Introducing nbsynthetic: a easy however highly effective tabular information technology open supply library for small datasets.

On this article we introduce nbsyntehtic, an open supply mission created by NextBrain.ml for a easy and strong unsupervised artificial tabular information technology python library.
- Easy: Designed with a easy and steady unsupervised GAN (Generative Adversarial Community) structure based mostly in Keras.
- Sturdy: With particular hyperparameter tuning to make sure coaching stability whereas minimizing computational price.
Benefits:
- As a result of it’s based mostly on an unsupervised structure, customers don’t have to have a predefined goal.
- It’s supposed primarily for small datasets with each steady and categorical options.
- Due to their simplicity, fashions will be run on a CPU.
- Modules for fast enter information preparation and have engineering are included.
- Modules for operating statistical assessments and evaluating actual and artificial information (we don’t just like the time period “faux information”) are included. It additionally features a particular statistical check (Most Imply Discrepancy — MMD) that measures the gap between the technique of two samples mapped right into a reproducing kernel Hilbert house (RKHS).
- Plotting utilities are included for evaluating the likelihood distributions of authentic and artificial information.
Right here you could find the nbsynthetic mission (library, documentation, and examples).
Synthetic information is experiencing its glory days, with a number of functions for picture, video, and speech technology. Lately, there was a rising curiosity in generative fashions for functions akin to creating new varieties of artwork or simulating video sequences. Nevertheless, developments in tabular information appear to be much less formidable, regardless of being essentially the most frequent kind of information obtainable on this planet. Artificial tabular information is disrupting industries like autonomous automobiles, healthcare, and monetary companies. The healthcare enterprise embraces this novel thought, particularly for addressing sufferers’ privateness issues, but in addition for simulating artificial genomic datasets or affected person medical data in analysis initiatives.
Spreadsheets are utilized by almost 700 million individuals worldwide every single day to cope with small samples of information introduced as tabular information.
Spreadsheets are utilized by almost 700 million individuals worldwide every single day to cope with small samples of information introduced as tabular information. This data is usually used to make selections and acquire insights. Nevertheless, it’s generally thought of as “poor high quality’” information as a result of incomplete data or for being small (lack of statistical significance). Machine Studying may very well be extremely worthwhile in these functions. However, as any information scientist is conscious, the present cutting-edge in ML is targeted on giant datasets, excluding a considerable variety of potential ML customers. Moreover, we should handle fashionable statistics necessities that warn on the low reliability of ML algorithms when utilized to small pattern measurement information.
Artificial tabular information is disrupting industries like autonomous automobiles, healthcare, and monetary companies.
For instance, we’re serving to a big psychiatric hospital with a knowledge evaluation mission. They got here to us with complete analysis based mostly on information collected during the last ten years. Psychiatric hospitalizations are essential, and this analysis started with the objective of bettering early alerts and prevention protocols. We acquired the leads to the type of a spreadsheet with thirty-eight columns and 300 rows. There have been quite a few empty values (solely seven rows contained all thirty-eight function values). Actually, that could be a small quantity of information for any information scientist, and even much less for a statistician. It was, nevertheless, a difficult effort for them to gather this information. With this information, the validity of any statistical methodology could be questioned. By creating artificial datasets, we have been capable of present dependable data with statistical validity and likewise handle the privateness challenge, a essential level for affected person report administration.
