Extract info from a pretrained mannequin utilizing Pytorch and Hugging Face
Aim
Let’s start by defining what our function is for this hands-on article. We need to construct a mannequin that takes as enter a number of paperwork, and manages to categorise them by their content material.
Some classes are for instance : politics, journey , sports activities, and so on.
To do that we need to use a pretrained mannequin akin to BERT.
Background
BERT is a language mannequin primarily based closely on the Transformer encoder. In case you are unfamiliar with Transformers I like to recommend studying this wonderful article.
Bert in a nutshell :
- It takes as enter the embedding tokens of a number of sentences.
- The primary token is at all times a particular token known as [CLS].
- The sentences are separated by one other particular token known as [SEP].
- For every token BERT outputs an embedding known as hidden state.
- Bert was educated on the masked language mannequin and subsequent sentence prediction duties.
Within the masked language mannequin (MLM), an enter phrase (or token) is masked and BERT has to attempt to determine what the masked phrase is. For the subsequent sentence prediction (NSP) activity, two sentences are given in enter to BERT, and he has to determine whether or not the second sentence follows semantically from the primary one.
For classification issues akin to ours, we’re solely within the hidden state related to the preliminary token [CLS], which by some means captures the semantics of the complete sentence higher than the others. So we are able to use this embedding as enter of a classifier that webuild on prime of it.
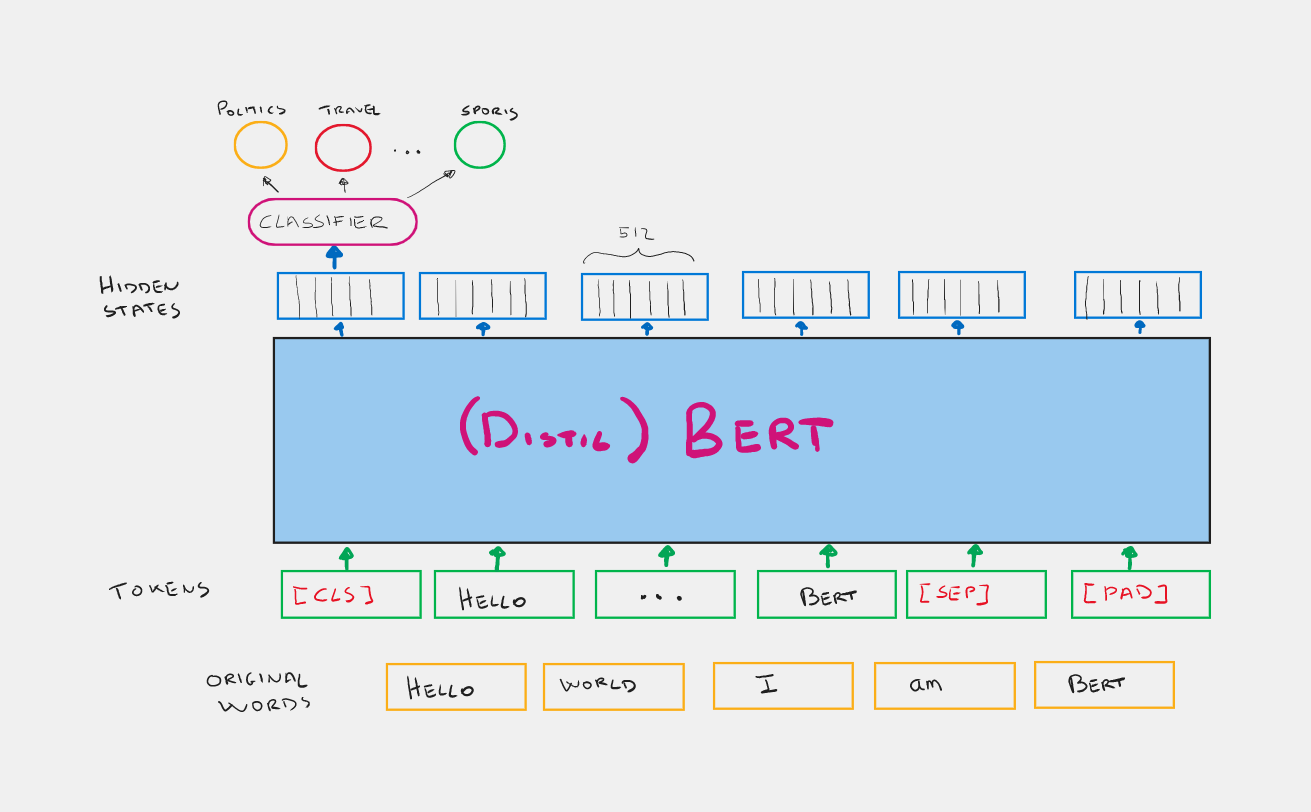
From the picture above you possibly can see that we are going to be utilizing a lighter model of BERT known as DistilBERT. This distilled mannequin is 40% smaller than the unique however nonetheless maintains about 97% efficiency on the assorted NLP duties.
