
For many entrepreneurs, fixed updates are wanted to maintain their web site recent and enhance their search engine optimisation rankings.
Nonetheless, some websites have tons of and even hundreds of pages, making it a problem for groups that manually push the updates to search engines like google and yahoo. If the content material is being up to date so incessantly, how can groups be sure that these enhancements are impacting their search engine optimisation rankings?
That’s the place crawler bots come into play. An internet crawler bot will scrape your sitemap for brand spanking new updates and index the content material into search engines like google and yahoo.
On this put up, we’ll define a complete crawler checklist that covers all the online crawler bots that you must know. Earlier than we dive in, let’s outline net crawler bots and present how they perform.
What Is a Internet Crawler?
An internet crawler is a pc program that routinely scans and systematically reads net pages to index the pages for search engines like google and yahoo. Internet crawlers are also referred to as spiders or bots.
For search engines like google and yahoo to current up-to-date, related net pages to customers initiating a search, a crawl from an online crawler bot should happen. This course of can typically occur routinely (relying on each the crawler’s and your web site’s settings), or it may be initiated straight.
Many elements influence your pages’ search engine optimisation rating, together with relevancy, backlinks, website hosting, and extra. Nonetheless, none of those matter in case your pages aren’t being crawled and listed by search engines like google and yahoo. That’s the reason it’s so very important to ensure that your web site is permitting the right crawls to happen and eradicating any boundaries of their approach.
Bots should frequently scan and scrape the online to make sure probably the most correct data is offered. Google is probably the most visited web site in the US, and roughly 26.9% of searches come from American customers:
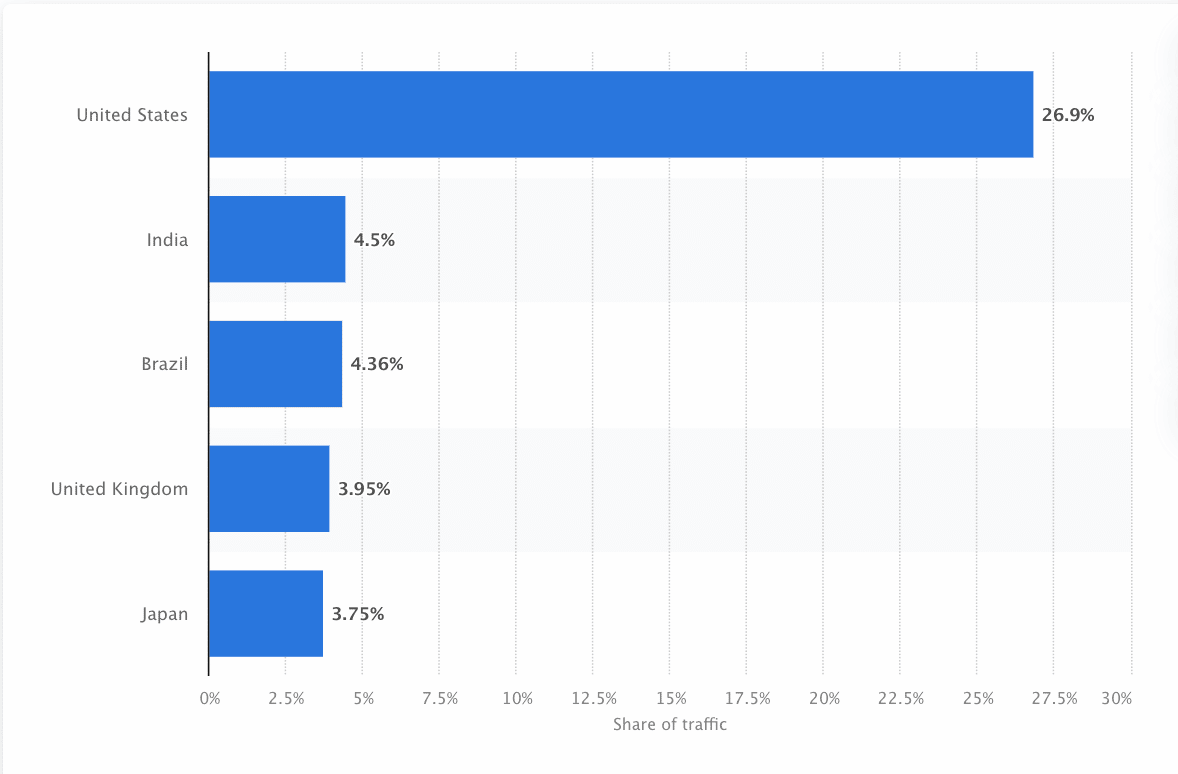
Nonetheless, there isn’t one net crawler that crawls for each search engine. Every search engine has distinctive strengths, so builders and entrepreneurs typically compile a “crawler checklist.” This crawler checklist helps them determine completely different crawlers of their web site log to just accept or block.
Entrepreneurs must assemble a crawler checklist stuffed with the completely different net crawlers and perceive how they consider their web site (not like content material scrapers that steal the content material) to make sure that they optimize their touchdown pages appropriately for search engines like google and yahoo.
How Does a Internet Crawler Work?
An internet crawler will routinely scan your net web page after it’s printed and index your information.
