

Machine studying analysis is progressing at an ever-faster tempo. We’re probably nonetheless a long time away from reaching the singularity, however AI has already turn into the buzzword that each tech firm is throwing round. Numerous AI fashions exist, however many depend on related coaching methods to develop and refine their capabilities. Reinforcement studying is a well-liked methodology, and the DeepMind group behind AlphaTensor have detailed how they use deep reinforcement studying to gamify the machine studying course of.
Reinforcement studying broadly describes methods that use rewards and penalties to information an AI mannequin by means of a posh process. A human analogy may very well be taking part in any sport with a rating system. Higher play (e.g. successful video games) is rewarded by transferring up the leaderboard whereas errors are met with a drop in rank. Alongside the way in which, gamers will strive totally different ways and techniques to adapt to what opponents are doing. In fact, some people might not be bothered to care a couple of ladder rank, however AI fashions could be compelled with software program.
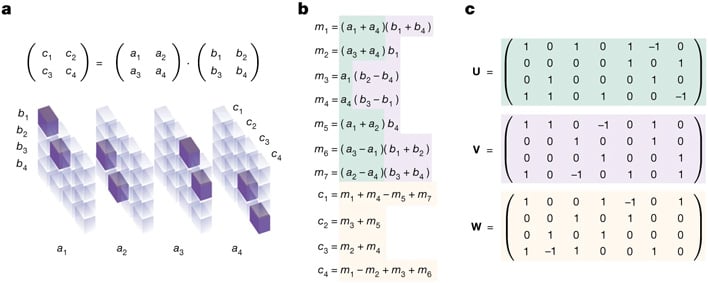
AlphaTensor is an AI mannequin based mostly on AlphaZero which is tasked with discovering algorithms to resolve arbitrary matrix multiplication issues. Matrix multiplications are used to explain transformations in house and the matrices symbolize a mathematical idea known as a tensor, the final time period for scalars and vectors. Tensor math is on the coronary heart of linear algebra and has functions in varied fields from supplies science to machine studying itself.
Matrix multiplications are solved based on particular guidelines and processes. Like a lot of math, there are optimizations that may be made to resolve these issues in fewer and fewer steps. The refined algorithms allow bigger matrix multiplications to be accomplished at possible timescales.
AlphaTensor is offered with a sport within the type of a single participant puzzle. The board consists of a grid of numbers representing a 3D Tensor, which AlphaTensor is then tasked with decreasing to zeros by means of a sequence of allowable strikes, comprised of matrix multiplications. The attainable moveset is staggeringly huge, exceeding video games like chess and Go by a number of elements.
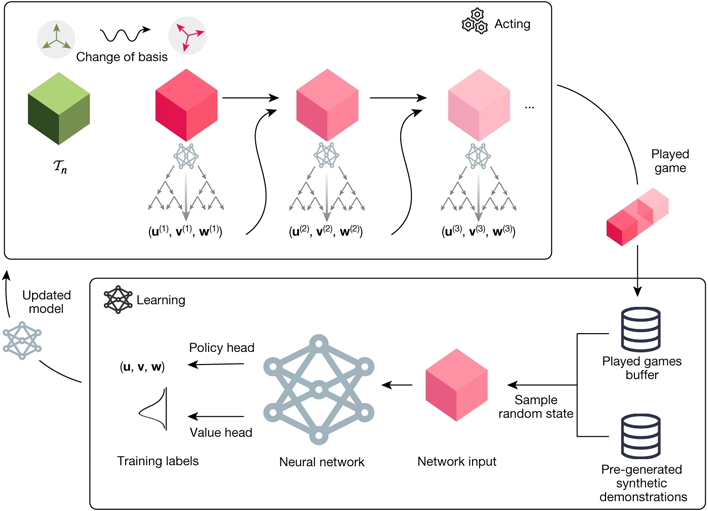
The AI makes use of Monte Carlo tree searches (MCTS) to plan its strikes. That is successfully the identical system utilized by AlphaZero to grasp chess and Go. With MCTS, the AI participant seems at a pattern of potential strikes whose outcomes are tracked as a distribution of potential success. Rounds of the sport are capped to a sure variety of runs to keep away from unnecessarily lengthy video games, however profitable matches are fed again in to enhance the community’s decisionmaking parameters.
Co-author Hussein Fawzi instructed Nature, “AlphaTensor embeds no human instinct about matrix multiplication,” so “the agent in some sense must construct its personal data about the issue from scratch.” By means of this suggestions, AlphaTensor learns which strikes usually tend to yield success, and profitable it has been. In matrix sizes as much as 5 x 5 pairs, AlphaTensor has matched or exceeded the effectivity of recognized algorithms when it comes to steps.

Particularly, AlphaTensor has found a 47 step resolution to paired 4 x 4 matrix multiplication which improves on the recognized 49 step resolution which was present in 1969. It additionally shaved a pair steps off of paired 5 x 5 matrix multiplication, decreasing 98 steps to 96. Its enhancements additionally prolonged to some asymmetrically sized matrix multiplications, with higher methods of fixing 3 x 4 instances 4 x 5 matrices, 4 x 4 instances 4 x 5 matrices, and 4 x 5 instances 5 x 5 matrices, the final of which it achieved in 4 fewer steps than recognized strategies.
The researchers word that the preliminary predefined moveset sampling does current a limitation. It’s attainable that extra environment friendly algorithms may very well be derived from beginning strikes which are excluded at the beginning. Other than brute forcing each attainable transfer—which is computationally costly—the researchers imagine they may adapt AlphaTensor to seek out higher beginning units itself. An AI working on the elemental math it’s constructed from and optimizing its situations? Possibly that is beginning to sound just like the singularity.
In actuality although, it’s straightforward to attract parallels between AlphaTensor studying to resolve these immense issues and a fledgling Starcraft participant, which DeepMind’s AI has coincidentally excelled at too. By means of iteration, it learns which strikes will maximize its possibilities of success and which usually tend to finish in failure—like having a swarm of zerglings get roasted by the opponent’s clump of fire-spewing hellbats. The zerg participant can strive sneaky run-bys in future matches to take advantage of the hellbat’s lack of mobility in future matches relatively than interact in a direct battle. Matrix multiplication might not be as thrilling, however the underpinning course of the AI makes use of to study is all the identical.

{kind=link}