
The artwork of querying SQL Databases in Pure Language

“the way forward for BI is Conversational” — that is what Gartner and different analysts have been telling us for the previous few years.
Let’s concentrate on structured information, relational information to be extra exact. This varieties the underlying storage format for a lot of the Enterprise Intelligence (BI) world, regardless of whether or not you might be querying the database interactively or constructing a report in Tableau, Energy BI, Qlik Sense, and so forth. The predominant language to work together with such storage platforms is SQL. We’ve already seen some merchandise on this house, e.g., Energy BI Q&A, Salesforce Photon.
We’re speaking about translating a Pure Language Question (NLQ) to SQL on this article, also referred to as a Pure Language Interface to Databases (NLIDB).
For instance, allow us to think about a Nation desk with Language and Inhabitants particulars — illustrative schema beneath:
Nation desk: Nation ID | Identify | Language | Inhabitants Depend
NLQ1: Which nation has the utmost inhabitants depend?
SQL1: Choose Identify, max([Population Count]) from Nation;
On the core of most Pure Language Q&A techniques [1], is a Pure Language Understanding Unit (NLU) module that’s attempting to know the NLQ’s intent by extracting and classifying the ‘utterances’. In easy phrases, one can consider utterances as the important thing phrases within the sentence, e.g., nation, most, inhabitants, depend.

The subsequent step is to generate the corresponding SQL question primarily based on this data. So we’d like a metamorphosis / mapping logic to map ‘nation’ to the ‘Nation’ desk (the desk to be queried), ‘most’ to the ‘max’ SQL operator, ‘inhabitants depend’ to the column ‘inhabitants depend’. And, that is the place issues begin to get difficult.
Mapping NLQ utterances to the proper SQL operators, esp., in figuring out if an utterance corresponds to a Desk, Column, Major / International Key, SQL operator, within the first place —is non-trivial.
For instance, with none inherent information of the database schema, it is rather troublesome for the mapping logic to find out that the ‘depend’ on this case refers to column ‘inhabitants depend’ , and never the SQL operator COUNT. The issue will get amplified for advanced queries, e.g.,
NLQ2: Which language is spoken by most variety of nations?
whose SQL translation would contain each the SQL operators: MAX & COUNT. Different examples of advanced queries embody situations the place we have to JOIN a number of tables.
On this part, we do do a deep dive into the issue area, reflecting on current literature / approaches — to know the technical challenges concerned.
There are two benchmark datasets which can be primarily referenced on this subject:
- WikiSQL: is a big annotated corpus for creating pure language interfaces, which was launched together with the paper [2].
- Spider is a large-scale annotated semantic parsing and text-to-SQL dataset. SParC is the context-dependent/multi-turn model of Spider, and CoSQL is the dialogue model of Spider and SParC datasets. For an in depth dialogue, check with the accompanying paper [3].
As Spider highlights in its introductory textual content, any NLIDB answer must not solely perceive the underlying database schema, however it ought to generalize to new schemas as properly. The generalization problem lies in (a) encoding the database schema for the semantic parser, and (b) modeling alignment between database columns, keys, and their mentions in a given NLQ [4].
With this context, allow us to check out some works which have tried to encode (the lacking) database schema information into neural networks. Directed graphs are a preferred formalism to encode database schema relationships.[4] presents a unified framework to deal with schema encoding, linking, and have illustration inside a text-to-SQL encoder. [5] encodes the database schema with a graph neural community, and this illustration is used at each encoding and decoding time in an encoder-decoder semantic parser. [6] presents a database schema interplay graph encoder to make the most of historic data of database schema gadgets. Within the decoding section, a gate mechanism is used to to weigh the significance of various vocabularies after which make a prediction of SQL tokens.
Pre-trained giant language fashions [7] as text-to-SQL mills assist to a sure extent, esp., with respect to encoding desk and column names by making the most of the eye mechanism [8]. Nevertheless, they nonetheless wrestle with schema relationships for advanced SQL operation.
The papers present important progress in embedding database schemas, nevertheless, they’re nonetheless particular to the datasets into consideration; and don’t generalize properly to new domains / schemas.
On this part, we think about approaches to finest add this lacking area information / database schema relationships to a text-to-SQL generator.
