A robust mannequin that mixes one of the best of each worlds
The vanilla Transformer is not the all-mighty mannequin that tackles any case in Deep Studying.
In a earlier article, we proved that for time sequence forecasting duties, Transformers had been struggling. That’s why Google created a hybrid Transformer-LSTM mannequin that achieves SOTA ends in time sequence forecasting duties.
After the hype ended, researchers began specializing in the shortcomings of Transformers. The brand new analysis is directed in the direction of leveraging options from different fashions (CNNs, RNNs, RL fashions) to strengthen Transformers. A typical instance is the brand new technology of Imaginative and prescient Transformers[1], the place they borrow concepts from CNNs.
In March 2022, a Google Analysis staff and the Swiss AI Lab IDSIA proposed a brand new structure, known as Block-Recurrent Transformer[2].
So, what’s the Block-Recurrent Transformer? It’s a novel Transformer mannequin that leverages the recurrence mechanism of LSTMs to attain important perplexity enhancements in language modeling duties over long-range sequences.
However first, let’s briefly focus on the strengths and shortcomings of Transformers in comparison with LSTMS. This may aid you perceive what impressed the researchers to suggest the Block-Recurrent Transformer.
Probably the most important benefits of Transformers are summarized within the following classes:
Parallelism
RNNs implement sequential processing: The enter (let’s say sentences) is processed phrase by phrase.
Transformers use non-sequential processing: Sentences are processed as a complete, quite than phrase by phrase.
This comparability is best illustrated in Determine 1 and Determine 2.
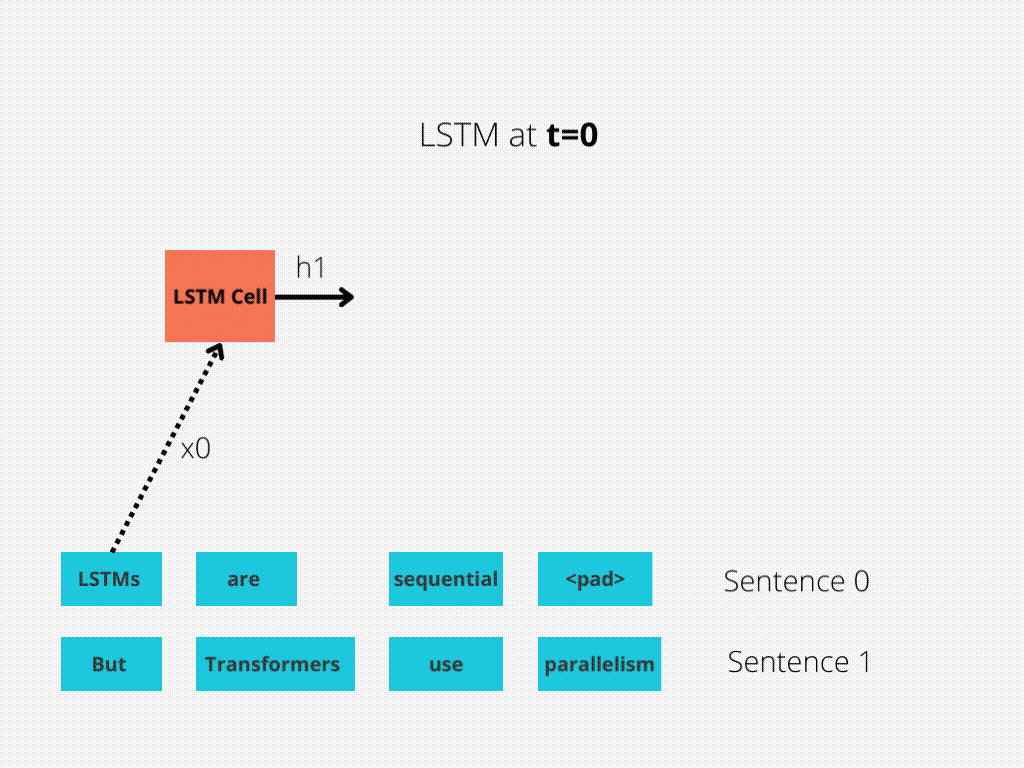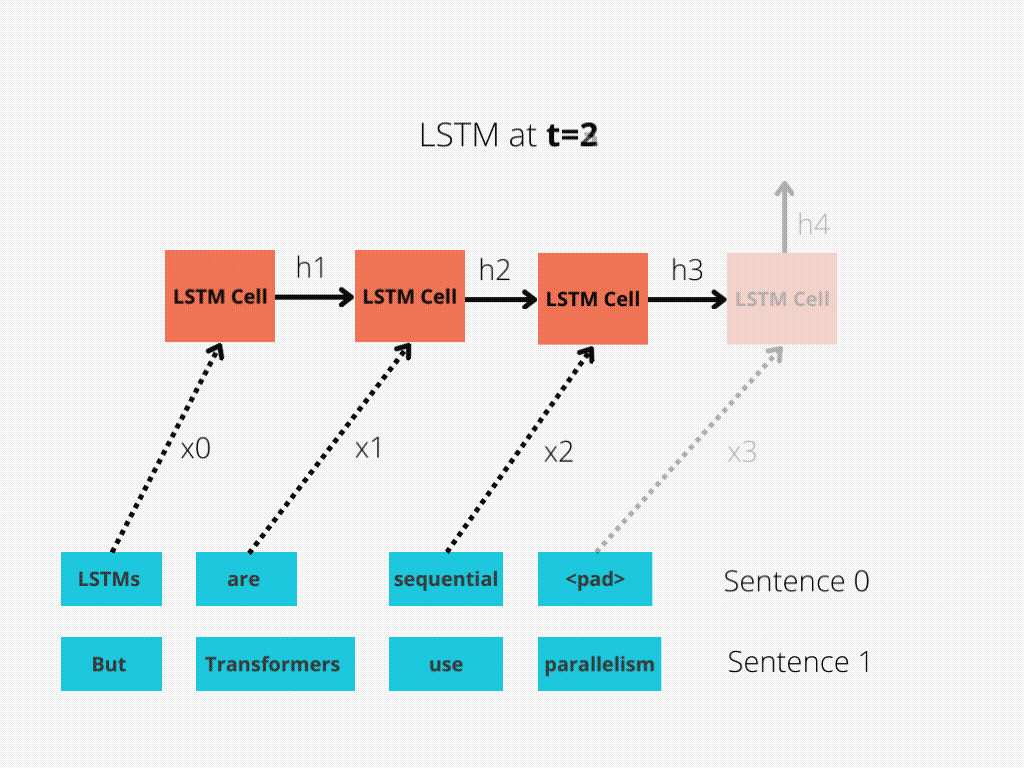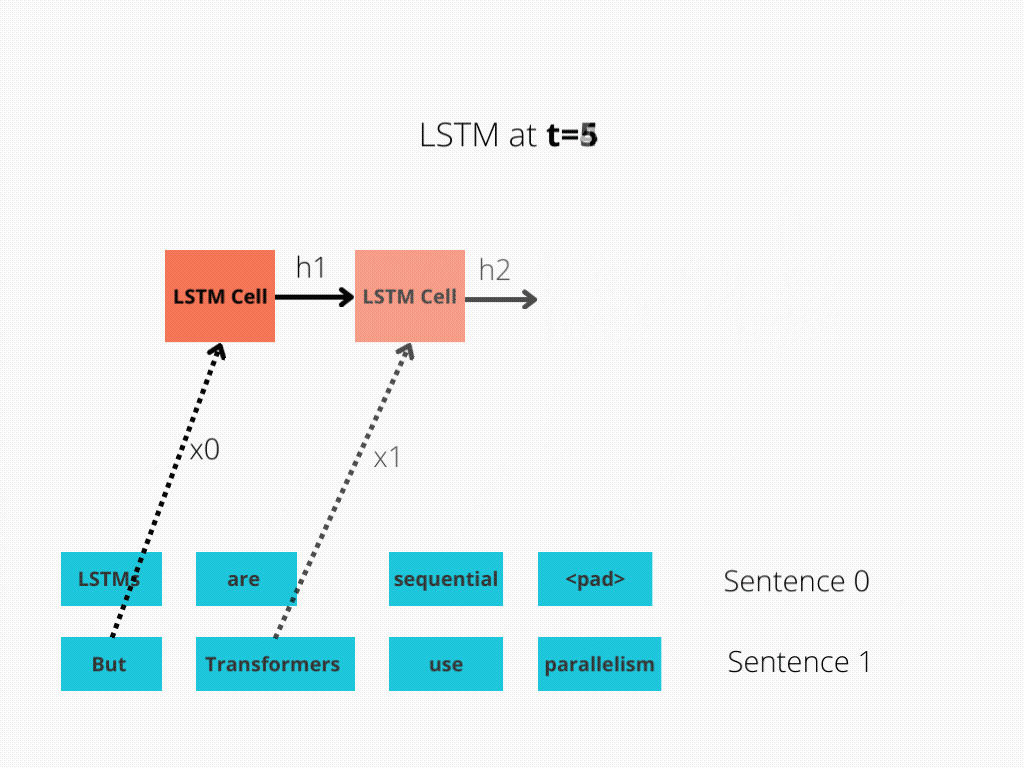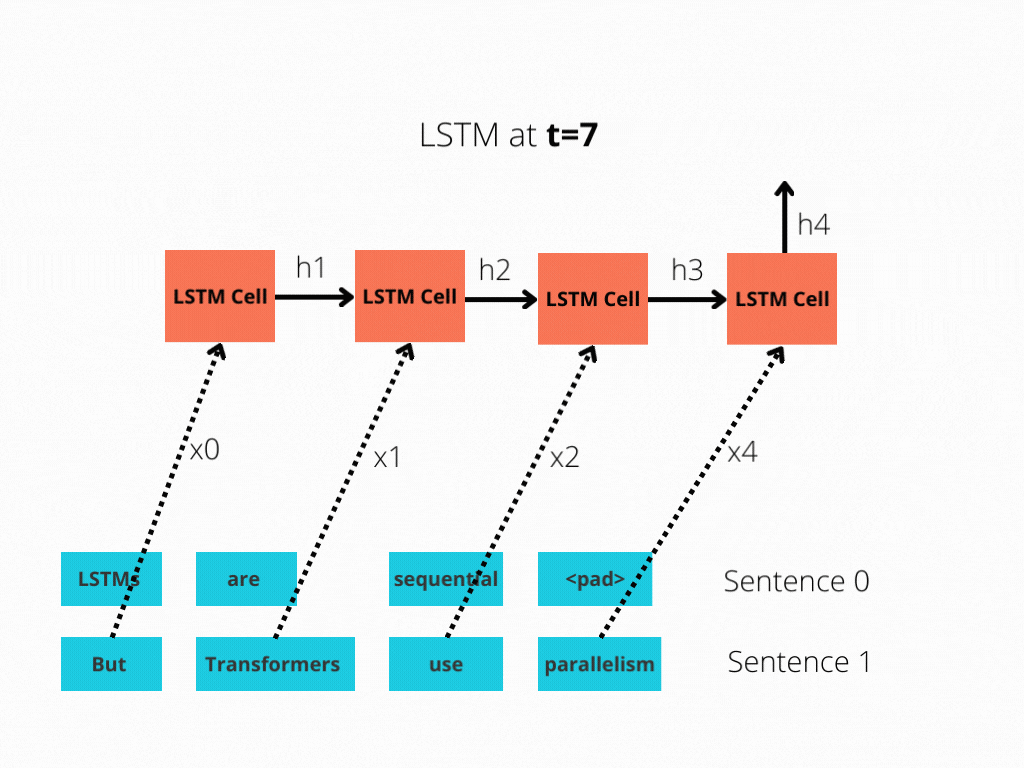
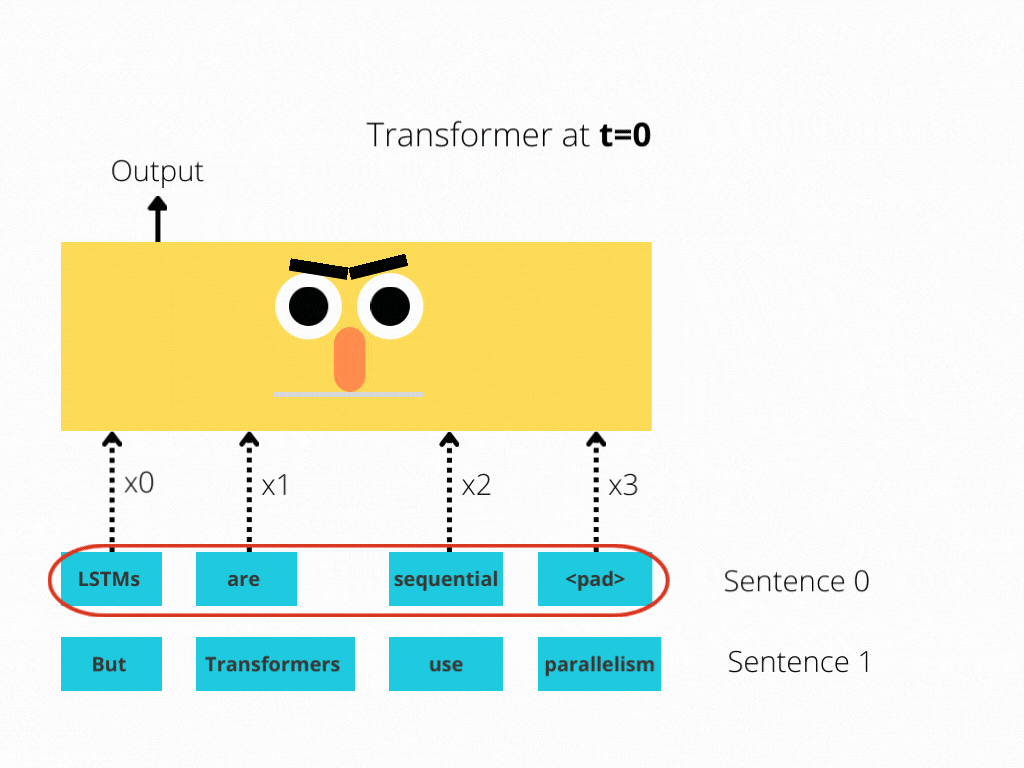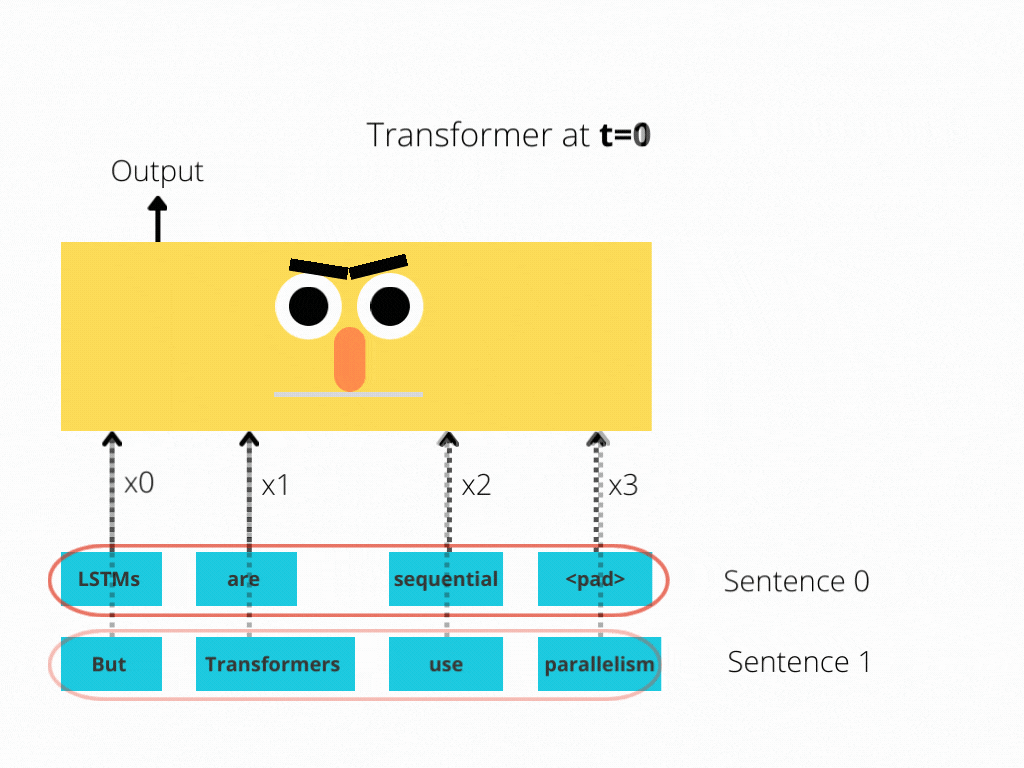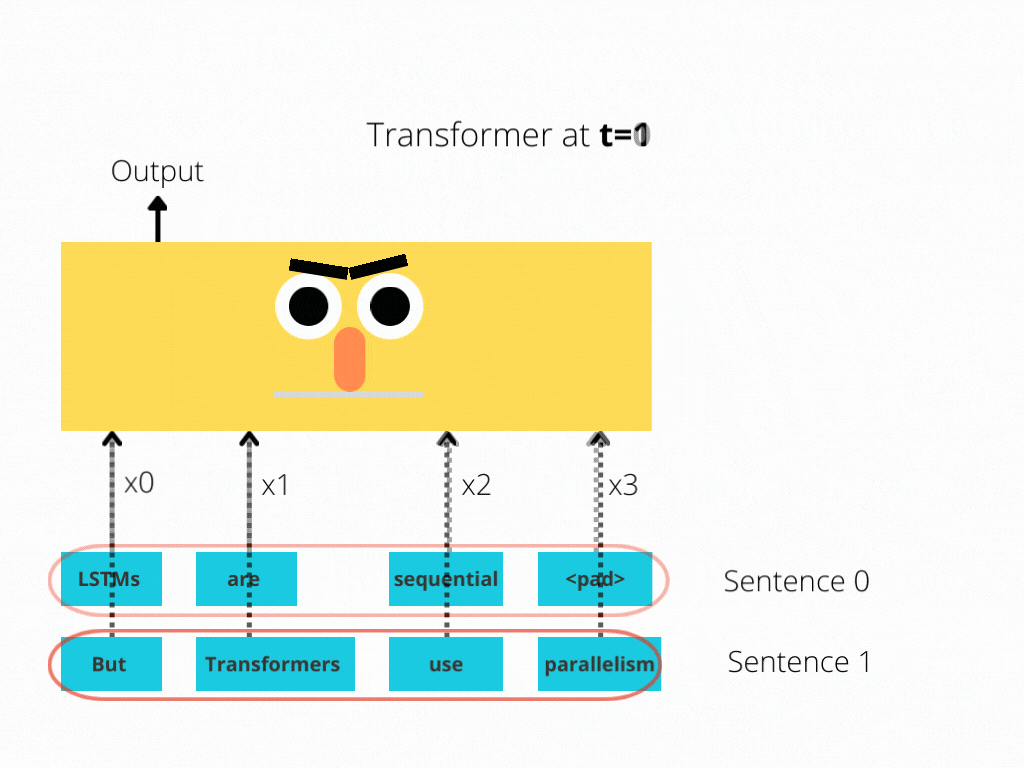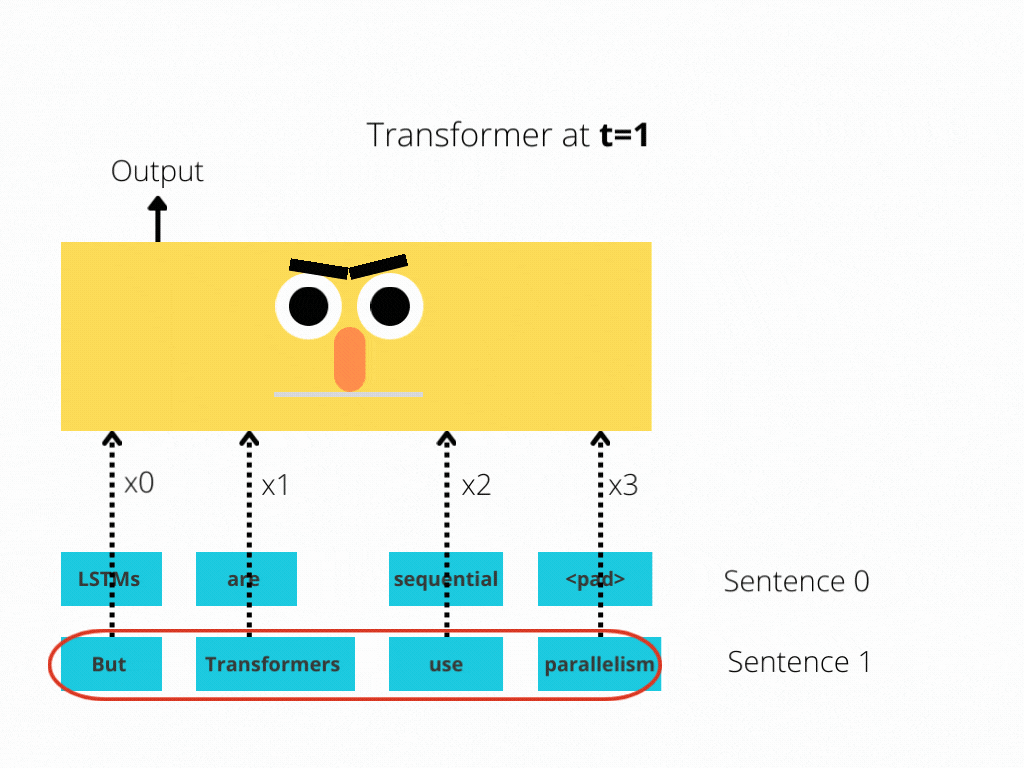
The LSTM requires 8 time-steps to course of the sentences, whereas BERT[3] requires solely 2!
Thus, BERT is best capable of reap the benefits of parallelism, offered by fashionable GPU acceleration.
