
In right this moment’s world, working with knowledge has grow to be one of many core substances of any user-facing utility. Whereas it might appear insignificant initially, dealing with it nicely just isn’t so trivial once you’re engaged on the size of hundreds of day by day lively customers.
Kafka helps you construct sturdy, fault-tolerant, and scalable knowledge pipelines. Furthermore, it has been adopted by functions like Twitter, LinkedIn, and Netflix.
On this article, we are going to perceive what Kafka pub-sub is, the way it helps, advert find out how to begin utilizing it in your Node.js API.
Leap forward:
What’s pub-sub?
Pub-sub is a approach to decouple the 2 ends of a connection and talk asynchronously. This setup consists of publishers (pub) and subscribers (sub), the place publishers broadcast occasions, as an alternative of focusing on a specific subscriber in a synchronous, or blocking, vogue. The subscribers then eat occasions from the publishers.
With this mechanism, a subscriber is not tied to a given producer and may eat and course of occasions at its personal tempo. It promotes scalability as a result of a single broadcast occasion will be consumed by a number of subscribers. It’s a large leap ahead from a mere HTTP request.
Opposite to this, the HTTP request-response cycle leaves the requester ready for the response and successfully blocks them from doing anything. It is a large cause for shifting to an event-based structure in right this moment’s microservice-based functions setting.
A short introduction to Kafka
Kafka provides three major capabilities:
- A pub-sub mechanism
- Storing knowledge (even after consumption is full) for so long as you need
- Course of occasions in batch or real-time (use case particular)
Kafka ensures that any printed occasion will be consumed by a number of shoppers, and that these occasions gained’t be deleted or faraway from the storage as soon as consumed. It permits you to eat the identical occasion a number of instances, so knowledge sturdiness is top-notch.
Now that we all know what Kafka offers, let’s have a look at the way it works.
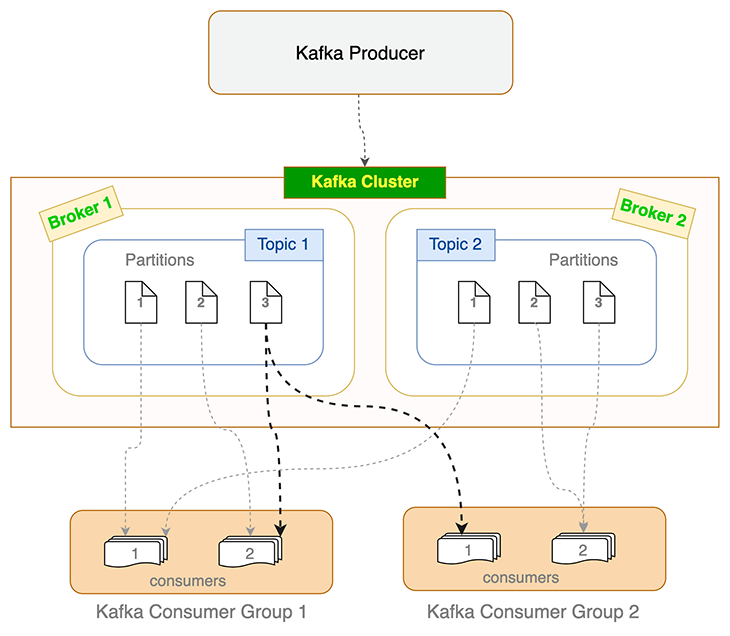
A recent, self-hosted or managed Kafka cluster largely comprises brokers. A Kafka dealer is a pc or cloud occasion working the Kafka dealer course of. It manages a subset of partitions and handles incoming requests to write down new occasions to these partitions or learn them. Writes normally solely occur to the situations working the chief; different situations observe by replication. For a given matter and its partitions unfold throughout a number of brokers, Kafka seamlessly elects a brand new chief from the followers if a pacesetter dealer dies.
Producers and shoppers use Kafka dealer(s) to write down occasions and skim from Kafka subjects. Subjects are additional divided into partitions. To maintain monitor of what number of occasions are processed (and dedicated), Kafka maintains an offset worth, which is nothing however an incrementing quantity that displays the variety of occasions processed.
When a shopper dies or turns into unresponsive (i.e., failing to ship heartbeats to the dealer inside the sessionTimeout ms set), Kafka reassigns these orphaned partitions to the remaining shoppers. Related load balancing occurs when a brand new shopper joins the patron group. This means of reassigning and reevaluating load is named rebalancing. When Kafka shoppers rebalance, they begin consumption from the most recent un-committed offset.
Sensible constraint on partition and shopper depend
A subject’s partition can solely be consumed by a single shopper in a shopper group. However a number of shoppers from completely different shopper teams can every eat from the identical partition. That is depicted within the flowchart above for Partition 3 of Subject 1.
Organising our Node.js undertaking
We are going to use a barebones Specific.js API for this tutorial. You will discover the starter code right here. We are going to use it as a base and add Kafka help to the API. We will do extra with the info, however the API is deliberately saved easy in order that we are able to give attention to Kafka.