Guide strategy
Nearly all of Q&A techniques in the present day encompass a Pure Language Understanding (NLU) unit skilled to acknowledge the person’s question in a supervised method. This consists of Q&A techniques out there available in the market in the present day, e.g., Google DialogFlow, Amazon Lex, Microsoft LUIS, RASA.
So that they first must be skilled by offering a set of NLQs, query variations, and their corresponding solutions — which on this case could be the corresponding SQL queries.
Along with ‘intents’ and ‘utterances’, a vital half in customizing Q&A techniques is to supply ‘entities’ [9]. The entities check with the area particular vocabulary, e.g., they’ll check with the workplace places of a corporation, within the context of an HR app.
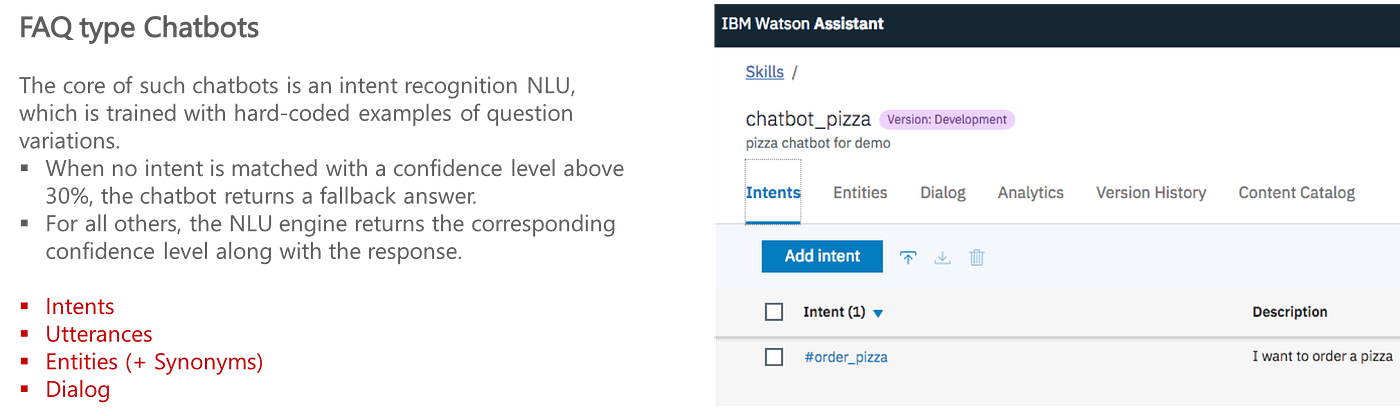
The purpose right here is that just like configuring / coaching Chatbots, we are able to additionally enter the area information within the type of a database schema manually on this case — to enhance the text-to-SQL era in NLIDB techniques.
To make clear, a SQL parser can extract the desk, column names, key relationships, and so forth., from the underlying Knowledge Definition Language (DDL) specification file.
So the information that must be entered manually on this case is the pure language description of tables, columns, and their relationships — which is lacking from most database documentations.
Whereas handbook enrichment works, and is usually probably the most dependable strategy; you will need to recall right here that NLIDB techniques are primarily meant for enterprise customers, customers of experiences / dashboards; who might not be very comfy with technical information entry. Additionally, this isn’t one-time information entry, and the encoded area information will must be tailored each time the underlying database schema modifications.
Automated approaches primarily based on Energetic / Reinforcement Studying
A great way to bootstrap text-to-SQL mills is by studying from current SQL question logs and BI experiences. It’s honest to say that the majority NLIDB techniques will complement current BI platforms. So it is smart to leverage historic SQL logs and current experiences / dashboards to get an understanding of probably the most ceaselessly requested SQL queries, and consequently the NLQs that can be utilized for preliminary coaching.
The generalization capability of this preliminary mannequin could be improved by introducing an auxiliary process, which may explicitly be taught the mapping between entities within the NLQ and desk, column, key names within the schema [10]. Latest works have prolonged this to few shot studying duties (energetic studying setting normally), e.g., [11] proposes an environment friendly meta-learning technique that makes use of a two-step gradient replace to power the mannequin to be taught a generalization capability in direction of zero-shot tables.