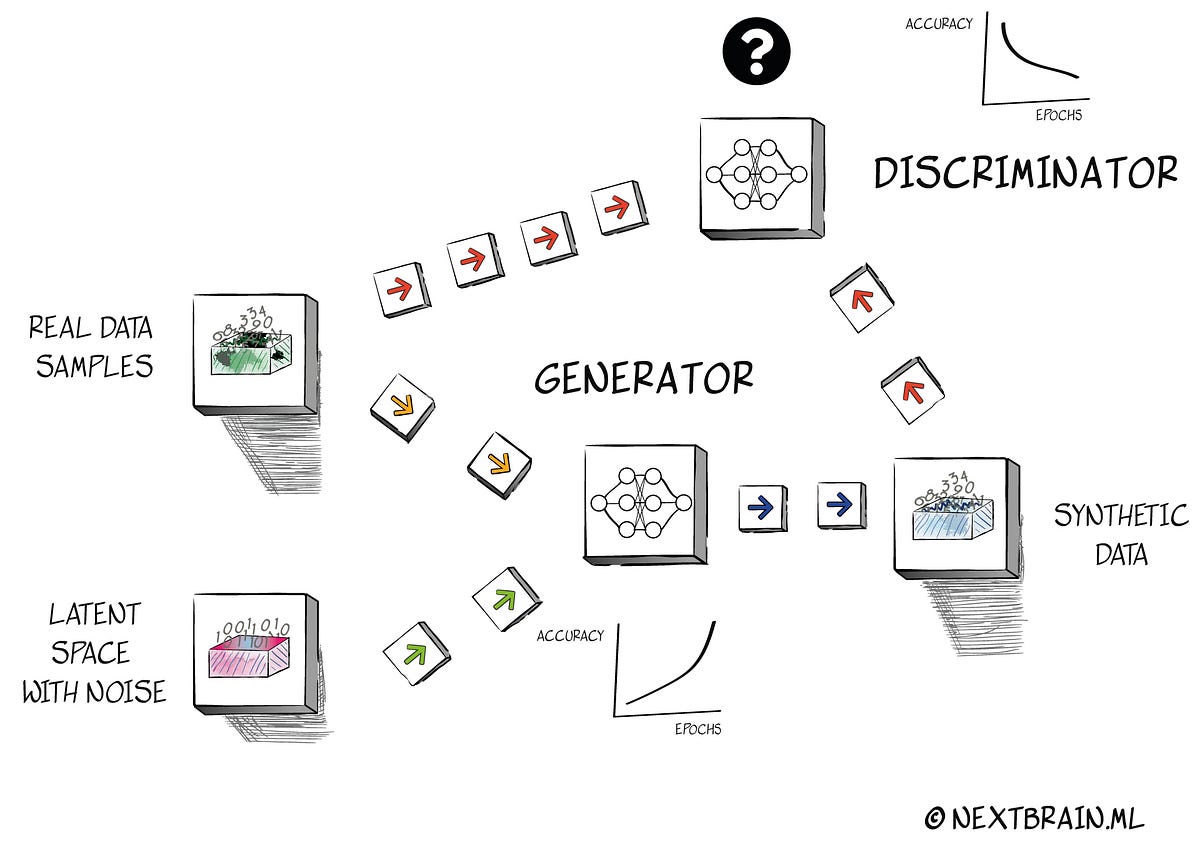
Generative Adversarial Networks, or GANs, are the expertise on the coronary heart of those generative functions. GANs have been launched by Ian Goodfellow in 2014 [1]. The thought was to engineer two separate neural networks and pit them towards one another. The primary neural community begins out by producing new information that’s statistically much like the enter information. The second neural community is tasked with figuring out which information is artificially created and which not. Each networks constantly compete with each other: the primary tries to trick the second, and the second tries to determine what the primary is doing. The sport ends when the second community just isn’t capable of ‘discriminate’ if information is coming from the primary community output or from the unique information. We name the primary community generator and the second community discriminator.
Training generator and discriminator fashions on the similar time is mostly unstable by definition.
Coaching generator and discriminator fashions on the similar time is mostly unstable by definition[2], so the principle drawbacks of GANs are unstable coaching and mode collapse. The evolution of GANs has introduced attention-grabbing concepts to unravel this challenge, akin to introducing additional data to the discriminator with a purpose to get higher accuracy and provides extra stability to the framework (conditional GANs or cGANs). This variant methodology requires a ‘goal’ or reference class that situations the GAN output with further data. However after we are addressing the aforementioned goal customers, we discover that many datasets should not have a single goal function as a result of customers need to make predictions on completely different options with a purpose to get extra insights about their information.
Conditioning the artificial information to a single function can even introduce a bias within the generated information if the person needs to, for instance, resolve a ML drawback utilizing one other function as a goal. Because of this a non-conditional GAN or non-supervised GAN (additionally known as vanilla GAN) is attention-grabbing for such issues, as a result of it isn’t crucial to decide on a goal.
