Advantageous-tuning a pre-trained language mannequin (LM) has turn into the de facto normal for doing switch studying in pure language processing. Over the past three years (Ruder, 2018), fine-tuning (Howard & Ruder, 2018) has outdated the usage of function extraction of pre-trained embeddings (Peters et al., 2018) whereas pre-trained language fashions are favoured over fashions educated on translation (McCann et al., 2018), pure language inference (Conneau et al., 2017), and different duties as a consequence of their elevated pattern effectivity and efficiency (Zhang and Bowman, 2018). The empirical success of those strategies has led to the event of ever bigger fashions (Devlin et al., 2019; Raffel et al., 2020). Current fashions are so giant the truth is that they will obtain cheap efficiency with out any parameter updates (Brown et al., 2020). The restrictions of this zero-shot setting (see this part), nevertheless, make it probably that with the intention to obtain one of the best efficiency or keep fairly environment friendly, fine-tuning will proceed to be the modus operandi when utilizing giant pre-trained LMs in follow.
In the usual switch studying setup (see under; see this publish for a common overview), a mannequin is first pre-trained on giant quantities of unlabelled information utilizing a language modelling loss similar to masked language modelling (MLM; Devlin et al., 2019). The pre-trained mannequin is then fine-tuned on labelled information of a downstream activity utilizing a typical cross-entropy loss.
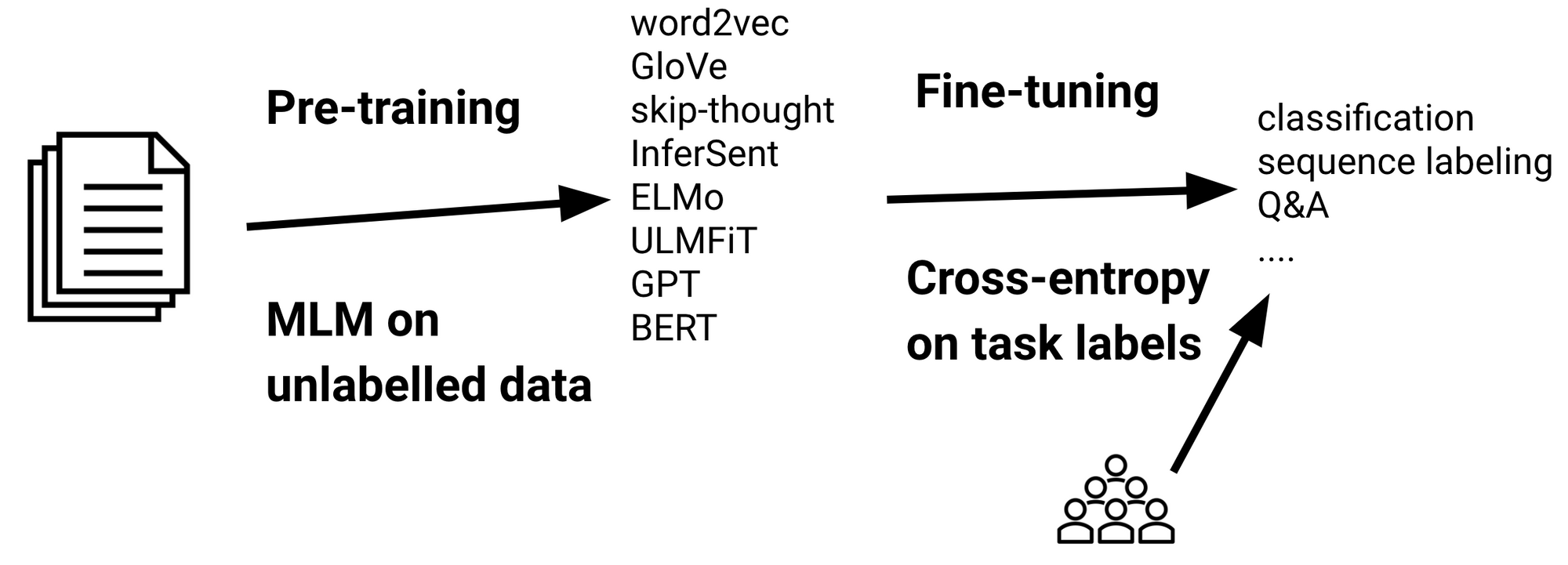
Whereas pre-training is compute-intensive, fine-tuning will be completed comparatively inexpensively. Advantageous-tuning is extra necessary for the sensible utilization of such fashions as particular person pre-trained fashions are downloaded—and fine-tuned—tens of millions of occasions (see the Hugging Face fashions repository). Consequently, fine-tuning is the principle focus of this publish. Particularly, I’ll spotlight the newest advances which have formed or are more likely to change the best way we fine-tune language fashions, which will be seen under.
