
Apache Iceberg is a high-performance format for big analytic tables. There’re plenty of tutorials on the web about the best way to use Iceberg. This put up is slightly completely different, it’s for these people who find themselves curious to know the interior mechanism of Iceberg. On this put up, I’ll use Spark sql to create/insert/delete/replace Iceberg desk in Apache Zeppelin and can clarify what occurs beneath for every operation.
To display the interior mechanism extra intuitively, I take advantage of Apache Zeppelin to run all the instance code. You possibly can reproduce what I did simply by way of Zeppelin docker. You possibly can verify this text for the best way to play Spark in Zeppelin docker. Right here I simply summarize it as following steps:
- Step 1. git clone https://github.com/zjffdu/zeppelin-notebook.git
- Step 2. Obtain Spark 3.2.1
- Step 3. Run the next command to start out the Zeppelin docker container. ${zeppelin_notebook}is the pocket book folder you cloned in Step 1, ${spark_location} is the Spark folder you downloaded in Step 2.
docker run -u $(id -u) -p 8080:8080 -p 4040:4040 --rm -v
${spark_location}:/decide/spark -v
${zeppelin_notebook}:/decide/pocket book -e
ZEPPELIN_NOTEBOOK_DIR=/decide/pocket book -e SPARK_HOME=/decide/spark
-e ZEPPELIN_LOCAL_IP=0.0.0.0 --name zeppelin
apache/zeppelin:0.10.1
Then open http://localhost:8080 in browser, and open the pocket book Spark/Deep Dive into Iceberg which comprises all of the code on this article.
Mainly, there’re 3 layers for Iceberg:
- Catalog layer
- Metadata layer
- Knowledge Layer
Catalog Layer
Catalog layer has 2 implementations:
- Hive catalog which makes use of hive metastore. Hive metastore makes use of relational database to retailer the place’s present model’s snapshot file.
- Path based mostly catalog which is predicated on file system. This tutorial makes use of path based mostly catalog. It makes use of information to retailer the place’s the present model’s metadata file. ( version-hint.textual content is the pointer which level to every model’s metadata file v[x].metadata.jsonin the under examples)
Metadata Layer
In metadata layer, there’re 3 sorts of information:
- Metadata file. Every CRUD operation will generate a brand new metadata file which comprises all of the metadata data of desk, together with the schema of desk, all of the historic snapshots till now and and so forth. Every snapshot is related to one manifest listing file.
- Manifest listing file. Every model of snapshot has one manifest listing file. Manifest listing file comprises a group of manifest information.
- Manifest file. Manifest file will be shared cross snapshot information. It comprises a group of information information which retailer the desk knowledge. Moreover that it additionally comprises different meta data for potential optimization, e.g. row-count, lower-bound, upper-bound and and so forth.
Knowledge Layer
Knowledge layer is a bunch of parquet information which comprise all of the historic knowledge, together with newly added data, up to date report and deleted data. A subset of those knowledge information compose one model of snapshot.
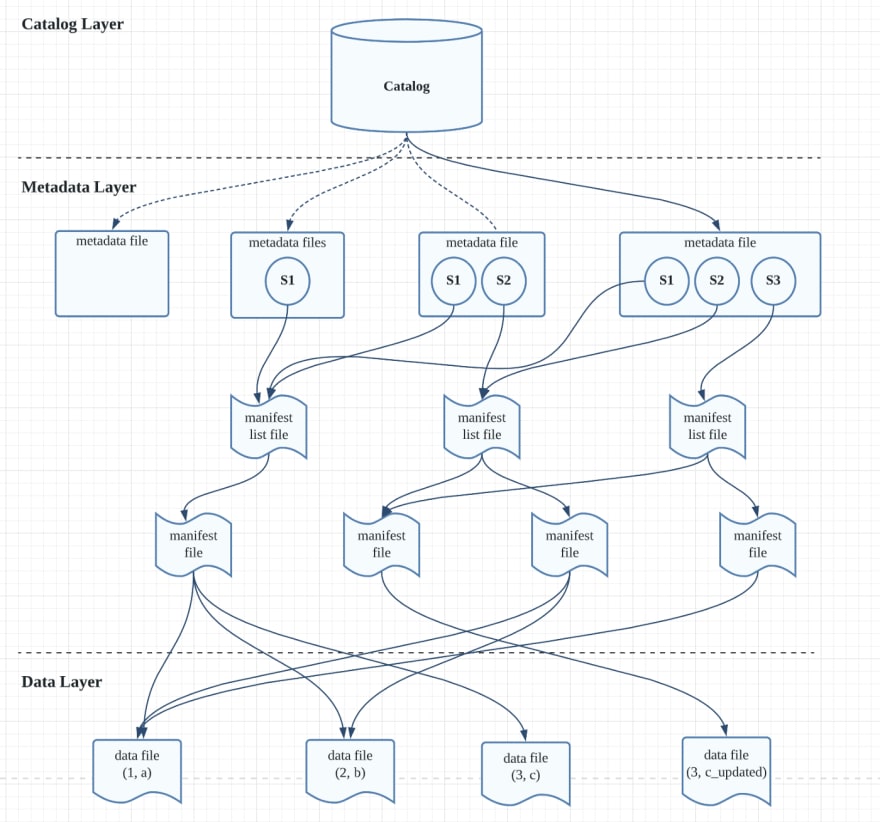
The diagram above is the structure of Iceberg and in addition demonstrates what we did on this tutorial
- S1 means the model after we insert 3 data
- S2 means the model after we replace one report
- S3 means the model after we delete one report
Obtain jq and avro instruments jar
jq is used for show json , avro instruments jar is used to learn iceberg metadata information (avro format) and show it in plain textual content.