Be aware that each illustrations are simplified: We assumed a batch measurement of 1. Additionally, we didn’t trouble with BERT’s particular tokens, the truth that it takes 2 sentences, and so forth.
Lengthy-term reminiscence
RNNs are compelled to compress their discovered illustration of the enter sequence right into a single state vector earlier than shifting to future tokens.
Additionally, whereas LSTMs solved the vanishing gradient subject that vanilla RNNs endure from, they’re nonetheless susceptible to exploding gradients. Thus, they’re battling longer dependencies.
Transformers, alternatively, have a lot greater bandwidth. For instance, within the Encoder-Decoder Transformer[4] mannequin, the Decoder can immediately attend to each token within the enter sequence, together with the already decoded. That is depicted in Determine 3:

Higher Consideration mechanism
The idea of Consideration[4] is just not new to Transformers. The Google Neural Engine[5](stacked Bi-LSTMs in encoder-decoder topology) again in 2016 was already utilizing Consideration.
Recall that Transformers use a particular case known as Self-Consideration: This mechanism permits every phrase within the enter to reference each different phrase within the enter.
Transformers can use massive Consideration home windows (e.g. 512, 1048). Therefore, they’re very efficient at capturing contextual info in sequential knowledge over lengthy ranges.
Subsequent, let’s transfer to the Transformer shortcomings:
The O(n²) price of Self-Consideration
The most important subject of Transformers.
There are two essential causes:
- The preliminary BERT mannequin has a restrict of
512tokens. The naive strategy to addressing this subject is to truncate the enter sentences. - Alternatively, we will create Transformer Fashions that surpass that restrict, making it as much as
4096tokens. Nevertheless, the price of self-attention is quadratic with respect to the sentence size.
Therefore, scalability turns into fairly difficult. Quite a few concepts have been proposed that restructure the unique self-attention mechanism:
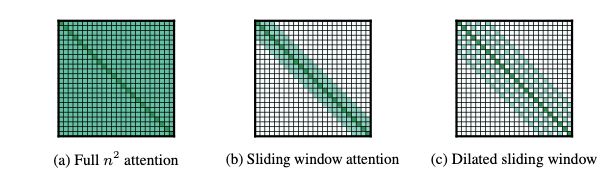
Most of those concepts had been launched by newer-generation fashions corresponding to Longformer[6] and Transformer XL[7]. These fashions are optimized for long-form texts and obtain important enhancements.
However, the problem stays: Can we additional cut back the computational price with out sacrificing effectivity?
Time sequence are difficult
Whereas Transformers have dominated the NLP area, they’ve restricted success with temporal knowledge. However why? Aren’t time sequence sequential knowledge as nicely?
- Transformers can higher calculate the output of a time-step from long-term historical past as an alternative of the present enter and hidden state. That is much less environment friendly for native temporal dependencies.
- Consequently, short-term reminiscence is equally important to longer-term reminiscence for time sequence.
- That’s why Google researchers unveiled a hybrid Deep studying mannequin[1] for Time Collection Forecasting: The mannequin makes use of Consideration but additionally contains an LSTM encoder-decoder stack that performs a big position in capturing the native temporal dependencies.