Internet crawlers search for particular key phrases related to the online web page and index that data for related search engines like google and yahoo like Google, Bing, and extra.
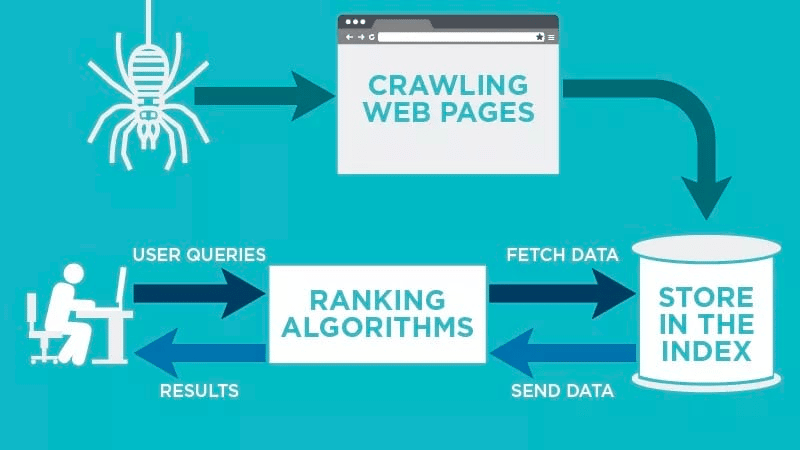
Algorithms for the various search engines will fetch that information when a consumer submits an inquiry for the related key phrase that’s tied to it.
Crawls begin with identified URLs. These are established net pages with numerous alerts that direct net crawlers to these pages. These alerts could possibly be:
- Backlinks: The variety of occasions a web site hyperlinks to it
- Guests: How a lot site visitors is heading to that web page
- Area Authority: The general high quality of the area
Then, they retailer the info within the search engine’s index. Because the consumer initiates a search question, the algorithm will fetch the info from the index, and it’ll seem on the search engine outcomes web page. This course of can happen inside a couple of milliseconds, which is why outcomes usually seem shortly.
As a webmaster, you may management which bots crawl your web site. That’s why it’s vital to have a crawler checklist. It’s the robots.txt protocol that lives inside every web site’s servers that directs crawlers to new content material that must be listed.
Relying on what you enter into your robots.txt protocol on every net web page, you may inform a crawler to scan or keep away from indexing that web page sooner or later.
By understanding what an online crawler appears for in its scan, you may perceive tips on how to higher place your content material for search engines like google and yahoo.
Compiling Your Crawler Record: What Are the Totally different Forms of Internet Crawlers?
As you begin to consider compiling your crawler checklist, there are three most important varieties of crawlers to search for. These embrace:
- In-house Crawlers: These are crawlers designed by an organization’s growth workforce to scan its web site. Usually they’re used for web site auditing and optimization.
- Business Crawlers: These are custom-built crawlers like Screaming Frog that firms can use to crawl and effectively consider their content material.
- Open-Supply Crawlers: These are free-to-use crawlers which might be constructed by a wide range of builders and hackers world wide.
It’s vital to know the various kinds of crawlers that exist so you recognize which sort that you must leverage in your personal enterprise targets.
The 11 Most Widespread Internet Crawlers to Add to Your Crawler Record
There isn’t one crawler that does all of the work for each search engine.
As a substitute, there are a number of net crawlers that consider your net pages and scan the content material for all the various search engines obtainable to customers world wide.
Let’s take a look at a few of the most typical net crawlers immediately.
1. Googlebot
Googlebot is Google’s generic net crawler that’s chargeable for crawling websites that can present up on Google’s search engine.

