
ACM.67 Creating Zero Belief rulesets or safety teams on AWS
It is a continuation of my collection of posts on Automating Cybersecurity Metrics.
Again after I labored on the community crew at Capital One, builders needed to submit requests outlining the community necessities for his or her functions which obtained reviewed by the safety crew after which carried out. I occurred to be one of many individuals implementing these requests in the course of the night time in manufacturing.
What usually occurred was the event crew would come within the subsequent day and their software didn’t work as anticipated. Generally I had made a mistake however as a rule, the community guidelines weren’t adequate to cowl all the software’s wants as a result of the builders didn’t absolutely perceive the connection necessities for his or her software.
This entire networking course of was very irritating for builders and particularly in the event that they didn’t perceive how networking works. They only wished to construct and run their functions in a whole lot of circumstances and so they didn’t wish to be community directors. A few of us just like the geekiness of designing a zero belief networks. Different individuals couldn’t be bothered as a result of they wish to construct cool functions that do leading edge issues for patrons.
Stopping Errors in Cloud Networking Implementations
One of many issues on this surroundings was that the dev, QA, and prod networking environments didn’t work the identical approach. I might extremely counsel working in the direction of a constant structure, although you’ll have some variations probably as a result of QA and safety instruments that you simply’ll most likely run in QA however not in manufacturing. When you can’t precisely mirror the environments then attempt to create a staging surroundings to check deployments that mirrors manufacturing.
Past that, for manufacturing environments, I began asking the event and QA crew to indicate up on the time I deployed their community so they might check it. That approach any errors I made could be found and stuck throughout the open window I needed to make the change. Moreover, if the crew made a mistake of their community request they might know instantly and never begin sending messages to higher administration about how the community crew of 5 individuals was blocking the deployments of 11,000 builders when it wasn’t our fault.
As I’ve been doing on this entire submit, leverage abstraction to simplify your community design and your code. Don’t write the identical code again and again. Reuse what you possibly can for repeated initiatives. Create acceptable community designs. Contemplate when you possibly can consolidate right into a single VPC or subnet and when issues needs to be segregated for correct belief boundaries. Additionally, there are newer constructs now which didn’t exist on the time like Transit Gateways and shared VPCs which can assist simplify community designs.
Figuring out your software community necessities with netstat
Apart from serving to builders with networking requests throughout each day workplace hours, the opposite factor I did was to write down a device that builders might run on their hosts to see what site visitors their software was sending and to assist them perceive the IP addresses and ports in use by their software. On the time Lambda features didn’t exist. Movement Logs didn’t both after I first began on that crew and weren’t carried out on our VPCs initially when the have been launched. For lack of one thing higher, I primarily wrote a script that ran a netstat command (I feel. It could have been tcpdump) and parsed out all of the IP addresses and ports with open connections.
Primarily you possibly can run one thing like this on a bunch and see what’s linked or what ports are open and listening:
netstat -an | grep 'tcp|udp'
I added a bit extra to it to formulate an inventory that could possibly be submitted in a community request to our crew. I’m making an attempt to recollect if I used that or tcpdump. It’s on some weblog submit at Capital One if it’s nonetheless printed. Netstat provides you some extent it time snapshot of connections, whereas tcpdump would seize site visitors for a time frame and may catch one thing netstat misses because it runs and inspects site visitors till you cease it. You’d must run netstat a number of occasions or use one thing that captures site visitors over time if in case you have a connection that periodically comes and goes.
This listing might or will not be full as a result of if you’re utilizing load balancers, then the system you run the script on may be linked to solely one of many load balancers however you may have one other load balancer on the market that the host will attempt to connect with later — so you continue to want to know your structure and never simply depend on this script alone, however the script helped. As well as, when builders ran this script, generally they discovered connections they didn’t anticipate and companies they wanted to show off that have been producing undesirable site visitors.
Leveraging FlowLogs to find out software networking necessities
It’s not fairly as easy to run netstat on a Lambda perform, although you definitely might. Additionally, now that we now have AWS Movement Logs we will question the logs to see what connections an software is making to find out how we will whittle down networking guidelines to a zero belief strategy (presuming all the pieces is logged, which it needs to be).