Reinforcement Studying (RL) approaches are additionally attention-grabbing on this context, the place a Deep Q-Community (DQN) agent could be skilled to ‘rating’ novel (unseen) queries, such that they are often successfully added to reinforce the (offline) coaching dataset. As an illustration, [12] proposes a RL primarily based self-improving enterprise chatbot that reveals a rise in efficiency from an preliminary 50% success price to 75% in 20–30 coaching epochs.
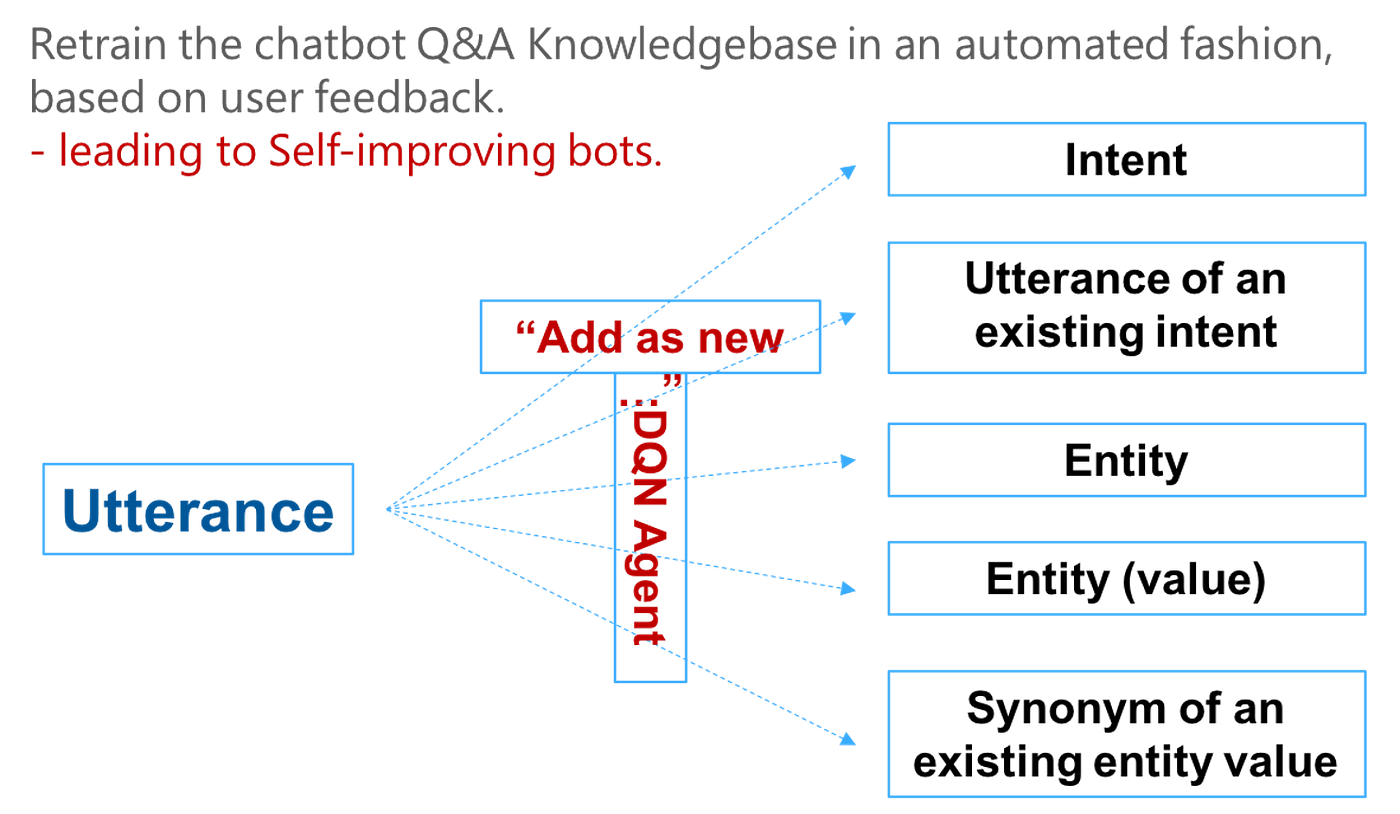
We conclude with some ideas for the long run. With text-to-SQL, the primary purpose has been to recreate the SQL querying to databases paradigm, to at least one utilizing Pure Language Queries (NLQs).
