A novel anomaly localization method that produces the options tailored to the goal dataset and employs switch studying
This text is in continuation of the tales Paper Evaluation: Reconstruction by inpainting for visible anomaly detection and GANomaly Paper Evaluation: Semi-Supervised Anomaly Detection through Adversarial Coaching. Within the earlier posts, I coated reconstruction-based approaches that determine anomalies in pictures. Fashions, reminiscent of autoencoder and generative adversarial networks, can be utilized to detect anomalies in pictures. How do they work?
They encode and reconstruct solely regular pictures throughout coaching. In analysis, there’s the speculation that these fashions should not reconstruct properly anomalous pictures since they weren’t fed throughout coaching and, then, the defect pictures ought to have a better anomaly rating than defect-free pictures. Nonetheless, this activity is difficult with complicated datasets and typically some of these approaches can produce good reconstruction outcomes for irregular pictures, resulting in failure on distinguishing between irregular and regular pictures.
Because of this, I researched different sorts of anomaly detection strategies and I got here throughout a novel method, referred to as Coupled-hypersphere-based Characteristic Adaptation (CFA). There are two important concepts behind this method:
- It makes use of pre-trained CNN to extract the options of patches
- It adopts switch studying to adapt the function to the goal dataset and, consequently, irregular options will be clearly distinguished from regular options.
On this submit, I’m going to overview the paper that launched this novel anomaly detection mannequin.
Define
- Necessities
- Overview of CFA
- Experiment Settings
- Quantitative Outcomes
- Qualitative Outcomes
1. Necessities
While you learn a paper, there are at all times some ideas which are taken as a right and are obligatory to know deeply the work. I like to recommend you to have a look on this part for those who don’t know one among these phrases:
- SPADE
- Switch Studying
- Visible anomaly detection
SPADE
Semantic Pyramid Anomaly Detection (SPADE) is an anomaly detection method that makes use of pre-trained CNNs, reminiscent of ResNet-18 and Large ResNet-50, to extract significant options [2]. In a different way from CFA, this method exploits a pre-trained CNN on ImageNet with out studying the goal dataset, which might have a totally completely different distribution from the dataset that was fed to the pre-trained CNN.
SPADE consists of three completely different phases to resolve the duty of anomaly detection:
- The pre-trained CNN extracts options from the goal dataset.
- The second section makes use of KNN to retrieve Okay nearest regular pictures from the coaching set for every take a look at picture. The space is calculated utilizing the Euclidian metric between the extracted options representing normality from the coaching dataset and the extracted options of the take a look at picture.
- The third section finds dense pixel-level correspondence between the goal and the conventional pictures. If goal picture areas don’t current close to matches with the conventional pictures, retrieved within the second section, are labeled as anomalous.
Switch Studying
Switch Studying is a deep studying analysis space centered on making use of beforehand acquired information in a single area to resolve a unique however associated activity. For instance, you should utilize a pre-trained CNN, reminiscent of ResNet which was beforehand skilled on ImageNet, to categorise pictures into the classes of cats and canines.
Visible Anomaly Detection
Visible anomaly detection is a vital downside within the area of machine studying that mixes laptop imaginative and prescient and anomaly detection [3]. It may be additional grouped into two completely different classes:
- image-level anomaly detection solely tries to know if the entire picture is anomalous or regular
- pixel-level anomaly detection locates the irregular areas inside the picture. Because of this, it’s usually referred to as anomaly localization.
2. Overview of CFA
Coupled-hypersphere-based Characteristic adaptation (CFA) is an anomaly localization method that mixes function extractors with switch studying. Certainly, it exploits the ideas of switch studying to create extra sturdy and generalizing options that let to find out of whether or not the enter picture of the goal dataset is anomalous or not.
Earlier works that used solely pre-trained CNNs with out switch studying, reminiscent of SPADE, Padim, and PatchCore, with giant datasets, like ImageNet, achieved excellent performances. Nonetheless, it may be difficult when the goal dataset is totally completely different from ImageNet and the produced options within the center layers are consequently biased. There are different two important contributions to this method:
- A novel loss operate is proposed, based mostly on soft-boundary regression, that searches a hypersphere with a minimal radius to cluster regular options. Thus, it permits the patch descriptor to extract discriminative options, and, then, irregular options will be clearly distinguished from regular ones.
- The scalable reminiscence financial institution is compressed independently of the scale of the goal dataset. It supplies three advantages: assuaging the danger of overestimated normality of irregular options and reaching the effectivity of spatial complexity.
Coupled-Hypersphere-based Characteristic Adaption
The bias downside of the pre-trained CNN is solved by combining a hypersphere-based loss operate and a reminiscence financial institution. It tries to extract clustered options φ(pt) utilizing the Okay-means algorithm since regular options are vital for distinguishing irregular options.
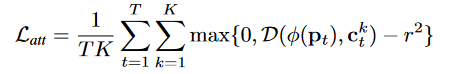
the place Okay is the variety of nearest neighbors matching with the target-oriented options and D is the space metric. Thus, CFA permits function adaptation by optimizing the parameters of the target-oriented options φ(pt) to reduce the loss L_{att} by switch studying.
To keep away from the overestimation of the normality of irregular options, an extra loss is outlined. To deal with this downside, exhausting unfavourable options are used to carry out contrastive supervision, resulting in a extra discriminant φ(pt). Laborious unfavourable options are outlined because the Okay+j-th nearest neighbor ct^j of pt. The loss L_{rep} supervises φ() contrastively such that the hypersphere created with ct^j as the middle repels pt.