I defined how one can guarantee each VPC has Movement Logs enabled right here:
[LINK HERE]
Upon getting VCP Movement Logs Enabled you possibly can question your logs to see what your system elements are connecting to, presuming it will get logged. I present how to have a look at VPC Movement Logs on this Lambda Networking submit:
We’ll look extra at Lambda Movement Logs within the subsequent submit, however primarily you possibly can work out what community interface is related together with your Lambda Operate and take a look at the site visitors associated to it.
As soon as you realize what guidelines you have to implement you possibly can create your safety group guidelines.
Safety group guidelines are stateless
One of many errors I made early one was pondering that I wanted to permit site visitors each methods in a safety group the identical approach you do for NACLs. I didn’t notice that safety teams are stateless. That signifies that the networking elements checking to see if site visitors needs to be allowed or not are checking to see if a connection has been established in a single course, and in that case, it permits the return site visitors within the different course. In different phrases, for those who enable an IP tackle from the Web to connect with an online server on port 443 with an inbound rule, the return site visitors is allowed, no matter what outbound guidelines exist within the safety group.
Outbound safety group guidelines
The default outbound guidelines on an AWS safety group used to permit any outbound site visitors. I’ve written about my experiences up to now making an attempt to get a knowledge middle the place I had a managed server to dam outbound site visitors for me and why that issues in my guide and earlier weblog posts.
Don’t depart your outbound site visitors guidelines fully open. They too needs to be particular to scale back the blast radius if a bunch or compute useful resource is totally compromised. You exponentially depart programs open to knowledge exfiltration and lateral motion inside a subnet for those who depart these outbound guidelines open.
Do not forget that NACLs work between networks, that means on the subnet degree. They won’t block site visitors between hosts inside a subnet. That’s what safety teams will do for you.
Sadly, if you don’t deploy any outbound safety group guidelines utilizing CloudFormation, you’re going to get a default rule that permits outbound entry to anyplace. You’ll want to use a workaround to override it and I’ve seen some strategies which aren’t good corresponding to a rule to permit something in the identical safety group to ship site visitors to one another. We have to forestall all outbound site visitors and that doesn’t work except you solely have one factor in your safety group ever and nobody ever unintentionally or maliciously assigns that group to one thing else.
Endpoints or hosts assigned to the identical safety group can’t routinely talk with one another
A safety group is just not a bunch of hosts or endpoints or cloud sources. It’s a group of community guidelines. While you apply that group of guidelines to the host, it may solely talk on the ports and protocols you open to the hosts and networks you specify in these guidelines. Until you explicitly create a rule that claims the safety group can talk with different hosts in the identical safety group, that site visitors is blocked.
Creating guidelines between safety teams
One in all my favourite issues about safety teams is that you may create guidelines utilizing safety group IDs. That is handy as a result of usually the IP addresses assigned to hosts change within the cloud. As well as, when community guidelines change with reference to subnet and VCP CIDRS you don’t have to alter your safety teams. You may wish to enable a safety group to speak with different sources in the identical safety group and you should utilize the safety group ID for that.
Different Guidelines and Restrictions
The foundations within the cloud are all the time altering and there are a couple of different guidelines you’ll need to pay attention to when creating safety teams. Take a look at the newest documentation for extra corresponding to naming conventions and limits on the variety of guidelines in a bunch or a set of teams utilized to a useful resource:
Safety Teams and CloudFormation
Let’s create our safety teams. We’ll use CloudFormation:
GroupName: We are able to use this as a substitute of tags for safety group names.
Description: We are able to present a helpful description for the group so individuals comprehend it’s function.
VpcId: We should affiliate a safety group with a VPC, however we might find yourself utilizing the identical group configuration in several VPCs so we’ll wish to cross this worth in as a parameter.
Subsequent we now have SecurityGroupIngress and SecurityGroupEgress. The documentation says that is an embedded kind in a safety group, however we will nonetheless separate out our guidelines utilizing these sorts the identical approach we did for NACL guidelines as proven on this template:

We don’t need an rigid hardcoded answer like above so we now have a bit extra flexibility when creating rulesets. Take a look at the answer beneath.