Configure Spark

%spark.conf is a particular interpreter to configure Spark interpreter in Zeppelin. Right here I configure the Spark interpreter as described on this fast begin. Moreover that, I specify the warehouse folder spark.sql.catalog.native.warehouse explicitly in order that I can verify the desk folder simply later on this tutorial. Now let’s begin to use Spark and play Iceberg in Zeppelin.
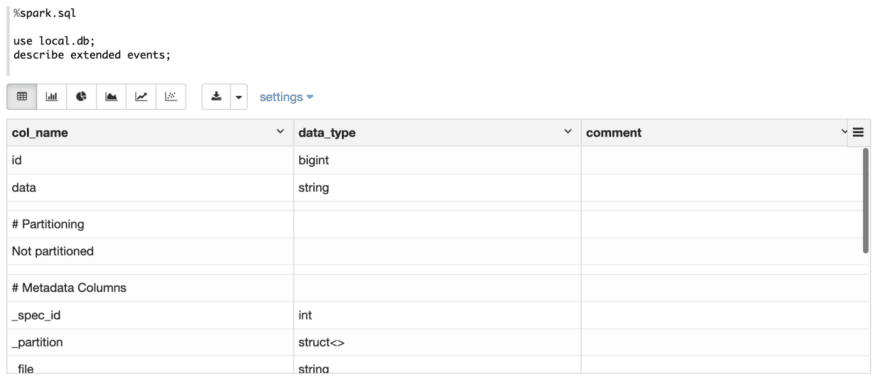
First Let’s create an Iceberg desk occasions with 2 fields: idand knowledge.

Then describe this desk to verify its particulars
Examine Desk Folder
So what does Iceberg do beneath for this create sql assertion? Really, Iceberg did 2 issues:
- Create a listing occasions below the warehouse folder /tmp/warehouse
- Add a metadata folder which comprises all of the metadata data
Since it is a newly created desk, no knowledge is on this desk. There’s just one metadata folder below the desk folder (/tmp/warehouse/db/occasions ). There’re 2 information below this folder:
- version-hint.textual content. This file solely comprises one quantity which level to the present metadata file v[n].medata.json)
- v1.metadata.json. This file comprises the metadata of this desk, such because the schema, location, snapshots and and so forth. For now, this desk has no knowledge, so there’s no snapshots on this metadata file.

