
Search has at all times been core to the Stack Overflow expertise. It was one of many first options we constructed for customers, and for the reason that early days of Stack Overflow, most of our guests have come to us via search engines like google and yahoo. With search engine referrals persistently comprising over 90% of our web site visitors, we felt for a few years as if this was a solved downside.
Our search has been lexical, that means it tries to match key phrases in your question in an effort to determine one of the best outcomes. With the latest developments in AI and LLMs, nonetheless, semantic search has begun to push lexical get hold of of style. Semantic search converts a whole doc’s content material into numerical vectors based mostly on machine-learned that means, which a search can then traverse as if it have been a 3D bodily house. It permits for extra environment friendly storage of search information and higher, quicker outcomes, however most significantly, it permits customers to go looking utilizing pure language as a substitute of a inflexible syntax of key phrase manipulation.
We’re fascinated by search—co-author David Haney constructed his early profession on it. To David, search isn’t fascinating due to the employed logic and algorithms; it’s fascinating as a result of it’s a human sentiment downside. It doesn’t matter if the algorithms “work completely,” simply that the human doing the looking feels good concerning the outcomes—that they bought what they wished. With the rise in semantic search, we noticed a well-timed alternative to know the advantages of semantic for our personal web site search performance. Final week’s announcement at WeAreDevelopers highlighted how modifications to go looking, powered by OverflowAI, are an enormous a part of our roadmap. Beneath, we’ll dig into among the particulars of how search used to work round right here, and the way we’re constructing the following technology..
The previous methods: Lexical
Let’s speak about lexical search and the place we’ve come from. When Stack Overflow began in 2008, we used Microsoft SQL’s full-text search capabilities. As our web site grew to one of the crucial closely trafficked domains on the web, we wanted to broaden. We changed it with Elasticsearch, which is the business normal, and have been utilizing that ever since.
We use an algorithm that matches key phrases to paperwork utilizing TF-IDF (Time period Frequency – Inverse Doc Frequency). Basically, TF-IDF ranks a key phrase’s significance by how uncommon it’s throughout your complete search corpus. The much less usually a phrase seems, the extra necessary it’s. That helps to devalue “filler” phrases that seem on a regular basis in textual content however don’t present a lot search worth: “is,” “you,” “the,” and so forth. We use stemming, which teams associated phrase varieties in order that “run” can even match each “runner” and “working.” While you do a search, we discover paperwork that finest match your question with successfully no analysis of their location within the doc.
We do some extra processing to enhance relevance for the search outcomes, like bi-gram shingles, which tokenize phrases into adjoining pairs. This helps differentiate phrases like “The alligator ate Sue” from “Sue ate the alligator,” which have the equivalent key phrases however very completely different meanings.
However even with the top-of-the-line algorithm, lexical search suffers from a few important issues. To start with, it’s very inflexible. In case you misspell a key phrase or use a synonym, you received’t get good outcomes except somebody has achieved some processing within the index. In case you pack a bunch of phrases into a question—by, let’s say, asking a query as in case you have been having a dialog with somebody—then you definitely won’t match any paperwork.
The second downside is that lexical search requires a domain-specific language to get outcomes for something greater than a stack of key phrases. It’s not intuitive to most individuals to have to make use of specialised punctuation and boolean operators to get what you need.
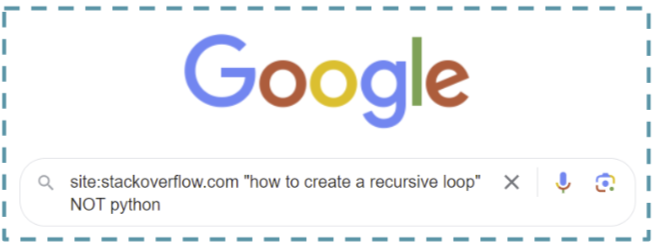
To get good outcomes, you shouldn’t have to know any magic phrases. With semantic search, you don’t.
And the brand new: Semantic
As we mentioned earlier, search is a human sentiment downside. We don’t wish to have to determine the precise key phrases in a question; we simply wish to ask a query and get a superb reply. Questions and solutions are the bread and butter of stackoverflow.com and our Stack Trade websites. It is smart to make use of semantic search to make our search equally intuitive and approachable.
Semantic search is a very completely different paradigm than lexical search. Think about the search house as a 3D dice the place all of the paperwork are given a numerical rating based mostly on their that means and embedded into vectors with coordinates. Vectors are saved in proximity to one another in response to the meanings of their phrases. Stated one other means, in case you consider the search house as a metropolis, phrases with carefully associated that means or sentiment will reside in the identical or adjoining neighborhoods.