If you wish to observe alongside, run the API regionally in your machine. Listed below are the steps:
- Clone the repository:
git clone [email protected]:Rishabh570/kafka-nodejs-starter.git - Checkout to the starter department:
git checkout starter - Set up the packages:
npm set up - Run the server:
npm begin
Now that the API is working regionally in your machine, let’s set up Kafka.
Putting in Kafka
Earlier than we begin producing and consuming occasions, we have to set up Kafka to our API. We are going to use the Kafka.js consumer library for Node.js.
Run this command to put in it:
npm set up kafkajs
Subsequent, set up the Kafka CLI device. It helps with administrative duties and experimenting with Kafka. Merely head over to kafka.apache.org and obtain Kafka.
We are actually formally able to dive into the fascinating stuff. Let’s create a Kafka matter to start out producing occasions.
Making a Kafka matter
In Kafka, you want a subject to ship occasions. A Kafka matter will be understood as a folder; likewise, the occasions in that matter are the information in that folder. Occasions despatched on channelA will keep remoted from the occasions in channelB. Kafka subjects permit isolation between a number of channels.
Let’s create a subject utilizing the Kafka CLI we downloaded within the earlier step:
bin/kafka-topics.sh --create --topic demoTopic --bootstrap-server localhost:9092
We used the kafka-topics.sh script to create the Kafka matter. When working the above command, make sure you’re within the folder the place you downloaded the Kafka CLI device.
We now have created a subject named demoTopic. You possibly can title it something; I’d advocate following a naming conference when creating subjects. For an ecommerce utility, the nomenclature for Kafka subjects to inform customers who wishlisted an merchandise will be like this:
macbook14_wishlisted_us_east_1_appmacbook14_wishlisted_us_east_2_appmacbook14_wishlisted_us_east_1_webmacbook14_wishlisted_us_east_2_web
As you may need observed, it leverages merchandise and person properties to assign matter names. Not solely does this offload a serious duty out of your shoulders, it instantly tells you what sort of occasions the subject holds. In fact, you may make the names much more particular and granular based mostly in your particular undertaking.
Organising Kafka brokers
To ship occasions, we’d like another factor: brokers.
As we discovered earlier, brokers are liable for writing occasions and studying them from subjects. We’ll be certain that it’s setup earlier than our code runs.
Extra nice articles from LogRocket:
That is what our index.js file seems like:
const { Kafka } = require('kafkajs')
const kafka = new Kafka({
clientId: 'kafka-nodejs-starter',
brokers: ['kafka1:9092'],
});
Earlier than the API makes use of the routes to supply or eat occasions, it connects to the Kafka consumer and creates two brokers. That’s it.
Let’s transfer on to really producing occasions now.
Writing our first producer
We now have efficiently put in Kafka on our Node.js utility. It’s time to write down our first Kafka producer and study the way it works.
const producer = kafka.producer()
// Connect with the producer
await producer.join()
// Ship an occasion to the demoTopic matter
await producer.ship({
matter: 'demoTopic,
messages: [
{ value: 'Hello micro-services world!' },
],
});
// Disconnect the producer as soon as we're accomplished
await producer.disconnect();
We handle three steps with the above code:
- Connecting to the Kafka producer
- Sending a take a look at occasion on the subject we had created
- Disconnecting the producer as soon as we’re accomplished utilizing it
It is a simple instance. There are a number of configuration settings that the consumer library offers that you simply would possibly wish to tweak as per your wants. These embody:
- Idempotent: If set, the Kafka producer will be certain that the occasions are written to the subject precisely as soon as. You possibly can select to maintain it disabled and deal with idempotency whereas consuming
- Retry: You possibly can select to customise the retry mechanism when producing messages utilizing Kafka.js; learn extra about how the retry mechanism works right here
Configuring your Kafka shopper
We now have written our Kafka producer and it is able to ship occasions on the demoTopic matter. Let’s construct a Kafka shopper that may hearken to the identical matter and log it into the console.
const shopper = kafka.shopper({ groupId: 'test-group' })
await shopper.join()
await shopper.subscribe({ matter: 'demoTopic', fromBeginning: true })
await shopper.run({
eachMessage: async ({ matter, partition, message }) => {
console.log({
worth: message.worth.toString(),
})
},
});
Right here’s what is occurring within the above code snippet:
- We create a shopper group
- We hook up with the patron and subscribe to our
demoTopic - Lastly, we course of the messages consumed and log them to the console
Kafka shopper customization choices
The Kafka shopper offers many choices and lots of flexibility by way of permitting you to find out the way you wish to eat knowledge. Listed below are some settings it’s best to know:
autoCommit
Committing in Kafka means saving the message/occasion to disk after processing. As we all know, offset is only a quantity that retains monitor of the messages/occasions processed.