the place J is the whole variety of exhausting unfavourable options for use for contrastive supervision and alpha is the hyperparameter that controls the steadiness between these two losses, L_{att} and L_{rep}. As end result, these two losses are mixed into a novel loss:

Reminiscence Financial institution Compression
The aim is to assemble an environment friendly reminiscence financial institution. First, an preliminary reminiscence financial institution C0 is constructed by making use of Okay-means clustering to all of the options, obtained from the primary regular samples x0 of the coaching set X. After, there are the next steps to replace the reminiscence financial institution:
- Infer the i-th regular pattern and seek for the set of the closest patch options from the earlier reminiscence financial institution C_{i-1}
- the i-th reminiscence financial institution of the following state Ci is calculated by the exponential shifting common (EMA) of Ci^{NN} and C_{i-1}
The ultimate reminiscence financial institution C is obtained by repeating the above course of |X| instances for all regular samples of the coaching set.

We will discover that the area complexity is lowered in comparison with the opposite approaches based mostly on function extractors with out switch studying. Particularly, it’s not depending on the scale of the goal dataset |X|.

Scoring Perform
The anomaly rating is outlined utilizing the minimal distance between the target-oriented options φ(pt) and the memorized options.
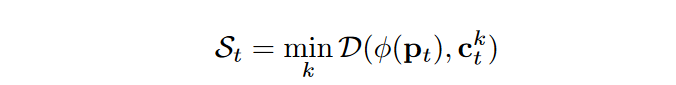
Nonetheless, the boundaries between clusters of regular options usually are not clear and it’s exhausting to differentiate irregular options with the naive anomaly rating exactly. Because of this, a novel scoring operate is proposed to think about the understanding of φ(pt). The extra φ(pt) is matched, the shorter the space to a particular memorized function is in comparison with different memorized options. Softmin is used to measure how shut the closest c is in comparison with the opposite c.

Throughout the analysis of the novel method CFA, we will get hold of the anomaly rating map, which constitutes the ultimate output for anomaly localization.
3. Experiment Settings
There are two datasets thought of as benchmarks to judge the novel method: MVTec AD and RD-MVTec datasets. Whereas the MVTec AD is a novel and complete industrial dataset with 5354 high-resolution pictures divided into 15 classes, the RD-MVTec is only a copy of the MVTec AD with unaligned samples. The photographs of the RD-MVTec are rotated randomly inside +=10 levels. After this transformation, the samples are resized to 256×256 and randomly cropped to 224×224.
The efficiency is evaluated utilizing Space Below the Receiver Operator Curve (AU-ROC) as metric. The image-level AUROC is used to judge the efficiency of the mannequin for anomaly detection, whereas pixel-level AUCROC for the efficiency for anomaly localization.
The experiments have been carried out utilizing all pre-trained CNNs on ImageNet, the place function maps are extracted from intermediate layers {C2,C3,C4} of every pre-trained CNN. A 1×1 CoordConv is taken into account because the Patch descriptor, which is skilled for 30 epochs.
4. Quantitative Outcomes
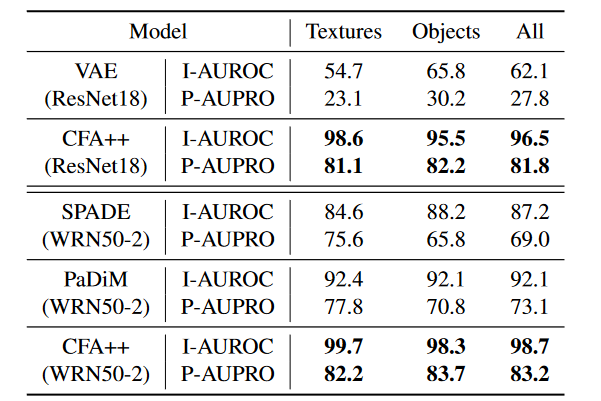
Desk 1 and Desk 2 present respectively the efficiency of various anomaly localization strategies on the MVTec AD dataset and RD-MVTec AD dataset.
- CFA++ presents frivolously decrease pixel-level AUROC scores than CFLOW when contemplating all of the courses collectively on the MVTec AD dataset. However it ought to be seen that it obtains good efficiency with a reminiscence financial institution, that has smaller spatial complexity.
- On RD-MVTec AD dataset, the performances of the anomaly localization approaches are decrease that the performances of the MVTec AD dataset. Particularly, SPADE appears the method extra smart to the rotation of the pictures, which decreases drastically its AUROC scores.