Though the accuracy we get could also be elevated by offering the GAN with a dependable goal class (an ‘additional’ situation in a cGAN), an unsupervised GAN is a flexible instrument for these lively spreadsheet customers who’ve small to medium-sized information units, with poor information and the necessity to acquire normal actionable insights. Nevertheless it additionally has some limitations.
The explanation why GANs are unstable throughout their coaching is that when the generator (G) and discriminator (D) are educated concurrently, one mannequin’s enhancements are made at the price of the opposite mannequin in a non-cooperative sport[3]. nbsynthetic makes use of the Keras open-source software program library. Its structure is predicated on a linear topology utilizing a fundamental Sequential structure with three hidden layers in each the generator and discriminator. Our GAN mannequin has a sequential structure the place G and D are linked.
This mannequin has been designed with the next concerns in thoughts:
1. Initialization.
Initialization is the method to outline the place to begin for the optimization (studying or coaching) of the neural community mannequin. When this course of just isn’t optimum, coaching course of can fail due its instability. We are going to break the symmetry of our GAN by randomly initializing the weights. The thought is to keep away from having all neurons in a layer be taught the identical data. Then we’ll use a Batch Normalization [5] which stabilizes studying by normalizing the enter to every unit to have zero imply and unit variance.
2. Convergence
As we now have seen, because of the GANs sport, each fashions (G and D) can fail to converge [4]. In picture technology, the principle technique to keep away from these convergence failures has been utilizing convolutional nets [5]. The convolution layer maps enter options to a higher-level illustration whereas preserving their decision by discarding irrelevant data over a number of downsampling steps [6]. However this technique, which has proven related advances for picture and speech technology, doesn’t appear best for small pattern measurement tabular information as a result of we are able to lose data in every step. Truly, when working with small pattern measurement tabular datasets, we realized that lots of the enhancements made to spice up the accuracy of GANs in picture recognition are unfavorable. We selected a easy and dense structure because the optimum method for nbsynthetic.

3. Activation capabilities
LeakyReLU (a sort of activation perform based mostly on a ReLU however it has a small slope for adverse values as an alternative of a flat slope) is widespread in GAN architectures. Nevertheless, each have completely different missions. G has to generate a knowledge illustration as shut as potential to the unique information, whereas D has to resolve (classification) if the output is completely different from the enter information or not. For constructing each generator and discriminator sequential fashions, we use the LeakyReLU activation perform. For mannequin compilation, we’ll use a tanh activation perform (with a spread -1 to 1) for G, and for D we’ll use a sigmoid perform ranged from 0 to 1, as a result of it has to easily ‘resolve’ if the info is legitimate or not.
tanh (and sigmoid however not LeaskyReLU) are steady capabilities with steady inverses. So the tanh layer (generator) preserves topological properties within the output layer, however results in a a lot increased gradient than the sigmoid perform. The thought is to assist the community attain the worldwide minimal sooner with a purpose to keep away from complicated it when we now have a combination of steady and categorical options.
We will’t use linear activation capabilities as a result of categorical options would confuse the GAN. The discriminator activity is to categorise the output into “equal to enter information” lessons. Classification with a sigmoid unit (discriminator) is equal to looking for a hyperplane that separates lessons within the closing layer illustration. On this case, utilizing a sigmoid perform with a decrease gradient will enhance classification accuracy.
4. Optimization
Each G and D are educated with stochastic gradient descent utilizing the Adaptive Second Estimation optimizer — Adam — to compute adaptive studying charges for every parameter[7]. We’re utilizing a small studying price (lr = 0.0002) and a lowered momentum time period (or imply of the gradient) beneath the default worth of 0.9 (β1 = 0.4), with the purpose of lowering instability.
5. Noise injection
G creates a pattern utilizing a fixed-length random vector ξ as enter. This vector is the latent house. A compressed illustration of the info distribution will likely be generated after coaching when factors on this multidimensional vector house match the enter information. ξ is normally sampled from Gaussian distributions and may be capable of enhance the numerical stability of GANs [8]. This course of is also called noise injection. The error perform when coaching with noise is much like a regularization perform [9] the place the coefficient λ of the regularizer is managed by the noise variance.