- Lastly, time sequence could be multivariate, have static knowledge, and so forth. They often require extra particular dealing with.
We received’t give attention to the time sequence facet on this article. For extra details about Deep Studying fashions for time sequence, be at liberty to examine this article.
What’s the Block-Recurrent Transformer? The Block-Recurrent Transformer is a novel mannequin that revolutionizes the NLP area.
The principle breakthrough of this mannequin is the Recurrent Cell: A modified Transformer layer that works in a recurrent trend.
Let’s shortly define the principle traits after which we’ll delve deeper into the mannequin’s structure.
- Block-Degree Parallelism: The Recurrent Cell processes tokens in blocks, and all tokens inside a block are processed in parallel.
- Giant Consideration Home windows: For the reason that mannequin breaks the enter into blocks, it may possibly use massive consideration home windows (was examined as much as
4096tokens). Therefore, the Block-Recurrent Transformer belongs to the household of long-range Transformers (like Longformer). - Linear Complexity: As a result of the Recurrent Cell breaks the enter in blocks, the mannequin calculates self-attention block-wise in O(n) time utilizing Sliding Self-Consideration.
- Extra Secure Coaching: Processing the sequence in blocks could be helpful for propagating info and gradients over lengthy distances with out inflicting catastrophic forgetting points throughout coaching.
- Data Diffusion: The Block-Recurrent Transformer operates on a block of state vectors quite than a single vector (like RNNs do). Thus, the mannequin can take full benefit of recurrence and higher seize previous info.
- Interoperability: The Recurrent Cell could be linked with standard Transformer layers.
- Modularity: The Recurrent Cells could be stacked horizontally or vertically as a result of the Recurrent Cell can function in two modes: horizontal (for recurrence) and vertical (for stacking layers). This may develop into clear within the following part.
- Operational Value: Including recurrence is like including an additional Transformer layer. No further parameters are launched.
- Effectivity: The mannequin exhibits important enhancements in comparison with different long-range Transformers.
The next two sections will describe intimately the 2 essential parts of Block-Recurrent Transformer: The Recurrent Cell structure and the Sliding Self-Consideration with Recurrence.
The spine of the Block-Recurrent Transformer is the Recurrent Cell.
Be aware: Don’t get confused by its characterization as ‘Cell’. It’s a fully-fledged Transformer layer, designed to function in a recurrent approach.
The Recurrent Cell receives the next varieties of enter:
- A set of
Wtoken embeddings, withWbeing the block measurement. - A set of “present state” vectors, known as
S.
And the outputs are:
- A set of
Woutput token embeddings. - A set of “subsequent state” vectors.
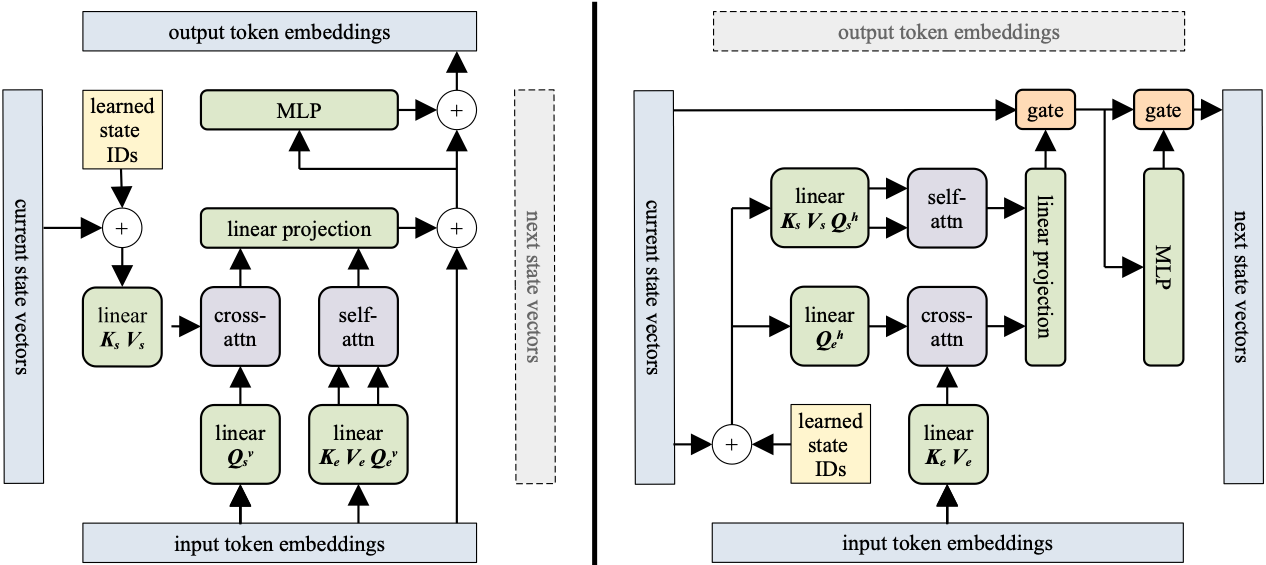
Determine 5 exhibits the Recurrent Cell structure. The structure is kind of easy and reuses a lot of the prevailing Transformer codebase!