Committing typically makes certain that we don’t waste assets processing the identical occasions once more if a rebalance occurs. However it additionally will increase the community visitors and slows down the processing.
maxBytes
This tells Kafka the utmost quantity of bytes to be accrued within the response. This setting can be utilized to restrict the dimensions of messages fetched from Kafka and avoids overwhelming your utility.
fromBeginning
Kafka consumes from the most recent offset by default. If you wish to eat from the start of the subject, use the fromBeginning flag.
await shopper.subscribe({ subjects: ['demoTopic], fromBeginning: true })
Search
You possibly can select to eat occasions from a specific offset as nicely. Merely move the offset quantity you wish to begin consuming from.
// This may now solely resolve the earlier offset, not commit it
shopper.search({ matter: 'instance', partition: 0, offset: "12384" })
The consumer additionally offers a neat pause and resume performance on the patron. This lets you construct your personal customized throttling mechanism.
There are lots of different choices to discover and you may configure them based on your wants. You will discover all the patron settings right here.
Why is Kafka pub-sub higher than utilizing HTTP requests?
HTTP has its legitimate use circumstances, however it’s simple to overdo it. There are situations the place HTTP just isn’t appropriate. For instance, you’ll be able to inject occasions right into a Kafka matter named order_invoices to ship them to the shoppers who requested them throughout their buy.
It is a higher method in comparison with sending the occasions over HTTP as a result of:
- It permits you to decouple the occasion sender and receiver. Since you don’t anticipate (or want) a right away response, an HTTP request doesn’t assist
- It’s sturdy. Since Kafka occasions aren’t dropped upon consumption, you’ll be able to replay these occasions if the notification-sending service fails abruptly
- It’s scalable. You possibly can eat the Kafka occasions at a number of locations, even in several providers or APIs
What occurs after consumption?
If in case you have idempotency necessities, I’d advocate having an idempotency layer in your providers as nicely. With an idempotency layer, you’ll be able to replay all Kafka occasions, in addition to the occasions between two given timestamps.
How do you filter out solely particular ones between a given time frame? When you take a better look, Kafka doesn’t (and mustn’t) resolve this drawback.
That is the place the application-level idempotency layer comes into play. When you replay all your occasions between particular timestamps, the idempotency mechanism in your providers makes certain to solely cater to the first-seen occasions.
A easy idempotency answer will be to select a novel and fixed parameter from the request (say, order ID in our invoices instance) and create a Redis key utilizing that. So, one thing just like the beneath ought to work for starters:
notification:invoices:<order_id>
This fashion, even if you happen to replay occasions, your utility gained’t course of the identical order once more for sending out the notification for the bill. Furthermore, in order for you this Redis key to be related for less than a day, you’ll be able to set the TTL accordingly.
Actual-world functions of Kafka
Kafka pub-sub can be utilized in quite a lot of locations:
- In large-scale, distributed messaging platforms, on account of its sturdiness, replication, and fault tolerance
- For person exercise monitoring: Kafka offers batch processing for messages, which can be utilized to post-process and retailer person clickstream and habits info
- As a streaming pipeline for processing non-time-sensitive occasions. For instance, sending notifications to your prospects when an merchandise is again in inventory, sending bulletins, or promotional marketing campaign notifications
- In revision historical past, to supply the historic actions carried out at particular timeframes
- To retailer occasions that you do not need to lose after they’re consumed and processed as soon as. This helps in replaying or resyncing your functions and sure operations
Twitter makes use of Kafka as its main pub-sub pipeline. LinkedIn makes use of it to course of greater than 7 trillion messages per day, and Kafka occasion streams are used for all point-to-point and throughout the Netflix studio communications on account of its excessive sturdiness, linear scalability, and fault tolerance.
It wouldn’t be unsuitable to say that Kafka is among the most vital cornerstones for scalable providers, satisfying tens of millions of requests.
Conclusion
We now have checked out what Kafka pub-sub is, the way it works, and one of many methods you’ll be able to leverage it in your Node.js utility.
Now, you will have all of the required instruments and information to embark in your Kafka journey. You may get the whole code from this kafka-node-starter repository, in case you weren’t capable of observe alongside. Simply clone the repository and observe the steps proven on this information. You’ll positively have a greater understanding once you observe this hands-on.
For any queries and suggestions, be at liberty to achieve out within the feedback.
200’s solely  Monitor failed and sluggish community requests in manufacturing
Monitor failed and sluggish community requests in manufacturing
Deploying a Node-based internet app or web site is the simple half. Ensuring your Node occasion continues to serve assets to your app is the place issues get more durable. When you’re desirous about guaranteeing requests to the backend or third occasion providers are profitable, attempt LogRocket.  https://logrocket.com/signup/
https://logrocket.com/signup/
LogRocket is sort of a DVR for internet and cell apps, recording actually every little thing that occurs whereas a person interacts along with your app. As an alternative of guessing why issues occur, you’ll be able to mixture and report on problematic community requests to shortly perceive the foundation trigger.
LogRocket devices your app to report baseline efficiency timings resembling web page load time, time to first byte, sluggish community requests, and likewise logs Redux, NgRx, and Vuex actions/state. Begin monitoring at no cost.

{kind=link}