Get Up to date with the Newest Tendencies on GitHub in Your Native Machine
GitHub feed is an effective way so that you can comply with together with what’s trending in the neighborhood. You may uncover some helpful repositories by taking a look at what your connections have starred.

Nevertheless, there is likely to be some repositories you don’t care about. For instance, you is likely to be solely concerned about Python repositories, however there are repositories written in different languages in your GitHub feed. Thus, it could take you some time to seek out helpful libraries.
Wouldn’t it’s good in the event you can create a private dashboard exhibiting the repositories that your connections adopted, filtered by your favourite language like beneath?

On this article, we are going to discover ways to do precisely that, with GitHub API + Streamlit + Prefect.
At a excessive stage, we are going to:
- Use GitHub API to jot down scripts to tug the information from GitHub
- Use Streamlit to create a dashboard displaying the statistics of the processed information
- Use Prefect to schedule to run the scripts to get and course of information every day

If you wish to skip by means of the reasons and go straight to creating your individual dashboard, view this GitHub repository:
To drag information from GitHub, you want your username and an entry token. Subsequent, create the file known as .env to save lots of your GitHub authentication.
Add .env to your .gitignore file to make sure that .env just isn’t tracked by Git.
Within the file process_data.py below the improvement listing, we are going to write code to entry the knowledge within the file .env utilizing python-dotenv:
Subsequent, we are going to get the final data of public repositories we acquired in our GitHub feed utilizing GitHub API. The GitHub API permits us to simply get information out of your GitHub account together with occasions, repositories, and so forth.
We are going to use pydash to get the URLs of all starred repositories from a listing of repositories:
Get the precise data of every starred repository reminiscent of language, stars, house owners, pull requests, and so forth:
The data extracted from every repo ought to look just like this.
Save the information to the native listing:
Put all the things collectively:
The present script works, however to guarantee that it’s resilient towards failures, we are going to use Prefect so as to add observability, caching, and retries to our present workflow.
Prefect is an open-source library that allows you to orchestrate your information workflow in Python.
Add Observability
As a result of it takes some time to run the file get_data.py, we would need to know which code is being executed and roughly how for much longer we have to wait. We are able to add Prefect’s decorators to our capabilities to get extra perception into the state of every operate.
Particularly, we add the decorator @activity to the capabilities that do one factor and add the decorator @circulation to the operate that comprises a number of duties.
Within the code beneath, we add the decorator @circulation to the operate get_data since get_data comprises all duties.
You need to see the beneath output when operating this Python script:
From the output, we all know which duties are accomplished and which of them are in progress.
Caching
In our present code, the operate get_geneneral_info_of_repos takes some time to run. If the operate get_specific_info_of_repos failed, we have to rerun the whole pipeline once more and look ahead to the operate get_geneneral_info_of_repos to run.

To scale back the execution time, we will use Prefect’s caching to save lots of the outcomes of get_general_info_of_repos within the first run after which reuse the leads to the second run.

Within the file get_data.py, we add caching to the duties get_general_info_of_repos , get_starred_repo_urls , and get_specific_info_of_repos as a result of they take fairly a little bit of time to run.
So as to add caching to a activity, specify the values for the arguments cache_key_fn and cach_expiration.
Within the code above,
cache_key_fn=task_input_hashtells Prefect to make use of the cached outcomes except the inputs change or the cache expired.cached_expiration=timedelta(days=1)tells Prefect to refresh the cache after at some point.
We are able to see that the run that doesn’t use caching (lush-ostrich) completed in 27s whereas the run that makes use of caching (provocative-wildebeest) completed in 1s!

Notice: To view the dashboard with all runs like above, run prefect orion begin.
Retries
There’s a probability that we fail to tug the information from GitHub by means of the API, and we have to run the whole pipeline once more.