A uniform distribution is definitely a standard distribution with a most customary deviation. So utilizing a uniform distribution we improve the worth of the variance and so the worth of the coefficient λ. We will cut back overfitting throughout coaching by rising the coefficient λ with a easy community construction and a small pattern tabular enter information. Our experiments have supported this speculation.

6. Enter information preparation
Enter information preparation is probably an important ingredient for a non-supervised GAN. This community expects to obtain low and medium pattern measurement information (as much as 100 options and fewer than 1000 cases). Moreover, information can have each steady and categorical columns. Steady columns might not essentially observe regular distributions and should comprise outliers. Categorical columns will be boolean or multi-class .
An important resolution level in information preparation will likely be to establish each information sorts in order that they are often handled in a different way. We solely have to scale categorical columns from -1 to 1. (as a result of we’re utilizing tanh activation capabilities). Nevertheless, with a purpose to be strong to completely different likelihood distributions of inputs and outliers, we should remodel steady information. We’re going to map all several types of enter likelihood distributions to uniform distributions utilizing a quantile transformation [10]. In consequence, as a result of noise injection (latent house) can also be a uniform distribution, generator G will solely course of information with steady uniform distributions as inputs.
Producing artificial information has an vital problem in being certain that new information may be very “shut” to authentic information. There are a number of statistical assessments to search out out if two samples belong to the identical likelihood distribution. The Scholar’s t-test, the Wilcoxon signed-rank check (a nonparametric variation of the paired Scholar’s t-test), and the Kolmogorov-Smirnov check for numerical options are included on this library [11]. These assessments examine the likelihood distributions of every function within the enter dataset and the artificial information in a one-to-one method (known as the “two-sample check” or also called the “homogeneity drawback”).
Fashionable statistical assessments are fairly highly effective, however sure assumptions have to be made.
These assumptions make making use of these assessments to widespread datasets troublesome when some options might battle with the hypotheses whereas others don’t. This information additionally comprises a mix of distinct varieties of options with completely different likelihood distributions, so a single check just isn’t legitimate for all of them on the similar time. Some assessments, for instance, depend on the normality assumption (information follows a standard distribution), but we are able to have information with options of virtually any distribution. For instance, Scholar’s t-test is a check evaluating means, whereas Wilcoxon’s assessments the ordering of the info. For instance, if you’re analyzing information with many outliers, Wilcoxon’s check could also be extra applicable. The Scholar’s t check depends on the idea of normality; that’s, samples are usually distributed.
However, the Wilcoxon check is simply legitimate for steady values. The Kolmogorov-Smirnov Goodness-of-Match Check[11] is used to resolve if a pattern comes from a inhabitants with a selected distribution. It solely applies to steady distributions like Wilcoxon’s check, and is prone to be extra strong with distributions which might be forward of normality.
To handle this challenge, we proposed fairly a special resolution by utilizing the Most Means Discrepancy check (MMD)[12]. MMD is a statistical check that checks if two samples belong to completely different distributions. This check calculates the distinction in means between two samples, that are mapped onto a reproducing kernel Hilbert house (RKHS)[13]. The Most Imply Discrepancy has been extensively utilized in machine studying and nonparametric testing.
Based mostly on samples drawn from every of them, MMD evaluates whether or not two distributions p and q differ by discovering a clean perform that’s giant on factors drawn from p and small on factors drawn from q. The statistic measurement is the distinction between the imply perform values of the 2 samples; when this distinction is giant, the samples are almost certainly from completely different distributions. Another excuse we selected this check is that it performs higher with information from small pattern sizes (a quite common assumption within the majority of statistical assessments).
Topological Knowledge Evaluation, or TDA [14], is a brand new method to coping with information from a special perspective. There are numerous benefits to making use of this cutting-edge method when evaluating authentic with artificial information:
- Quantitative evaluation ignores important data hidden in information. Additionally, in lots of information representations, it’s unclear how a lot worth precise information distances have, due to this fact measures should not all the time justified.
- TDA is anxious with distances and clusters with a purpose to characterize information in topological areas. To construct a topological house, we now have to rework information factors into simplicial complexes. These are representations of house as a union of factors, intervals, triangles, and different higher-dimensional analogues shaped by connecting factors (also called filtration). The impact of connecting factors in an area by rising some radius round them leads to the creation of geometric objects known as simplices (this is the reason they’re known as simplicial complexes).