Safety Group Template
First I’m going to create a generic, reusable safety group template with no guidelines related to it. This gives extra flexibility and requires much less code general to implement. Right here’s the standalone safety group template:
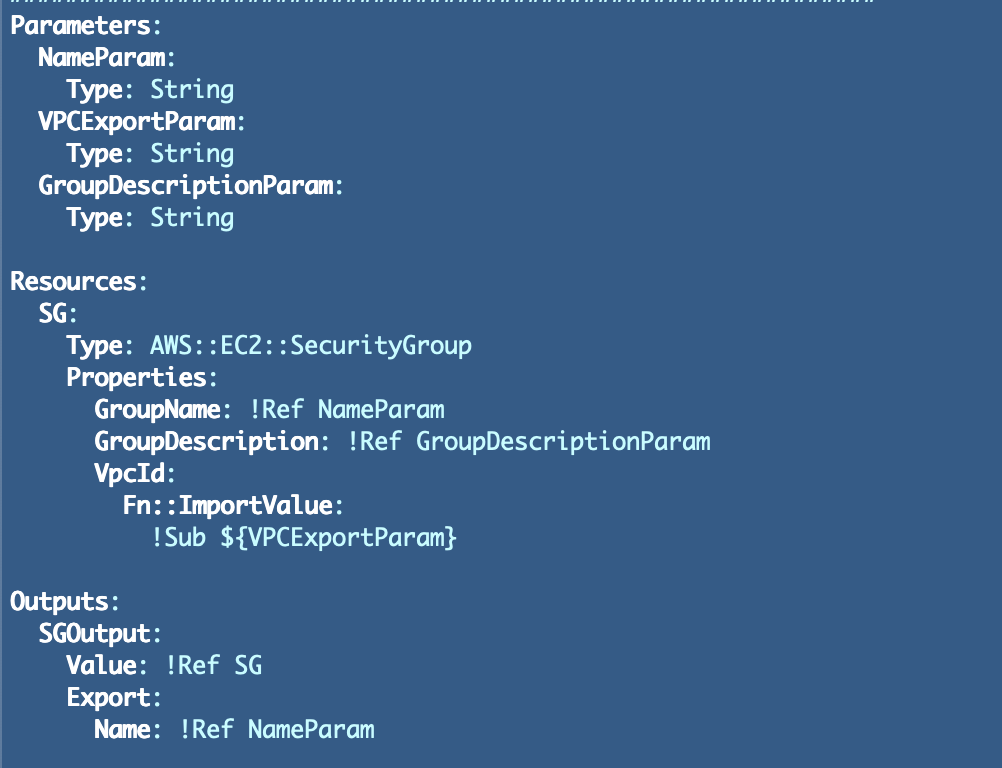
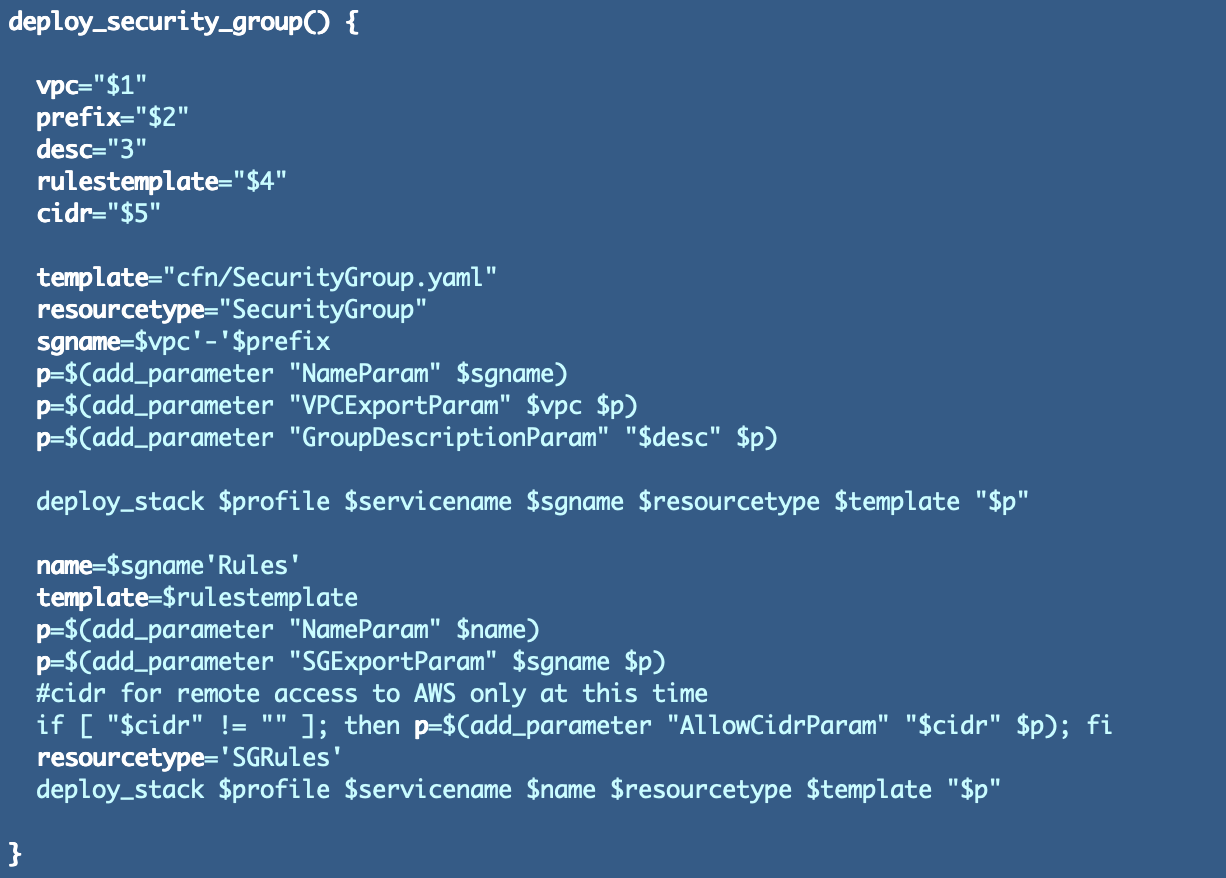
I’ll add a standard perform for safety group deployments like this:
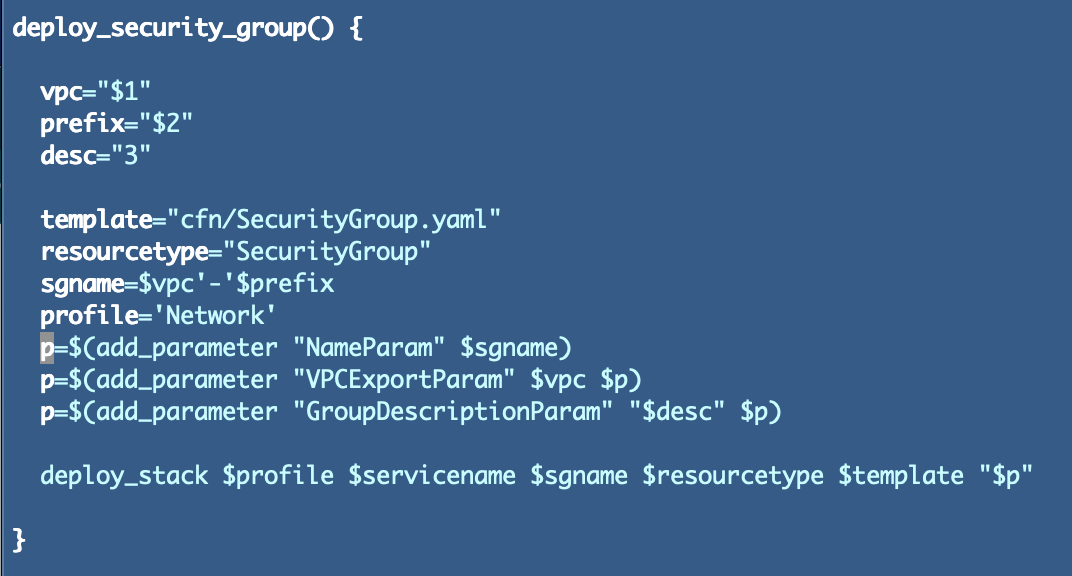
And name it like this for the primary safety group:

Observe that I nonetheless haven’t resolved the issue of areas in parameters handed round in bash. I might change my bash parameters to switches however actually I don’t wish to use bash in any respect for this so I’m leaving it this manner for now till I get all the pieces working.