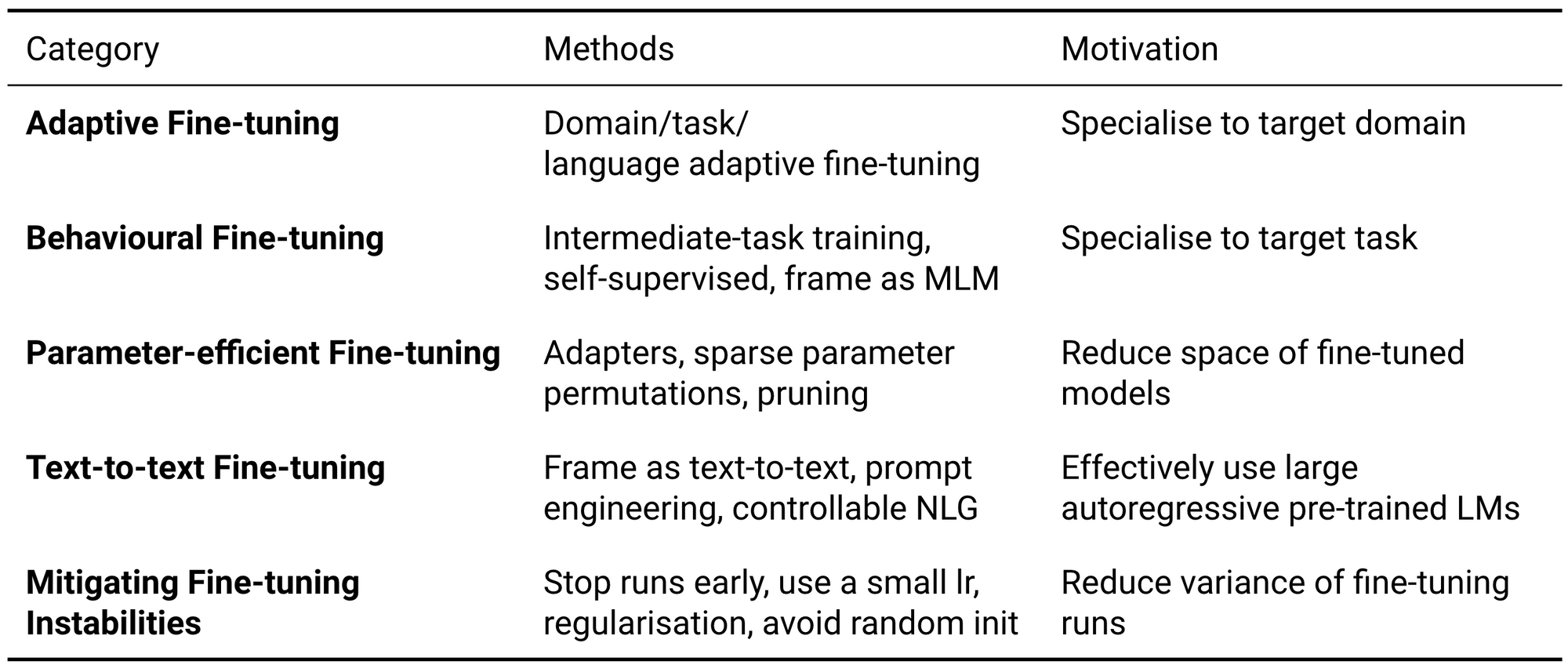
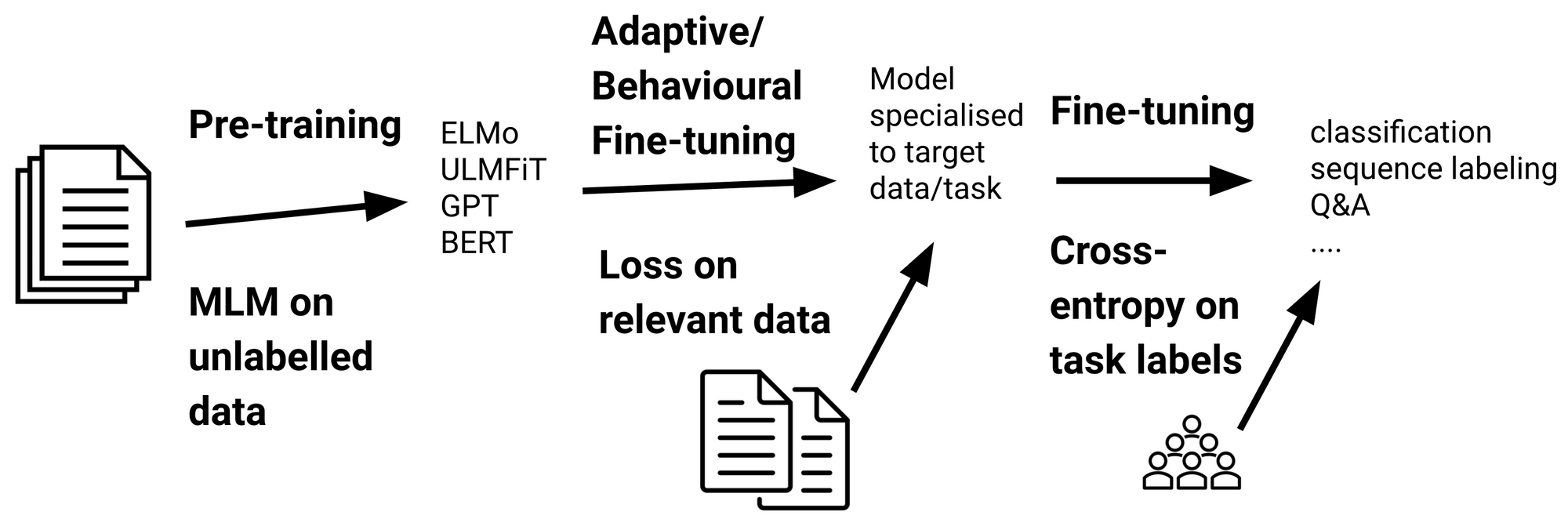
Adaptive fine-tuning
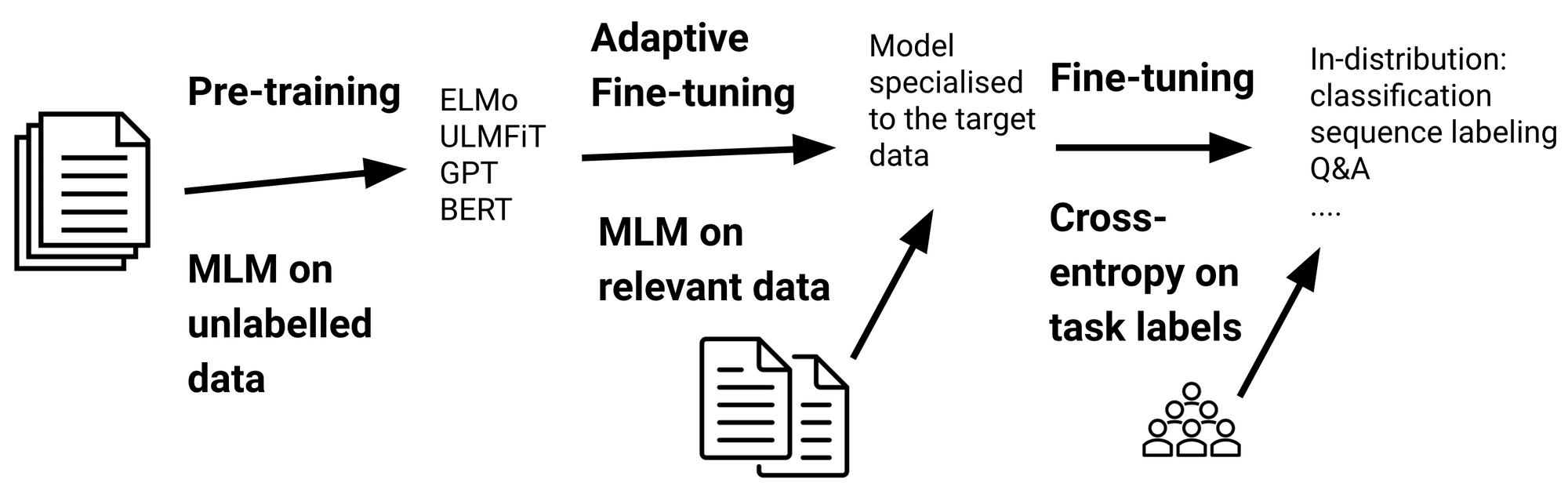
Regardless that pre-trained language fashions are extra sturdy by way of out-of-distribution generalisation than earlier fashions (Hendrycks et al., 2020), they’re nonetheless poorly outfitted to take care of information that’s considerably totally different from the one they’ve been pre-trained on. Adaptive fine-tuning is a option to bridge such a shift in distribution by fine-tuning the mannequin on information that’s nearer to the distribution of the goal information. Particularly, adaptive fine-tuning entails fine-tuning the mannequin on further information previous to task-specific fine-tuning, which will be seen under. Importantly, the mannequin is fine-tuned with the pre-training goal, so adaptive fine-tuning solely requires unlabelled information.