One other factor you possibly can discover, is that BERT’s enter are usually not the unique phrases however the tokens. Merely BERT has related a tokenizer that preprocess the textual content in order that it’s interesting for the mannequin. Phrases are sometimes cut up into subwords and as well as particular tokens are added [CLS] to point the start of the sentence, [SEP] to separate a number of sentences, and [PAD] to make every sentence have the identical variety of tokens.
If you wish to be taught extra about Bert or his wordpiece tokenizer try these assets:
Dataset
The dataset we’re going to use known as BCC Full Textual content Doc Classification and it’s accessible on Kaggle with public entry.
This dataset accommodates 2225 information, which consists of 5 classes in complete. The 5 classes we need to determine are Sports activities, Enterprise, Politics, Tech, and Leisure.
Obtain kaggle dataset instantly from colab. (Bear in mind to add you private kaggle key)
I gained’t go into the main points of learn how to learn this information and switch it right into a dataframe, however I assume you possibly can create a daframe with two columns : short_description and class.
Encoding Labels
The dataset has labels akin to : Politics, Sports activities, and so on….
We have to rework these labels into numbers by merely utilizing a label encoder.
Generate Textual content Embeddings
For every textual content generate an embedding vector, that can be utilized as enter to our ultimate classifier. The vector embedding related to every textual content is just the hidden state that Bert outputs for the [CLS] token.
Let’s begin by importing the mannequin and tokenizer from HuggingFace.
Now we have now to tokenize the textual content. Bear in mind to outline the padding on this approach every tokenized sentence may have the identical size, and the truncation so if the sentence is just too lengthy it will likely be reduce off. The final argument is to return a PyTorch tensor.
The results of tokenizing a textual content shall be a dictionary that accommodates the input_ids , which are the tokens expressed in numbers, and the attention_mask that tells us if the token is or isn’t a [PAD].
Get the texts ([CLS]) hidden states by working the mannequin.
Construct the classifier
Having reached this level you should utilize the classifier you want finest by giving it as enter the hidden states and asking it to foretell the labels. On this case I’ll use a RandomForest.
The efficiency of this classifier is not going to be nice as a result of we used little information and didn’t do a lot work on the classifier. However out of curiosity I like to recommend that you just evaluate it in opposition to a dummy classifier that predicts labels randomly.
On this arms on article we noticed how we are able to reap the benefits of the capabilities of a pretrained mannequin to create a easy classifier in little or no time.
Understand that what we educated is just the ultimate classifier, i.e., the random forest.
Bert, however, was used solely in inference to generate the embeddings that by some means seize the primary options of the texts, which is why we are saying we used a Characteristic Extraction methodology.
However can we practice Bert himself to show him learn how to create higher textual content embeddings in our particular case? Certain! Within the subsequent article I’ll present you learn how to do advantageous tuning of (Distil) BERT!
Marcello Politi