After I checked the safety group to see what guidelines obtained created.
No inbound:
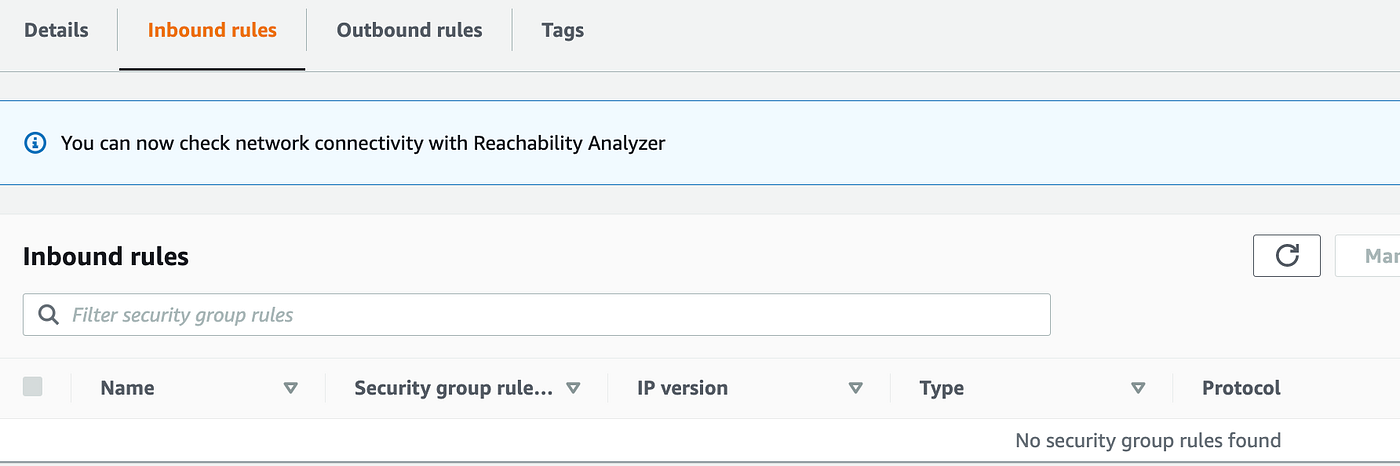
Outbound guidelines — discover the default any/any rule has been added:

We’ll repair the principles in a minute. for now we will add the RDP Group

And two batch job safety teams. I don’t know if I actually need two but.

Guidelines Templates
First we have to create our templates which outline the ingress and egress guidelines. For SSH and RDP we’re going to cross in a single CIDR right here however you possibly can modify as wanted to your functions. When you use a VPN, that is the place your community design could also be simpler. You enable all of your builders to connect with the VPN and as soon as authenticated on the community layer, they will attain a person host and log into it. When you use this design you possibly can limit site visitors for SSH and RDP to your VPN CIDRs reasonably than probably tons of of 1000’s of builders working remotely, or all the Web.