I’ll clarify step-by-step each element proven in Determine 5:
Self-Consideration and Cross-Consideration
The Block-Recurrent Transformer helps two varieties of operations: Self-Consideration and Cross-Consideration. Extra particularly:
- Self-Consideration is carried out on keys, values, and queries generated from the identical embedding (the
Okay,V, andQmatrices respectively). - Cross-Consideration is carried out on queries generated from one embedding, and keys and values generated from one other embedding.
If you happen to recall the unique Transformer Encoder-Decoder mannequin[4], the Encoder was performing self-attention, whereas the “encoder-decoder consideration” layers within the Decoder carried out cross-attention. That’s as a result of the queries come from the earlier Decoder layer, whereas keys and values come from the Encoder output. The Recurrent Cell performs each operations in the identical layer. In different phrases:
The Recurrent Cell does self-attention(encoding) and cross-attention(decoding) in parallel!
Horizontal vs vertical mode
Subsequent, we’ll give attention to the Recurrent Cell structure, proven in Determine 5. Like I mentioned earlier, the Recurrent Cell operates in two modes:
- Vertical (Stacking): On this mode, the mannequin performs self-attention over the enter embeddings and cross-attention over the recurrent states.
- Horizontal (Recurrence): That is precisely the other: The mannequin does self-attention over the recurrent states and cross-attention over the enter embeddings.
Place bias
Additionally, you will discover a sq. field in Determine 5 known as Realized State IDs. Let’s clarify what that is and why we’d like it.
By now, it’s clear that the recurrent state transferred between Recurrent Cells is just not a single vector (like RNNs), however a lot of state vectors.
As a result of the identical MLP layer is utilized to each state vector (a typical apply), the experimental evaluation confirmed that the state vectors couldn’t differentiate. After just a few coaching epochs, they have an inclination to develop into similar.
To forestall this subject, the authors added a set of additional learnable “state IDS” to the state vectors. The authors name this performance place bias. That is analogous to positional encoding, which the vanilla Transformer applies to the enter embeddings. The authors of Block-Recurrent Transformer apply this system to the recurrent state vectors as an alternative, and that’s why they use a distinct identify to keep away from confusion.
Positional encoding
The Block-Recurrent Transformer doesn’t apply the traditional positional encoding to the enter tokens as a result of they don’t work nicely for lengthy sequences. As an alternative, the authors use a well-known trick launched within the T5 structure [8]: They add positional-relative bias vectors to the self-attention matrix stemming from the enter embeddings within the vertical mode. The bias vector is a discovered perform of the relative distance between keys and queries.
Gate configurations
One other distinction between Block-Recurrent Transformer and the opposite Transformer fashions is the utilization of residual connections.
The authors of Block-Recurrent Transformer tried the next configurations:
- Changing the residual connections with gates. (This configuration is proven in Determine 5).
- Selecting between a mounted gate and an LSTM gate.
The authors did a number of experiments to search out the optimum configurations. For extra particulars, examine the unique paper.
The Self-Consideration of the Block-Recurrent Transformer is a revolutionary performance that mixes the next ideas:
- The matrix product
QK^TVturns into ‘linearized’. - Changing the O(n²) full-attention with O(n) sliding consideration.
- Including recurrence.
The primary two ideas have been proposed in associated work [6],[9]. Due to them, Consideration achieves linear price however loses its potential in very lengthy paperwork. The Block-Recurrent Transformer combines the primary two concepts with recurrence, an idea borrowed from RNNs.
The recurrence mechanism is elegantly built-in inside a Transformer layer and affords dramatically improved outcomes over very lengthy sentences.
We are going to analyze every idea individually to raised perceive how the Block-Recurrent Transformer makes use of Consideration.
Linear matrix product
Within the Transformer ecosystem, Consideration revolves round 3 matrices: The queries Q , the keys Okay and the valuesV.
As a reminder, the vanilla Consideration is given by:
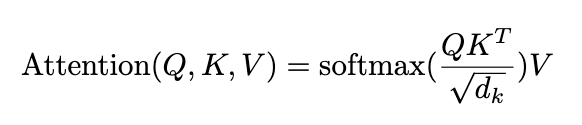
The Block-Recurrent Transformer calculates the Consideration rating a bit otherwise: First, the softmax operation is eliminated. The remaining phrases are then re-arranged as Q(Okay^TV) ( proven in Determine 5) and computed in a linearized method, in keeping with [9].
Sliding Self-Consideration
Given an extended sequence of N tokens, a sliding window applies a causal masks so that every token solely attends to itself and the earlier W tokens. (Keep in mind that W is the block measurement).