We consider that Conversational BI can be way more disruptive, in enabling new methods of interacting with databases (or information shops normally).
As an illustration:
- Metadata Bot: Given the complexity of enterprise databases, and the following problem in encoding them; could also be we’ve been approaching the issue wrongly to start out them. If we are able to present the customers with a Q&A system (let’s name it Meta Bot — meta as in metadata queries, and nothing to do with Meta / Fb) that may reply queries reg. the database schema, e.g., ‘Which desk comprises the Gross sales information for Switzerland?’ along with some kind of auto-complete for SQL operators, e.g., ‘Do we’ve the Gross sales Knowledge for Germany and Spain in a single desk?’, answered by a be part of / filter on the respective desk(s); the customers will be capable of compose their SQL queries effectively, with out the necessity for any superior SQL information.
- Incremental queries: The earlier level already alludes to it. Queries in the present day are principally one-shot. Our conversations then again have a movement — we proceed what has been mentioned earlier than — primarily based on historic context. Sure, a saved process performs SQL queries in sequence, nevertheless, it’s pre-defined logic. Conversational BI would allow incrementally refining the question leads to real-time, till the person finds the information that that he / she is in search of in real-time.
- D. Biswas. Chatbots & Pure Language Search. In direction of Knowledge Science, https://towardsdatascience.com/chatbots-natural-language-search-cc097f671b2b
- Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2SQL: Producing Structured Queries from Pure Language utilizing Reinforcement Studying. https://arxiv.org/abs/1709.00103
- Tao Yu, et al. 2018. Spider: A big-scale Human-labeled Dataset for Advanced and Cross-domain Semantic Parsing and Textual content-to-Sql Activity. https://arxiv.org/abs/1809.08887
- Bailin Wang, et. al. 2020. RAT-SQL: Relation-Conscious Schema Encoding and Linking for Textual content-to-SQL Parsers. In Proc. of the 58th Annual Assembly of the Affiliation for Computational Linguistics. https://doi.org/10.18653/v1/ 2020.acl-main.677
- Ben Bogin, Matt Gardner, Jonathan Berant (2019). Representing Schema Construction with Graph Neural Networks for Textual content-to-SQL Parsing. ACL, https://arxiv.org/pdf/1905.06241.pdf
- Yitao Cai and Xiaojun Wan. 2020. IGSQL: Database Schema Interplay Graph Primarily based Neural Mannequin for Context-Dependent Textual content-to-SQL Technology. In Proc. of the 2020 Convention on Empirical Strategies in Pure Language Processing (EMNLP), https://aclanthology.org/2020.emnlp-main.560.pdf
- Lin, X.V., Socher, R., & Xiong, C. (2020). Bridging Textual and Tabular Knowledge for Cross-Area Textual content-to-SQL Semantic Parsing. FINDINGS. https://arxiv.org/abs/2012.12627
- Bahdanau, Dzmitry, Kyunghyun Cho and Yoshua Bengio. Neural Machine Translation by Collectively Studying to Align and Translate. https://arxiv.org/pdf/1409.0473.pdf
- W. Shalaby, A. Arantes, T. G. Diaz, and C. Gupta. Constructing chatbots from giant scale domain-specific information bases: Challenges and alternatives, 2020, https://arxiv.org/pdf/2001.00100.pdf
- Chang, S., Liu, P., Tang, Y., Huang, J., He, X., & Zhou, B. (2020). Zero-shot Textual content-to-SQL Studying with Auxiliary Activity. AAAI, https://arxiv.org/pdf/1908.11052.pdf
- Chen, Y., Guo, X., Wang, C., Qiu, J., Qi, G., Wang, M., & Li, H. (2021). Leveraging Desk Content material for Zero-shot Textual content-to-SQL with Meta-Studying. AAAI, https://arxiv.org/pdf/2109.05395.pdf
- E. Ricciardelli, D. Biswas. Self-improving Chatbots primarily based on Reinforcement Studying. RLDM 2019, https://towardsdatascience.com/self-improving-chatbots-based-on-reinforcement-learning-75cca62debce

{kind=link}