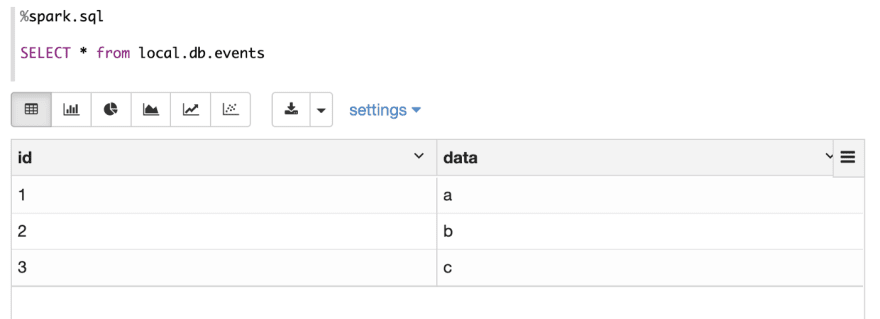
Now let’s insert 3 new data (1, a), (2, b), (3, c)

Then use choose assertion to confirm the consequence.
Examine Desk Folder
Really there’re 2 issues occurred beneath for this insert operation.
- In knowledge folder, 3 parquet information are created. One report per parquet file.
- In metadata folder, the content material ofversion-hint.textual content is modified to 2, v2.metadata.jsonis created which has one newly created snapshot which level to 1 manifest listing file. This manifest listing file factors to 1 manifest file which factors to the three parquet information.

We will use the avro instruments jar to learn the manifest listing file which is avro format. And we discover that it shops the situation of manifest file and different meta data like added_data_files_count, deleted_data_files_count and and so forth.
Then use the avro instruments jar to learn the manifest file which comprises the trail of the information information and different associated meta data.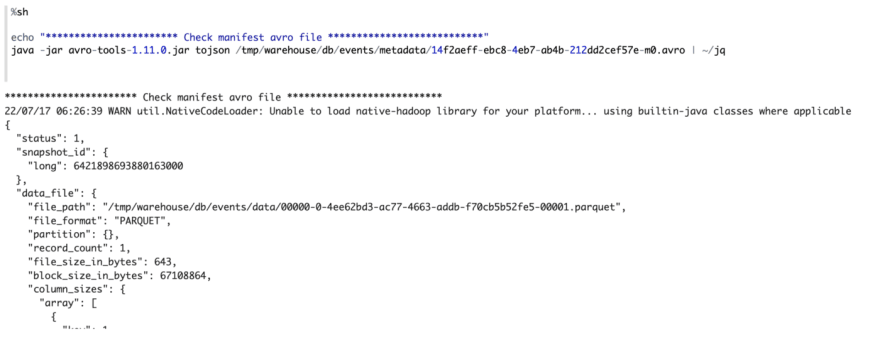
We will use spark api to learn uncooked parquet knowledge information, and we will discover there’s one report in every parquet file.