Formally, given a goal area $mathcal{D}_T$ consisting of a function house $mathcal{X}$ and a marginal chance distribution over the function house $P(X)$ the place $X = {x_1, ldots, x_n } in mathcal{X}$ (Pan and Yang, 2009; Ruder, 2019), adaptive fine-tuning permits us to find out about each the function house $mathcal{X}$ and the distribution of the goal information $P(X)$.
Variants of adaptive fine-tuning—area, activity, and language-adaptive fine-tuning—have been used to adapt a mannequin to information of the goal area, goal activity, and goal language respectively. Dai and Le (2015) first confirmed the advantages of domain-adaptive fine-tuning. Howard and Ruder (2018) later demonstrated improved pattern effectivity by fine-tuning on in-domain information as a part of ULMFiT. Additionally they proposed task-adaptive fine-tuning, which fine-tunes the mannequin with the pre-training goal on the duty coaching information. Because the pre-training loss supplies richer info for modelling the goal information in comparison with the cross-entropy over one-hot activity labels, task-adaptive fine-tuning is helpful past common fine-tuning. Alternatively, adaptive and common fine-tuning will be completed collectively through multi-task studying (Chronopoulou et al., 2019).
Area and task-adaptive fine-tuning have not too long ago been utilized to the newest era of pre-trained fashions (Logeswaran et al., 2019; Han and Eisenstein, 2019; Mehri et al., 2019). Gururangan et al. (2020) present that adapting to information of the goal area and goal activity are complementary. Not too long ago, Pfeiffer et al. (2020) proposed language-adaptive fine-tuning to adapt a mannequin to new languages.
An adaptively fine-tuned mannequin is specialised to a selected information distribution, which it is going to be capable of mannequin properly. Nonetheless, this comes on the expense of its potential to be a common mannequin of language. Adaptive fine-tuning is thus most helpful when excessive efficiency on (doubtlessly a number of) duties of a single area is necessary and will be computationally inefficient if a pre-trained mannequin must be tailored to numerous domains.
Behavioural fine-tuning
Whereas adaptive fine-tuning permits us to specialise our mannequin to $mathcal{D}_T$, it doesn’t educate us something straight in regards to the goal activity. Formally, a goal activity $mathcal{T}_T$ consists of a label house $mathcal{Y}$, a previous distribution $P(Y)$ the place $Y = {y_1, ldots, y_n } in mathcal{Y}$, and a conditional chance distribution $P(Y | X)$. Alternatively, we are able to educate a mannequin capabilities helpful for doing properly on the goal activity by fine-tuning it on related duties, as will be seen under. We are going to confer with this setting as behavioural fine-tuning because it focuses on studying helpful behaviours and to differentiate it from adaptive fine-tuning.
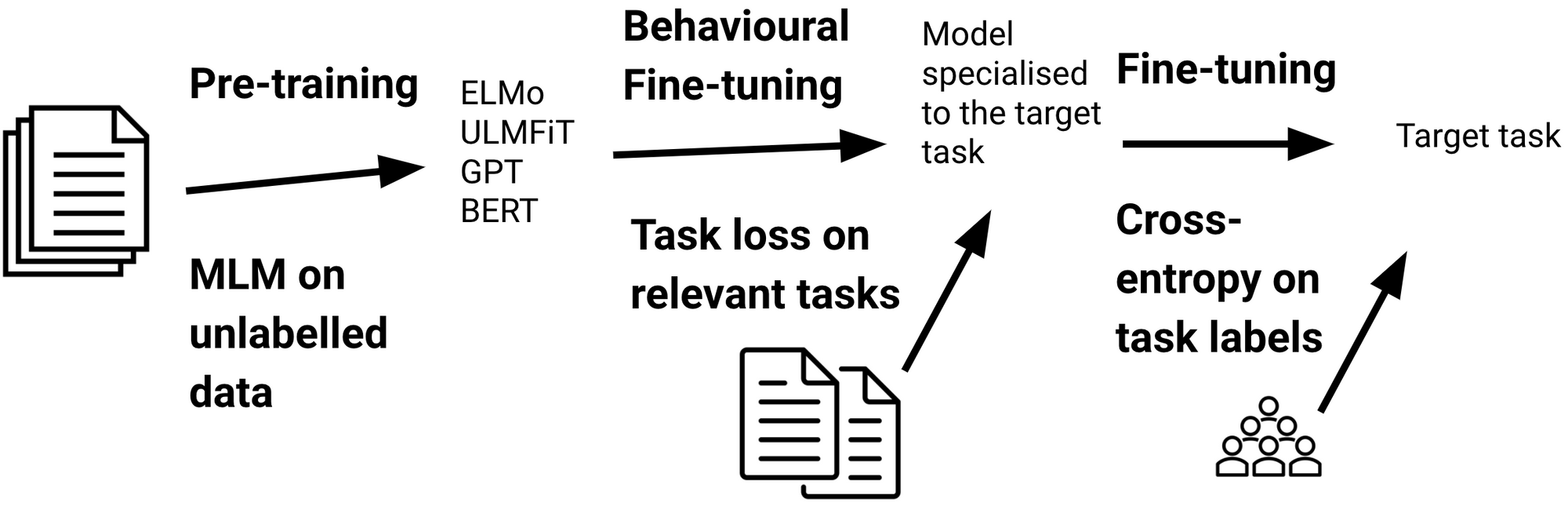
One option to educate a mannequin related capabilities is to fine-tune it on related labelled information of a associated activity previous to task-specific fine-tuning (Phang et al., 2018). This so-called intermediate-task coaching works greatest with duties that require high-level inference and reasoning capabilities (Pruksachatkun et al., 2020; Phang et al., 2020). Behavioural fine-tuning with labelled information has been used to show a mannequin details about named entities (Broscheit, 2019), paraphrasing (Arase and Tsujii, 2019), syntax (Glavaš and Vulić, 2020), reply sentence choice (Garg et al., 2020), and query answering (Khashabi et al., 2020). Aghajanyan et al. (2021) fine-tune on round 50 labelled datasets in a massively multi-task setting and observe that a big, various assortment of duties is necessary for good switch efficiency.