Though there are technically two variations of Googlebot—Googlebot Desktop and Googlebot Smartphone (Cellular)—most consultants take into account Googlebot one singular crawler.
It is because each observe the identical distinctive product token (often called a consumer agent token) written in every web site’s robots.txt. The Googlebot consumer agent is solely “Googlebot.”
Googlebot goes to work and sometimes accesses your web site each few seconds (except you’ve blocked it in your web site’s robots.txt). A backup of the scanned pages is saved in a unified database referred to as Google Cache. This allows you to have a look at previous variations of your web site.
As well as, Google Search Console can be one other instrument site owners use to know how Googlebot is crawling their web site and to optimize their pages for search.
2. Bingbot
Bingbot was created in 2010 by Microsoft to scan and index URLs to make sure that Bing affords related, up-to-date search engine outcomes for the platform’s customers.
Very similar to Googlebot, builders or entrepreneurs can outline of their robots.txt on their web site whether or not or not they approve or deny the agent identifier “bingbot” to scan their web site.
As well as, they’ve the flexibility to tell apart between mobile-first indexing crawlers and desktop crawlers since Bingbot just lately switched to a brand new agent sort. This, together with Bing Webmaster Instruments, supplies site owners with better flexibility to indicate how their web site is found and showcased in search outcomes.
3. Yandex Bot
Yandex Bot is a crawler particularly for the Russian search engine, Yandex. This is likely one of the largest and hottest search engines like google and yahoo in Russia.