In Desk 3, the efficiency of CFA++ is way more class by visualizing the image-level ROCAUC rating per class on the MVTec AD dataset. It’s value noticing that CFA++ outperforms all the opposite approaches when wanting on the efficiency on the class stage because of the impact of the function adaptation to the goal dataset, whereas CFLOW has decrease performances than CFA++ when coping with a category at a time.

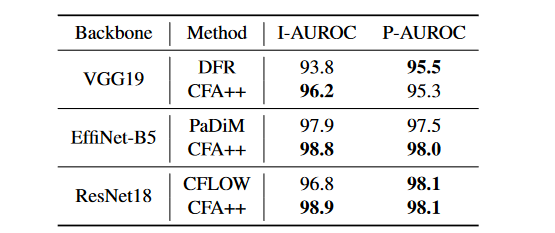
Desk 4 permits evaluating the efficiency of anomaly detection/localization mixed with the pre-trained CNN. CFA++ obtains the very best performances when it makes use of EffiNet-B5 and ResNet18 as function extractors.
5. Qualitative Outcomes
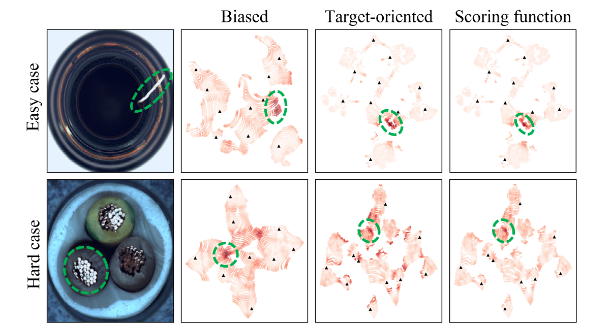
The qualitative outcomes are vital to interpret if the options produced by CFA allow distinguishing regular pictures from irregular pictures. The next determine reveals the anomaly rating of patch options of two examples, the bottle with a straightforward defect to determine and the cable with a tougher anomaly.
Within the anomaly rating, the crimson coloration represents the anomaly rating. This visualization needs to spotlight the variations when switch studying is utilized or not on the extracted options:
- When a function is obtained with out switch studying, the normality of the conventional function is underestimated and has a rating just like that of the irregular function. Then, it’s exhausting to determine the variations between the 2 options for the reason that boundary based mostly on the anomaly rating is ambiguous and never so clear (second column — Biased).
- When target-oriented options are obtained after utilizing switch studying, they’re properly clustered, as you may see from the third column of Determine 1. Nonetheless, clustering alone shouldn’t be sufficient to exactly rating the unsure irregular options of the exhausting case. The scoring operate proposed within the paper calculates the anomaly rating by bearing in mind the understanding. In such a approach, we’re in a position to distinguish the irregular options from the conventional ones within the exhausting case.
Beneath there are the anomaly localization outcomes that present the irregular areas recognized by CFA.

Takeaways
I hope you appreciated this overview of CFA. As I’m by no means drained to repeat, anomaly detection is a difficult downside to resolve and there’s a want of getting an outline of those strategies to know which one is probably the most applicable in that exact context.
Within the final article, I advised you check out papers that specify Skip-GANomaly and AnoGAN. On this submit, I counsel you to learn the papers concerning SPADE, PaDiM, CFLOW, and FastFlow. All these approaches have in frequent that they exploit the pre-trained CNNs to detect and localize anomalies. Let me know you probably have different solutions about readings, sharing information is the easiest way to enhance. Thanks for studying. Have a pleasant day!
References:
[1] CFA: Coupled-hypersphere-based Characteristic Adaptation for Goal-Oriented Anomaly Localization, S. Lee, S. Lee and B. Cheol Tune, (2022)
[2] Sub Picture Anomaly Detection with Deep Pyramid Correspondences, N. Cohen and Y. Hoshen, (2021)
[3] Visible Anomaly Detection for Photos: A Systematic Survey, J. Yang, R. Xu, Z. Qi and Y. Shi, (2022)