As supervised information of such high-level reasoning duties is mostly laborious to acquire, we are able to as an alternative prepare on targets that educate the mannequin capabilities which can be related for the downstream activity however which might nonetheless be discovered in a self-supervised method. As an illustration, Dou and Neubig (2021) fine-tune a mannequin for phrase alignment with an goal that teaches it to establish parallel sentences, amongst others. Sellam et al. (2020) fine-tune BERT for high quality analysis with a spread of sentence similarity alerts. In each instances, a range of studying alerts is necessary.
One other efficient means is to border the goal activity as a type of masked language modelling. To this finish, Ben-David et al. (2020) fine-tune a mannequin for sentiment area adaptation with a pivot-based goal. Others suggest pre-training targets, which can be utilized equally throughout fine-tuning: Ram et al. (2021) pre-train a mannequin for QA with a span choice activity whereas Bansal et al. (2020) pre-train a mannequin for few-shot studying by robotically producing cloze-style multi-class classification duties.
Distinguishing between adaptive and behavioural fine-tuning encourages us to contemplate the inductive biases we goal to instill in our mannequin and whether or not they relate to properties of the area $mathcal{D}$ or the duty $mathcal{T}$. Disentangling the function of area and activity is necessary as details about a site can typically be discovered utilizing restricted unlabelled information (Ramponi and Plank, 2020) whereas the acquisition of high-level pure language understanding abilities with present strategies usually requires billions of pre-training information samples (Zhang et al., 2020).
The excellence between activity and area turns into fuzzier, nevertheless, after we body duties by way of the pre-training goal. A sufficiently common pre-training activity similar to MLM might present helpful info for studying $P(Y | X)$ however probably doesn’t comprise each sign necessary for the duty. As an illustration, fashions pre-trained with MLM wrestle with modelling negations, numbers, or named entities (Rogers et al., 2020).
Equally, the usage of information augmentation entangles the roles of $mathcal{D}$ and $mathcal{T}$ because it permits us to encode the specified capabilities straight within the information. As an illustration, by fine-tuning a mannequin on textual content the place gendered phrases are changed with these of the alternative gender, a mannequin will be made extra sturdy to gender bias (Zhao et al., 2018; Zhao et al., 2019; Manela et al., 2021).
Parameter-efficient fine-tuning
When a mannequin must be fine-tuned in lots of settings similar to for numerous customers, it’s computationally costly to retailer a replica of a fine-tuned mannequin for each situation. Consequently, latest work has centered on retaining many of the mannequin parameters fastened and fine-tuning a small variety of parameters per activity. In follow, this allows storing a single copy of a big mannequin and lots of a lot smaller information with task-specific modifications.