Steps in persistence homology are illustrated within the above determine. First, we outline a level cloud. Then we use a filtration methodology to create simplicical complexes and, lastly, we establish the topological signatures of information (that is how we name hyperlinks and loops) and characterize them in a persistence diagram. These diagrams present a helpful option to summarize the topological construction of a point-cloud of information or a perform. Knowledge topological areas are homotopy equivalent[15] to enter datasets.
A comparability of persistence diagrams from an enter dataset and an artificial one generated utilizing nbsynthetic from the primary is proven within the picture beneath. As we are able to see, each diagrams are very comparable signatures. We will see that hyperlinks (red-colored factors — H0) have an identical distribution, that means that each have very comparable topological signatures. In an artificial dataset (ten occasions the size of the unique dataset), there seems to be a loop (inexperienced coloured level — H1) and even a void (H2), however there additionally seems to be noise.
We will additionally apply a quantitative evaluation check to examine if each diagrams are equal. We will use the Mann Whitney U check [16], which is used to check whether or not two samples are prone to derive from the identical inhabitants. Within the information used within the determine, the p-value is 1 for hyperlinks and 1 for loops (we are able to reject the null speculation), that means that each diagrams are equal. That’s, generated artificial information has the identical topology as authentic enter information.

The picture beneath illustrates nbsynthetic information created from a three-dimensional tree level cloud. We will see that the “artificial tree” shares little or no with the “actual tree.” If we run the MMD check as beforehand described, the MMD worth is 0.12. We usually settle for, as a measure of ‘closeness’ between authentic and artificial information, MMD values of lower than 0.05 (widespread values in our experiments have been between 0.001 and 0.02). This instance was chosen as a result of it clearly demonstrates our artificial limitations: coping with low-dimensional enter information (3) and information containing solely steady columns.

Low-dimensional inputs confuse the GAN through the regularization course of, leading to incomprehensible outputs. Artificial information is collapsing on all axes, that means that GAN’s discriminator hasn’t been capable of distinguish between actual and generated information. In consequence, the GAN is unable to generate an acceptable illustration of the enter information when solely steady options are fed into it. However after we add an additional function with a categorical dtype to the enter information, MMD values fall routinely, that means that the enter information is extra precisely represented. We should remember the fact that the enter latent variable (or noise injection) of our generator has a uniform distribution. If we swap to a standard distribution, the accuracy improves as nicely (though it doesn’t get very excessive accuracy both). It seems as if categorical options function as “reference” or “conditional” enter, as an exterior class does in conditional GANs or cGANs. This limitation helps us to grasp a bit extra how our GAN works.
We should keep in mind that nbsynthetic doesn’t repair enter information drawbacks akin to imbalanced information or information distributions with extreme skewness. Artificial information doesn’t essentially should be taught the precise distribution of enter information options, however will probably be shut. What we demand from the GAN community is to grasp how these options are linked to one another; that’s, to grasp patterns. Then, it may very well be essential to carry out further transformations on artificial information with a purpose to obtain issues like heteroscedasticity or to scale back the bias generated for imbalanced goal information.
A future step for this mission is to incorporate a module that transforms enter information with a purpose to keep away from these limitations.
We now have launched a library for artificial tabular information technology to be used with small (and medium-sized) pattern datasets. We now have used an unsupervised GAN with a easy linear topology with a purpose to cut back its complexity and computational price. To make it dependable, we now have acutely analyzed hyperparameter tuning to generate artificial information as “shut” to the unique information as potential. We now have additionally explored the easiest way to quantify this closeness with statistical instruments. Within the nbsynthetic git hub repository tutorial, you can find further strategies akin to switch studying or topological information evaluation (additionally launched right here) that aren’t but obtainable within the library.
We need to proceed bettering the library in two instructions:
- Exploring different GAN architectures for the above talked about case of solely steady options being obtainable within the enter information.
- We’re exploring extra strategies to quantify how completely different authentic and generated information are. Topological information evaluation is essentially the most promising means.

{kind=link}