An intuitive clarification of sentence embeddings utilizing the Siamese BERT (SBERT) community and the right way to code it
On this article, I’m going to clarify every part it is advisable know concerning the underlying mechanics behind the Sentence-BERT mannequin. I may even element how its distinctive structure is used for particular, distinctive duties like semantic similarity search, and how one can code this.
These days, lots of the most generally used transformers for a plethora of NLP duties, like query answering, language modeling, and summarization are word-level transformers. For instance, transformers like BERT, RoBERTa, and the unique transformer resolve many various duties by computing word-level embeddings, they usually have been additionally skilled to carry out duties like masked language modeling. Nevertheless, for a job like semantic search, which requires a powerful sentence-level understanding, utilizing simply word-level transformers turns into computationally unfeasible.
Semantic search is a job that entails discovering the sentences which can be much like a goal/given sentence in which means. In a paragraph of 10 sentences, for instance, a semantic search mannequin would return the highest okay sentence pairs which can be the closest in which means with one another. Utilizing transformers like BERT would require that each sentences are fed into the community, and once we evaluate numerous sentences (a number of hundred/thousand) the computations required makes BERT an unfeasible selection (it could take a number of hours of coaching).
This paper goals to beat this problem by way of Sentence-BERT (SBERT): a modification of the usual pretrained BERT community that makes use of siamese and triplet networks to create sentence embeddings for every sentence that may then be in contrast utilizing a cosine-similarity, making semantic seek for numerous sentences possible (solely requiring a number of seconds of coaching time).
What does BERT do?
BERT solves semantic search in a pairwise style. It makes use of a cross-encoder: 2 sentences are handed to BERT and a similarity rating is computed. Nevertheless, when the variety of sentences being in contrast exceeds a whole bunch/hundreds of sentences, this may lead to a complete of (n)(n-1)/2 computations being completed (we’re basically evaluating each sentence with each different sentence; i.e, a brute pressure search). On a contemporary V100 GPU, this may require a number of hours of coaching time (65 hours to be particular). Here’s a diagram representing the cross-encoder community of BERT:
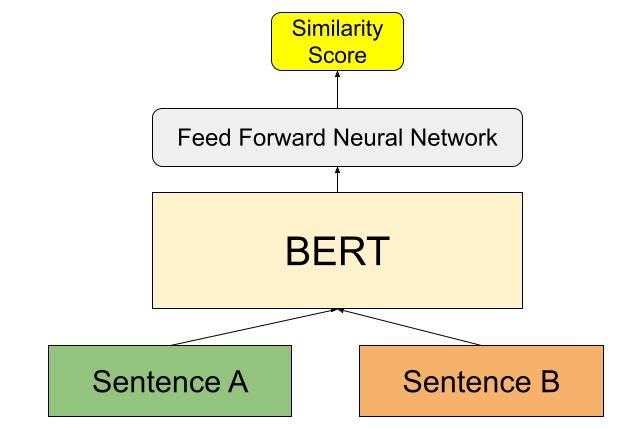
The BERT cross-encoder consists of an ordinary BERT mannequin that takes in as enter the 2 sentences, A and B, separated by a [SEP] token. On prime of the BERT is a feedforward layer that outputs a similarity rating.
To beat this drawback, researchers had tried to make use of BERT to create sentence embeddings. The most typical manner was to enter particular person sentences to BERT — and do not forget that BERT computes word-level embeddings, so every phrase within the sentence would have its personal embedding. After the sentences have been inputted to BERT, due to BERT’s word-level embeddings, the commonest approach to generate a sentence embedding was by averaging all of the word-level embeddings or through the use of the output of the primary token (i.e. the [CLS] token). Nevertheless, this technique usually resulted in dangerous sentence embeddings, usually averaging worse than averaged GLoVE embeddings.
What are Siamese Networks?
Siamese neural networks are particular networks that include two (or extra) similar subnetworks/fashions, the place the (often ) two fashions share/have the identical parameters/weights. Parameter updating is mirrored throughout each sub-models. Siamese networks are mostly used to compute similarity scores of the inputs, in order that they have many functions.
One purpose why Siamese networks are so highly effective and versatile is that they’re skilled primarily by computing similarities between two issues (usually photos, however in our case, sentences). Due to this, including new courses (for classification duties) or evaluating two issues (two sorts of photos, for instance) the place one merchandise has a classification not current through the coaching turns into straightforward to do. Here’s a diagram representing the structure of siamese networks. The mannequin makes use of the siamese networks/shared weights/2 CNN’s to compute encodings for each photos, after which makes use of a similarity operate and an activation operate to compute the similarity between each encodings.

So how precisely do you practice Siamese Networks?
You might be pondering that, if siamese networks are additionally skilled in a pairwise style, shouldn’t additionally they be very computationally inefficient?
That is incorrect. Whereas Siamese networks are skilled in a pairwise style, they aren’t skilled with each doable pair combos within the group of things like BERT did. Basically, the SBERT community makes use of an idea referred to as triplet loss to coach its siamese structure. For the sake of explaining triplet loss, I’ll use the instance of evaluating/discovering related photos. Firstly, the community randomly chooses an anchor picture. After this, it finds one constructive pair (one other picture belonging to the identical class) and one adverse pair (one other picture belonging to a distinct class). Then, the community calculates the similarity rating between the two photos for every pair utilizing a similarity rating (this varies primarily based on what operate you might be utilizing). Utilizing these 2 similarity scores, the community will then calculate a loss rating, after which replace its weights/run backpropagation primarily based on this loss. All the photographs within the dataset are assigned in/to those triplet teams, so the community is ready to be skilled on each picture within the dataset, with out having to run a computationally inefficient brute pressure/be skilled on each mixture/pair of photos.