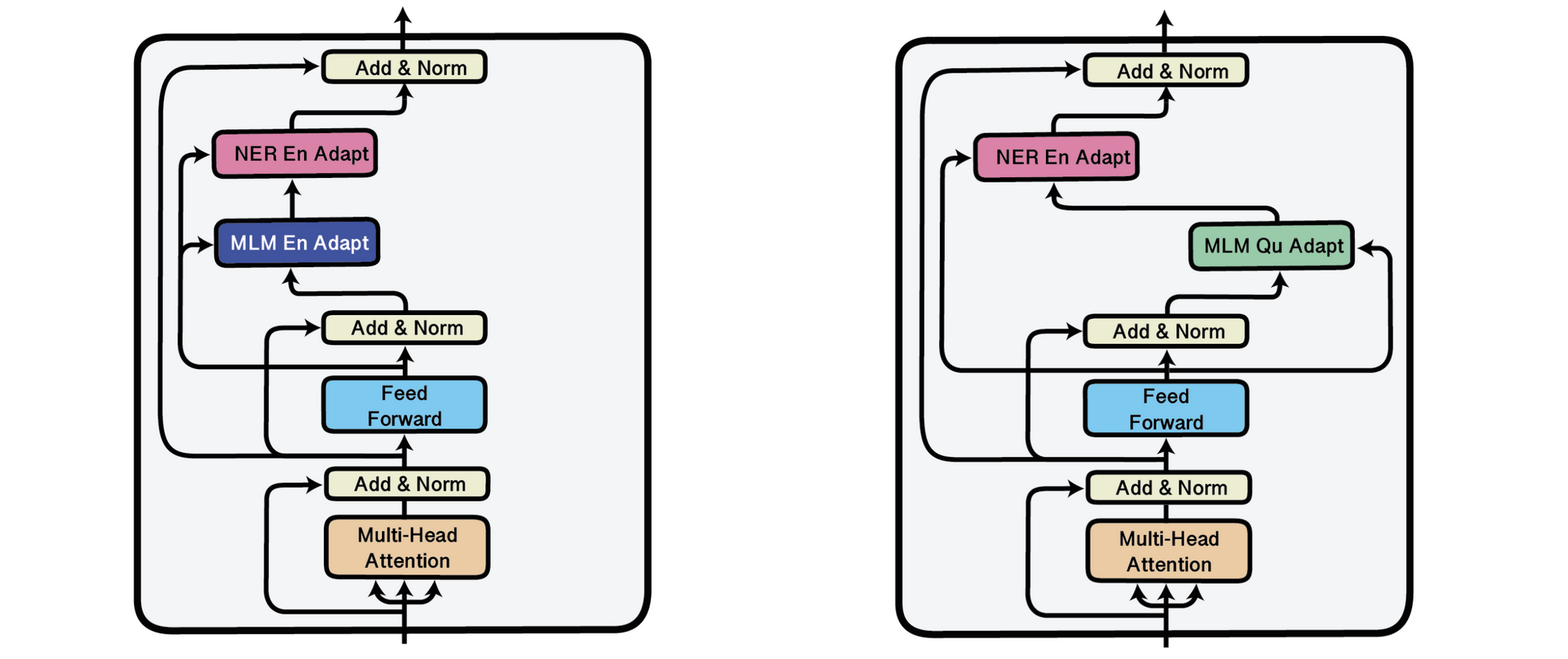
The primary approaches on this line of labor are primarily based on adapters (Rebuffi et al., 2017), small bottleneck layers which can be inserted between the layers of a pre-trained mannequin (Houlsby et al., 2019; Stickland and Murray, 2019) whose parameters are fastened. Adapters render widespread settings similar to storing a number of checkpoints throughout coaching in addition to extra superior methods similar to checkpoint averaging (Izmailov et al., 2018), snapshot ensembling (Huang et al., 2017) and temporal ensembling (Laine and Aila, 2017) way more space-efficient. Utilizing adapters, a general-purpose mannequin will be effectively tailored to many settings similar to totally different languages (Bapna and Firat, 2019). Pfeiffer et al. (2020) not too long ago demonstrated that adapters are modular and will be mixed through stacking, which permits studying specialised representations in isolation. That is notably helpful when working with the beforehand mentioned strategies: an adaptively or behaviourally fine-tuned adapter will be evaluated with none task-specific fine-tuning by stacking a educated activity adapter on prime of it. This setting will be seen under the place a activity adapter educated on named entity recognition (NER) is stacked on both an English (left) or Quechua language adapter (proper).