As a substitute of rerunning the whole pipeline, it’s extra environment friendly to rerun the duty that failed a particular variety of instances after a particular time frame.
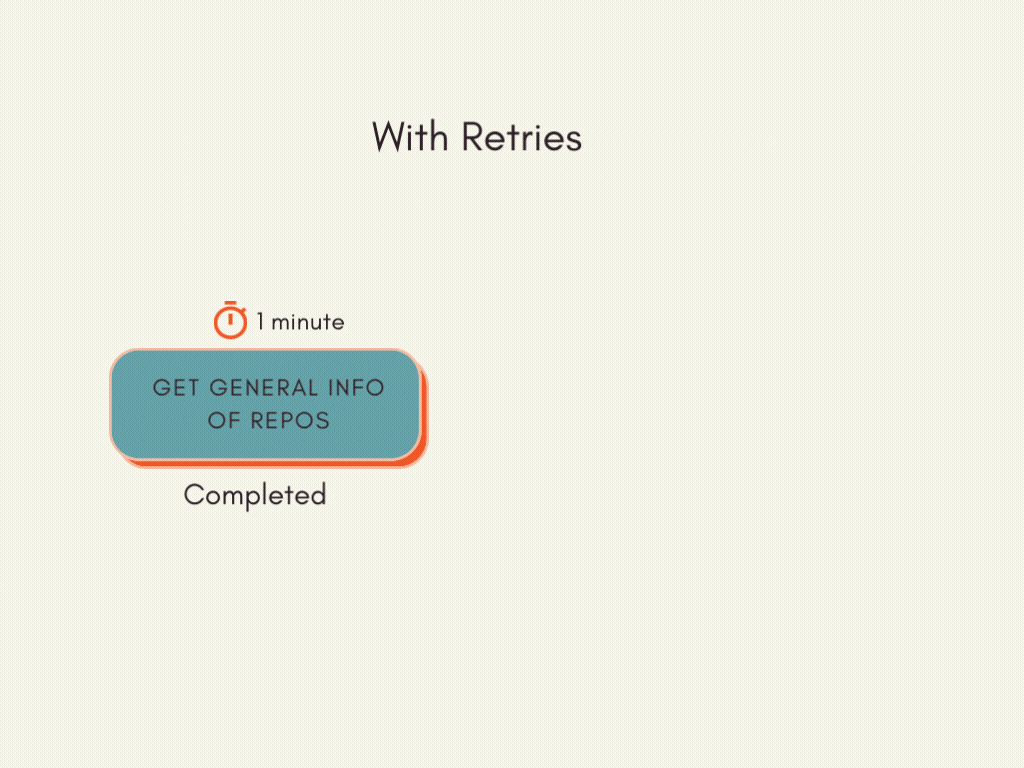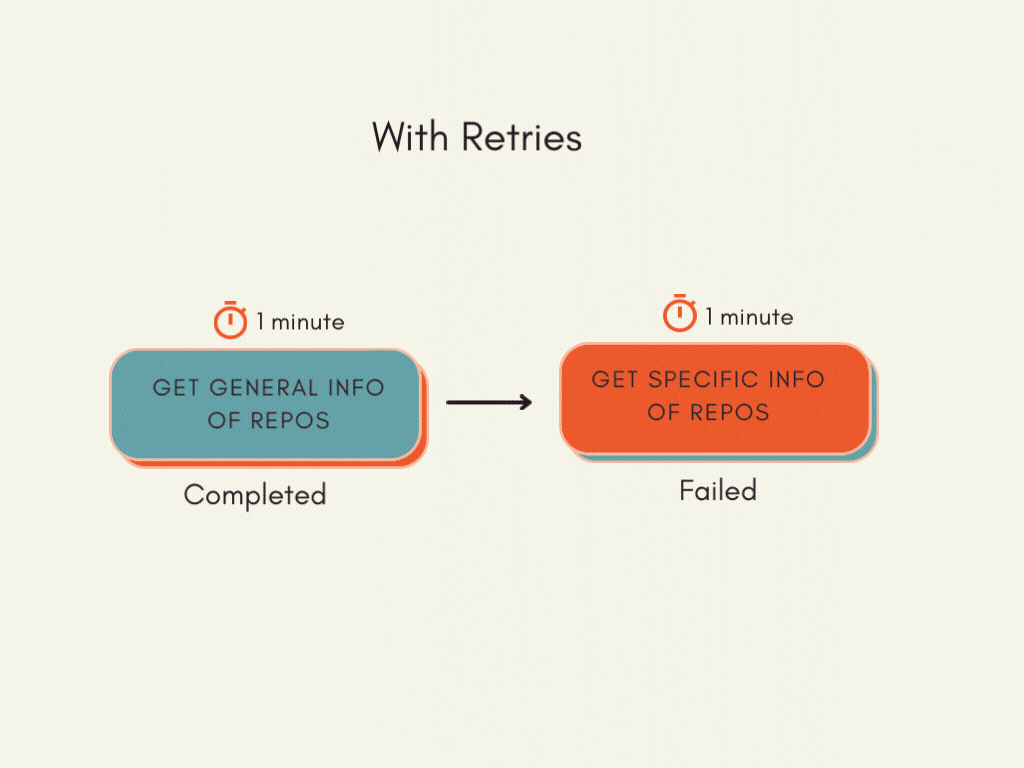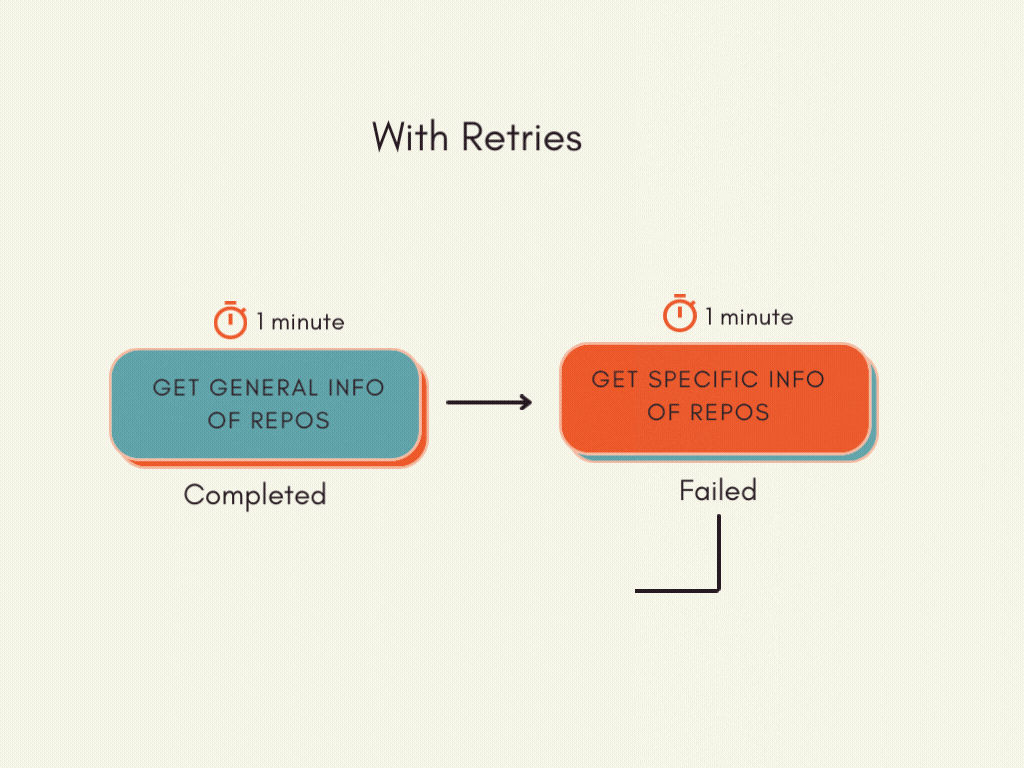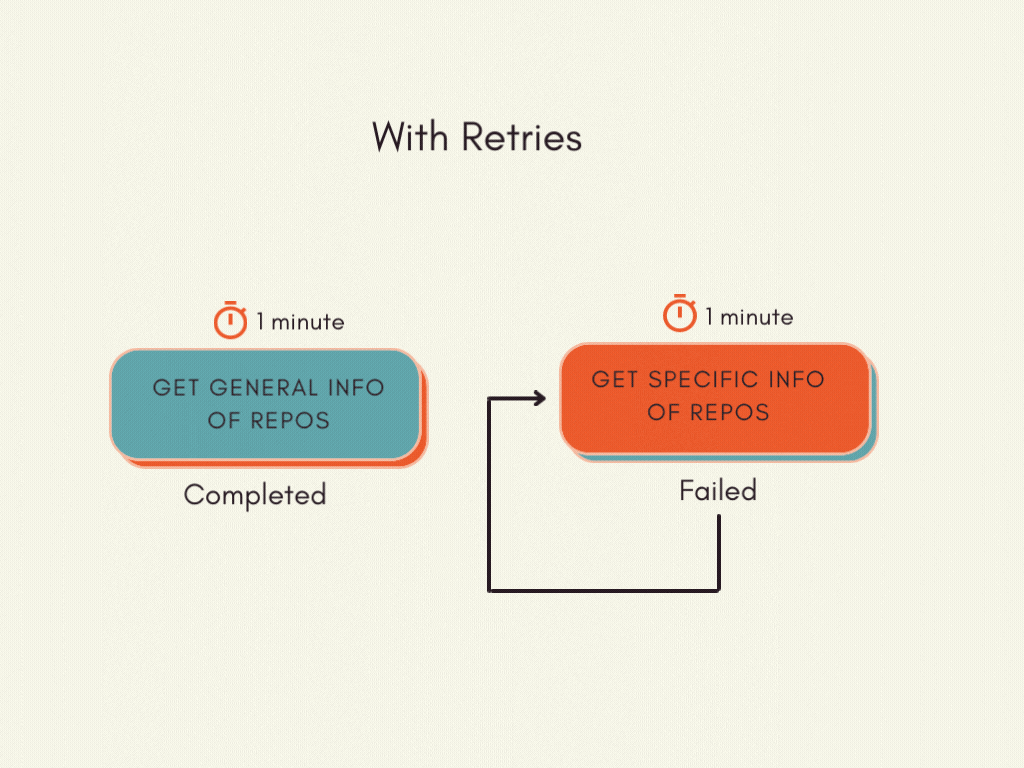
Prefect permits you to routinely retry on failure. To allow retries, add retries and retry_delay_seconds parameters to your activity.
Within the code above:
retries=3tells Prefect to rerun the duty as much as 3 instancesretry_delay_seconds=60tells Prefect to retry after 60 seconds. This performance is useful since we would hit the speed restrict if we name the GitHub API repeatedly in a brief period of time.
Within the file process_data.py below the listing improvement, we are going to clear up the information in order that we get a desk that solely exhibits what we’re concerned about.
Begin with loading the information and solely saving the repositories which might be written in a particular language:

Subsequent, we are going to maintain solely the knowledge of a repository that’s fascinating to us, which incorporates:
- Full title
- HTML URL
- Description
- Stargazers rely
Create a DataFrame from the dictionary then take away the duplicated entries:
Put all the things collectively:
Now come to a enjoyable half. Create a dashboard to view the repositories and their statistics.
The construction of the listing for our app code will look just like this:
Visualize The Statistics of Repositories
The file [Visualize.py](<http://Visualize.py>) will create the house web page of the app whereas the information below the listing pages create the kids pages.
We are going to use Streamlit to create a easy app in Python. Let’s begin with writing the code to point out the information and its statistics. Particularly, we need to see the next on the primary web page:
- A desk of repositories filtered by language
- A chart of the highest 10 hottest repositories
- A chart of the highest 10 hottest subjects
- A phrase cloud chart of subjects
Code of Visualize.py :
To view the dashboard, sort:
cd app
streamlit run Visualize.py
Go to http://localhost:8501/ and you must see the next dashboard!

Filter Repositories Primarily based on Their Subjects
We get repositories with totally different subjects, however we regularly solely care about particular subjects reminiscent of machine studying and deep studying. Let’s create a web page that helps customers filter repositories based mostly on their subjects.
And you must see a second web page that appears like this. Within the GIF beneath, I solely see the repositories with the tags deep-learning, spark, and mysql after making use of to the filter.

If you wish to have a every day replace of repositories on the GitHub feed, you may really feel lazy to run the script to get and course of information on daily basis. Wouldn’t it’s good in the event you can schedule to routinely run your script on daily basis?