The authors within the paper for SBERT use one thing much like this, however not the precise mechanism. In spite of everything, in contrast to picture classification, in semantic search, sentences don’t have a category that they are often related to. The authors use a singular approach involving discovering and minimizing the euclidian distance between sentences and utilizing this metric to seek out what sentence pairs could be thought-about constructive and what pairs could be thought-about adverse. You possibly can learn extra about it of their paper right here.
What does SBERT do and the way does it work?
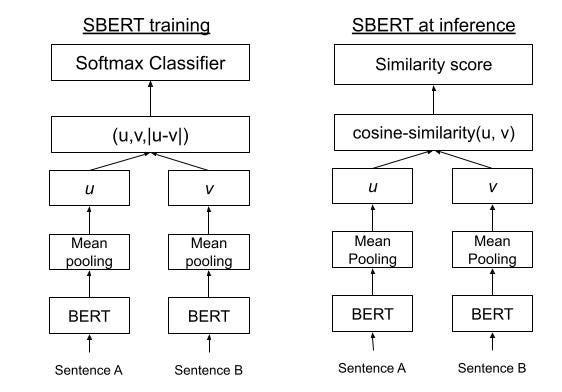
When you take a look at the unique cross-encoder structure of BERT, SBERT is much like this however removes the ultimate classification head. Not like BERT, SBERT makes use of a siamese structure (as I defined above), the place it comprises 2 BERT architectures which can be basically similar and share the identical weights, and SBERT processes 2 sentences as pairs throughout coaching.
Let’s say that we feed sentence A to BERT A and sentence B to BERT B in SBERT. Every BERT outputs pooled sentence embeddings. Whereas the unique analysis paper tried a number of pooling strategies, they discovered mean-pooling was the very best method. Pooling is a way for generalizing options in a community, and on this case, imply pooling works by averaging teams of options within the BERT.
After the pooling is finished, we now have 2 embeddings: 1 for sentence A and 1 for sentence B. When the mannequin is coaching, SBERT concatenates the two embeddings which can then run by way of a softmax classifier and be skilled utilizing a softmax-loss operate. At inference — or when the mannequin really begins predicting — the 2 embeddings are then in contrast utilizing a cosine similarity operate, which can output a similarity rating for the 2 sentences. Here’s a diagram for SBERT when it’s fine-tuned and at inference.
How are you going to use SBERT?
SBERT has its personal Python library that yow will discover right here. Utilizing it is so simple as utilizing a mannequin from the cuddling face transformer library. For instance, to compute sentence embeddings, you are able to do this:
from sentence_transformers import SentenceTransformer
mannequin = SentenceTransformer('paraphrase-MiniLM-L6-v2')sentences = ['The quick brown fox jumps over the lazy dog',
'Dogs are a popular household pet around the world']embeddings = mannequin.encode(sentences)
for embedding in embeddings:
print(embedding)
Right here, I used the ‘paraphrase-MiniLM-L6-v2’ pretrained mannequin, however there are lots of different pretrained fashions you need to use that yow will discover right here.
Utilizing SBERT to compute sentence similarity can be straightforward. Right here is how one can compute/discover the very best similarity scores between sentences in an inventory of sentences.
from sentence_transformers import SentenceTransformer, util
mannequin = SentenceTransformer('all-MiniLM-L6-v2')sentences = ['The cat sits outside',
'A man is playing guitar',
'I love pasta',
'The new movie is awesome',
'The cat plays in the garden',
'A woman watches TV',
'The new movie is so great',
'Do you like pizza?']#encode the sentences
embeddings = mannequin.encode(sentences, convert_to_tensor=True)#compute the similarity scores
cosine_scores = util.cos_sim(embeddings, embeddings)#compute/discover the very best similarity scores
pairs = []
for i in vary(len(cosine_scores)-1):
for j in vary(i+1, len(cosine_scores)):
pairs.append({'index': [i, j], 'rating': cosine_scores[i]
[j]})#type the scores in lowering order
pairs = sorted(pairs, key=lambda x: x['score'], reverse=True)for pair in pairs[0:10]:
i, j = pair['index']
print("{} tt {} tt Rating: {:.4f}".format(sentences[i],
sentences[j], pair['score']))
These code snippets have been taken from the SBERT library web site. You possibly can discover extra right here. The code above outputs:
The brand new film is superior The brand new film is so nice Rating: 0.8939 The cat sits exterior The cat performs within the backyard Rating: 0.6788 I really like pasta Do you want pizza? Rating: 0.5096
I really like pasta The brand new film is so nice Rating: 0.2560
I really like pasta The brand new film is superior Rating: 0.2440
A person is enjoying guitar The cat performs within the backyard Rating: 0.2105 The brand new film is superior Do you want pizza? Rating: 0.1969
The brand new film is so nice Do you want pizza? Rating: 0.1692
The cat sits exterior A girl watches TV Rating: 0.1310
The cat performs within the backyard Do you want pizza? Rating: 0.0900