Whereas adapters modify the mannequin’s activations with out altering the underlying parameters, one other line of labor modifies the pre-trained parameters straight. For instance this set of strategies, we are able to view fine-tuning as studying how one can perturb the parameters of a pre-trained mannequin. Formally, with the intention to receive the parameters of a fine-tuned mannequin $theta_{textual content{fine-tuned}} in mathbb{R}^D$ the place $D$ is the dimensionality of the mannequin, we study a task-specific parameter vector $theta_{textual content{activity}} in mathbb{R}^D$ that captures how one can change the pre-trained mannequin parameters $theta_{textual content{pre-trained}} in mathbb{R}^D$. The fine-tuned parameters are the results of making use of the task-specific permutations to the pre-trained parameters:
start{equation}
theta_{textual content{fine-tuned}} = theta_{textual content{pre-trained}} + theta_{textual content{activity}}
finish{equation}
As an alternative of storing a replica of $theta_{textual content{fine-tuned}}$ for each activity, we are able to retailer a single copy of $theta_{textual content{pre-trained}}$ and a replica of $theta_{textual content{activity}}$ for each activity. This setting is cheaper if we are able to parameterise $theta_{textual content{activity}}$ extra effectively. To this finish, Guo et al. (2020) study $theta_{textual content{activity}}$ as a sparse vector. Aghajanyan et al. (2020) set $theta_{textual content{activity}} = theta_text{low} textbf{M}$ the place $theta_text{low}$ is a low-dimensional vector and $textbf{M}$ is a random linear projection (of their case, the FastFood remodel (Li et al., 2018)).
Alternatively, we are able to apply modifications solely to a subset of the pre-trained parameters. A basic methodology in laptop imaginative and prescient (Donahue et al., 2014) fine-tunes solely the final layer of the mannequin. Let $theta_{textual content{pre-trained}}$ be the gathering of pre-trained parameters throughout all $L$ layers of the mannequin, i.e. $theta_{textual content{pre-trained}} = bigcuplimits_{l=1}^{L} theta_{textual content{pre-trained}}^l$ the place $theta_{textual content{pre-trained}}^l$ is the parameter vector related to the $l$-th layer, with analogous notation for $theta_{textual content{fine-tuned}}$ and $theta_{textual content{activity}}$. Advantageous-tuning solely the final layer is then equal to:
start{equation}
start{cut up}
theta_{textual content{fine-tuned}} = & (bigcuplimits_{l=1}^{L-1} theta_{textual content{pre-trained}}^l)
& cup (theta_{textual content{pre-trained}}^L + theta_{textual content{activity}}^L)
finish{cut up}
finish{equation}
Whereas this works much less properly in NLP (Howard & Ruder, 2018), there are different subsets of parameters which can be simpler to fine-tune. As an illustration, Ben-Zaken et al. (2020) obtain aggressive efficiency by solely fine-tuning a mannequin’s bias parameters.
One other line of labor prunes parameters of the pre-trained mannequin throughout fine-tuning. Such strategies use totally different standards for pruning weights similar to primarily based on zero-th or first-order details about a weight’s significance (Sanh et al., 2020). As there may be restricted help of sparse architectures with present {hardware}, approaches which can be structurally sparse, i.e. the place updates are concentrated in a restricted set of layers, matrices, or vectors are presently preferable. As an illustration, the previous couple of layers of pre-trained fashions have been proven to be of restricted use throughout fine-tuning and will be randomly reinitialised (Tamkin et al., 2020; Zhang et al., 2021) and even utterly eliminated (Chung et al., 2021).
Whereas pruning strategies concentrate on lowering the entire variety of parameters of task-specific fashions, many of the different strategies concentrate on lowering the variety of trainable parameters—whereas sustaining a replica of $theta_{textual content{pre-trained}}$. The newest of the latter approaches usually match the efficiency of full fine-tuning whereas coaching round 0.5% of the mannequin’s parameters per activity (Pfeiffer et al., 2020; Guo et al., 2020; Ben-Zaken et al., 2020).
There’s growing proof that enormous pre-trained language fashions study representations that compress NLP duties properly (Li et al., 2018; Gordon et al., 2020; Aghajanyan et al., 2020). This sensible proof coupled with their comfort, availability (Pfeiffer et al., 2020) in addition to latest empirical successes make these strategies promising each for conducting experiments in addition to in sensible settings.