Let’s schedule our Python scripts by making a deployment with Prefect.
Use Subflows
Since we need to run the circulation get_data earlier than operating the circulation process_data, we will put them below one other circulation known as get_and_process_data contained in the file improvement/get_and_process_data.py.
Subsequent, we are going to write a script to deploy our circulation. We use IntervalSchedule to run the deployment on daily basis.
To run the deployment, we are going to:
- Begin a Prefect Orion server
- Configure a storage
- Create a piece queue
- Run an agent
- Create the deployment
Begin a Prefect Orion Server
To begin a Prefect Orion server, run:
prefect orion begin
Configure Storage
Storage saves your activity outcomes and deployments. Later while you run a deployment, Prefect will retrieve your circulation from the storage.
To create storage, sort:
prefect storage create
And you will note the next choices in your terminal.
On this mission, we are going to use non permanent native storage.
Create a Work Queue
Every work queue additionally organizes deployments into work queues for execution.
To create a piece queue, sort:
prefect work-queue create --tag dev dev-queue

Output:
UUID('e0e4ee25-bcff-4abb-9697-b8c7534355b2')
The --tag dev tells the dev-queue work queue to solely serve deployments that embody a dev tag.
Run an Agent
Every agent makes positive deployments in a particular work queue are executed
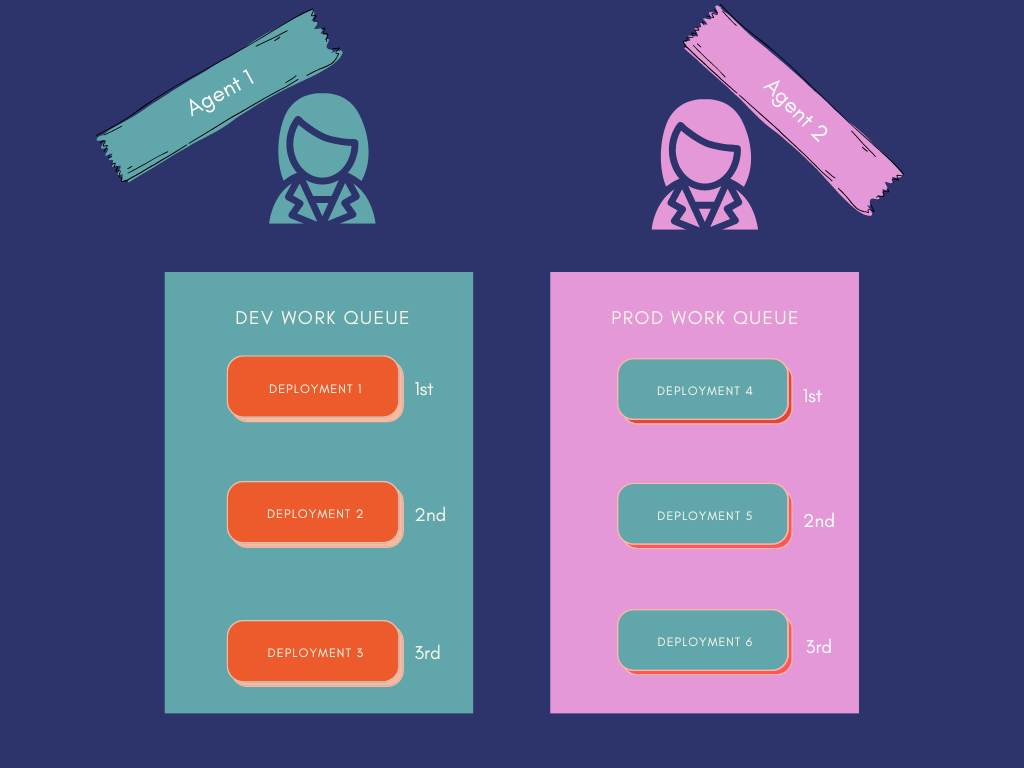
To run an agent, sort prefect agent begin <ID of dev-queue> . Because the ID of the dev-queue is e0e4ee25-bcff-4abb-9697-b8c7534355b2 , we sort:
prefect agent begin 'e0e4ee25-bcff-4abb-9697-b8c7534355b2'
Create a Deployment
To create a deployment from the file improvement.py, sort:
prefect deployment create improvement.py
You need to see the brand new deployment below the Deployments tab.

Then click on Run within the high proper nook:

Then click on Stream Runs on the left menu:

And you will note that your circulation is scheduled!

Now the script to tug and course of information will run on daily basis. Your dashboard additionally exhibits the newest repositories in your native machine. How cool is that?
Within the present model, the app and Prefect agent runs on the native machine and can cease working in the event you flip off your machine. If we flip off the machine, the app and the agent will cease operating.
To stop this from occurring, we will use a cloud service reminiscent of AWS or GCP to run the agent, retailer the database, and serve the dashboard.

Within the subsequent article, we are going to discover ways to do precisely that.

{kind=link}