Now, let’s use replace assertion to replace one report.
Examine consequence after replace
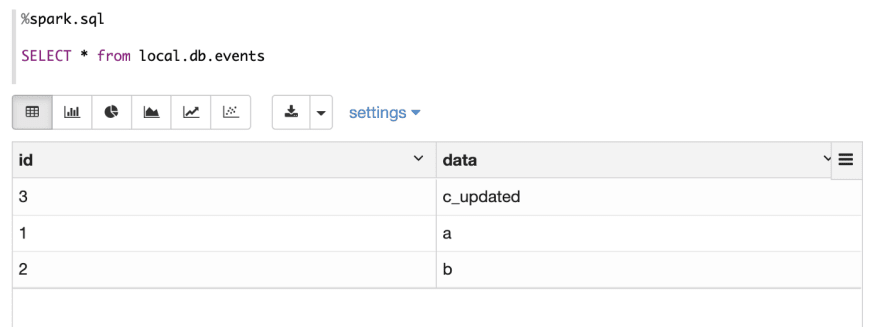
Examine Desk Folder
- In knowledge folder, the present parquet information are usually not modified. However one new parquet file is generated.(3,
c_updated) - In metadata folder, the content material ofversion-hint.textual content is modified to three, v3.metadata.jsonis created which has 2 snapshots. One snapshot is the primary snapshot in above step, one other new snapshot is created which has a brand new manifest listing file.
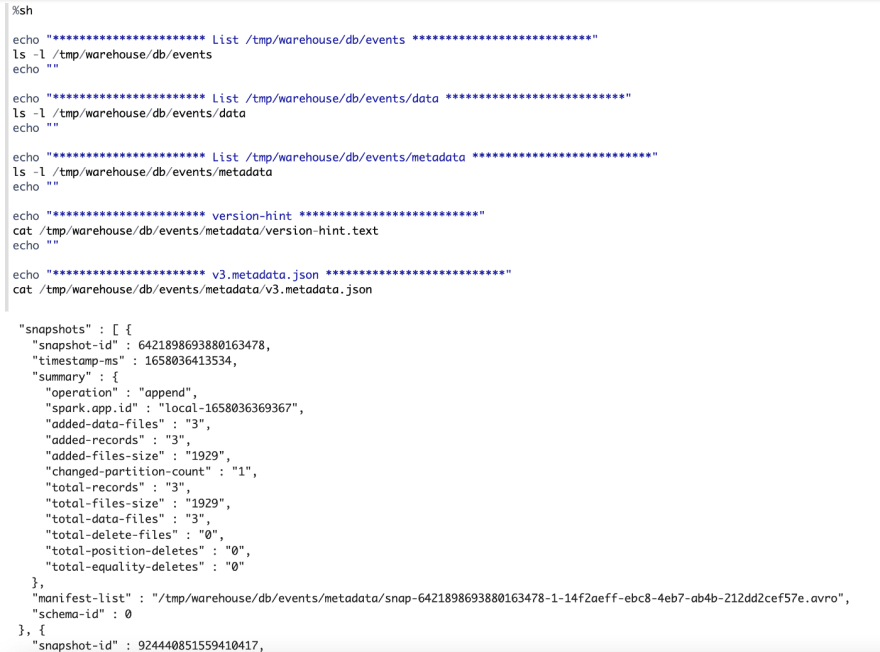
You could be curious to understand how Iceberg implements the replace operation with out altering present knowledge. This magic occurs in Iceberg metadata layer. For those who verify this model’s metadata file, you’ll discover now it comprises 2 snapshots, and every snapshot is related to one manifest listing file. The primary snapshot is similar as above, whereas the second snapshot is related to a brand new manifest listing file. On this manifest listing file, there’re 2 manifest information.
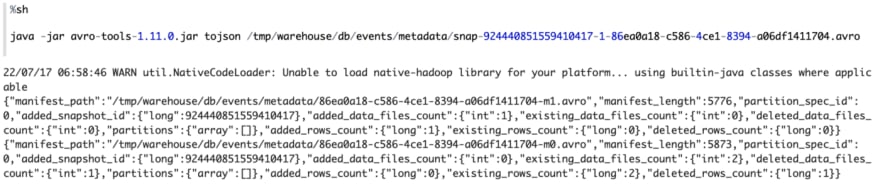
The primary manifest file level to newly added knowledge file (3, c_updated). Whereas within the second manifest file, you’ll discover that it nonetheless comprises 3 knowledge information that comprises (1, a), (2, b), (3, c), however the standing of the third knowledge file(3, c) is 2 which implies this knowledge file is deleted, so when Iceberg learn this model of desk, it might skip this knowledge file. So solely (1,a), (2, b) shall be learn.
Now, let’s delete report (2, b)
Use choose assertion to confirm the consequence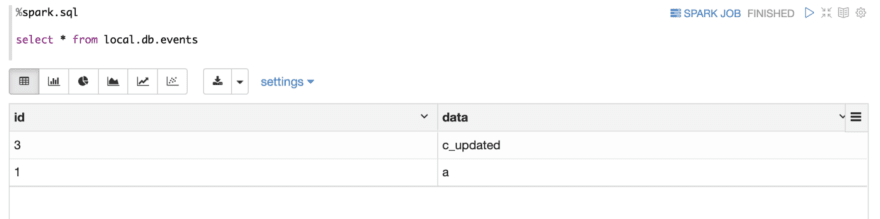
Examine Desk Folder
- In knowledge folder, nothing modified.
- In metadata folder, the content material ofversion-hint.textual content is modified to 4, v4.metadata.jsonis created which has another snapshots (completely 3 snapthots).
The manifest listing file related to the brand new snapshot comprises 2 manifest information.
The manifest listing file related to the brand new snapshot comprises 2 manifest information.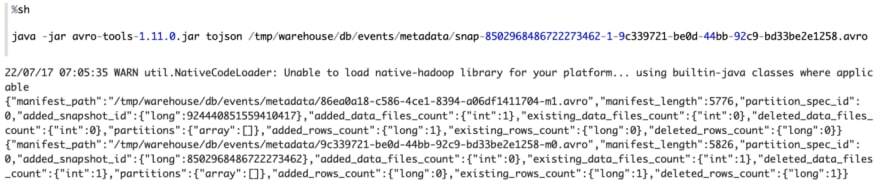
The primary manifest level to 1 knowledge information (3, c_updated), , the second manifest file level to knowledge file (1, a), (2, b). However the standing of information file (2, b) is 2, which implies it has been deleted, so when Iceberg learn this model of desk, it might simply skip this knowledge file. So solely (1, a) shall be learn.