While you run a search, your question is first reworked right into a vector in the identical means that your paperwork have been listed. The system then traverses the vector house from the question embeddings to search out close by vectors, as a result of these are associated and due to this fact related. In a means, it’s a nearest-neighbor operate, because it returns the vectors for phrases present in your paperwork which can be most carefully located to the question.
The search itself is an easy mathematical calculation: cosine distance. The actual problem is in creating the embeddings themselves.
The primary problem is deciding what mannequin to make use of. We may select between a pre-tuned open supply, a proprietary mannequin, or fine-tuning our personal mannequin. Fortunately, our information dumps have been utilized in many of those embedding fashions, so they’re already optimized for our information to some extent. In the meanwhile, we’re utilizing a pre-tuned open supply mannequin that produces 768 dimensions. Others, primarily closed-source fashions, can produce double and even triple that quantity, however it’s fairly broadly accepted that these fashions are pointless and even overkill.
The second problem is deciding find out how to chunk the textual content; that’s, find out how to break the textual content up into tokens for embedding As a result of embedding fashions have a set context size, we’d like to ensure to incorporate the precise textual content within the embedding: not too little but in addition not an excessive amount of.
With this semantic mapping of our information, we will keep away from the rigidity and strictness of lexical search. You’ll be able to write your question like a pure query you’d ask a pal, and get related outcomes again in form. When trying to find “find out how to type record of integers in python”.
The draw back to semantic search is that generally you really need a inflexible search. In case you’re searching for a particular error code or distinctive key phrase, then semantic search might not do as effectively. Basically, semantic search does worse with brief queries, like two- or three-word phrases. However fortuitously, we don’t need to completely use both lexical or semantic—we will do a hybrid search expertise. In a hybrid mannequin, we will proceed to assist our Superior Search use circumstances whereas providing one of the best of semantic search to most customers on the identical time.
After all, the satan is within the particulars, so right here’s what we’ve been doing to make semantic search a actuality on Stack Overflow.
Implementing semantic search on SO
Semantic search and LLMs go collectively like cookies and milk. Throughout the know-how sector, organizations are quickly deploying Retrieval Augmented Technology (RAG) to create intuitive search experiences. We’re doing equally—in spite of everything, Not Invented Right here is an antipattern! The factor about RAG is that it’s solely nearly as good as the standard of your search outcomes. We predict our tens of tens of millions of questions and solutions—curated and moderated by our superb neighborhood—are about as certified because it will get.
Constructing on the work we did to construct course suggestions, we used the identical pipeline from our Azure Databricks information platform that fed right into a pre-trained BERT mannequin from the `SentenceTransformers` library to generate embeddings. For the vector database that saved these embeddings, we had a number of non-negotiable necessities:
- It needed to be open-source and never hosted so we may run it on our current Azure infrastructure.
- It wanted to assist hybrid search—lexical and semantic on the identical information.
- As a result of our current information science efforts have leaned fairly closely into the PySpark ecosystem, it wanted to have a local Spark connection.
Weaviate, a startup centered on constructing open supply AI-first infrastructure, glad all these necessities. To this point, so good.
The a part of this method that may endure probably the most experimentation as soon as it rolls out is the embedding technology course of. Particularly, what textual content we embrace as a part of the embedding for a query or reply—and the way we course of it. We’ve made our embedding technology pipeline extremely configurable to simply assist creating a number of embeddings per publish. This could allow us to experiment quickly.
We even have entry to different alerts that assist outline the standard of a query and its solutions: votes, web page views, anonymized copy information, and extra. We may bias in direction of up to date paperwork which have been edited lately or obtained new votes. There are lots of levers we will pull—and as we experiment within the coming months—we’ll work out which of them add probably the most worth to our search expertise..
One other necessary sign is suggestions from the neighborhood. We wish to know when persons are proud of their search outcomes. So while you see an opportunity to present us suggestions, please do!
AI and the longer term
Allow us to pose a query: to programmers searching for correct, logically appropriate solutions to their questions, what good is an LLM that hallucinates? How do you’re feeling while you’re given technical steering by a conversational AI that’s confidently incorrect?
In all of our forthcoming search iteration and experimentation, our ethos is straightforward: accuracy and attribution. In a world of LLMs creating outcomes from sources unknown, we are going to present clear attribution of questions and solutions utilized in our RAG LLM summaries. As at all times on Stack Overflow, your whole search outcomes are created and curated by neighborhood members.
Our speculation is that if our semantic search produces high-quality outcomes, technologists searching for solutions will use our search as a substitute of a search engine or conversational AI. Our forthcoming semantic search performance is step one in a steady experimental course of that may contain lots of information science, iteration, and most significantly: our customers. We’re excited to embark upon this journey along with our neighborhood and might’t wait so that you can expertise our new semantic search.
Tags: embedding, search, semantic search, vector

{kind=link}