SSH
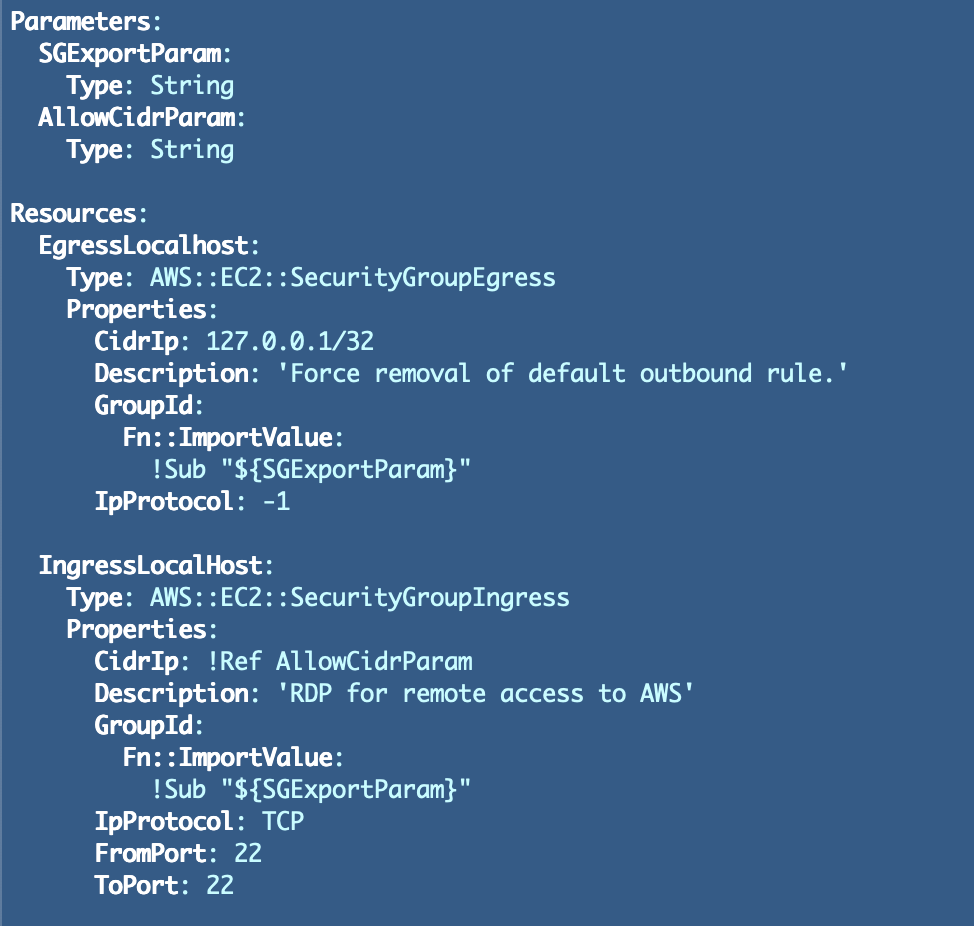
RDP
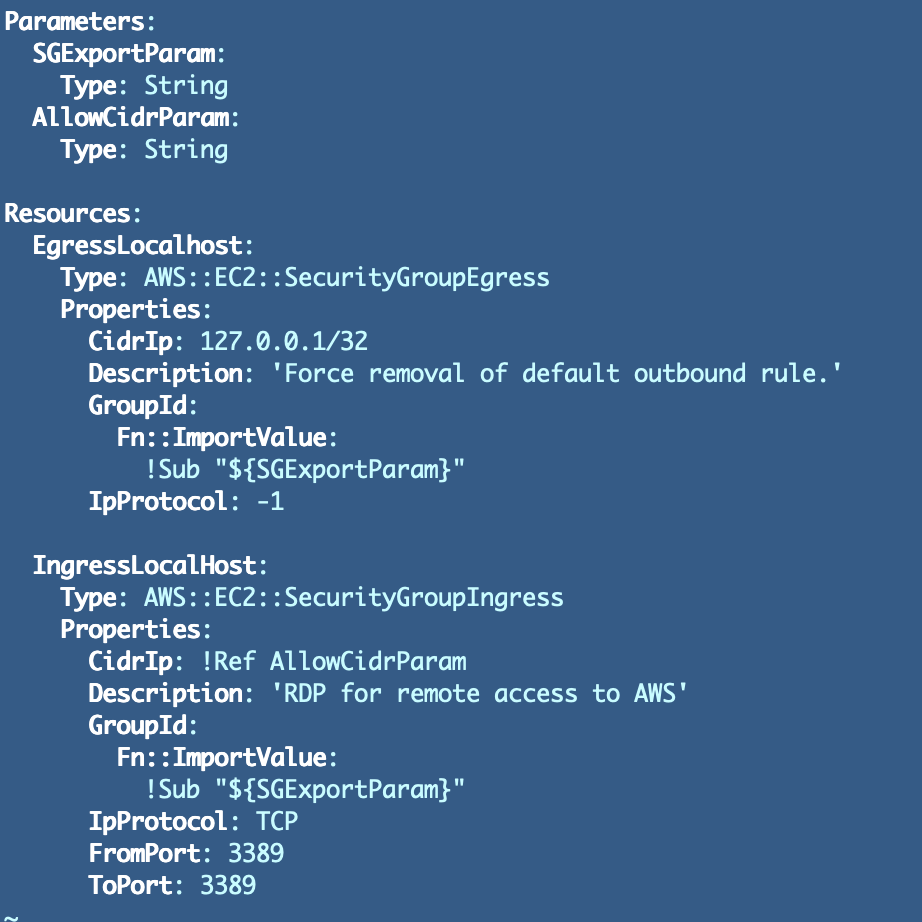
NO Entry — a template with no guidelines to quickly use for our Lambda features since we don’t know what guidelines we’ll want but.