Use spark api to learn these knowledge information.

You may also learn metadata tables to examine a desk’s historical past, snapshots, and different metadata.
Examine historical past metadata
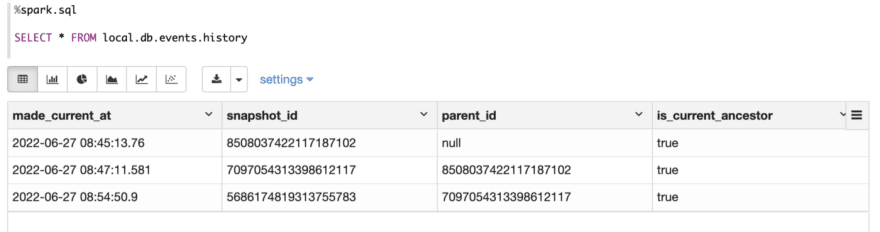
Examine snapshot metadata

Examine manifest metadata
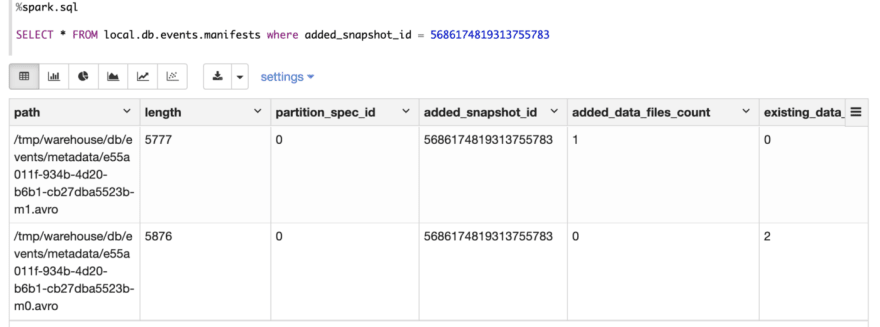
Examine file meta desk
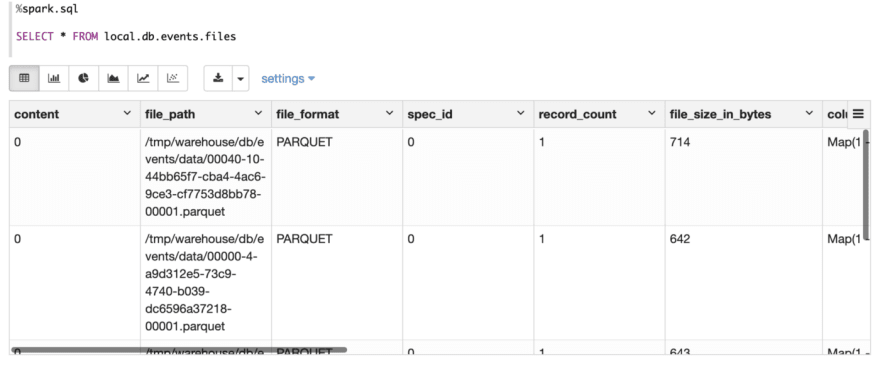
On this article, I do 4 fundamental steps to play Apache Iceberg:
- Create Desk
- Insert Knowledge
- Replace Knowledge
- Delete Knowledge
At every step, I verify what is modified below the desk folder. All of the steps are achieved in Apache Zeppelin docker container, you’ll be able to reproduce them simply. Only one factor to recollect, as a result of the file names are randomly generated (snapshot file, manifest file, parquet file), so that you must replace code to make use of the proper file identify. Hope this text is beneficial so that you can perceive the interior mechanism of Apache Iceberg.

{kind=link}