Let’s visualize the eye matrix:
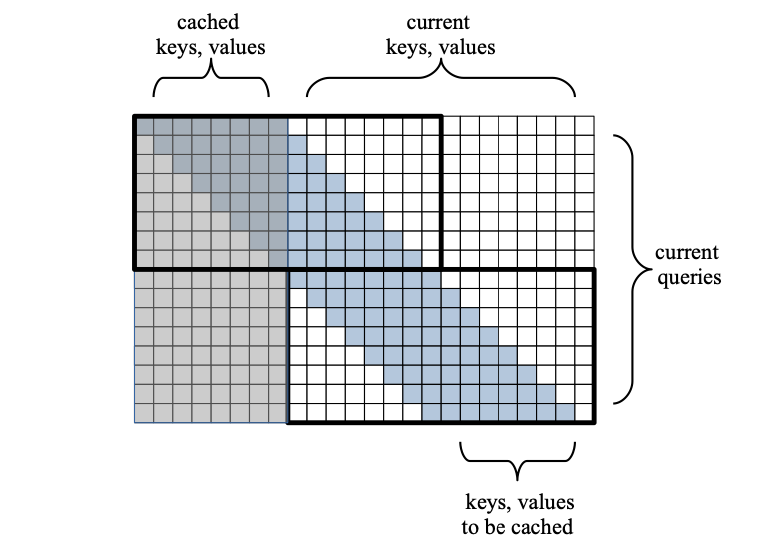
In Determine 6, we’ve got a window measurement W =8 and sequence size N =16. The primary W shaded tokens had been computed and cached on the earlier coaching step. The remaining N unshaded tokens come from the present enter.
Every token within the enter sequence attends to the earlier W=8 tokens successively, in a sliding trend. Subsequently, in every row, we’ve got W computations. The peak of the matrix is N (the variety of tokens in our sentence). Therefore, the full price is O(N*W) as an alternative of the complete price matrix O(N*(W+N)). In different phrases, the price with respect to the sequence N is linear as an alternative of quadratic!
So, in our instance, Consideration is finished to 2 tiles of measurement Wx2W. Let’s analyze the chain of occasions:
- Within the first consideration step, the primary
Wtokens of the enter sentence will attend to the final cachedWkeysandvaluesfrom the earlier sentence. - Within the second consideration step, the final
Wtokens of our enter sentence will attend to the primaryWtokens of our enter sentence. - This ends our coaching step and the final
Wkeysandvaluesof the enter sentences are cached for use for the following coaching step. - By now, you’ll have seen the sliding sample. That’s why we name this mechanism Sliding Self-Consideration.
Be aware: After I say the token X attends to the token Y, we don’t imply the token themselves: I imply the keys, values, and question scores of these respective tokens!
How recurrence helps
As I mentioned earlier, Sliding Self-Consideration (the non-recurrent model) was already in use by earlier fashions [6][7], with just a few variations although:
- Within the authentic model, the enter sentences weren’t partitioned into blocks. The fashions that used the easy Sliding Self-Attention had been ingesting the enter all of sudden. This restricted the quantity of knowledge they may course of effectively.
- The cached keys and values used from the earlier coaching steps are non-differentiable — which means they don’t seem to be up to date throughout backpropagation. Nevertheless, within the recurrent model, the sliding window has an additional benefit as a result of it may possibly backpropagate gradients over a number of blocks.
- The unique Sliding Self-Consideration mannequin at its topmost layer has a theoretical receptive area of
W*L, the placeLrepresents the variety of mannequin layers. Within the recurrent model, the receptive area is virtually limitless! That’s why the Block-Recurrent Transformer excels in long-range content material.
Lastly, the Block-Recurrent Transformer was put to the take a look at.
Experimental course of
The duty was auto-regressive language modeling, the place the aim was to foretell the following phrase, given a sentence.
The mannequin was examined on 3 datasets: PG19, arXiv, and Github. All of them include very lengthy sentences.
The authors examined the Block-Recurrent Transformer and used Transformer XL as a baseline. The Block-Recurrent Transformer was configured in two modes:
- Single Recurrent Mode: The authors used a 12-layer Transformer with recurrence solely on layer 10.
- Suggestions mode: The identical mannequin was used, besides this time the tenth layer didn’t simply loop the output to itself: The output of the tenth layer was broadcasted to all the opposite layers when processing the following block. Therefore, layers 1–9 may cross-attend that enter, making the mannequin extra highly effective however computationally dearer.
Analysis
The fashions had been evaluated utilizing perplexity — a standard metric for language fashions.
For many who don’t know, perplexity is outlined as P=2^L, the place L is standard entropy.
Intuitively, within the context of language modeling, you may consider perplexity within the following approach: If the worth of perplexity is 30, predicting the following phrase within the sentence is as unsure as guessing appropriately the results of a 30-sided die. The decrease the perplexity, the higher.
Outcomes
Normally, the Block-Recurrent Transformer considerably outperformed the Transformer XL when it comes to each perplexity and pace.
Additionally, relating to the Block-Recurrent Transformer, the Suggestions mode was higher than the Single Recurrent Mode. Nevertheless, the authors conclude that the extra efficiency doesn’t compensate for the additional complexity.
The paper authors tried varied configurations, corresponding to including or skipping gates. For extra info, examine the unique paper[2].
This text mentioned the Block-Recurrent Transformer, a breakthrough paper that leverages the normal RNN recurrence to extend the Transformer potential in lengthy paperwork.
I urge you to learn the unique paper[2], utilizing this text as a companion information to assist your understanding.
For the reason that paper may be very new, the authors haven’t launched any supply code, though there are some unofficial implementations on Github.