Modify the deployment script to acquire a CIDR
To acquire the CIDR for now I’m going to cross it into my command line script utilizing echo and browse.

When you’re creating this to your personal use and also you solely wish to enable your IP tackle, you should utilize your public IP tackle. For a single IP tackle it’s important to put /32 on the finish to make it correct CIDR notation. You possibly can add some code to make use of a third-party service to lookup your IP tackle however I’ve had blended outcomes with these companies. I’ve one other answer in thoughts which I’ll attempt to write about later.
When you don’t know what your exterior, Web-facing IP tackle is, search “what’s my ip” in Google. That’s the IP tackle you have to use in your community guidelines on AWS.
You don’t want to make use of your native IP tackle in your laptops — which you will get utilizing ipconfig or ifconfig relying in your working system. This addresses ought to solely be accessible to gadgets in your native community.
Modify the safety group perform to name the principles template (handed in) and set the CIDR if supplied as a parameter.
Now check deploying our guidelines.
./deploy.sh
After the script runs, examine to see that every one your safety teams exist with the correct guidelines.
As I used to be creating this template I’m eager about future use circumstances and unsure the templates will keep precisely like this however they work fairly nicely for the speedy use case.
Now for closing testing, I can deploy an EC2 occasion within the distant Entry VPC — one Home windows and one Linux with the respective safety teams, and check to ensure I can login. If I’ve any issues there are a few issues I can do.
- Take a look at VPC Movement Logs. Seek for the IP tackle from which I’m making an attempt to attach. Seek for Rejected packets to find out if something is getting rejected from the Web. Seek for the non-public tackle of the host in AWS and see if that has any rejected packets.
- Run the AWS Reachability device. I don’t often use this as I have a tendency to have a look at logs however it’s possible you’ll discover it helpful.
Now if we have to add new safety teams we will use our Safety Group template and use an present or new rule template. If we now have a number of distant customers with totally different IP addresses, we will create a separate rule for every person.
We nonetheless have some clear as much as do. Comply with or updates.
Teri Radichel
When you favored this story please clap and observe:
Medium: Teri Radichel or E mail Checklist: Teri Radichel
Twitter: @teriradichel or @2ndSightLab
Requests companies through LinkedIn: Teri Radichel or IANS Analysis
© 2nd Sight Lab 2022
All of the posts on this collection:
____________________________________________
Writer:
Cybersecurity for Executives within the Age of Cloud on Amazon

Want Cloud Safety Coaching? 2nd Sight Lab Cloud Safety Coaching
Is your cloud safe? Rent 2nd Sight Lab for a penetration check or safety evaluation.
Have a Cybersecurity or Cloud Safety Query? Ask Teri Radichel by scheduling a name with IANS Analysis.
Cybersecurity & Cloud Safety Sources by Teri Radichel: Cybersecurity and Cloud safety courses, articles, white papers, shows, and podcasts

{kind=link}