Site owners could make their web site pages accessible to Yandex Bot by means of their robots.txt file.
As well as, they might additionally add a Yandex.Metrica tag to particular pages, reindex pages within the Yandex Webmaster or concern an IndexNow protocol, a singular report that factors out new, modified, or deactivated pages.
4. Apple Bot
Apple commissioned the Apple Bot to crawl and index webpages for Apple’s Siri and Highlight Options.
Apple Bot considers a number of elements when deciding which content material to raise in Siri and Highlight Options. These elements embrace consumer engagement, the relevance of search phrases, quantity/high quality of hyperlinks, location-based alerts, and even webpage design.
5. DuckDuck Bot
The DuckDuckBot is the online crawler for DuckDuckGo, which affords “Seamless privateness safety in your net browser.”
Site owners can use the DuckDuckBot API to see if the DuckDuck Bot has crawled their web site. Because it crawls, it updates the DuckDuckBot API database with current IP addresses and consumer brokers.
This helps site owners determine any imposters or malicious bots attempting to be related to DuckDuck Bot.
6. Baidu Spider
Baidu is the main Chinese language search engine, and the Baidu Spider is the location’s sole crawler.

Google is banned in China, so it’s vital to allow the Baidu Spider to crawl your web site if you wish to attain the Chinese language market.
To determine the Baidu Spider crawling your web site, search for the next consumer brokers: baiduspider, baiduspider-image, baiduspider-video, and extra.
If you happen to’re not doing enterprise in China, it might make sense to dam the Baidu Spider in your robots.txt script. This can forestall the Baidu Spider from crawling your web site, thereby eradicating any likelihood of your pages showing on Baidu’s search engine outcomes pages (SERPs).
7. Sogou Spider
Sogou is a Chinese language search engine that’s reportedly the primary search engine with 10 billion Chinese language pages listed.

If you happen to’re doing enterprise within the Chinese language market, that is one other standard search engine crawler that you must learn about. The Sogou Spider follows the robotic’s exclusion textual content and crawl delay parameters.
As with the Baidu Spider, in the event you don’t wish to do enterprise within the Chinese language market, it is best to disable this spider to forestall sluggish web site load occasions.
8. Fb Exterior Hit
Fb Exterior Hit, in any other case often called the Fb Crawler, crawls the HTML of an app or web site shared on Fb.

This allows the social platform to generate a sharable preview of every hyperlink posted on the platform. The title, description, and thumbnail picture seem due to the crawler.
If the crawl isn’t executed inside seconds, Fb is not going to present the content material within the {custom} snippet generated earlier than sharing.
9. Exabot
Exalead is a software program firm created in 2000 and headquartered in Paris, France. The corporate supplies search platforms for shopper and enterprise purchasers.
Exabot is the crawler for his or her core search engine constructed on their CloudView product.
Like most search engines like google and yahoo, Exalead elements in each backlinking and the content material on net pages when rating. Exabot is the consumer agent of Exalead’s robotic. The robotic creates a “most important index” which compiles the outcomes that the search engine customers will see.
10. Swiftbot
Swiftype is a {custom} search engine in your web site. It combines “the most effective search expertise, algorithms, content material ingestion framework, purchasers, and analytics instruments.”
When you’ve got a posh web site with many pages, Swiftype affords a helpful interface to catalog and index all of your pages for you.
Swiftbot is Swiftype’s net crawler. Nonetheless, not like different bots, Swiftbot solely crawls websites that their prospects request.
11. Slurp Bot
Slurp Bot is the Yahoo search robotic that crawls and indexes pages for Yahoo.
This crawl is important for each Yahoo.com in addition to its companion websites together with Yahoo Information, Yahoo Finance, and Yahoo Sports activities. With out it, related web site listings wouldn’t seem.
The listed content material contributes to a extra customized net expertise for customers with extra related outcomes.
The 8 Business Crawlers search engine optimisation Professionals Must Know
Now that you’ve got 11 of the most well-liked bots in your crawler checklist, let’s take a look at a few of the widespread business crawlers and search engine optimisation instruments for professionals.
1. Ahrefs Bot
The Ahrefs Bot is an online crawler that compiles and indexes the 12 trillion hyperlink database that standard search engine optimisation software program, Ahrefs, affords.
The Ahrefs Bot visits 6 billion web sites each day and is taken into account “the second most lively crawler” behind solely Googlebot.
Very similar to different bots, the Ahrefs Bot follows robots.txt features, in addition to permits/disallows guidelines in every web site’s code.
2. Semrush Bot
The Semrush Bot permits Semrush, a number one search engine optimisation software program, to gather and index web site information for its prospects’ use on its platform.
The information is utilized in Semrush’s public backlink search engine, the location audit instrument, the backlink audit instrument, hyperlink constructing instrument, and writing assistant.
It crawls your web site by compiling a listing of net web page URLs, visiting them, and saving sure hyperlinks for future visits.
3. Moz’s Marketing campaign Crawler Rogerbot
Rogerbot is the crawler for the main search engine optimisation web site, Moz. This crawler is particularly gathering content material for Moz Professional Marketing campaign web site audits.

