tokens for the Transformer, the place extra tokens equals longer context, which ought to equal extra sophistication in this system’s output.
Additionally: AI in sixty seconds
And Perceiver AR does so with “improved effectivity in comparison with the extensively used decoder-only Transformer and Transformer-XL architectures and the flexibility to differ the compute used at take a look at time to match a goal finances.”
Particularly, the wall clock time to compute Perceiver AR, they write, is dramatically lowered for a similar quantity of consideration, and a capability to get a lot better context — extra enter symbols — on the similar computing finances:
The Transformer is proscribed to a context size of two,048 tokens, even with solely 6 layers—bigger fashions and bigger context size require an excessive amount of reminiscence. Utilizing the identical 6-layer configuration, we are able to scale the Transformer-XL reminiscence to a complete context size of 8,192. Perceiver AR scales to 65k context size, and will be scaled to over 100k context with additional optimization.
All which means flexibility of compute: “This offers us extra management over how a lot compute is used for a given mannequin at take a look at time and permits us to easily commerce off velocity towards efficiency.”
The strategy, Jaegle and colleagues write, can be utilized on any enter sort, not simply phrase symbols, for instance, pixels of a picture:
The identical process will be utilized to any enter that may be ordered, so long as masking is utilized. For instance, a picture’s RGB channels will be ordered in raster scan order, by decoding the R, G, and B colour channels for every pixel within the sequence and even below totally different permutations.
Additionally: Ethics of AI: Advantages and dangers of synthetic intelligence
The authors see huge potential for Perceiver to go locations, writing that “Perceiver AR is an effective candidate for a general-purpose, long-context autoregressive mannequin.”
There’s an additional ripple, although, within the pc effectivity issue. Some current efforts, the authors word, have tried to slim down the compute finances for auto-regressive consideration through the use of “sparsity,” the method of limiting which enter parts are given significance.
On the similar wall clock time, the Perceiver AR can run extra symbols from enter by way of the identical variety of layers, or run the identical variety of enter symbols whereas requiring much less compute time — a flexibilty the authors consider is usually a basic strategy to better effectivity in giant networks.
DeepMind/Google Mind
That has some drawbacks, principally, being too inflexible. “The draw back of strategies that use sparsity is that this sparsity have to be hand-tuned or created with heuristics which might be usually area particular and will be exhausting to tune,” they write. That features efforts reminiscent of OpenAI and Nvidia’s 2019 “Sparse Transformer.”
“In distinction, our work doesn’t drive a home made sparsity sample on consideration layers, however relatively permits the community to study which long-context inputs to take care of and propagate by way of the community,” they write.
“The preliminary cross-attend operation, which reduces the variety of positions within the sequence, will be seen as a type of realized sparsity,” they add.
It is doable realized sparsity on this method might itself be a robust device within the toolkit of deep studying fashions in years to return.

{kind=link}