Textual content-to-text fine-tuning
One other growth in switch studying is a transfer from masked language fashions similar to BERT (Devlin et al., 2019) and RoBERTa (Liu et al., 2019) to autoregressive fashions of language similar to T5 (Raffel et al., 2019) and GPT-3 (Brown et al., 2020). Whereas each units of strategies can be utilized to assign chance scores to textual content (Salazar et al., 2020), autoregressive LMs are simpler to pattern from. In distinction, masked LMs are usually restricted to fill-in-the-blank settings, e.g. (Petroni et al., 2019).
The usual means to make use of masked LMs for fine-tuning is to exchange the output layer used for MLM with a randomly initialised task-specific head that’s discovered on the goal activity (Devlin et al., 2019). Alternatively, the pre-trained mannequin’s output layer will be reused by recasting a activity as MLM in a cloze-style format (Talmor et al., 2020; Schick and Schütze, 2021). Analogously, autoregressive LMs usually solid the goal activity in a text-to-text format (McCann et al., 2018; Raffel et al., 2020; Paolini et al., 2021). In each settings, the fashions are capable of profit from all their pre-trained data and don’t must study any new parameters from scratch, which improves their pattern effectivity.
Within the excessive when no parameters are fine-tuned, framing a goal activity by way of the pre-training goal permits zero-shot or few-shot studying utilizing a task-specific immediate and a small variety of examples of a activity (Brown et al., 2020). Nonetheless, whereas such few-shot studying is feasible, it isn’t the best means to make use of such fashions (Schick and Schütze, 2020; see this publish for a short overview). Studying with out updates requires an enormous mannequin because the mannequin must rely completely on its current data. The quantity of data out there to the mannequin can be restricted by its context window and the prompts proven to the mannequin have to be fastidiously engineered.
Retrieval augmentation (see this publish for an summary) can be utilized to off-load the storage of exterior data and symbolic approaches might be used to show a mannequin task-specific guidelines akin to (Awasthi et al., 2020). Pre-trained fashions may also turn into bigger and extra highly effective and could also be behaviourally fine-tuned to be good on the zero-shot setting. Nonetheless, with out fine-tuning a mannequin is in the end restricted in its potential to adapt to a brand new activity.
Consequently, for many sensible settings one of the best path ahead arguably is to fine-tune all or a subset of the mannequin’s parameters utilizing the strategies described within the earlier sections. As well as, we’ll more and more see an emphasis of pre-trained fashions’ generative capabilities. Whereas present strategies usually concentrate on modifying a mannequin’s pure language enter similar to through computerized immediate design (Schick and Schütze, 2020; Gao et al., 2020; Shin et al., 2020), the best option to modulate the output of such fashions will probably act straight on their hidden representations (Dathathri et al., 2020; see Lillian Weng’s publish for an summary of strategies for controllable era).
Mitigating fine-tuning instabilities
A sensible drawback with fine-tuning pre-trained fashions is that efficiency can range drastically between totally different runs, notably on small datasets (Phang et al., 2018). Dodge et al., 2020 discover that each the load initialisation of the output layer and the order of the coaching information contribute to variation in efficiency. As instabilities are usually obvious early in coaching, they advocate stopping the least promising runs early after 20-30% of coaching. Mosbach et al. (2021) moreover advocate utilizing small studying charges and to extend the variety of epochs when fine-tuning BERT.
A variety of latest strategies search to mitigate instabilities throughout fine-tuning by counting on adversarial or belief region-based approaches (Zhu et al., 2019; Jiang et al., 2020; Aghajanyan et al., 2021). Such strategies usually increase the fine-tuning loss with a regularisation time period that bounds the divergence between replace steps.
In mild of the earlier part, we are able to make one other suggestion for minimising instabilities throughout fine-tuning: Keep away from utilizing a randomly initialised output layer on the goal activity for small datasets by framing the goal activity as a type of LM or use behavioural fine-tuning to fine-tune the output layer previous to task-specific fine-tuning. Whereas text-to-text fashions are thus extra sturdy to fine-tuning on small datasets, they undergo from instabilities within the few-shot setting and are delicate to the immediate and few-shot examples (Zhao et al., 2021).
General, as fashions are more and more utilized to difficult duties with fewer coaching examples, it’s essential to develop strategies which can be sturdy to potential variations and that may be reliably fine-tuned.
Quotation
For attribution in educational contexts, please cite this work as:
@misc{ruder2021lmfine-tuning,
writer = {Ruder, Sebastian},
title = {{Current Advances in Language Mannequin Advantageous-tuning}},
yr = {2021},
howpublished = {url{http://ruder.io/recent-advances-lm-fine-tuning}},
}
{kind=link}