Rogerbot follows all guidelines set forth in robots.txt recordsdata, so you may determine if you wish to block/enable Rogerbot from scanning your web site.
Site owners will be unable to seek for a static IP handle to see which pages Rogerbot has crawled as a result of its multifaceted method.
4. Screaming Frog
Screaming Frog is a crawler that search engine optimisation professionals use to audit their very own web site and determine areas of enchancment that can influence their search engine rankings.

As soon as a crawl is initiated, you may evaluate real-time information and determine damaged hyperlinks or enhancements which might be wanted to your web page titles, metadata, robots, duplicate content material, and extra.
In an effort to configure the crawl parameters, you could buy a Screaming Frog license.
5. Lumar (previously Deep Crawl)
Lumar is a “centralized command middle for sustaining your web site’s technical well being.” With this platform, you may provoke a crawl of your web site that will help you plan your web site structure.
Lumar prides itself because the “quickest web site crawler available on the market” and boasts that it could crawl as much as 450 URLs per second.
6. Majestic
Majestic primarily focuses on monitoring and figuring out backlinks on URLs.

The corporate prides itself on having “one of the complete sources of backlink information on the Web,” highlighting its historic index which has elevated from 5 to fifteen years of hyperlinks in 2021.
The location’s crawler makes all of this information obtainable to the corporate’s prospects.
7. cognitiveSEO
cognitiveSEO is one other vital search engine optimisation software program that many professionals use.
The cognitiveSEO crawler permits customers to carry out complete web site audits that can inform their web site structure and overarching search engine optimisation technique.
The bot will crawl all pages and supply “a completely personalized set of information” that’s distinctive for the tip consumer. This information set may also have suggestions for the consumer on how they’ll enhance their web site for different crawlers—each to influence rankings and block crawlers which might be pointless.
8. Oncrawl
Oncrawl is an “industry-leading search engine optimisation crawler and log analyzer” for enterprise-level purchasers.
Customers can arrange “crawl profiles” to create particular parameters for the crawl. It can save you these settings (together with the beginning URL, crawl limits, most crawl pace, and extra) to simply run the crawl once more underneath the identical established parameters.
Do I Must Shield My Website from Malicious Internet Crawlers?
Not all crawlers are good. Some might negatively influence your web page pace, whereas others might attempt to hack your web site or have malicious intentions.
That’s why it’s vital to know tips on how to block crawlers from coming into your web site.
By establishing a crawler checklist, you’ll know which crawlers are the nice ones to look out for. Then, you may weed by means of the fishy ones and add them to your block checklist.
How To Block Malicious Internet Crawlers
Along with your crawler checklist in hand, you’ll be capable of determine which bots you wish to approve and which of them that you must block.
Step one is to undergo your crawler checklist and outline the consumer agent and full agent string that’s related to every crawler in addition to its particular IP handle. These are key figuring out elements which might be related to every bot.
With the consumer agent and IP handle, you may match them in your web site data by means of a DNS lookup or IP match. If they don’t match precisely, you may need a malicious bot making an attempt to pose because the precise one.
Then, you may block the imposter by adjusting permissions utilizing your robots.txt web site tag.
Abstract
Internet crawlers are helpful for search engines like google and yahoo and vital for entrepreneurs to know.
Guaranteeing that your web site is crawled appropriately by the correct crawlers is vital to your corporation’s success. By conserving a crawler checklist, you may know which of them to be careful for once they seem in your web site log.
As you observe the suggestions from business crawlers and enhance your web site’s content material and pace, you’ll make it simpler for crawlers to entry your web site and index the correct data for search engines like google and yahoo and the shoppers searching for it.
Save time, prices and maximize web site efficiency with:
- Instantaneous assist from WordPress internet hosting consultants, 24/7.
- Cloudflare Enterprise integration.
- World viewers attain with 35 information facilities worldwide.
- Optimization with our built-in Software Efficiency Monitoring.
All of that and way more, in a single plan with no long-term contracts, assisted migrations, and a 30-day-money-back-guarantee. Try our plans or speak to gross sales to search out the plan that’s best for you.

{kind=link}